基于 ClickHouse Connect 的 Python 集成
介绍
ClickHouse Connect 是一个核心数据库驱动,为各类 Python 应用程序提供互操作能力。
- 主要接口是包
clickhouse_connect.driver中的Client对象。该核心包还包含若干用于与 ClickHouse 服务器通信的辅助类和实用函数,以及用于高级管理 INSERT 和 SELECT 查询的 “context” 实现。 clickhouse_connect.datatypes包为所有非实验性的 ClickHouse 数据类型提供基础实现及其子类。其主要功能是将 ClickHouse 数据在 ClickHouse “Native” 二进制列式格式之间进行序列化与反序列化,以实现 ClickHouse 与客户端应用之间最高效的传输。clickhouse_connect.cdriver包中的 Cython/C 类对一些最常见的序列化与反序列化进行了优化,相比纯 Python 实现可显著提升性能。- 包
clickhouse_connect.cc_sqlalchemy中提供了一个 SQLAlchemy dialect,它基于datatypes和dbi包构建。该实现支持 SQLAlchemy Core 功能,包括带有JOIN(INNER、LEFT OUTER、FULL OUTER、CROSS) 的SELECT查询、WHERE子句、ORDER BY、LIMIT/OFFSET、DISTINCT操作、带WHERE条件的轻量级DELETE语句、表反射,以及基础 DDL 操作 (CREATE TABLE、CREATE/DROP DATABASE) 。尽管它不支持高级 ORM 功能或高级 DDL 功能,但为在 ClickHouse 面向 OLAP 的数据库上运行的大多数分析型工作负载提供了强大的查询能力。 - 核心驱动和 ClickHouse Connect SQLAlchemy 实现是将 ClickHouse 连接到 Apache Superset 的首选方式。请使用
ClickHouse Connect数据库连接,或使用clickhousedbSQLAlchemy dialect 连接字符串。
本文档内容基于 clickhouse-connect 0.9.2 版本。
官方 ClickHouse Connect Python 驱动使用 HTTP 协议与 ClickHouse 服务器通信。这使其能够支持 HTTP 负载均衡器,并且在包含防火墙和代理的企业环境中运行良好,但与原生基于 TCP 的协议相比,其压缩率和性能略低,且不支持某些高级特性,例如查询取消。在某些使用场景下,可以考虑使用基于原生 TCP 协议的 社区 Python 驱动。
要求和兼容性
| Python | 平台¹ | ClickHouse | SQLAlchemy² | Apache Superset | Pandas | Polars | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2.x, <3.9 | ❌ | Linux (x86) | ✅ | <25.x³ | 🟡 | <1.4.40 | ❌ | <1.4 | ❌ | ≥1.5 | ✅ | 1.x | ✅ |
| 3.9.x | ✅ | Linux (Aarch64) | ✅ | 25.x³ | 🟡 | ≥1.4.40 | ✅ | 1.4.x | ✅ | 2.x | ✅ | ||
| 3.10.x | ✅ | macOS (x86) | ✅ | 25.3.x (LTS) | ✅ | ≥2.x | ✅ | 1.5.x | ✅ | ||||
| 3.11.x | ✅ | macOS (ARM) | ✅ | 25.6.x (Stable) | ✅ | 2.0.x | ✅ | ||||||
| 3.12.x | ✅ | Windows | ✅ | 25.7.x (Stable) | ✅ | 2.1.x | ✅ | ||||||
| 3.13.x | ✅ | 25.8.x (LTS) | ✅ | 3.0.x | ✅ | ||||||||
| 25.9.x (Stable) | ✅ |
¹ClickHouse Connect 已在上述列出的平台上进行了专门测试。此外,还针对优秀的 cibuildwheel 项目所支持的所有架构构建了未经测试的二进制 wheel 包(带 C 优化)。最后,由于 ClickHouse Connect 也可以以纯 Python 方式运行,其源码安装在任何较新的 Python 环境中都应能正常工作。
²SQLAlchemy 支持仅限于 Core 功能(查询、基础 DDL),不支持 ORM 功能。详情请参阅 SQLAlchemy 集成支持 文档。
³ClickHouse Connect 在官方支持范围之外的版本上通常也能良好运行。
安装
通过 pip 从 PyPI 安装 ClickHouse Connect:
pip install clickhouse-connect
ClickHouse Connect 也可以从源代码安装:
- 使用
git clone克隆 GitHub 仓库 - (可选)运行
pip install cython以构建并启用 C/Cython 优化 - 使用
cd切换到项目根目录并运行pip install .
