Part 合并
ClickHouse 中的 part 合并 (part merges) 是什么?
ClickHouse 之所以快速,不仅体现在查询上,也体现在写入上,这要归功于其存储层,其工作方式类似于 LSM trees:
① 向 MergeTree 引擎家族的表插入数据时,会创建已排序、不可变的 data parts (数据片段) 。
② 所有数据处理都被下放给后台 part 合并 (part merges) 。
从而使数据写入既轻量又高度高效。
为了控制每张表中的 parts 数量并实现上述第 ② 点,ClickHouse 会在后台持续地将较小的 parts (按分区) 合并为更大的 parts,直到其压缩后的大小大约达到 ~150 GB。
下图展示了这一后台合并过程的示意:
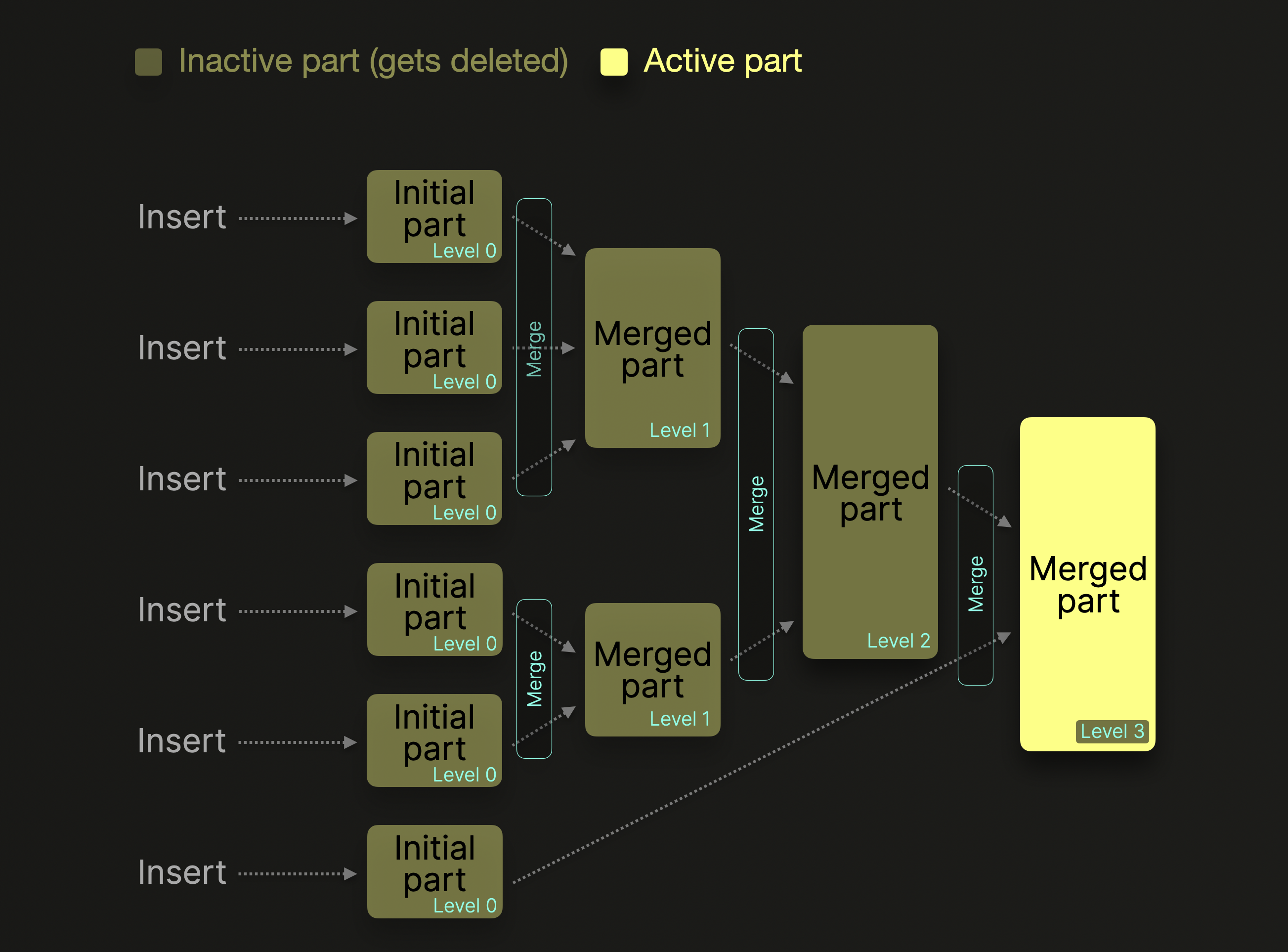
