数据部分
ClickHouse 中的表部件是什么?
在 ClickHouse 中,每个使用 MergeTree engine family 的表,其数据在磁盘上被组织成一组不可变的 data parts (数据片段) 。
为说明这一点,我们使用这张表 (改编自 UK property prices dataset) ,用于追踪英国已售房产的成交日期、城镇、街道和价格:
你可以在我们的 ClickHouse SQL Playground 中查询此表。
每当有一组行被插入到表中时,就会创建一个数据部分 (data part) 。如下图所示:
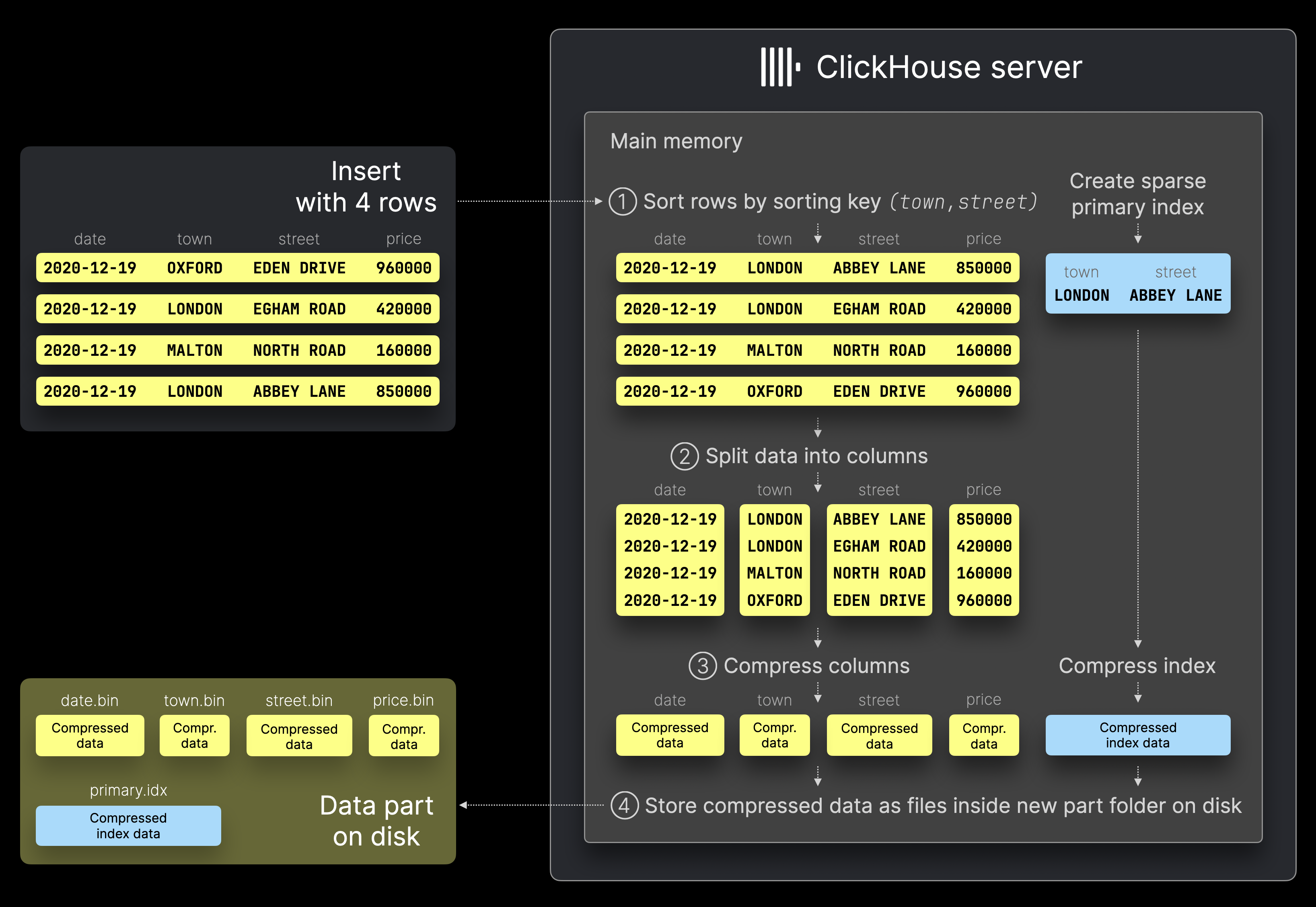
当 ClickHouse 服务器处理示意图中包含 4 行的示例插入操作 (例如通过 INSERT INTO 语句) 时,将执行以下几个步骤:
① 排序:根据表的排序键 (town, street) 对行进行排序,并为排序后的行生成稀疏主索引。
② 拆分:将排序后的数据按列拆分。
③ 压缩:对每一列进行压缩。
④ 写入磁盘:将压缩后的列作为二进制列文件保存在一个新目录中,该目录代表此次插入产生的数据部分。同时,稀疏主索引也会被压缩并存储在同一目录中。
根据表所使用的具体引擎,在排序的同时可能还会进行其他转换。
数据部分是自包含的,包含了解释其内容所需的全部元数据,而不需要一个集中式目录。除了稀疏主索引之外,数据部分还包含其他元数据,例如二级数据跳过索引、列统计信息、校验和、最小-最大索引 (如果使用了分区) ,以及更多信息。
Part 合并
