避免使用 OPTIMIZE FINAL
使用 MergeTree 引擎 的 ClickHouse 表会将数据以**不可变部件(immutable parts)**的形式存储在磁盘上,每次插入数据时都会创建新的部件。
每次插入都会创建一个新的部件,其中包含已排序、已压缩的列文件,以及索引和校验和等元数据。关于部件结构以及它们是如何形成的详细说明,建议参考本指南。
随着时间推移,后台进程会将较小的部件合并为更大的部件,以减少碎片并提高查询性能。
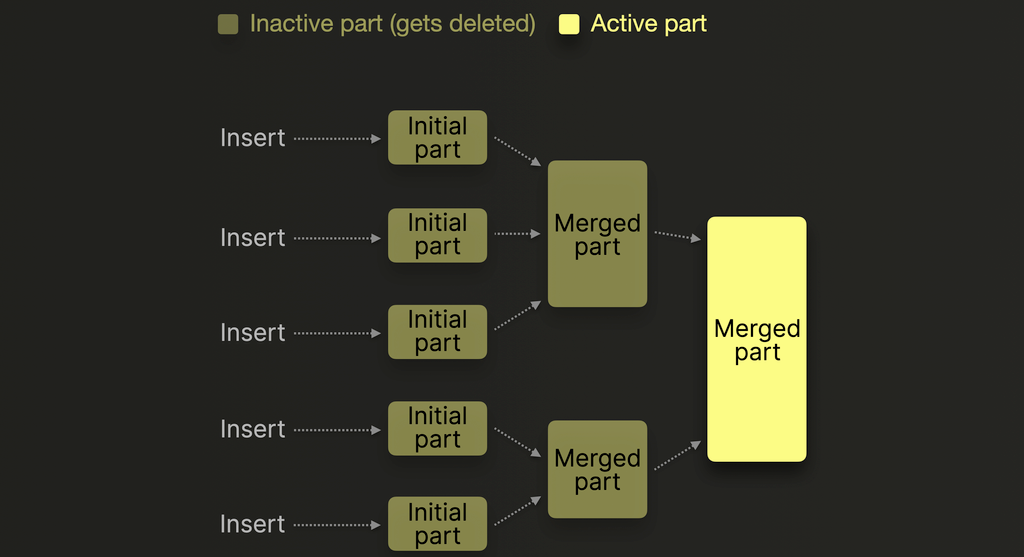
虽然可能会想通过以下方式手动触发这种合并操作:
在大多数情况下,你应该避免执行 OPTIMIZE FINAL 操作,因为它会触发
资源密集型操作,从而可能对集群性能产生影响。
OPTIMIZE FINAL 与 FINAL 并不相同,而在某些情况下必须使用 FINAL,
例如在使用 ReplacingMergeTree 时,为了获得没有重复的数据结果。通常,
如果查询在与主键相同的列上进行过滤,那么使用 FINAL 是可以接受的。
为什么要避免?
成本高昂
运行 OPTIMIZE FINAL 会强制 ClickHouse 将所有活动的 part 合并成单个 part,即使之前已经执行过大型合并。这包括:
- 解压缩所有 part
- 合并数据
- 再次对其进行压缩
- 将最终的 part 写入磁盘或对象存储
这些步骤非常耗费 CPU 和 I/O,在涉及大规模数据集时,可能会给系统带来显著压力。
它会忽略安全限制
通常,ClickHouse 会避免合并大于约 150 GB 的 part(可通过 max_bytes_to_merge_at_max_space_in_pool 进行配置)。但 OPTIMIZE FINAL 会忽略这一安全机制,这意味着:
- 它可能会尝试将多个 150 GB 的 part 合并成一个巨大的 part
- 这可能导致合并时间很长、内存压力增大,甚至内存耗尽错误
- 这些超大 part 后续可能难以再合并,即进一步尝试合并它们会因为上述原因而失败。在某些需要通过合并来保证查询行为正确的场景中,这可能会带来不良后果,例如 ReplacingMergeTree 中重复数据不断累积,从而降低查询时的性能。
让后台合并完成这项工作
ClickHouse 已经会在后台执行智能合并,以优化存储和查询效率。这些合并是增量的、感知资源使用情况的,并且会遵循已配置的阈值。除非存在非常特定的需求(例如在冻结表或导出之前对数据进行最终定版),否则通常应当让 ClickHouse 自行管理合并过程。
