选择低基数的分区键
分区本质上是一种数据管理技术,而非查询优化工具。尽管它可以在特定工作负载下提升性能,但不应作为加速查询的首选机制;必须在充分理解其影响的前提下谨慎选择分区键,并且仅在其与数据生命周期需求或已充分分析的访问模式相契合时才使用。
在 ClickHouse 中,分区会根据指定的键将数据组织成逻辑片段。这通过在建表时使用 PARTITION BY 子句来定义,通常用于按时间区间、类别或其他与业务相关的维度对行进行分组。分区表达式的每个唯一值都会在磁盘上形成其独立的物理分区,ClickHouse 会针对每个值将数据存储在各自的 分区片段 中。分区能够改进数据管理,简化数据保留策略,并且可以帮助优化某些查询模式。
例如,考虑下面这个英国房产成交价格数据集的表,它使用 toStartOfMonth(date) 作为分区键。
每当向表中插入一组行时,ClickHouse 不会像此处描述的那样创建一个包含所有插入行的单一分区片段,而是会针对插入行中每个唯一的分区键值创建一个新的分区片段:
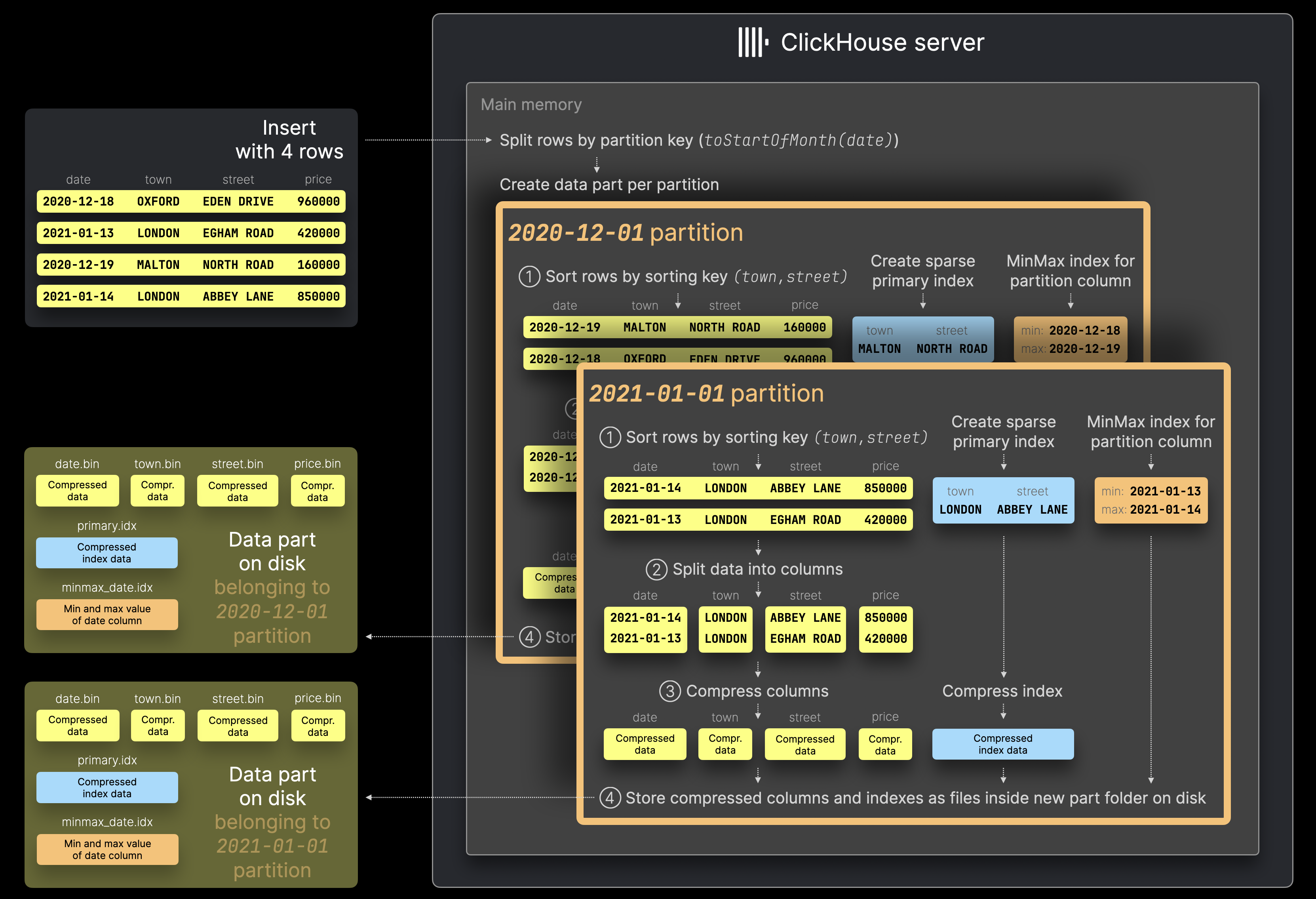
ClickHouse 服务器首先根据分区键值 toStartOfMonth(date) 将上图示例中插入的 4 行数据拆分开来。然后,对于确定的每个分区,这些行会像通常情况那样一样,依次经过多个顺序步骤处理 (① 排序,② 拆分为列,③ 压缩,④ 写入磁盘) 。
如需更详细的分区说明,建议参阅本指南。
