S3 表函数
s3 表函数允许你从兼容 S3 的存储中读取文件,也可以将文件写入其中。其语法结构如下:
- path — 包含文件路径的 存储桶 URL。在只读模式下,支持以下路径通配符:
*、?、{abc,def}和{N..M},其中N、M为数字,'abc'、'def'为字符串。更多信息,请参阅在路径中使用通配符文档。 - format — 文件的格式。
- structure — 表的结构。格式为
'column1_name column1_type, column2_name column2_type, ...'。 - compression — 该参数为可选。支持的值包括:
none、gzip/gz、brotli/br、xz/LZMA、zstd/zst。默认情况下,会根据文件扩展名自动检测压缩方式。
准备工作
DESCRIBE 语句:
DESCRIBE TABLE 语句的输出应显示 ClickHouse 会如何自动推断 S3 存储桶中所见的数据。注意,它还会自动识别并解压 gzip 压缩格式:
MergeTree 表作为目标端。下面的语句会在默认数据库中创建一个名为 trips 的表。请注意,我们选择对上文推断出的某些数据类型进行调整,尤其是不使用 Nullable() 数据类型修饰符,因为这可能会导致存储一些不必要的额外数据,并带来额外的性能开销:
pickup_date 字段上使用了分区。通常,分区键是用于数据管理的,但稍后我们会利用这个键将写入 S3 的操作并行化。
我们的出租车数据集中的每个条目都代表一次出租车行程。这些匿名化数据包含 2000 万条记录,压缩后存储在 S3 存储桶 https://datasets-documentation.s3.eu-west-3.amazonaws.com/ 的 nyc-taxi 文件夹下。数据采用 TSV 格式,每个文件约有 100 万行。
从 S3 读取数据
TabSeparatedWithNames 格式会在第一行中包含列名。其他格式 (例如 CSV 或 TSV) 则会为此查询返回自动生成的列,例如 c1、c2、c3 等。
查询还支持虚拟列,例如 _path 和 _file,分别提供存储桶路径和文件名的信息。例如:
MergeTree 表。
使用 clickhouse-local
clickhouse-local 程序让你无需部署和配置 ClickHouse server,即可快速处理本地文件。任何使用 s3 表函数 的查询都可以通过该实用工具执行。例如:
从 S3 插入数据
s3 函数与简单的 INSERT 语句结合使用。请注意,我们无需列出各列,因为目标表已提供所需的结构。这要求各列按照表 DDL 语句中指定的顺序出现:系统会根据它们在 SELECT 子句中的位置进行映射。插入全部 1000 万行可能需要几分钟,具体取决于 ClickHouse 实例的性能。下面我们先插入 100 万行,以确保能快速返回结果。可根据需要调整 LIMIT 子句或列选择,以导入所需的子集:
使用 ClickHouse Local 进行远程插入
clickhouse-local 将 S3 数据插入 ClickHouse。在下面的示例中,我们从 S3 存储桶读取数据,并使用 remote 函数将其插入 ClickHouse:
