
设计模式
这是关于从 PostgreSQL 迁移到 ClickHouse 的指南的 第 2 部分。此内容可以视为入门,旨在帮助用户部署符合 ClickHouse 最佳实践的初始功能系统。它避免了复杂的主题,结果不会是一个完全优化的模式;而是为用户构建生产系统和学习提供了坚实的基础。
Stack Overflow 数据集包含多个相关的表。我们建议迁移首先集中在迁移其主表上。这不一定是最大表,而是您期望接受最多分析查询的表。这将使您熟悉 ClickHouse 的主要概念,尤其是如果您来自 OLTP 背景时。这张表可能需要重新建模,因为在添加其他表时,可能需要充分利用 ClickHouse 的特性以获得最佳性能。我们在我们的 数据建模文档 中探讨这个建模过程。
建立初始模式
遵循这一原则,我们专注于主要的 posts 表。下面显示了其 Postgres 模式:
为了为上述每一列建立等效类型,我们可以使用 DESCRIBE 命令和 Postgres 表函数。将以下命令修改为您的 Postgres 实例:
这为我们提供了一个初步的非优化模式。
在没有
NOT NULL Constraint的情况下,Postgres 列可以包含 Null 值。在未检查行值的情况下,ClickHouse 将其映射到等效的 Nullable 类型。请注意,主键不能为 Null,这在 Postgres 中是一个要求。
我们可以使用这些类型通过简单的 CREATE AS EMPTY SELECT 命令创建一个 ClickHouse 表。
同样的方法可以用于以其他格式从 s3 加载数据。请参见此处有关从 Parquet 格式加载数据的等效示例。
初始加载
创建了表后,我们可以使用 Postgres 表函数 将行从 Postgres 插入 ClickHouse。
此操作可能会对 Postgres 造成相当大的负担。用户可能希望使用其他操作进行补充,以避免对生产工作负载造成影响,例如导出 SQL 脚本。此操作的性能将取决于您的 Postgres 和 ClickHouse 集群的大小及其网络互连。
每个从 ClickHouse 到 Postgres 的
SELECT仅使用一个连接。该连接来自服务端连接池,其大小由设置postgresql_connection_pool_size(默认值为 16)决定。
如果使用完整的数据集,示例应加载 5900 万个帖子。通过在 ClickHouse 中进行简单计数确认:
优化类型
优化此模式的类型的步骤与从其他来源加载数据(例如 S3 上的 Parquet)时是相同的。应用此 使用 Parquet 的替代指南 中描述的过程产生了以下模式:
我们可以通过简单的 INSERT INTO SELECT 将数据从前一个表读取并插入到此表中:
在我们的新模式中,我们不保留任何 null 值。上述插入将这些隐式转换为其各自类型的默认值 - 整数为 0,字符串为空值。ClickHouse 还会自动将任何数字转换为其目标精度。
在 ClickHouse 中的主键(排序键)
来自 OLTP 数据库的用户通常会寻找 ClickHouse 中的等效概念。在注意到 ClickHouse 支持 PRIMARY KEY 语法时,用户可能会倾向于使用与其源 OLTP 数据库相同的键定义其表模式。这是不合适的。
ClickHouse 主键有何不同?