启用分区后,ClickHouse 只会在分区内部对分区片段进行合并,而不会跨分区进行合并。我们在上面的示例表中对此进行了说明,见此处:
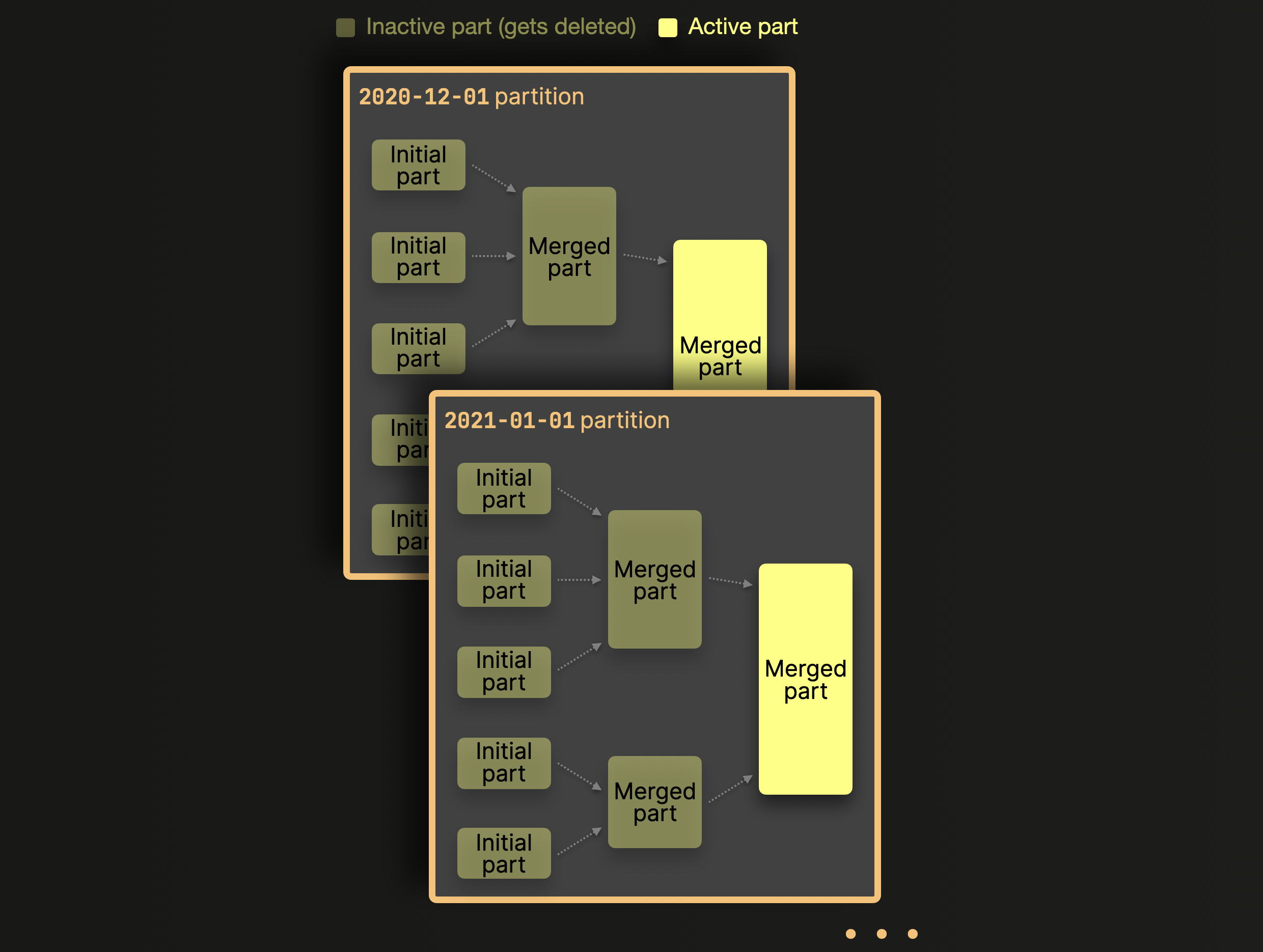
分区的应用
分区是在 ClickHouse 中管理大型数据集的强大工具,尤其适用于可观测性和分析类用例。通过允许在一次元数据操作中删除、移动或归档整个分区 (通常按时间或业务逻辑对齐) ,分区可以实现高效的数据生命周期管理。与逐行删除或复制操作相比,这种方式显著更快且资源占用更低。分区还能与 ClickHouse 的 TTL 和分层存储等特性良好集成,使你无需自定义编排即可实现数据保留策略或冷热存储策略。例如,近期数据可以保存在由 SSD 支撑的高速存储上,而较旧的分区则会自动迁移到更廉价的对象存储中。
虽然分区可以提升某些工作负载的查询性能,但也可能对响应时间产生负面影响。
如果分区键不在主键中,而查询按该键进行过滤,启用分区后用户可能会看到查询性能的提升。示例请参见此处。
相反,如果查询需要跨多个分区访问数据,由于总的 part 数量增加,性能可能会受到负面影响。基于这一原因,用户在将分区视为一种查询优化技术之前,应先理解自身的访问模式。
总之,用户应主要将分区视为一种数据管理技术。有关数据管理的示例,请参见可观测性用例指南中的“管理数据”以及“核心概念 - 表分区”中的“表分区用于做什么?”。
选择低基数的分区键