要通过安全的 SSL 连接执行此操作,请使用
remoteSecure 函数。导出数据
s3 表函数将数据写入 S3 中的文件。这需要具备相应的权限。我们会在请求中传递所需的凭证,但如需了解更多选项,请参阅 管理凭证 页面。
在下面这个简单示例中,我们将表函数用作目标端而不是源端。这里,我们把 trips 表中的 10,000 行流式传输到一个存储桶,并指定 lz4 压缩和 CSV 输出类型:
s3 函数中指定列,这也可以从 SELECT 中推断出来。
拆分大文件
INSERT 命令,每次处理一部分数据。ClickHouse 提供了通过 PARTITION 键自动拆分文件的方法。
在下面的示例中,我们使用 rand() 函数的模数创建了十个文件。注意,生成的分区 ID 会被引用到文件名中。这样会生成十个带数字后缀的文件,例如 trips_0.csv.lz4、trips_1.csv.lz4 等:
payment_type 是一个很自然的分区键,其基数为 5。
利用集群
INSERT INTO SELECT 查询时,可以通过插入到分布式表来缓解部分资源压力,但仍然只有一个节点负责读取、解析和处理数据。为了解决这一问题,并实现读取的横向扩展,我们提供了 s3Cluster 函数。
接收查询的节点称为发起节点,它会与集群中的每个节点建立连接。用于确定需要读取哪些文件的 glob 模式会被解析为一个文件集合。发起节点将文件分发给集群中的各个节点,这些节点充当工作节点。这些工作节点在完成读取后,会继续请求待处理的文件。通过这一过程,我们就能够对读取进行横向扩展。
s3Cluster 函数的格式与单节点变体相同,不同之处在于它需要指定目标集群,以标明工作节点:
cluster_name— 用于构建远程和本地服务器地址集合及连接参数的集群名称。source— 指向单个文件或一组文件的 URL。在只读模式下支持以下通配符:*、?、{'abc','def'}和{N..M},其中 N、M 为数字,abc、def 为字符串。更多信息请参见 路径中的通配符。access_key_id和secret_access_key— 指定用于给定端点的凭证密钥。可选。format— 文件的 格式。structure— 表的结构。格式为 ‘column1_name column1_type, column2_name column2_type, …’。
s3 函数一样,如果存储桶本身不安全,或者你通过环境定义了安全机制 (例如 IAM 角色) ,则凭证是可选的。不过,与 s3 function 不同的是,自 22.3.1 起,必须在请求中指定结构,也就是说不会自动推断 schema。
在大多数情况下,此函数会作为 INSERT INTO SELECT 的一部分使用。在这种情况下,你通常插入的是一张分布式表。下面我们给出一个简单示例,其中 trips_all 是一张分布式表。虽然该表使用的是 events 集群,但读取和写入所使用节点的一致性并不是必需条件:
s3cluster 函数设置 parallel_distributed_insert_select 参数。