为了管理每个表中的 parts 数量,后台合并 任务会定期将较小的 parts 合并成更大的部分,直到它们达到一个可配置的压缩大小 (通常约为 150 GB) 。合并后的 parts 会被标记为非活动,并在可配置的时间间隔后删除。随着时间推移,这一过程会形成一个由合并 parts 组成的分层结构,这也是该表引擎被称为 MergeTree 表的原因:
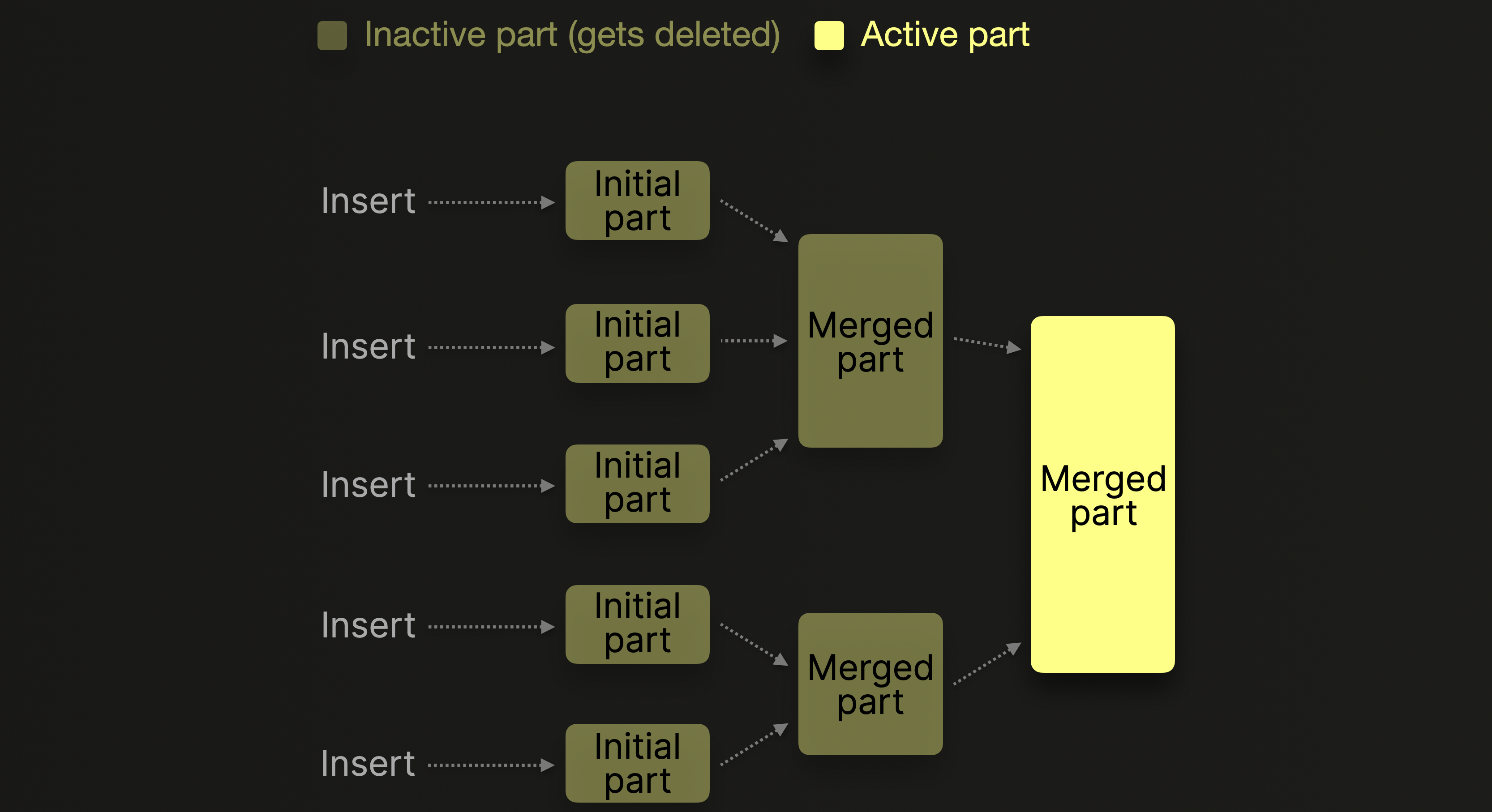
为尽量减少初始 parts 的数量以及合并带来的开销,数据库客户端建议要么批量插入元组,例如一次插入 20,000 行,要么使用异步插入模式。在异步模式下,ClickHouse 会将来自多个针对同一张表的 INSERT 语句的行缓存在一起,仅当缓冲区大小超过可配置阈值或超时时,才创建一个新的 part。
监控表的分片
你可以使用虚拟列 _part,查询示例表当前所有处于活动状态的 parts 列表:
上面的查询会检索磁盘上的目录名称,每个目录都代表该表的一个活动数据 part。目录名称中的各个组成部分具有特定含义,相关说明记录在此处,供有兴趣进一步了解的读者参考。
另外,ClickHouse 会在 system.parts 系统表中跟踪所有表的全部 ^^parts^^ 信息,下面这个查询会针对上面的示例表返回当前所有活动 ^^parts^^ 的列表,包括它们的合并层级以及这些 ^^parts^^ 中存储的行数:
每对该 part 额外执行一次合并操作,其合并层级就会增加 1。层级为 0 表示这是一个尚未被合并过的新 part。