每当发生一次额外合并,对应 part 的 merge level (合并层级) 就会加一。0 表示该 part 是新的,尚未被合并。已被合并进更大 parts 的 parts 会被标记为非活动,并在一段可配置的时间后 (默认 8 分钟) 最终被删除。随着时间推移,这会形成一个由合并 parts 构成的树。因此才称为 MergeTree 表。
监控合并
在 什么是表 parts 示例中,我们展示了,ClickHouse 会在 parts 系统表中跟踪所有表的 parts。我们使用了以下查询来获取示例表中每个活动部件的合并级别以及存储的行数:
先前文档中展示的 查询结果表明,该示例表包含四个活动的 ^^parts^^,每个都是由最初插入的 ^^parts^^ 经单次合并生成的:
运行 该查询现在显示,这四个 parts 此后已合并为一个最终的 part (前提是该表中没有进一步的插入操作) :
在 ClickHouse 24.10 中,一个新的 合并仪表板 被添加到了内置的监控仪表板中。通过 /merges HTTP 处理程序,该仪表板在 OSS 和 Cloud 中均可使用,用来可视化我们示例表的所有 part 合并:
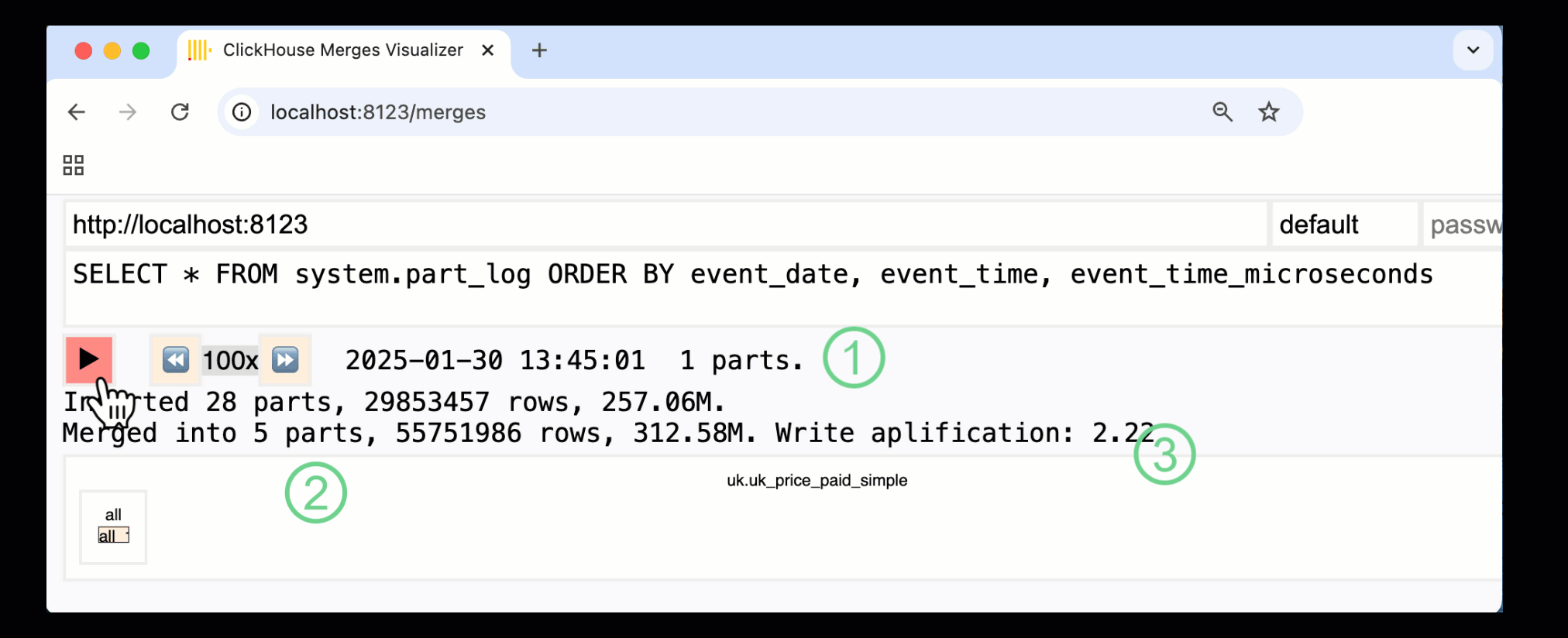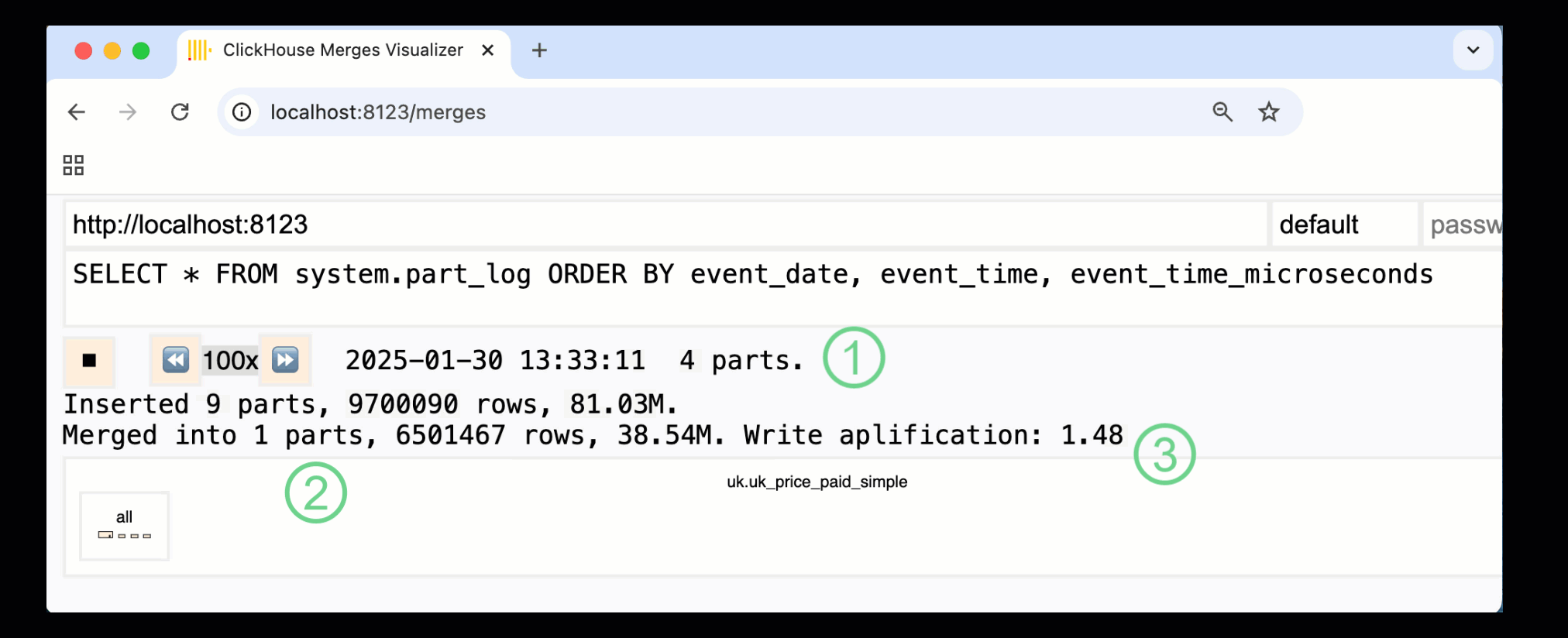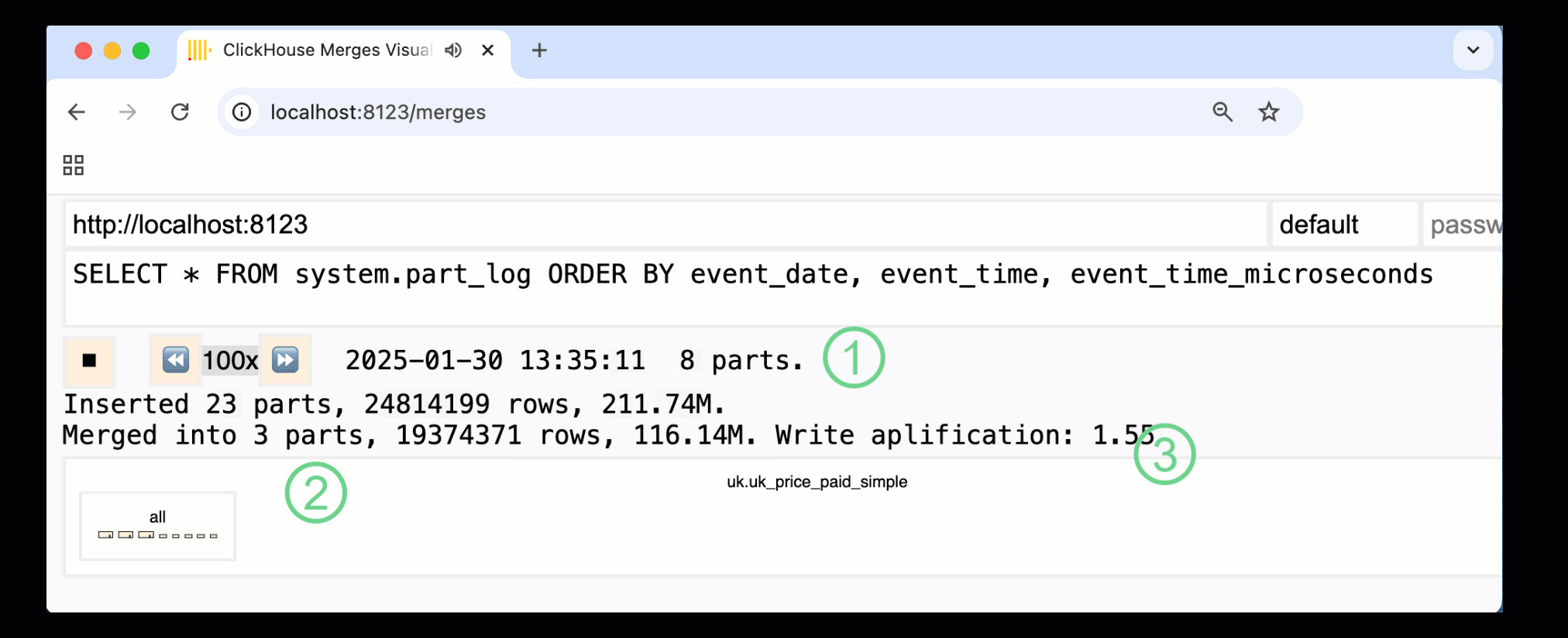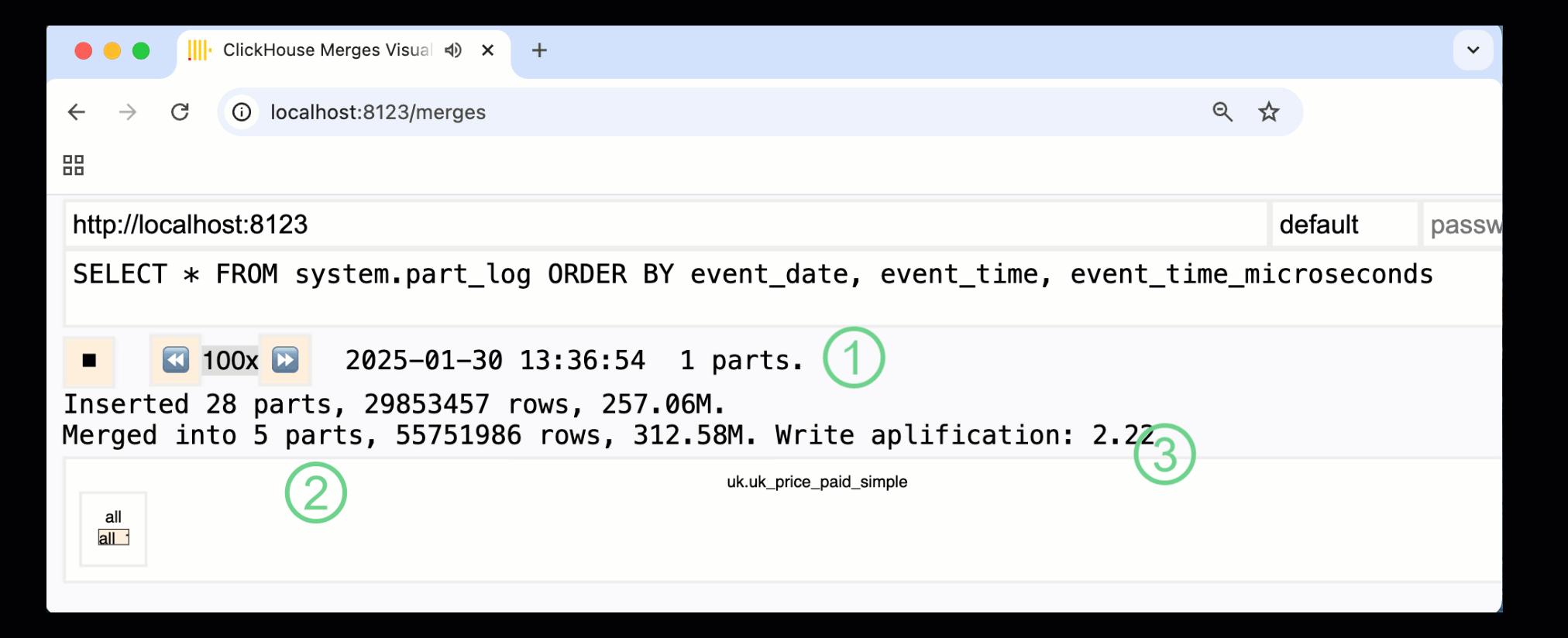
上面展示的仪表板捕获了整个过程,从最初的数据写入到最终合并为单个 part:
① 活跃 ^^parts^^ 的数量。
② part 合并,以方框形式进行可视化展示 (方框大小反映 part 的大小) 。
并发合并
单个 ClickHouse 服务器使用多个后台合并线程来执行 parts 的并发合并:
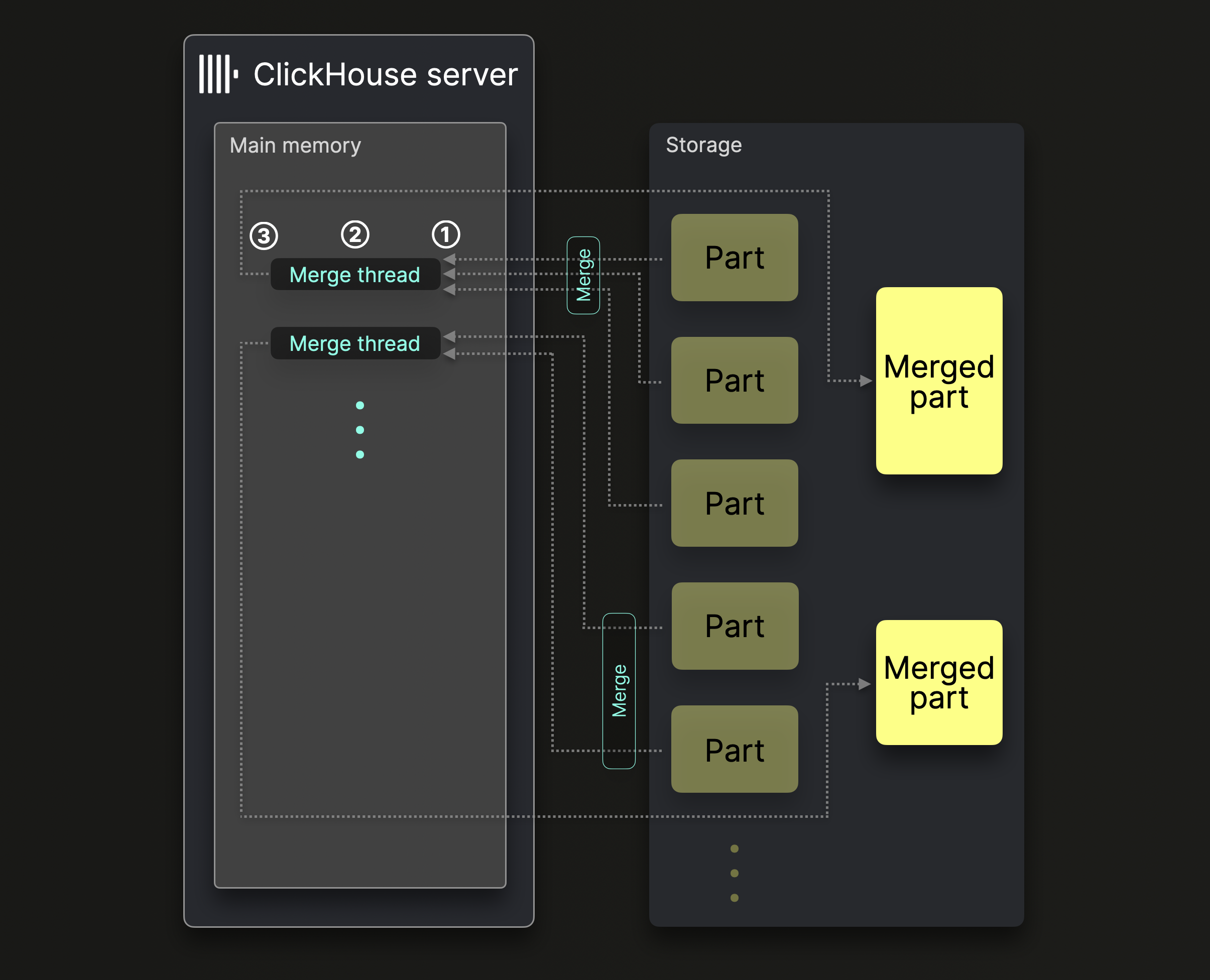
每个合并线程都会执行一个循环:
① 决定接下来要合并哪些 parts,并将这些 parts 加载到内存中。
② 在内存中将这些 parts 合并成一个更大的 part。
③ 将合并后的 part 写入磁盘。
转到 ①
请注意,增加 CPU 核心数量和 RAM 容量可以提高后台合并的吞吐量。
内存优化合并
ClickHouse 不一定会像在前一个示例中示意的那样,一次性将所有要合并的 parts 全部加载到内存中。根据若干因素,并为了降低内存消耗 (以牺牲合并速度为代价) ,所谓的垂直合并会将这些 parts 按块分段依次加载并合并,而不是一次性全部处理。
合并机制
下图展示了在 ClickHouse 中,由单个后台合并线程在默认情况下 (未启用纵向合并) 对 parts 执行合并的过程:
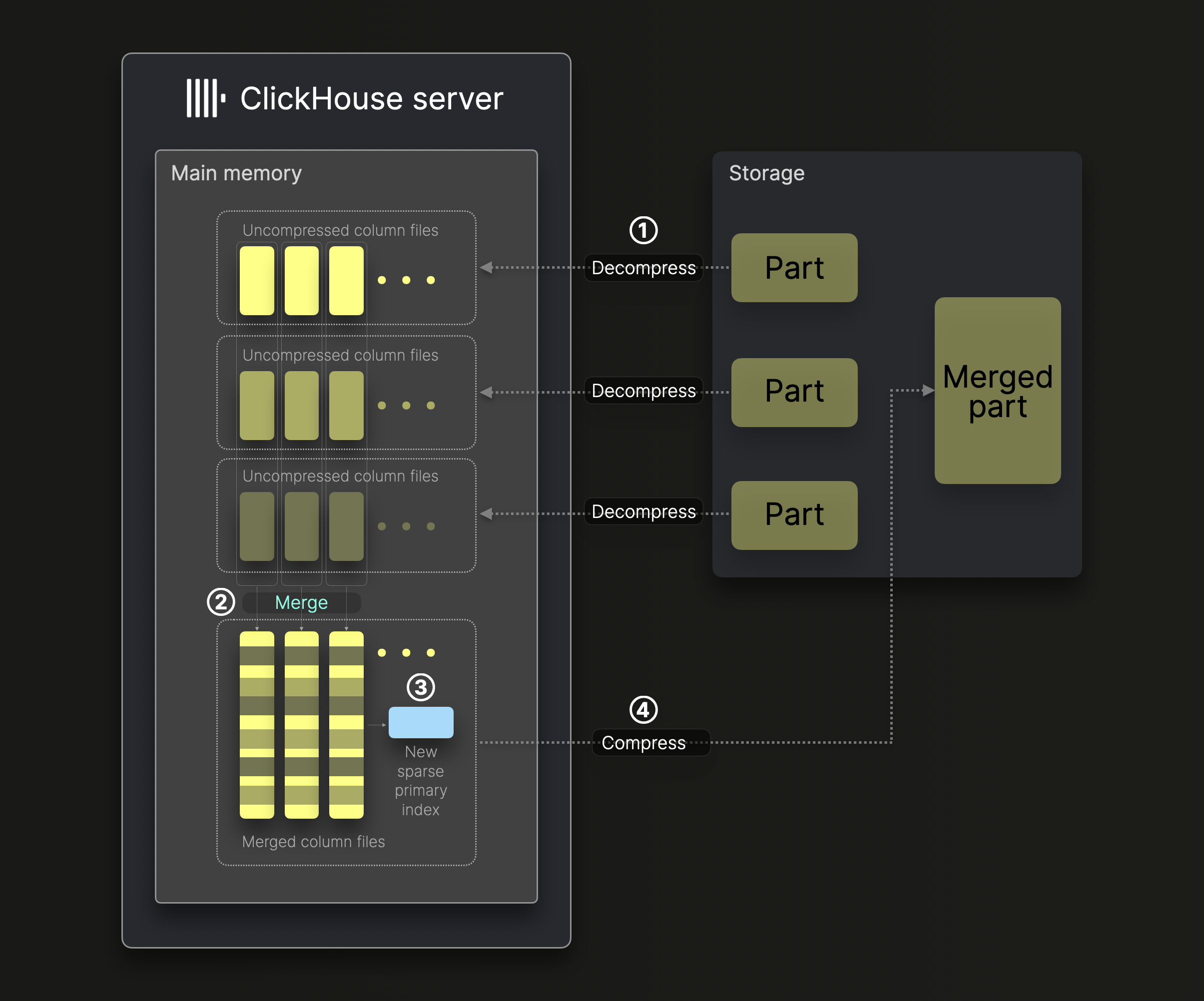
part 的合并大致分为以下几个步骤:
① 解压与加载:将待合并 parts 中的压缩二进制列文件解压并加载到内存中。
② 合并:将数据合并为更大的列文件。
③ 索引:为合并后的列文件生成新的稀疏主索引。
④ 压缩与存储:对新的列文件和索引进行压缩,并将其保存到一个新的目录中,用于表示合并后的数据 part。
数据 part 中的其他元数据,例如二级数据跳过索引、列统计信息、校验和以及最小-最大索引,也会基于合并后的列文件重新生成。为简化说明,我们在此省略了这些细节。
第 ② 步的具体机制取决于所使用的MergeTree 引擎,不同引擎的合并方式有所不同。例如,行可能会被聚合,或在数据过时时被替换。如前所述,这种方式将所有数据处理卸载到后台合并中,从而通过保持写入操作轻量高效,实现超快写入。
接下来,我们将简要概述 MergeTree 家族中各个具体引擎的合并机制。