S3 表引擎
s3 函数支持对存储在 S3 中的数据执行临时查询,但其语法较为繁琐。使用 S3 表引擎后,你无需反复指定存储桶 URL 和凭证。为此,ClickHouse 提供了 S3 表引擎。
path— 存储桶 URL 及文件路径。在只读模式下支持以下通配符:*、?、{abc,def}和{N..M},其中 N、M 表示数字,‘abc’、‘def’ 表示字符串。更多信息,请参见此处。format— 文件的格式。aws_access_key_id,aws_secret_access_key- AWS 账户用户的长期凭证。您可以使用它们对请求进行身份验证。该参数为可选。如果未指定凭证,则使用配置文件中的值。更多信息,请参见管理凭证。compression— 压缩类型。支持的值:none、gzip/gz、brotli/br、xz/LZMA、zstd/zst。该参数为可选。默认情况下,会根据文件扩展名自动检测压缩类型。
读取数据
https://datasets-documentation.s3.eu-west-3.amazonaws.com/nyc-taxi/ 存储桶中的前 10 个 TSV 文件创建一个名为 trips_raw 的表。每个文件都包含 100 万行:
{0..9} 模式,将范围限制为前十个文件。创建后,我们可以像查询其他任何表一样查询这个表:
插入数据
S3 表引擎支持并行读取。仅当表定义中不包含 glob pattern 时,才支持写入。因此,上面的表无法写入。
为演示写入,请创建一个指向可写 S3 存储桶 的表:
- 指定设置
s3_create_new_file_on_insert=1。这会在每次插入时创建新文件。每个文件末尾都会追加一个数字后缀,并且会随着每次插入操作单调递增。对于上述示例,后续一次插入会创建一个 trips_1.bin 文件。 - 指定设置
s3_truncate_on_insert=1。这会截断文件,也就是说,完成后文件将只包含新插入的行。
s3_truncate_on_insert 优先。
关于 S3 表引擎的一些说明:
- 与传统的
MergeTree家族表不同,删除S3表不会删除底层数据。 - 此类表的完整设置可在此处查看。
- 使用此引擎时,请注意以下限制:
- 不支持 ALTER 查询
- 不支持 SAMPLE 操作
- 没有索引的概念,即主键索引或跳过索引。
管理凭证
s3 函数或 S3 表定义中直接传入了凭证。虽然对于偶尔使用,这种方式或许可以接受,但在生产环境中,用户通常需要不那么显式的身份验证机制。为此,ClickHouse 提供了多种选项:
-
在 config.xml 或 conf.d 下的等效配置文件中指定连接详情。下面展示了一个示例文件的内容,假设使用 debian 软件包安装。
只要请求的 URL 与上述端点形成精确的前缀匹配,就会使用这些凭证。另请注意,此示例还支持声明
Authorization请求头,作为 access key 和 secret key 的替代方案。支持的设置完整列表见此处。 -
上述示例还说明了配置参数