为了理解为什么在 ClickHouse 中使用 OLTP 主键不合适,用户应了解 ClickHouse 索引的基本知识。我们以 Postgres 作为示例进行比较,但这些一般概念适用于其他 OLTP 数据库。
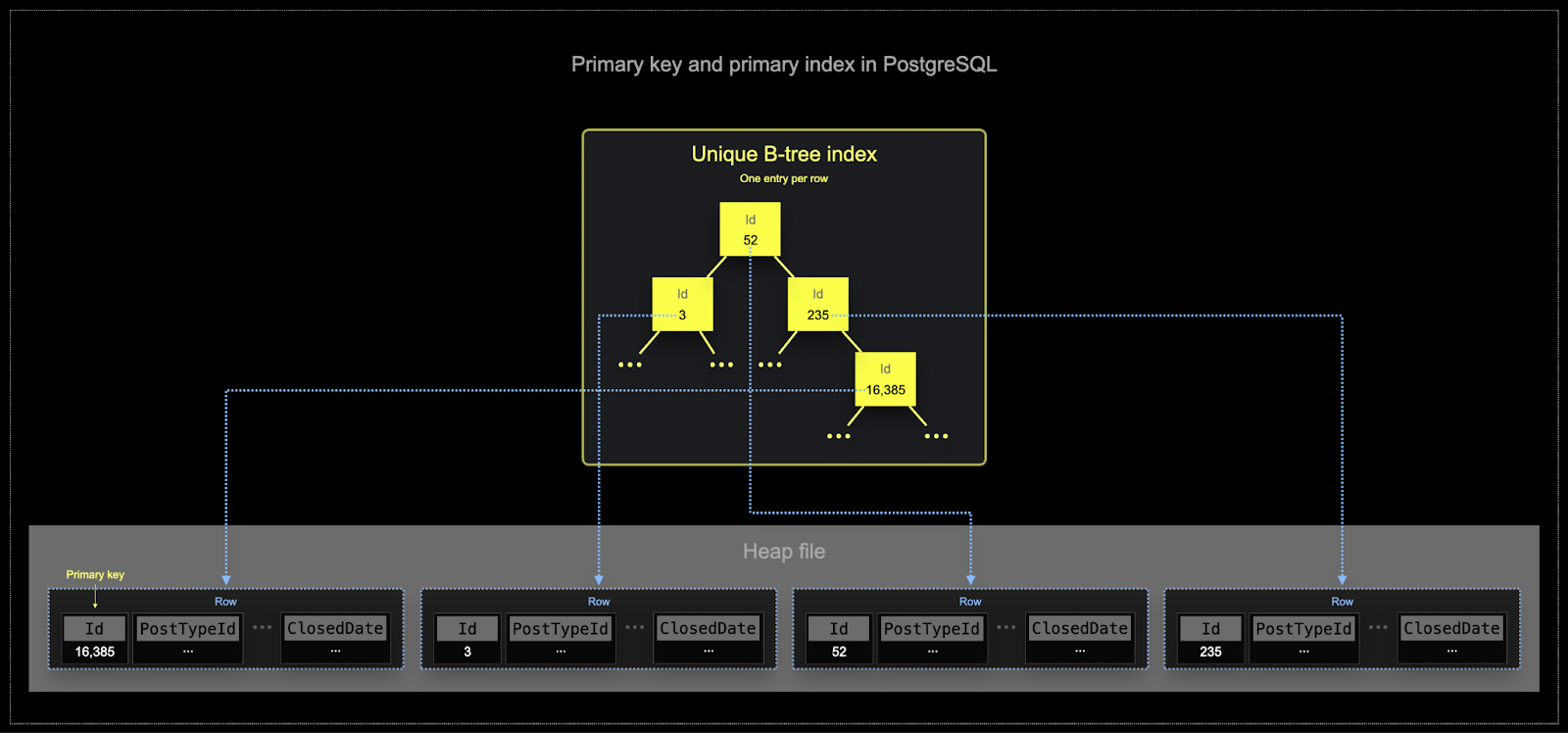
- Postgres 主键,按定义是每行唯一的。使用 B 树结构 可有效查看该键的单行。虽然 ClickHouse 可以针对单行值进行优化,但分析工作负载通常需要读取几个列,但用于许多行。过滤器通常需要确定 一部分行 以进行聚合。
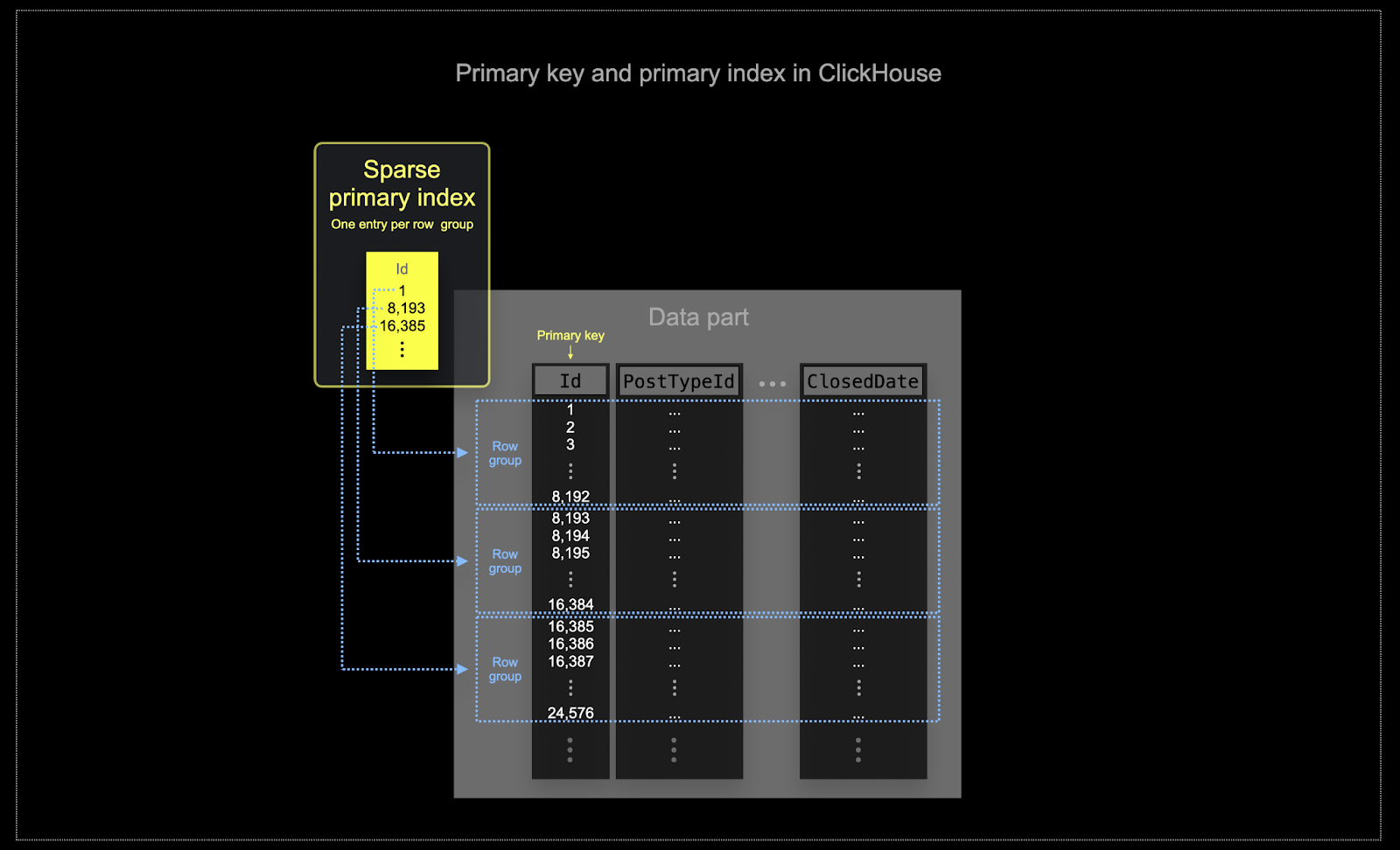
- 内存和磁盘效率对 ClickHouse 经常使用的规模至关重要。数据以称为 parts 的块写入 ClickHouse 表,合并 部分的规则在后台应用。在 ClickHouse 中,每个部分都有自己的主索引。当部分被合并时,合并部分的主索引也会被合并。与 Postgres 不同,这些索引不是为每行构建的。相反,部分的主索引具有每组行一个索引条目 - 这种技术称为 稀疏索引。