标准合并
下图展示了标准 MergeTree 表中的 parts 是如何合并的:
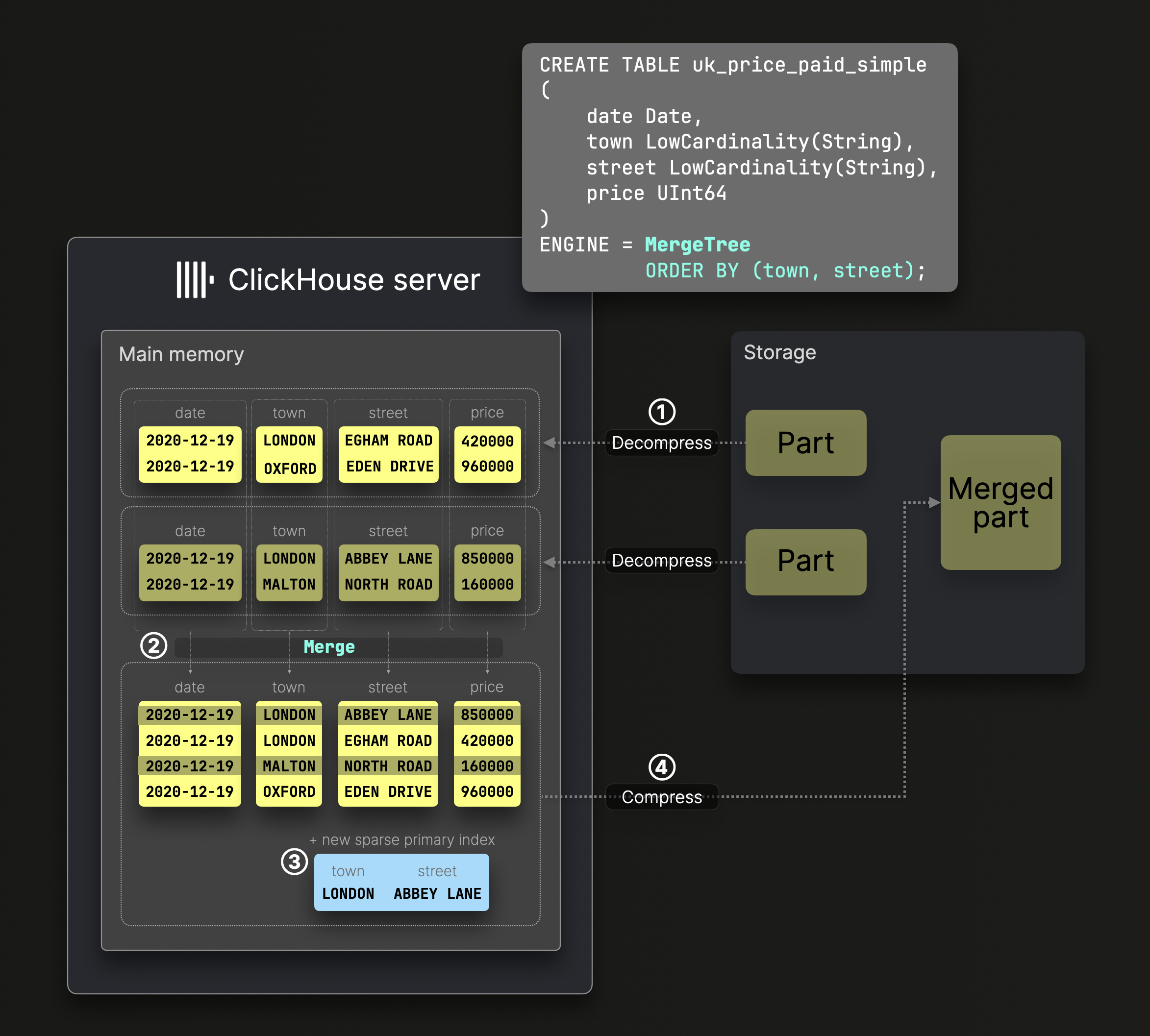
上图中的 DDL 语句创建了一个 sorting key 为 (town, street) 的 MergeTree 表,这意味着 磁盘上的数据按这些列排序,并相应生成稀疏主键索引。
① 已解压且预先排序的表列会在 ② 保持由表的 sorting key 定义的全局排序顺序的同时进行合并,③ 生成新的稀疏主键索引,④ 将合并后的列文件和索引压缩后作为一个新的 part 存储到磁盘上。
替换合并
ReplacingMergeTree 表中的 parts 合并与标准合并类似,但只保留每一行的最新版本,较旧的版本会被丢弃:
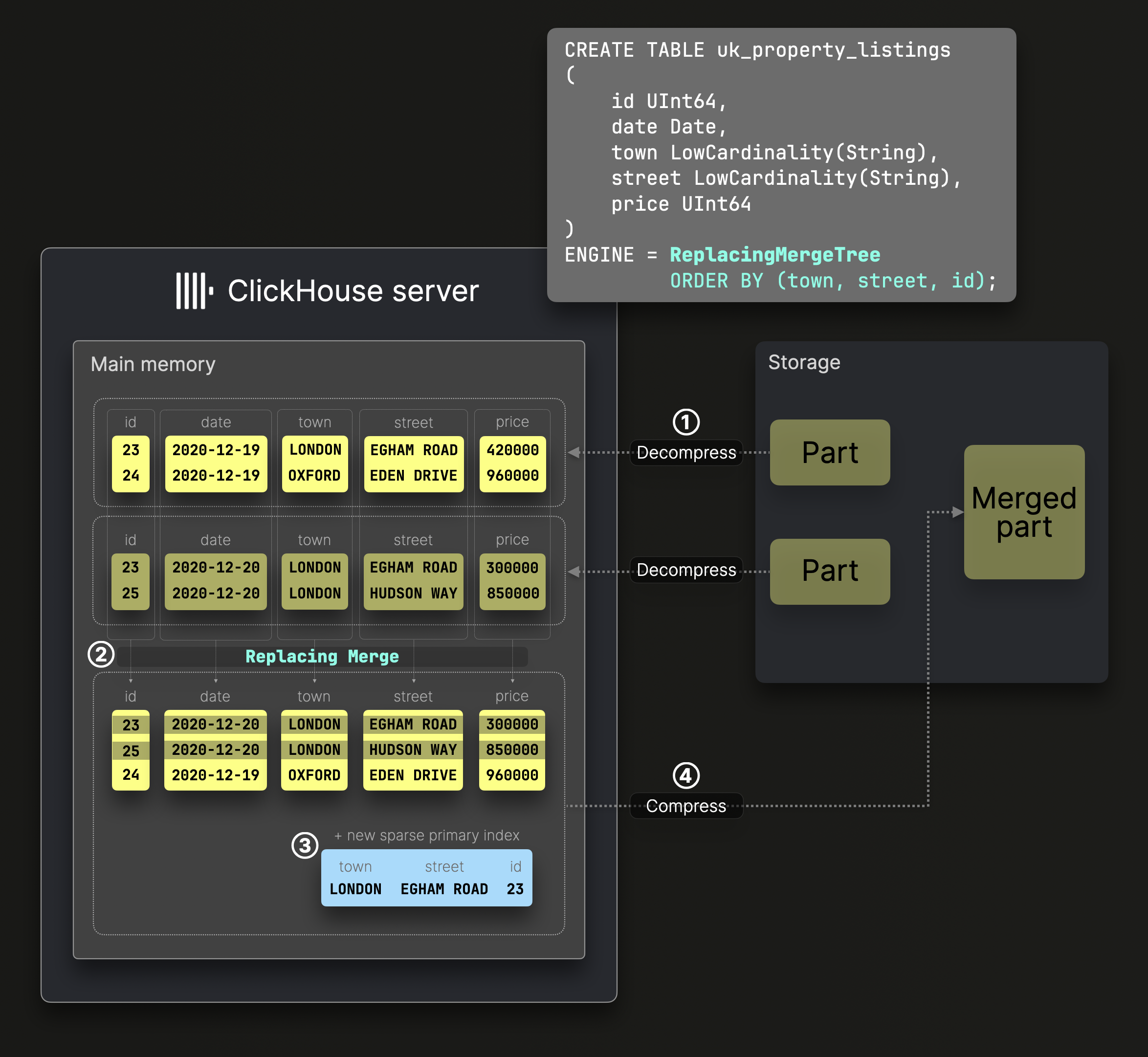
上图中的 DDL 语句创建了一个 ReplacingMergeTree 表,其 sorting key 为 (town, street, id),这意味着磁盘上的数据按这些列排序,并相应生成稀疏主键索引。
② 合并的工作方式与标准 MergeTree 表类似,会在保持全局排序顺序的同时合并解压后、预先排序的列。
不过,ReplacingMergeTree 会删除具有相同 sorting key 的重复行,并根据其所在 part 的创建时间戳仅保留最新的一行。
求和合并
在 SummingMergeTree 表的 parts 合并过程中,数值数据会自动汇总:
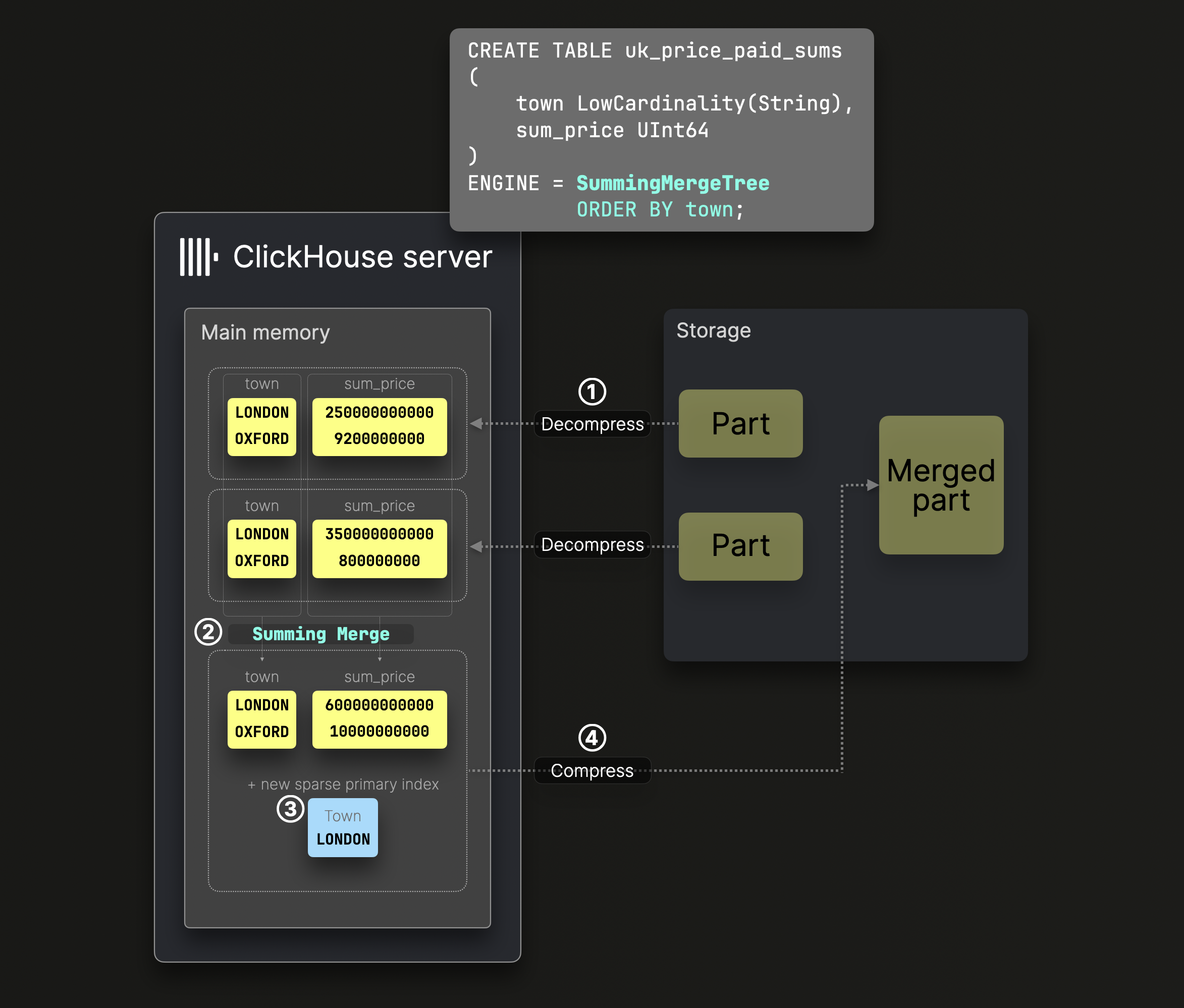
上图中的 DDL 语句定义了一个以 town 作为 sorting key 的 SummingMergeTree 表,这意味着磁盘上的数据按该列排序,并相应创建稀疏主键索引。
在 ② 合并步骤中,ClickHouse 会将所有具有相同 sorting key 的行替换为一行,同时对数值列的值求和。
聚合合并
上文中的 SummingMergeTree 表示例是 AggregatingMergeTree 表的一种专用变体,它允许在 parts 合并期间应用任意90+聚合函数,以实现自动增量数据转换:
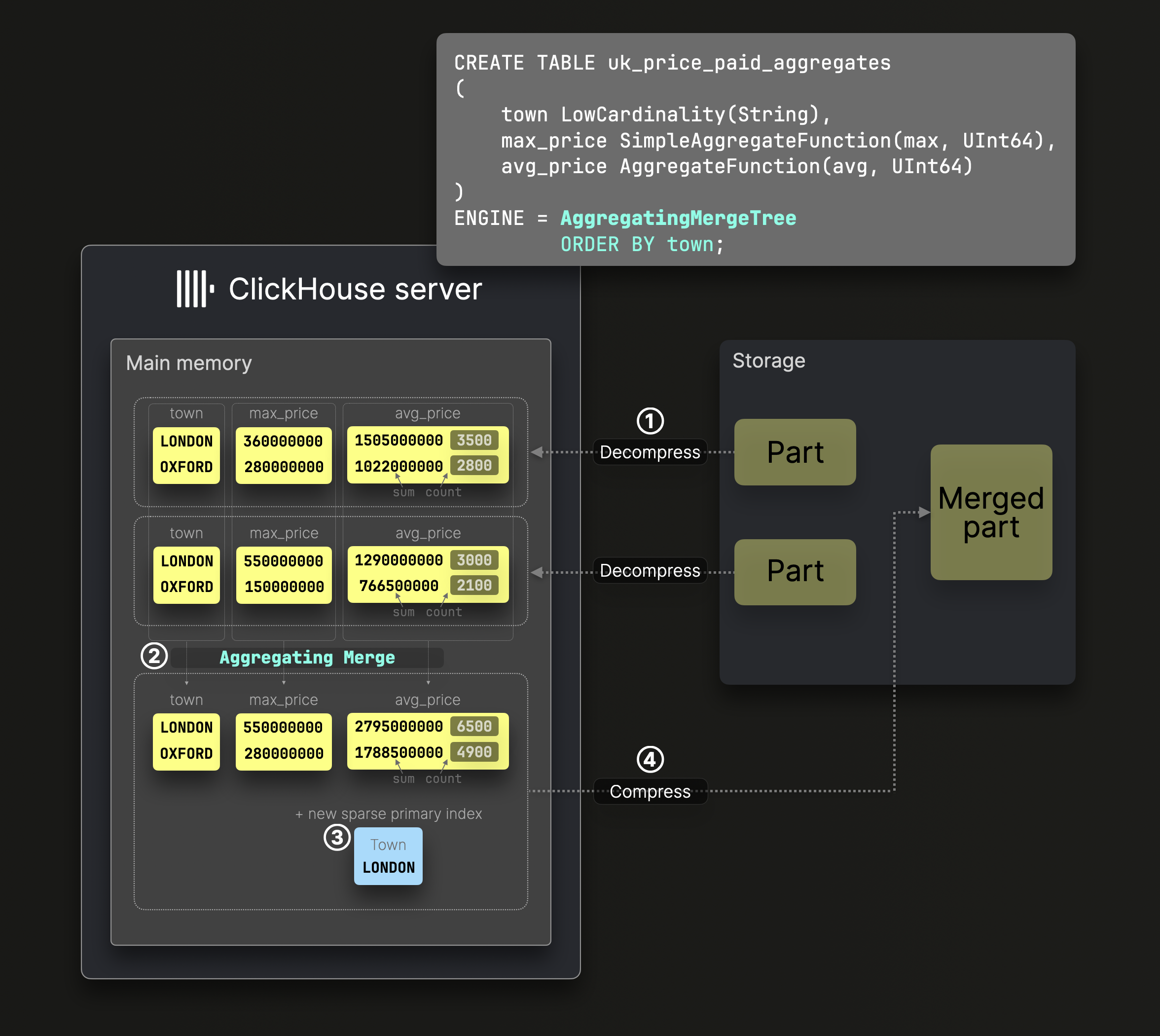
上图中的 DDL 语句创建了一个以 town 作为 sorting key 的 AggregatingMergeTree 表,确保磁盘上的数据按该列排序,并生成相应的稀疏主键索引。
在 ② 合并期间,ClickHouse 会将所有具有相同 sorting key 的行替换为一行,该行存储部分聚合状态(例如用于 avg() 的 sum 和 count)。这些状态通过增量后台合并确保结果准确。