use_environment_credentials可用。该配置参数也可以在s3级别进行全局设置:此设置会启用从环境中获取 S3 凭证的尝试,从而允许通过 IAM 角色进行访问。具体来说,将按以下顺序进行获取:- 查找环境变量
AWS_ACCESS_KEY_ID、AWS_SECRET_ACCESS_KEY和AWS_SESSION_TOKEN - 检查 $HOME/.aws
- 通过 AWS Security Token Service 获取临时凭证,即通过
AssumeRoleAPI - 检查 ECS 环境变量
AWS_CONTAINER_CREDENTIALS_RELATIVE_URI或AWS_CONTAINER_CREDENTIALS_FULL_URI以及AWS_ECS_CONTAINER_AUTHORIZATION_TOKEN中的凭证。 - 通过 Amazon EC2 实例元数据获取凭证,前提是 AWS_EC2_METADATA_DISABLED 未设置为 true。
- 也可以针对特定端点设置这些相同的参数,并使用相同的前缀匹配规则。
- 查找环境变量
性能优化
S3 存储调优
Wide and Compact。当前实现仍采用 ClickHouse 的默认行为 (由设置 min_bytes_for_wide_part 和 min_rows_for_wide_part 控制) ,但我们预计在未来版本中,S3 的行为会有所不同。例如,增大 min_bytes_for_wide_part 的默认值会更倾向于使用 Compact 格式,从而减少文件数量。因此,如果你仅使用 S3 存储,现在可能就需要调优这些设置。
S3 后端的 MergeTree
s3 函数及其相关表引擎让我们可以使用熟悉的 ClickHouse 语法查询存储在 S3 中的数据。不过,它们在数据管理功能和性能方面存在一定局限:不支持主索引,不支持无缓存,文件插入也需要由用户自行管理。
ClickHouse 意识到,S3 是一种很有吸引力的存储解决方案,尤其是在对“较冷”数据的查询性能要求不那么高、且用户希望将存储与 compute 分离的场景下。为此,ClickHouse 提供了将 S3 用作 MergeTree 引擎存储后端的支持。这使你既能利用 S3 在可扩展性和成本方面的优势,又能获得 MergeTree 引擎的插入和查询性能。
存储分层
创建磁盘
创建存储策略
创建表
修改表
<path> 配置的磁盘。请注意,我们的卷名和磁盘名称都不会改变。向表中插入的新数据会保留在默认磁盘上,直到达到 move_factor * disk_size,届时数据将被迁移到 S3。
实现复制
ReplicatedMergeTree 表引擎,可在使用 S3 磁盘时实现复制。详情请参阅使用 S3 对象存储跨两个 AWS 区域复制单个分片指南。
读写
- 默认情况下,查询处理管道中任一阶段可使用的最大查询处理线程数等于 CPU 核心数。某些阶段比其他阶段更容易并行化,因此该值只是一个上限。由于数据是从磁盘流式传输的,多个查询阶段可能会同时执行,因此单个查询实际使用的线程数可能会超过该值。可通过设置 max_threads 进行调整。
- 默认情况下,从 S3 读取是异步进行的。此行为由设置
remote_filesystem_read_method决定,其默认值为threadpool。处理请求时,ClickHouse 会以 stripe 为单位读取粒度。每个 stripe 可能包含很多列。线程会逐个读取这些粒度中的列。与同步逐列读取不同,系统会先对所有列执行预取,然后再等待数据返回。相比对每一列都进行同步等待,这种方式能显著提升性能。大多数情况下,你无需更改此设置——请参见性能优化。 - 写入会并行执行,最多支持 100 个并发文件写入线程。
max_insert_delayed_streams_for_parallel_write的默认值为 1000,用于控制并行写入的 S3 blob 数量。由于每个正在写入的文件都需要一个缓冲区 (约 1MB) ,这实际上限制了 INSERT 的内存占用。在服务器内存较低的场景下,适当调低该值可能更合适。
将 S3 对象存储用作 ClickHouse 磁盘
配置 ClickHouse 使用 S3 存储桶 作为磁盘
- 在 ClickHouse 的
config.d目录中创建一个新文件,用于存放存储配置。
- 添加以下存储配置;将其中的 bucket 路径、access key 和 secret key 替换为前面步骤中的相应值
<disks> 标签中的 s3_disk 和 s3_cache 都是任意命名的标签。你可以改用其他名称,但在 <policies> 标签下的 <disk> 标签中引用该磁盘时,必须使用相同的标签名。
<S3_main> 标签同样是任意命名的,它表示策略名称,在 ClickHouse 中创建资源时将用作存储目标的标识符。上面显示的配置适用于 ClickHouse 22.8 或更高版本;如果你使用的是较早版本,请参阅存储数据文档。有关使用 S3 的更多信息:
Integrations 指南:S3 Backed MergeTree- 将文件所有者更新为
clickhouse用户和组
- 重启 ClickHouse 实例,使更改生效。
测试
- 使用 ClickHouse 客户端登录,如下所示
- 创建表,并指定新的 S3 存储策略
- 验证该表是否已按正确的策略创建
- 向表中插入测试行
- 查看行
- 在 AWS 控制台中,进入存储桶列表,选择新建的存储桶和相应文件夹。 你应该会看到类似下面这样的内容:
使用 S3 对象存储在两个 AWS 区域之间复制单个分片
规划部署
安装软件
ClickHouse 服务器 节点
部署 ClickHouse
chnode1 和 chnode2。
将 chnode1 部署在一个 AWS 区域中,将 chnode2 部署在另一个区域中。
部署 ClickHouse Keeper
keepernode1、keepernode2 和 keepernode3。keepernode1 可部署在与 chnode1 相同的区域,keepernode2 可部署在与 chnode2 相同的区域,而 keepernode3 可部署在任一区域,但需与该区域内的 ClickHouse 节点位于不同的可用区。
在 ClickHouse Keeper 节点上执行部署步骤时,请参阅安装说明。
创建 S3 存储桶
chnode1 和 chnode2 的两个区域中各创建一个。
如果你需要有关创建存储桶和 IAM 角色 的分步说明,请展开 创建 S3 存储桶和 IAM 角色 并按步骤操作:
创建 S3 存储桶和 IAM 用户
创建 S3 存储桶和 IAM 用户
本文介绍配置 AWS IAM 用户、创建 S3 存储桶并将 ClickHouse 配置为使用该存储桶作为 S3 磁盘的基本步骤。
建议与您的安全团队共同确定所需权限,并将本文内容作为参考起点。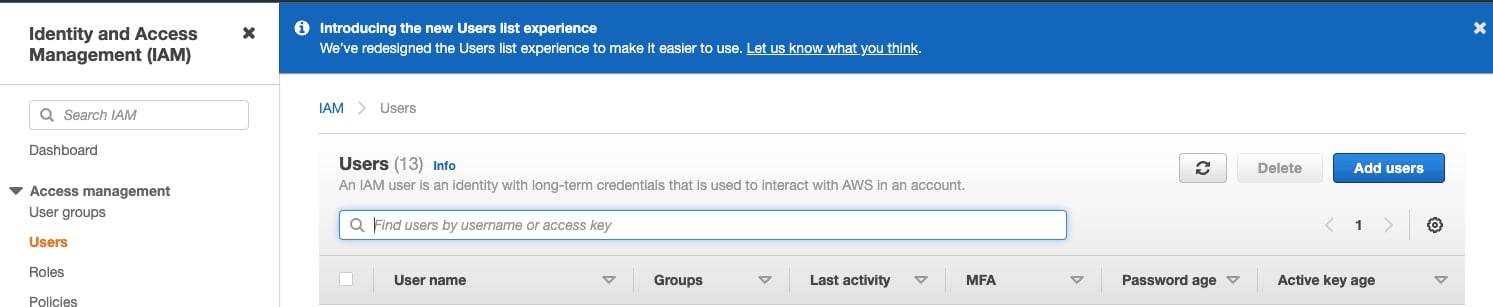



创建 AWS IAM 用户
在以下步骤中,您将创建一个服务账号用户 (而非登录用户) 。- 登录 AWS IAM Management Console。
-
在
Users菜单中,选择Create user
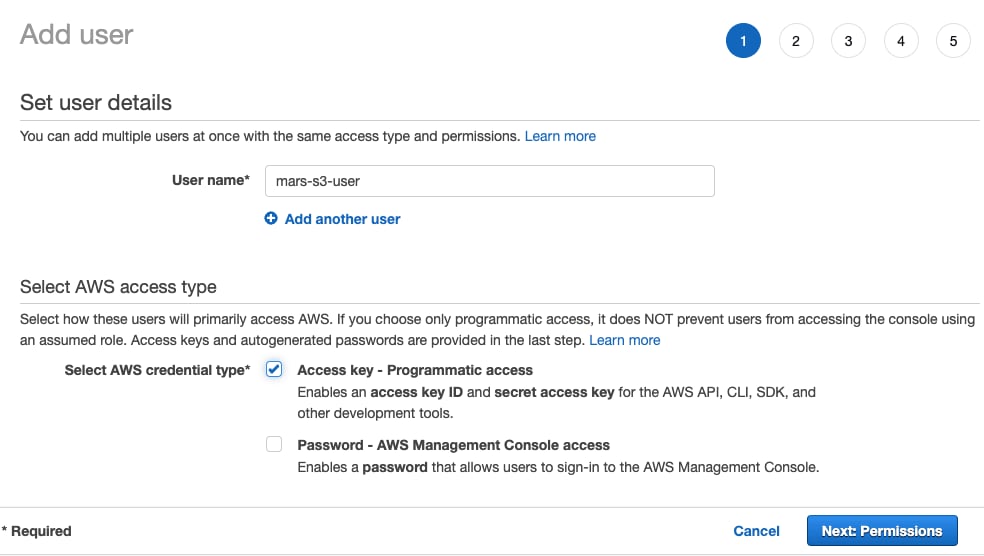
- 输入用户名,将凭证类型设置为
Access key - Programmatic access,然后选择Next: Permissions
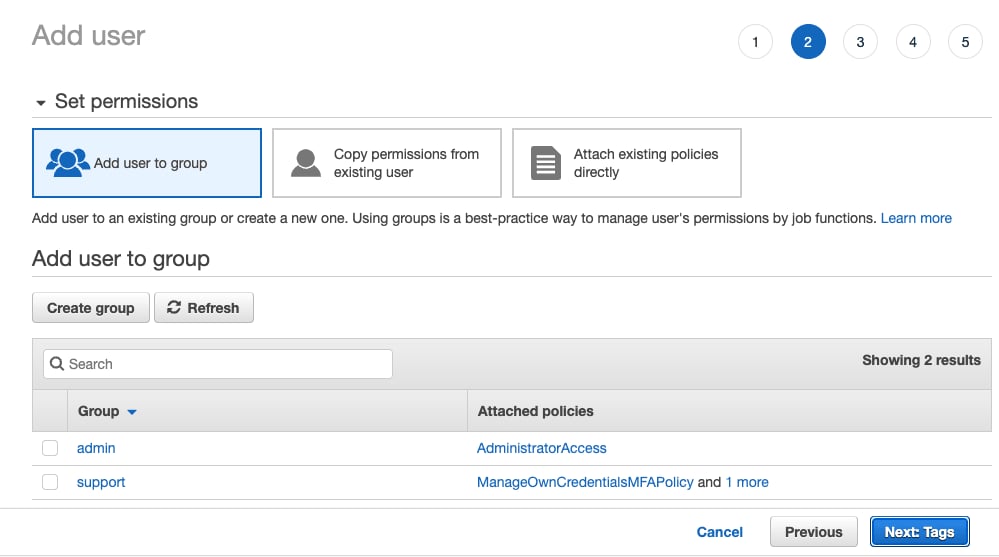
- 不要将用户添加到任何组;选择
Next: Tags
- 如果无需添加任何标签,请选择
Next: Review
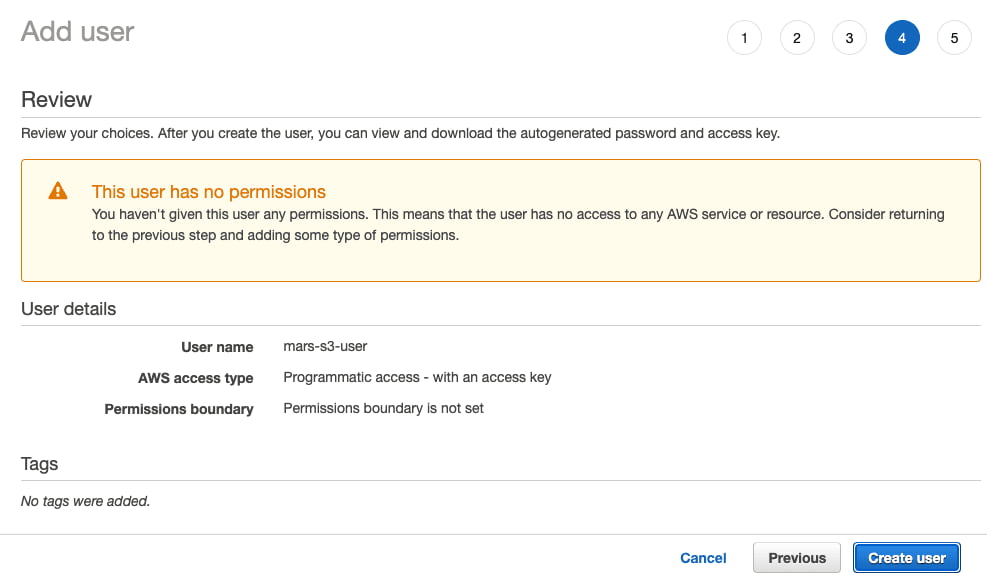
- 点击
Create User
提示用户无权限的警告信息可忽略;下一节将为该用户授予对此存储桶的权限
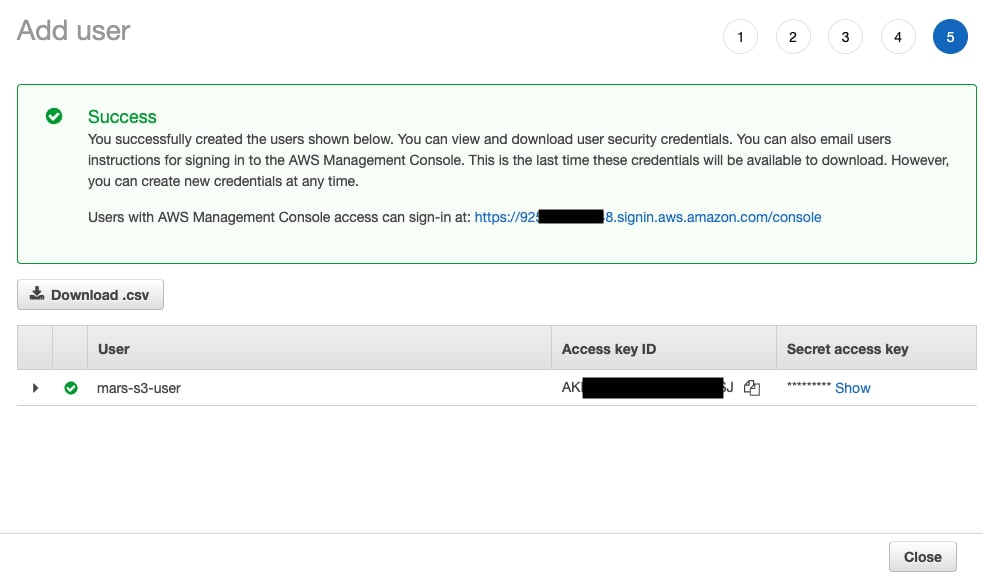
- 该用户现已创建;点击
show,然后复制访问密钥和机密密钥。
请将这些密钥另行保存;这是唯一一次可以查看该秘密访问密钥。
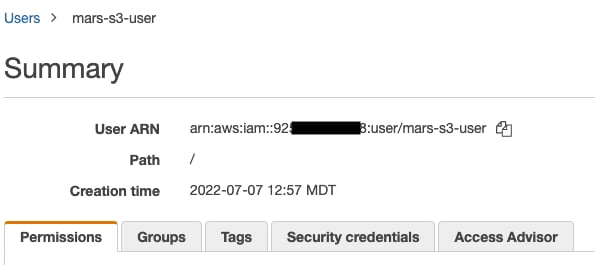
- 点击“关闭”,然后在“用户”页面中找到该用户。
- 复制 ARN (亚马逊资源名称) ,并保存下来,以便在配置存储桶的访问策略时使用。
创建 S3 存储桶
- 在 S3 存储桶部分,选择
Create bucket
- 输入存储桶名称,其余选项保持默认即可
存储桶名称必须在整个 AWS 范围内唯一,而不只是组织内唯一,否则会报错。
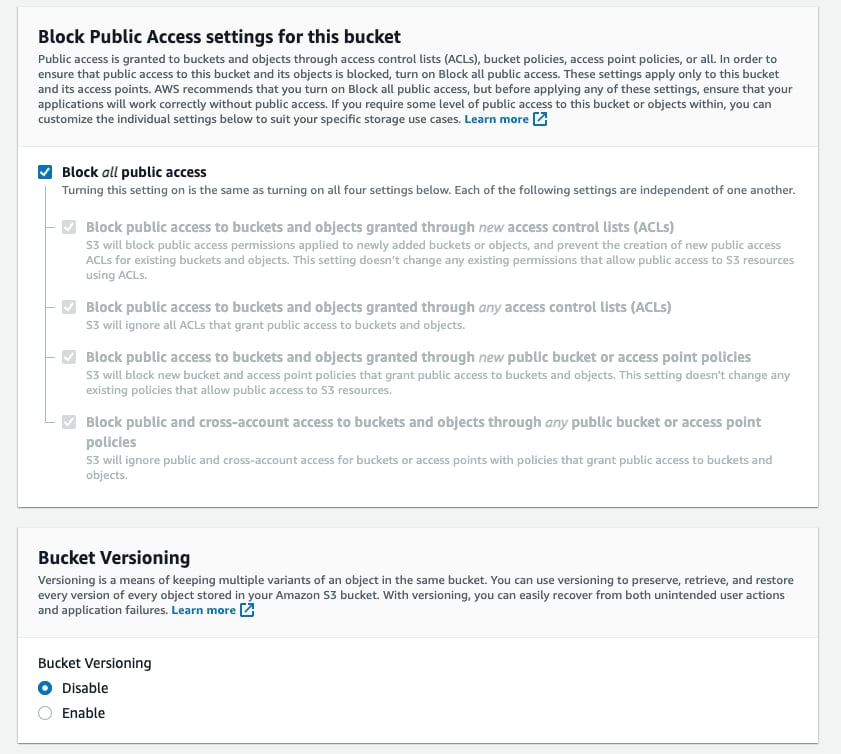
- 保持
Block all Public Access处于启用状态;无需公网访问。
- 在页面底部选择
Create Bucket
- 点击该链接,复制 ARN,并将其保存起来,以便在为存储桶配置访问策略时使用。
- 创建存储桶后,在 S3 存储桶列表中找到新的 S3 存储桶并点击该链接
- 选择
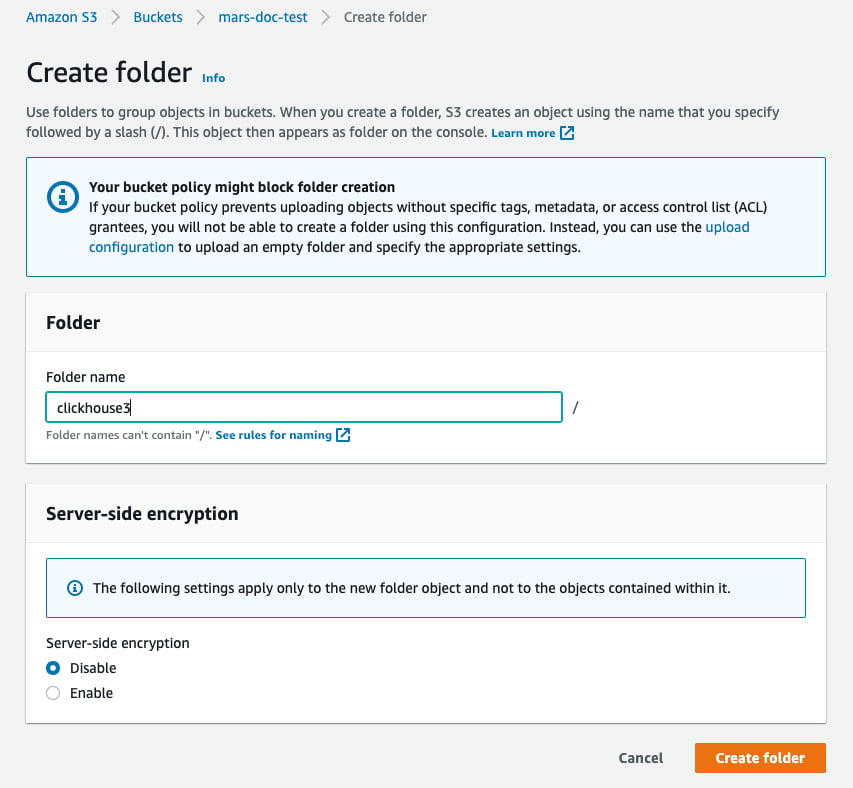
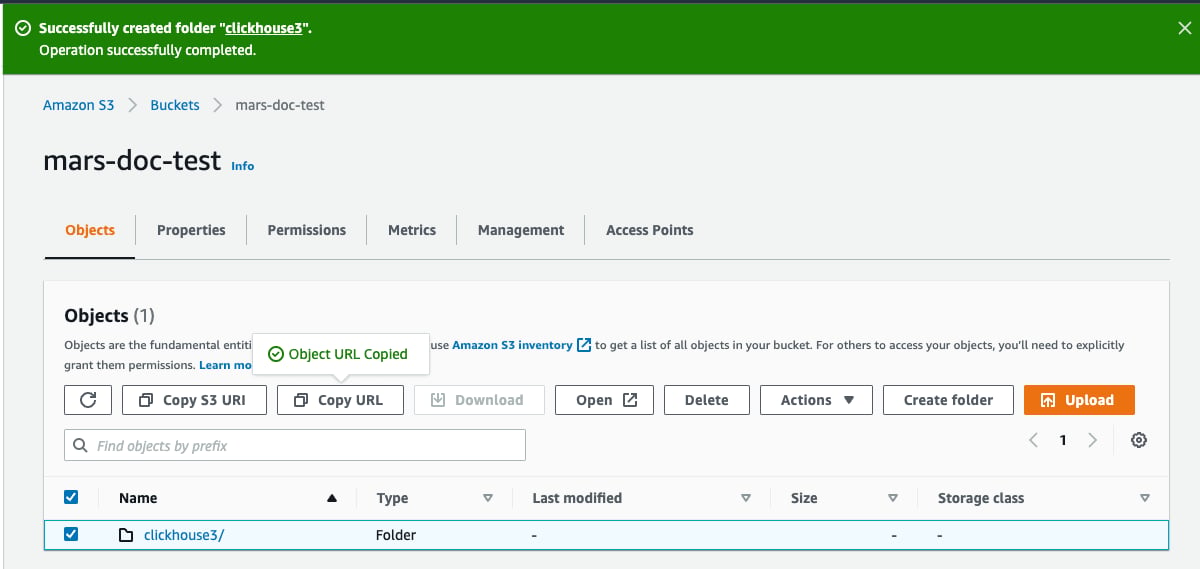
Create folder
- 输入一个文件夹名称,作为 ClickHouse S3 磁盘的目标文件夹,然后选择
Create folder
- 现在应可在存储桶列表中看到该文件夹
- 选中新建文件夹的复选框,然后点击
Copy URL。保存复制的 URL,以便在下一节的 ClickHouse 存储配置中使用。
