JDBC connector
仅当你的数据较为简单且只包含基础数据类型 (例如 int) 时才应使用此 connector。像 ClickHouse 特有的 map 等类型目前不受支持。
在下面的示例中,我们使用的是 Confluent 发行版的 Kafka Connect。
下面我们介绍一个简单的部署:从单个 Kafka topic 中拉取消息,并将行插入到 ClickHouse 表中。对于尚未拥有 Kafka 环境的用户,我们推荐使用 Confluent Cloud,它的免费层额度相当可观。
请注意,JDBC Connector 需要 schema (不能在 JDBC Connector 中直接使用原始 JSON 或 CSV) 。虽然可以在每条消息中携带 schema,但强烈建议使用 Confluent schema registry 以避免相关开销。我们提供的插入脚本会从消息中自动推断 schema 并将其写入 registry——因此该脚本可以复用于其他数据集。Kafka 的 key 假定为字符串 (String) 。关于 Kafka schema 的更多细节参见这里。
License
JDBC Connector 基于 Confluent Community License 进行分发。
Steps
Gather your connection details
要通过 HTTP(S) 连接到 ClickHouse,您需要以下信息:
| 参数 | 说明 |
|---|---|
HOST 和 PORT | 通常,在使用 TLS 时端口为 8443,不使用 TLS 时端口为 8123。 |
DATABASE NAME | 默认提供一个名为 default 的数据库,请填写您要连接的目标数据库名称。 |
USERNAME 和 PASSWORD | 默认用户名为 default。请使用适合您使用场景的用户名。 |
您的 ClickHouse Cloud 服务的详细信息可以在 ClickHouse Cloud 控制台中查看。 选择某个服务并点击 Connect:
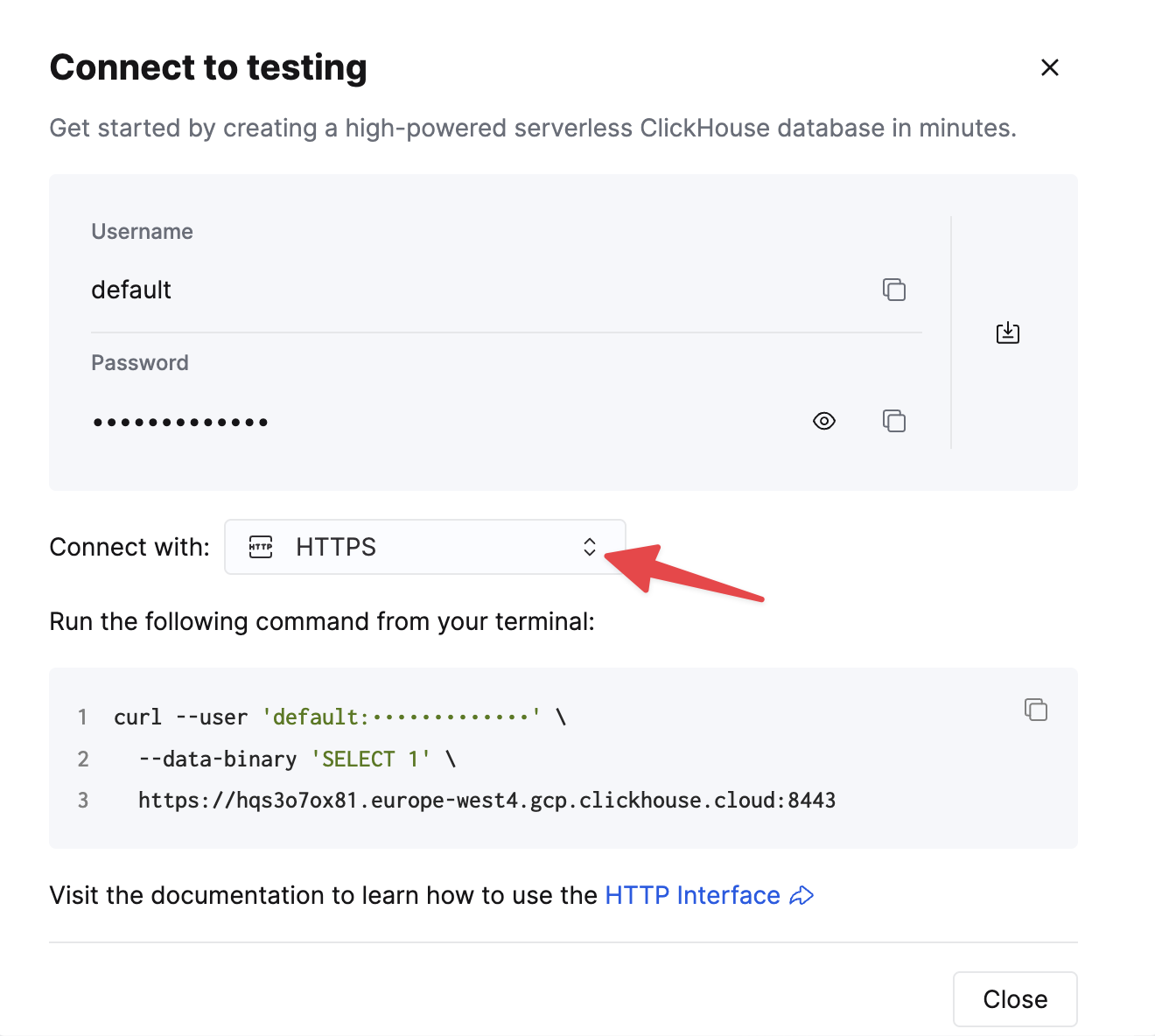
选择 HTTPS。连接信息会显示在示例 curl 命令中。
如果您使用的是自托管 ClickHouse,则连接信息由您的 ClickHouse 管理员进行设置。
1. Install Kafka Connect and Connector
我们假设你已经下载了 Confluent 安装包并在本地完成安装。请按照这里文档中关于安装 connector 的步骤进行操作。
如果你使用 confluent-hub 的安装方式,你的本地配置文件将会被更新。
要将数据从 Kafka 发送到 ClickHouse,我们使用 connector 的 Sink 组件。
2. Download and install the JDBC Driver
从这里下载并安装 ClickHouse JDBC driver clickhouse-jdbc-<version>-shaded.jar。然后按照这里中的说明将其安装到 Kafka Connect 中。其他驱动可能也能工作,但尚未经过测试。
常见问题:文档建议将 jar 复制到 share/java/kafka-connect-jdbc/。如果你遇到 Connect 无法找到 driver 的问题,请将 driver 复制到 share/confluent-hub-components/confluentinc-kafka-connect-jdbc/lib/。或者修改 plugin.path 将该 driver 包含进去——见下文。
3. Prepare configuration
请按照这些说明配置适合你安装类型的 Connect,同时注意 standalone 模式与分布式集群之间的差异。如果使用 Confluent Cloud,则应采用分布式部署方式。
下列参数与在 ClickHouse 中使用 JDBC connector 相关。完整参数列表请参见此处:
_connection.url_- 应采用jdbc:clickhouse://<clickhouse host>:<clickhouse http port>/<target database>的形式connection.user- 对目标数据库具有写权限的用户table.name.format- 用于插入数据的 ClickHouse 表。该表必须已存在。batch.size- 单个批次中发送的行数。请确保将其设置为足够大的数值。根据 ClickHouse 的建议,1000 应被视为最小值。tasks.max- JDBC Sink connector 支持运行一个或多个任务,可用于提升性能。结合批大小,这是提升性能的主要手段。value.converter.schemas.enable- 如果使用 schema registry,则设置为 false;如果将 schema 嵌入到消息中,则设置为 true。value.converter- 根据你的数据类型进行设置,例如对 JSON 使用io.confluent.connect.json.JsonSchemaConverter。key.converter- 设置为org.apache.kafka.connect.storage.StringConverter。我们使用字符串类型的 key。pk.mode- 与 ClickHouse 无关,设置为 none。auto.create- 不支持,必须为 false。auto.evolve- 我们建议将此设置为 false,尽管未来可能会提供支持。insert.mode- 设置为 "insert"。当前不支持其他模式。key.converter- 根据 key 的类型进行设置。value.converter- 根据 topic 中数据的类型进行设置。该数据必须具有受支持的 schema——JSON、Avro 或 Protobuf 格式。
如果使用我们的示例数据集进行测试,请确保如下设置:
value.converter.schemas.enable- 设置为 false,因为我们使用 schema registry。如果你在每条消息中嵌入 schema,则设置为 true。key.converter- 设置为 "org.apache.kafka.connect.storage.StringConverter"。我们使用字符串类型的 key。value.converter- 设置为 "io.confluent.connect.json.JsonSchemaConverter"。value.converter.schema.registry.url- 设置为 schema server 的 URL,并通过参数value.converter.schema.registry.basic.auth.user.info配置访问 schema server 的凭据。
适用于 GitHub 示例数据的配置文件示例可在此处找到,假定 Connect 以 standalone 模式运行且 Kafka 部署在 Confluent Cloud 上。
4. 创建 ClickHouse 表
确保该表已创建,如果在之前的示例中已经存在,请先将其删除。下面展示了一个与精简版 GitHub 数据集兼容的示例。注意,这里没有包含当前尚不受支持的任何 Array 或 Map 类型:
5. 启动 Kafka Connect
以 standalone 或 distributed 模式启动 Kafka Connect。
6. 向 Kafka 添加数据
使用提供的脚本和配置向 Kafka 插入消息。您需要修改 github.config 并填入您的 Kafka 凭证。该脚本目前已配置为在 Confluent Cloud 上使用。
此脚本可用于将任意 ndjson 文件写入到 Kafka 主题中。脚本会尝试自动为你推断 schema。提供的示例配置只会插入 10k 条消息——如有需要请在此修改。该配置还会在写入 Kafka 时,从数据集中移除任何不兼容的 Array 字段。
这是 JDBC connector 将消息转换为 INSERT 语句所必需的。如果你使用自己的数据,请确保要么在每条消息中都附带 schema(将 _value.converter.schemas.enable 设置为 true),要么确保你的客户端发布的消息引用注册表中的 schema。
Kafka Connect 随后会开始消费消息并向 ClickHouse 中插入数据行。请注意,关于“[JDBC Compliant Mode] Transaction isn't supported.”的警告是预期行为,可以忽略。
对目标表 “Github” 执行一次简单的读取查询,即可确认数据是否已成功插入。