需要特别注意的是,更多的 parts 会对查询性能产生负面影响。因此,如果 parts 的数量超过了配置好的限制 (无论是总量还是按分区) ,ClickHouse 会在插入时返回一个 “too many parts” 错误。
为分区键选择合适的**基数 (cardinality) **至关重要。高基数分区键——即具有大量不同分区值的键——会导致 parts 数量激增。由于 ClickHouse 不会跨分区合并 parts,分区过多会产生过多未合并的 parts,最终触发 “Too many parts” 错误。Merge 操作是必不可少的,它可以减少存储碎片并优化查询速度,但在高基数分区的场景下,这种 merge 潜力会丧失。
相反,一个低基数的分区键——不同取值少于 100 到 1,000 个——通常是更优的选择。它有利于高效地合并 parts,保持较低的元数据开销,并避免在存储中创建过多对象。此外,ClickHouse 会在分区列上自动构建 MinMax 索引,这可以显著加速在这些列上进行过滤的查询。例如,当表按 toStartOfMonth(date) 进行分区时,按月份过滤可以让引擎完全跳过无关的分区及其 parts。
虽然分区在某些查询模式下可以提升性能,但它本质上主要是一个数据管理特性。在很多情况下,由于数据碎片化加剧以及需要扫描的 parts 更多,跨所有分区进行查询甚至可能比使用未分区表更慢。请谨慎使用分区,并始终确保所选分区键是低基数的,同时与数据生命周期策略 (例如基于 TTL 的保留策略) 保持一致。如果不确定是否需要分区,可以先从不分区开始,再根据实际访问模式进行后续优化。
