CREATE TABLE events_snapshot (
ts DateTime32,
uuid String,
count UInt64
)
ENGINE = MergeTree
ORDER BY uuid;
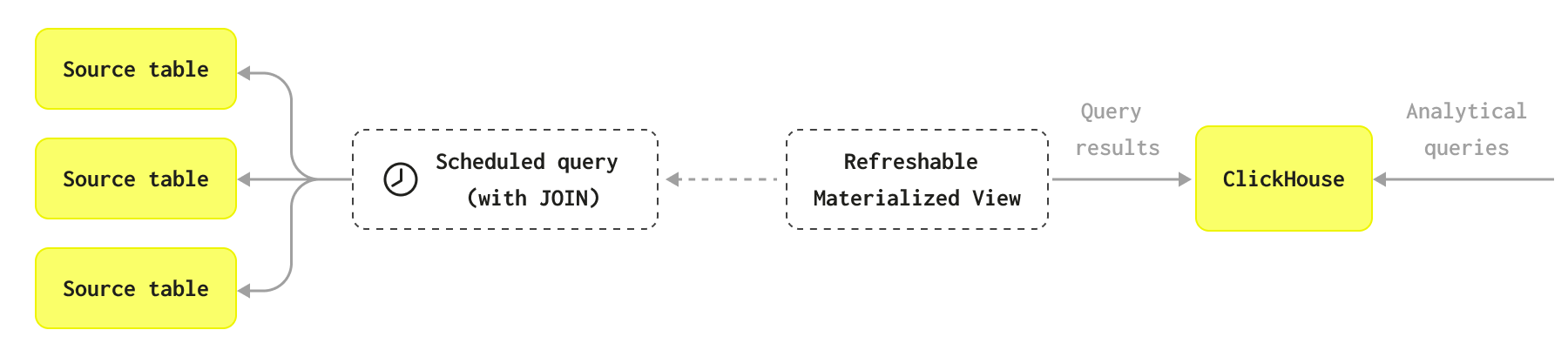
接下来可以创建一个可刷新materialized view 来填充该表:
CREATE MATERIALIZED VIEW events_snapshot_mv
REFRESH EVERY 10 SECOND APPEND TO events_snapshot
AS SELECT
now() AS ts,
uuid,
sum(count) AS count
FROM events
GROUP BY ALL;
SELECT
posts.*,
arrayMap(p -> (p.1, p.2), arrayFilter(p -> p.3 = 'Linked' AND p.2 != 0, Related)) AS LinkedPosts,
arrayMap(p -> (p.1, p.2), arrayFilter(p -> p.3 = 'Duplicate' AND p.2 != 0, Related)) AS DuplicatePosts
FROM posts
LEFT JOIN (
SELECT
PostId,
groupArray((CreationDate, RelatedPostId, LinkTypeId)) AS Related
FROM postlinks
GROUP BY PostId
) AS postlinks ON posts_types_codecs_ordered.Id = postlinks.PostId;
CREATE MATERIALIZED VIEW posts_with_links_mv
REFRESH EVERY 1 HOUR TO posts_with_links AS
SELECT
posts.*,
arrayMap(p -> (p.1, p.2), arrayFilter(p -> p.3 = 'Linked' AND p.2 != 0, Related)) AS LinkedPosts,
arrayMap(p -> (p.1, p.2), arrayFilter(p -> p.3 = 'Duplicate' AND p.2 != 0, Related)) AS DuplicatePosts
FROM posts
LEFT JOIN (
SELECT
PostId,
groupArray((CreationDate, RelatedPostId, LinkTypeId)) AS Related
FROM postlinks
GROUP BY PostId
) AS postlinks ON posts_types_codecs_ordered.Id = postlinks.PostId;
SELECT
id, any(actor_name) AS name, uniqExact(movie_id) AS movies,
round(avg(rank), 2) AS avg_rank, uniqExact(genre) AS genres,
uniqExact(director_name) AS directors, max(created_at) AS updated_at
FROM (
SELECT
imdb.actors.id AS id,
concat(imdb.actors.first_name, ' ', imdb.actors.last_name) AS actor_name,
imdb.movies.id AS movie_id, imdb.movies.rank AS rank, genre,
concat(imdb.directors.first_name, ' ', imdb.directors.last_name) AS director_name,
created_at
FROM imdb.actors
INNER JOIN imdb.roles ON imdb.roles.actor_id = imdb.actors.id
LEFT JOIN imdb.movies ON imdb.movies.id = imdb.roles.movie_id
LEFT JOIN imdb.genres ON imdb.genres.movie_id = imdb.movies.id
LEFT JOIN imdb.movie_directors ON imdb.movie_directors.movie_id = imdb.movies.id
LEFT JOIN imdb.directors ON imdb.directors.id = imdb.movie_directors.director_id
)
GROUP BY id
ORDER BY movies DESC
LIMIT 5;
CREATE MATERIALIZED VIEW imdb.actor_summary_mv
REFRESH EVERY 1 MINUTE TO imdb.actor_summary AS
SELECT
id,
any(actor_name) AS name,
uniqExact(movie_id) AS num_movies,
avg(rank) AS avg_rank,
uniqExact(genre) AS unique_genres,
uniqExact(director_name) AS uniq_directors,
max(created_at) AS updated_at
FROM
(
SELECT
imdb.actors.id AS id,
concat(imdb.actors.first_name, ' ', imdb.actors.last_name) AS actor_name,
imdb.movies.id AS movie_id,
imdb.movies.rank AS rank,
genre,
concat(imdb.directors.first_name, ' ', imdb.directors.last_name) AS director_name,
created_at
FROM imdb.actors
INNER JOIN imdb.roles ON imdb.roles.actor_id = imdb.actors.id
LEFT JOIN imdb.movies ON imdb.movies.id = imdb.roles.movie_id
LEFT JOIN imdb.genres ON imdb.genres.movie_id = imdb.movies.id
LEFT JOIN imdb.movie_directors ON imdb.movie_directors.movie_id = imdb.movies.id
LEFT JOIN imdb.directors ON imdb.directors.id = imdb.movie_directors.director_id
)
GROUP BY id
ORDER BY num_movies DESC;
INSERT INTO imdb.actors VALUES (845466, 'Clicky', 'McClickHouse', 'M');
INSERT INTO imdb.roles SELECT
845466 AS actor_id,
id AS movie_id,
'Himself' AS role,
now() AS created_at
FROM imdb.movies
LIMIT 10000, 910;
不到 60 秒,我们的目标表就已更新,充分体现了 Clicky 高产的演艺生涯:
SELECT *
FROM imdb.actor_summary
ORDER BY num_movies DESC
LIMIT 5;