支持策略
在报告任何问题之前,请先升级到最新版本的 ClickHouse Connect。请在 GitHub 项目 中提交问题。ClickHouse Connect 的后续版本会尽量与发布时仍处于主动支持状态的 ClickHouse 版本保持兼容。当前处于主动支持状态的 ClickHouse 服务器版本列表见此处。如果不确定应使用哪个版本的 ClickHouse 服务器,请阅读此处的讨论。我们的 CI 测试矩阵会针对最新的两个 LTS 版本和最新的三个稳定版本进行测试。不过,由于使用 HTTP 协议且 ClickHouse 各发行版本之间的破坏性变更极少,ClickHouse Connect 通常在超出官方支持范围的服务器版本上也能正常工作,但对某些高级数据类型的兼容性可能会有所差异。
基本用法
收集连接信息
要通过 HTTP(S) 连接到 ClickHouse,您需要以下信息:
| 参数 | 说明 |
|---|---|
HOST 和 PORT | 通常,在使用 TLS 时端口为 8443,不使用 TLS 时端口为 8123。 |
DATABASE NAME | 默认提供一个名为 default 的数据库,请填写您要连接的目标数据库名称。 |
USERNAME 和 PASSWORD | 默认用户名为 default。请使用适合您使用场景的用户名。 |
您的 ClickHouse Cloud 服务的详细信息可以在 ClickHouse Cloud 控制台中查看。 选择某个服务并点击 Connect:
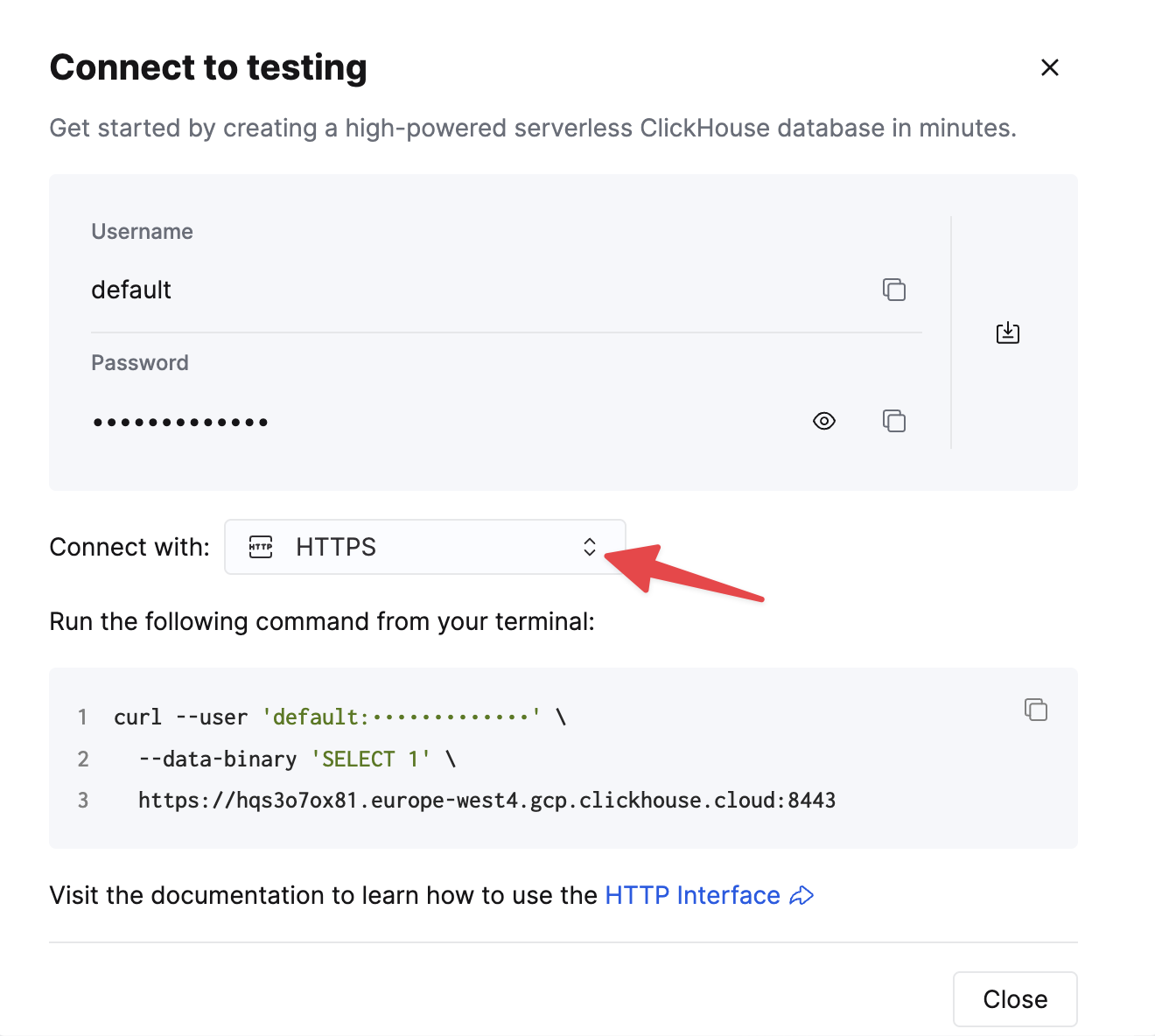
选择 HTTPS。连接信息会显示在示例 curl 命令中。
如果您使用的是自托管 ClickHouse,则连接信息由您的 ClickHouse 管理员进行设置。
建立连接
如下示例演示了两种连接 ClickHouse 的方式:
- 连接到本地主机上的 ClickHouse 服务器。
- 连接到 ClickHouse Cloud 服务。
使用 ClickHouse Connect 客户端实例连接到本地 ClickHouse 服务器:
使用 ClickHouse Connect 客户端实例连接到 ClickHouse Cloud 服务:
使用之前获取的连接信息。ClickHouse Cloud 服务需要 TLS,因此请使用端口 8443。
与数据库交互
要执行 ClickHouse SQL 命令,请使用客户端的 command 方法:
要插入批量数据,请使用客户端 insert 方法,并传入一个由多行及其对应值组成的二维数组:
要通过 ClickHouse SQL 查询数据,请使用客户端的 query 方法:
