从 Redshift 迁移数据到 ClickHouse
相关内容
简介
Amazon Redshift 是一个流行的云数据仓库解决方案,属于 Amazon Web Services 的一部分。本指南介绍了将数据从 Redshift 实例迁移到 ClickHouse 的不同方法。我们将介绍三种选项:
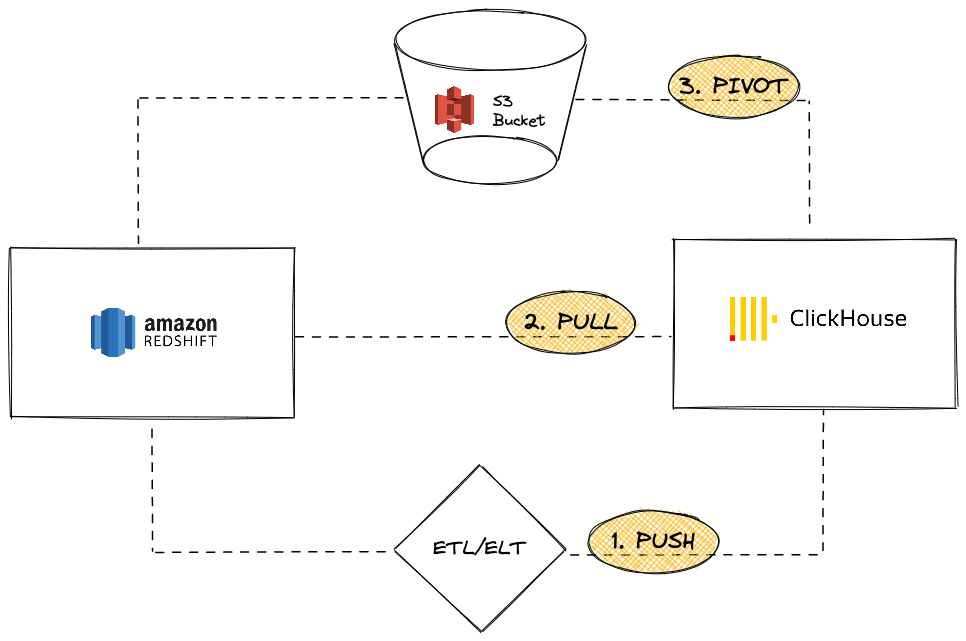
从 ClickHouse 实例的角度来看,您可以选择:
-
推送 数据到 ClickHouse,通过第三方 ETL/ELT 工具或服务
-
拉取 数据从 Redshift,利用 ClickHouse JDBC Bridge
-
使用 S3 进行转换,使用“卸载然后加载”的逻辑
我们在本教程中使用 Redshift 作为数据源。然而,这里提出的迁移方法并不专属于 Redshift,类似的步骤可以适用于任何兼容的数据源。
从 Redshift 推送数据到 ClickHouse
在推送场景中,目的是利用第三方工具或服务(自定义代码或ETL/ELT)将您的数据发送到 ClickHouse 实例中。例如,您可以使用软件 Airbyte 将数据在 Redshift 实例(作为源)和 ClickHouse(作为目的地)之间移动(请参阅我们的 Airbyte 集成指南)

优点
- 可以利用 ETL/ELT 软件现有的连接器目录。
- 内置的能力保持数据同步(附加/覆盖/增量逻辑)。
- 使数据转换场景成为可能(例如,参见我们的 dbt 集成指南)。
缺点
- 用户需要设置和维护 ETL/ELT 基础设施。
- 在架构中引入了第三方元素,可能成为潜在的可扩展性瓶颈。
从 Redshift 拉取数据到 ClickHouse
在拉取场景中,目的是利用 ClickHouse JDBC Bridge 直接连接到 Redshift 集群,并执行 INSERT INTO ... SELECT 查询:

优点
- 通用所有 JDBC 兼容工具
- 允许从 ClickHouse 内部优雅地查询多个外部数据源的解决方案
缺点
- 需要一个 ClickHouse JDBC Bridge 实例,这可能成为潜在的可扩展性瓶颈
尽管 Redshift 基于 PostgreSQL,但由于 ClickHouse 需要 PostgreSQL 9 及以上版本,而 Redshift API 基于较早版本(8.x),使用 ClickHouse PostgreSQL 表函数或表引擎是不可能的。
教程
要使用此选项,您需要设置一个 ClickHouse JDBC Bridge。ClickHouse JDBC Bridge 是一个独立的 Java 应用程序,处理 JDBC 连接性,并充当 ClickHouse 实例与数据源之间的代理。在本教程中,我们使用了一个用 示例数据库 预填充的 Redshift 实例。
- 部署 ClickHouse JDBC Bridge。有关更多详细信息,请参阅我们关于 外部数据源的 JDBC 用户指南
如果您使用 ClickHouse Cloud,您需要在单独的环境中运行 ClickHouse JDBC Bridge,并使用 remoteSecure 函数连接到 ClickHouse Cloud
- 配置 ClickHouse JDBC Bridge 的 Redshift 数据源。例如,
/etc/clickhouse-jdbc-bridge/config/datasources/redshift.json
- 一旦 ClickHouse JDBC Bridge 部署并运行,您可以开始从 ClickHouse 查询您的 Redshift 实例
- 接下来,我们展示使用
INSERT INTO ... SELECT语句导入数据
使用 S3 从 Redshift 进行数据转换到 ClickHouse
在此场景中,我们将数据导出到 S3 中的中间转换格式,并在第二步中,从 S3 加载数据到 ClickHouse。
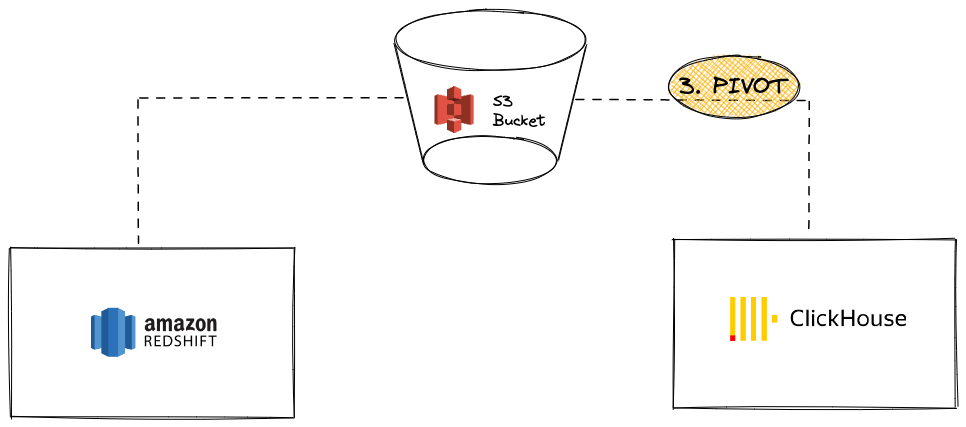
优点
- Redshift 和 ClickHouse 都具有强大的 S3 集成功能。
- 利用现有功能,如 Redshift 的
UNLOAD命令和 ClickHouse S3 表函数 / 表引擎。 - 由于 ClickHouse 对 S3 的并行读取和高吞吐能力,扩展无缝。
- 可以利用复杂和压缩的格式,如 Apache Parquet。
缺点
- 过程中的两个步骤(从 Redshift 卸载然后加载到 ClickHouse)。
教程
-
使用 Redshift 的 UNLOAD 功能,将数据导出到现有的私有 S3 存储桶中:
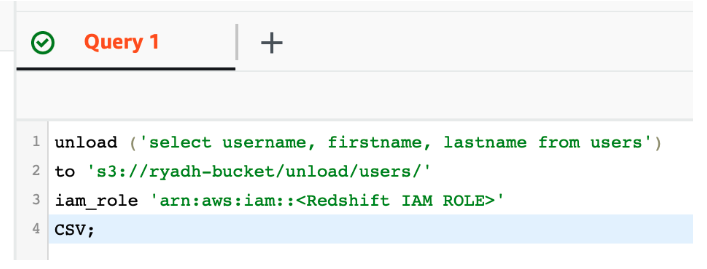
它将生成包含原始数据的部分文件在 S3 中

-
在 ClickHouse 中创建表:
或者,ClickHouse 可以尝试使用 CREATE TABLE ... EMPTY AS SELECT 来推断表结构:
当数据处于包含数据类型信息的格式(如 Parquet)时,这尤其有效。
- 使用
INSERT INTO ... SELECT语句将 S3 文件加载到 ClickHouse 中:
本示例使用 CSV 作为转换格式。然而,对于生产工作负载,我们建议 Apache Parquet 作为大规模迁移的最佳选择,因为它带有压缩功能,可以节省存储成本并缩短传输时间。(默认情况下,每个行组使用 SNAPPY 进行压缩)。ClickHouse 还利用 Parquet 的列方向加速数据摄取。