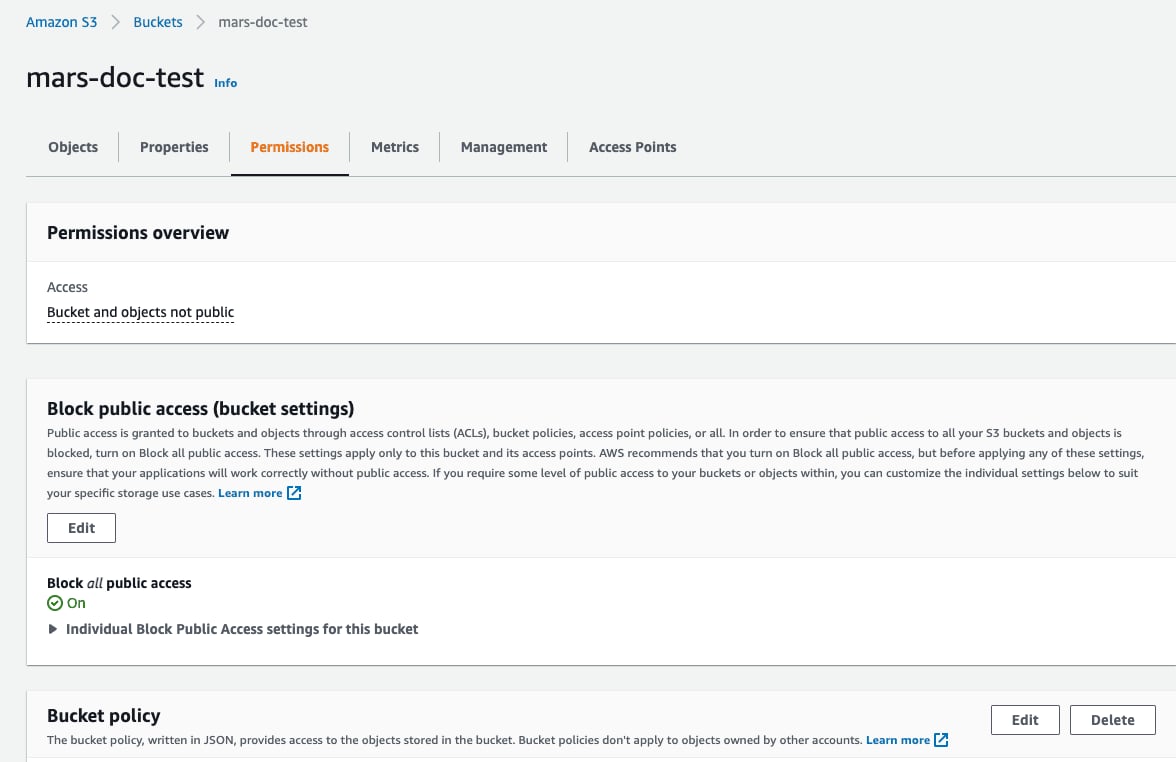
- 选择
Permissions选项卡,然后在Bucket Policy部分点击Edit按钮
- 添加存储桶策略,示例如下:
你应与安全团队协作,确定应使用哪些权限;这些内容可作为起点。
有关策略和设置的更多信息,请参阅 AWS 文档:
https://docs.aws.amazon.com/AmazonS3/latest/userguide/access-policy-language-overview.html
- 保存策略配置。
/etc/clickhouse-server/config.d/ 中。以下是其中一个存储桶的配置文件样本;另一个与其类似,只有高亮的三行不同:
/etc/clickhouse-server/config.d/storage_config.xml
本指南中的许多步骤都会要求你将配置文件放到
/etc/clickhouse-server/config.d/ 中。这是 Linux 系统中用于存放配置覆盖文件的默认位置。将这些文件放入该目录后,ClickHouse 会使用其中的内容覆盖默认配置。把这些文件放在该覆盖目录中,可以避免在升级时丢失配置。配置 ClickHouse Keeper
/etc/clickhouse-keeper/keeper_config.xml。3 个 Keeper server 使用相同的配置,只有一个设置项不同:<server_id>。
server_id 表示为使用该 configuration file 的主机分配的 ID。在下面的示例中,server_id 为 3,如果继续查看文件下方的 <raft_configuration> 部分,你会看到 server 3 的 hostname 是 keepernode3。ClickHouse Keeper 进程正是通过这种方式,在选举 leader 以及执行其他各项操作时,知道需要连接哪些其他 server。
/etc/clickhouse-keeper/keeper_config.xml
<server_id>) :
配置 ClickHouse 服务器
定义集群
<remote_servers> 部分中定义的。在此示例中,定义了一个集群 cluster_1S_2R,它由一个分片和两个副本组成。这两个副本分别位于主机 chnode1 和 chnode2 上。
/etc/clickhouse-server/config.d/remote-servers.xml
shard 和 replica 详细信息,即可指定使用复制表引擎。 创建表后,你可以通过查询 system.tables 查看 shard 和 replica 宏是如何使用的。
/etc/clickhouse-server/config.d/macros.xml
上述宏用于
chnode1;在 chnode2 上,请将 replica 设置为 replica_2。禁用 zero-copy 复制
allow_remote_fs_zero_copy_replication 默认值为 true。在此灾难恢复场景下,应将该设置设为 false;而在 22.8 及更高版本中,其默认值已为 false。