- 稀疏索引 之所以可能,是因为 ClickHouse 将部分的行按指定键有序存储在磁盘上。稀疏主索引允许它快速(通过索引条目的二进制搜索)识别可能匹配查询的行组。找到的可能匹配的行组随后将并行传输到 ClickHouse 引擎以查找匹配项。这种索引设计允许主索引小(它完全适合主内存),同时仍显著加快查询执行时间,尤其是对于数据分析用例中的典型范围查询。有关更多详细信息,我们推荐此 深入指南。
在 ClickHouse 中选择的键将决定不仅是索引,也决定数据在磁盘上写入的顺序。因此,它可以显著影响压缩级别,这反过来又会影响查询性能。使大多数列的值以连续顺序写入的排序键将使所选压缩算法(和编解码器)更有效地压缩数据。
表中的所有列将根据指定排序键的值进行排序,无论它们是否包含在键中。例如,如果
CreationDate用作键,则所有其他列的值的顺序将对应于CreationDate列中值的顺序。可以指定多个排序键 - 这将按照与SELECT查询中的ORDER BY子句相同的语义进行排序。
选择排序键
关于选择排序键的考虑和步骤,以 posts 表为例,请参见 此处。
压缩
ClickHouse 的列式存储意味着与 Postgres 相比,压缩效果通常会显著更好。以下是比较两个数据库中所有 Stack Overflow 表的存储需求的示例:
有关优化和测量压缩的更多详细信息,请参见 此处。