该设置应设为 false,原因有二:1) 此功能尚未达到生产可用状态;2) 在灾难恢复场景中,数据和元数据都需要存储在多个区域。将 allow_remote_fs_zero_copy_replication 设为 false。
/etc/clickhouse-server/config.d/remote-servers.xml
/etc/clickhouse-server/config.d/use_keeper.xml
配置网络
/etc/clickhouse-server/config.d/。下面是一个示例,用于将 ClickHouse 和 ClickHouse Keeper 配置为监听所有 IPv4 接口。有关更多信息,请参阅文档或默认配置文件 /etc/clickhouse/config.xml。
/etc/clickhouse-server/config.d/networking.xml
启动各服务器
运行 ClickHouse Keeper
检查 ClickHouse Keeper 状态
netcat 向 ClickHouse Keeper 发送命令。例如,mntr 会返回 ClickHouse Keeper 集群的状态。如果你在每个 Keeper 节点上运行该命令,就会看到其中一个是 leader,另外两个是跟随者:
启动 ClickHouse 服务器
验证 ClickHouse 服务器
-
验证集群是否存在:
-
使用
ReplicatedMergeTree表引擎在集群中创建表: -
了解前面定义的宏的用途
宏
shard和replica已在前文中定义,在下面高亮显示的这一行中,你可以看到这些值在每个 ClickHouse 节点上是如何被替换的。此外,这里还使用了uuid;uuid不在宏定义中,因为它是由系统生成的。
你可以通过设置
default_replica_path 和 default_replica_name,自定义上面显示的 ZooKeeper 路径 'clickhouse/tables/{uuid}/{shard}。相关文档见这里。测试
-
添加纽约市出租车数据集中的数据:
-
验证数据已存储在 S3 中。
此查询会显示磁盘上数据的大小,以及用于确定使用哪个磁盘的存储策略。
检查本地磁盘上的数据大小。根据上面的信息,存储的数百万行数据在磁盘上的大小为 36.42 MiB。这些数据应存储在 S3 上,而不是本地磁盘。上面的查询还会告诉我们数据和元数据在本地磁盘上的存储位置。检查本地数据:检查每个 S3 存储桶中的数据 (这里未显示总量,但插入后两个存储桶中都大约存储了 36 MiB):
S3Express
S3Express 将数据存储在单个可用区内。这意味着如果该可用区发生故障,数据将无法访问。
S3 磁盘
- 创建一个
Directory类型的存储桶 - 配置合适的存储桶策略,为你的 S3 用户授予所有必需的权限 (例如,使用
"Action": "s3express:*"可直接允许不受限制的访问) - 配置存储策略时,请提供
region参数
S3 存储
Object URL 路径。示例: