Dataflow BigQuery 到 ClickHouse 模板
BigQuery 到 ClickHouse 模板是一个批处理管道,用于将 BigQuery 表中的数据摄取到 ClickHouse 表。 该模板既可以读取整个表,也可以使用提供的 SQL 查询来过滤特定记录。
管道要求
- 源 BigQuery 表必须已存在。
- 目标 ClickHouse 表必须已存在。
- 必须能从 Dataflow 工作器实例访问 ClickHouse 主机。
模板参数
| 参数名称 | 参数说明 | 是否必填 | 备注 |
|---|---|---|---|
jdbcUrl | ClickHouse JDBC URL,格式为 jdbc:clickhouse://<host>:<port>/<schema>。 | ✅ | 不要将用户名和密码作为 JDBC 选项添加。可以在 JDBC URL 末尾添加其他任意 JDBC 选项。对于 ClickHouse Cloud 用户,请在 jdbcUrl 中添加 ssl=true&sslmode=NONE。 |
clickHouseUsername | 用于身份验证的 ClickHouse 用户名。 | ✅ | |
clickHousePassword | 用于身份验证的 ClickHouse 密码。 | ✅ | |
clickHouseTable | 要插入数据的目标 ClickHouse 表。 | ✅ | |
maxInsertBlockSize | 插入时的最大块大小,当由我们控制插入块的创建时适用(ClickHouseIO 选项)。 | 这是一个 ClickHouseIO 选项。 | |
insertDistributedSync | 如果启用该设置,向 Distributed 表执行 INSERT 查询时,会在数据发送到集群中的所有节点后才完成。(ClickHouseIO 选项)。 | 这是一个 ClickHouseIO 选项。 | |
insertQuorum | 对复制表执行 INSERT 查询时,等待指定数量的副本完成写入,并对数据写入进行线性化。0 表示禁用。 | 这是一个 ClickHouseIO 选项。此设置在默认服务器配置中是禁用的。 | |
insertDeduplicate | 对复制表执行 INSERT 查询时,指定是否对插入块执行去重。 | 这是一个 ClickHouseIO 选项。 | |
maxRetries | 每次插入操作的最大重试次数。 | 这是一个 ClickHouseIO 选项。 | |
InputTableSpec | 要读取的 BigQuery 表。指定 inputTableSpec 或 query 之一。当二者都设置时,query 参数优先。示例:<BIGQUERY_PROJECT>:<DATASET_NAME>.<INPUT_TABLE>。 | 使用 BigQuery Storage Read API 直接从 BigQuery 存储中读取数据。请注意 Storage Read API 的限制。 | |
outputDeadletterTable | 用于存放未能写入输出表的消息的 BigQuery 表。如果该表不存在,会在管道执行期间创建。如果未指定,则使用 <outputTableSpec>_error_records。例如:<PROJECT_ID>:<DATASET_NAME>.<DEADLETTER_TABLE>。 | ||
query | 用于从 BigQuery 读取数据的 SQL 查询。如果 BigQuery 数据集所在的项目与 Dataflow 作业不同,请在 SQL 查询中指定完整的数据集名称,例如:<PROJECT_ID>.<DATASET_NAME>.<TABLE_NAME>。默认使用 GoogleSQL,除非将 useLegacySql 设为 true。 | 必须指定 inputTableSpec 或 query 之一。如果同时设置了这两个参数,模板会使用 query 参数。示例:SELECT * FROM sampledb.sample_table。 | |
useLegacySql | 设为 true 时使用传统 SQL(legacy SQL)。该参数仅在使用 query 参数时生效。默认为 false。 | ||
queryLocation | 在没有底层表权限、而是通过授权视图(authorized view)读取时所需的位置。例如:US。 | ||
queryTempDataset | 设置一个已存在的数据集,用于创建存储查询结果的临时表。例如:temp_dataset。 | ||
KMSEncryptionKey | 当使用 query 作为数据源从 BigQuery 读取时,使用此 Cloud KMS 密钥对创建的任何临时表进行加密。例如:projects/your-project/locations/global/keyRings/your-keyring/cryptoKeys/your-key。 |
所有 ClickHouseIO 参数的默认值可在 ClickHouseIO Apache Beam Connector 中找到。
源表与目标表的模式
为了高效地将 BigQuery 数据集加载到 ClickHouse 中,流水线会执行列推断流程,该流程包含以下阶段:
- 模板会基于目标 ClickHouse 表构建一个 schema 对象。
- 模板会遍历 BigQuery 数据集,并尝试根据列名匹配列。
因此,BigQuery 数据集(无论是表还是查询)中的列名必须与 ClickHouse 目标表完全相同。
数据类型映射
BigQuery 类型会根据 ClickHouse 表的定义进行转换。因此,上表列出了在目标 ClickHouse 表中(针对给定的 BigQuery 表/查询)推荐使用的映射关系:
| BigQuery Type | ClickHouse Type | Notes |
|---|---|---|
| Array Type | Array Type | 内部类型必须是此表中列出的受支持基础数据类型之一。 |
| Boolean Type | Bool Type | |
| Date Type | Date Type | |
| Datetime Type | Datetime Type | 同样适用于 Enum8、Enum16 和 FixedString。 |
| String Type | String Type | 在 BigQuery 中,所有 Int 类型(INT、SMALLINT、INTEGER、BIGINT、TINYINT、BYTEINT)都是 INT64 的别名。建议在 ClickHouse 中为列设置合适的整数宽度,因为模板会根据定义的列类型(Int8、Int16、Int32、Int64)来转换列。 |
| Numeric - Integer Types | Integer Types | 在 BigQuery 中,所有 Int 类型(INT、SMALLINT、INTEGER、BIGINT、TINYINT、BYTEINT)都是 INT64 的别名。建议在 ClickHouse 中为列设置合适的整数宽度,因为模板会根据定义的列类型(Int8、Int16、Int32、Int64)来转换列。如果在 ClickHouse 表中使用了无符号 Int 类型(UInt8、UInt16、UInt32、UInt64),模板也会对其进行转换。 |
| Numeric - Float Types | Float Types | 支持的 ClickHouse 类型:Float32 和 Float64 |
运行模板
BigQuery 到 ClickHouse 模板可以通过 Google Cloud CLI 执行。
请务必通读本文档,尤其是上面的章节,以充分了解该模板的配置要求和前置条件。
- Google Cloud 控制台
- Google Cloud CLI
登录 Google Cloud 控制台并搜索 Dataflow。
- 点击
CREATE JOB FROM TEMPLATE按钮
- 模板表单打开后,输入作业名称并选择目标区域(region)。
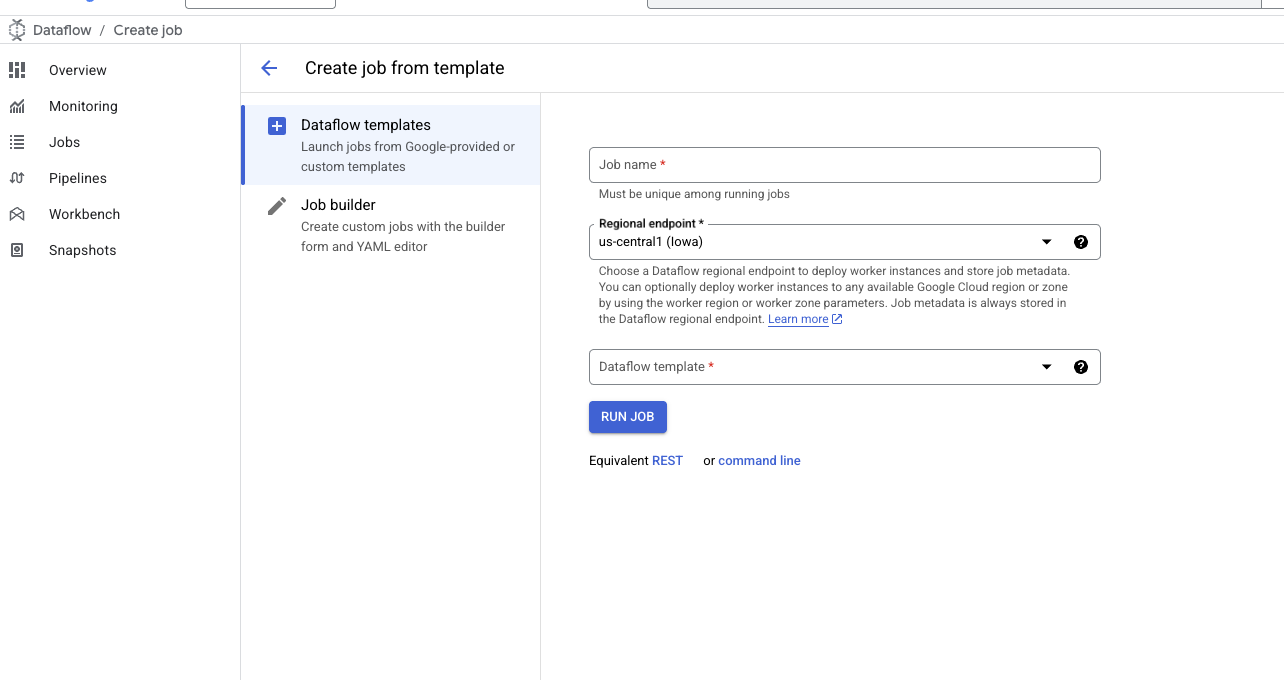
- 在
DataFlow Template输入框中输入ClickHouse或BigQuery,并选择BigQuery to ClickHouse模板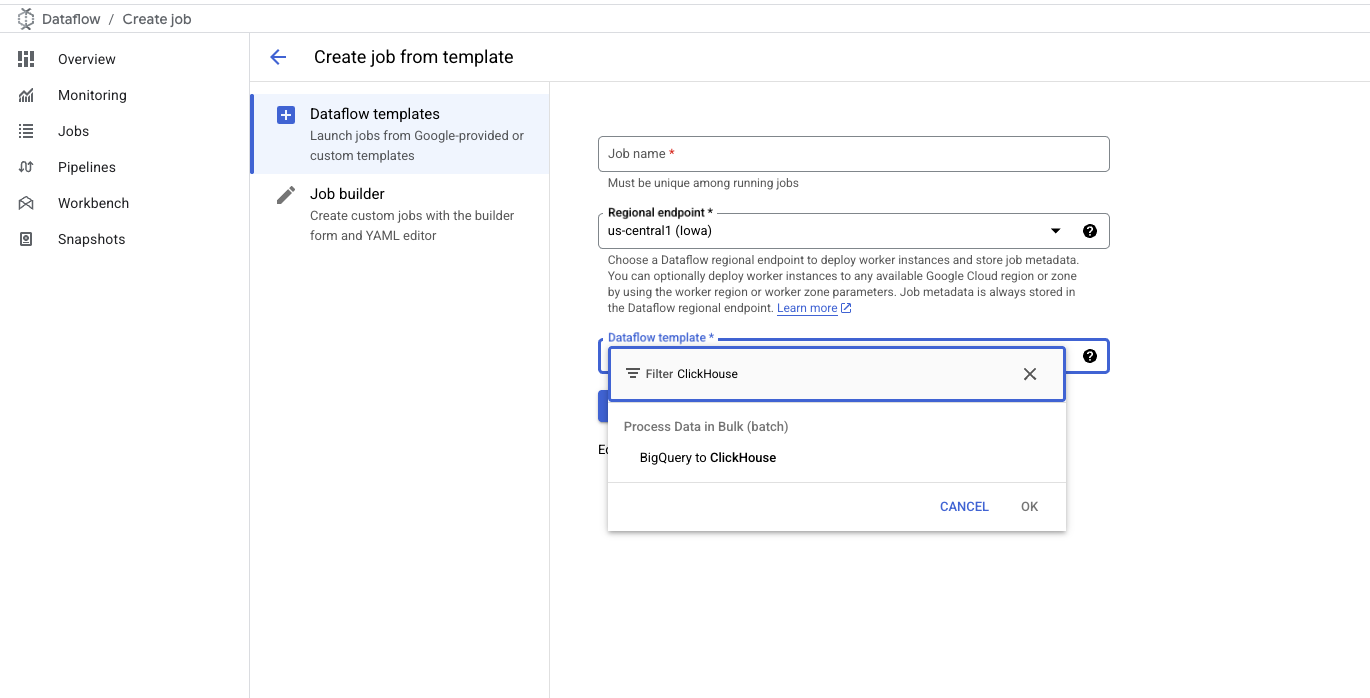
- 选择后,表单会展开,允许你提供更多详细信息:
- ClickHouse 服务器 JDBC URL,格式为
jdbc:clickhouse://host:port/schema。 - ClickHouse 用户名。
- ClickHouse 目标表名。
- ClickHouse 服务器 JDBC URL,格式为
ClickHouse 密码选项被标记为可选,适用于未配置密码的场景。
如需添加,请向下滚动至 Password for ClickHouse Endpoint 选项。
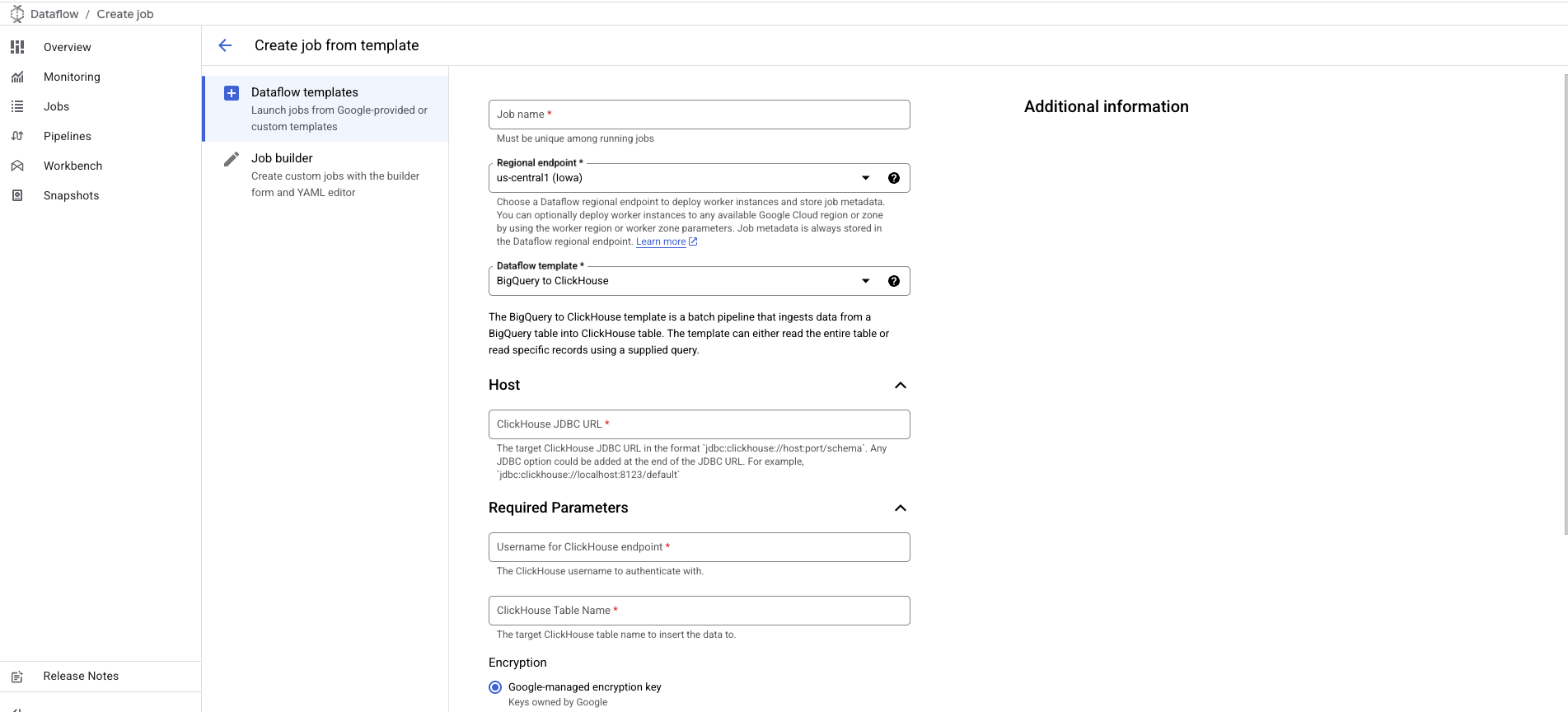
- 根据需要自定义并添加任何与 BigQuery/ClickHouseIO 相关的配置,具体见 模板参数 部分。
安装并配置 gcloud CLI
- 如果尚未安装,请安装
gcloudCLI。 - 按照
本指南
中的
Before you begin部分,完成运行 Dataflow 模板所需的配置、设置和权限。
运行命令
使用 gcloud dataflow flex-template run
命令来运行使用 Flex Template 的 Dataflow 作业。
下面是该命令的示例:
命令解析
- 作业名称(Job Name):
run关键字后面的文本是唯一的作业名称。 - 模板文件(Template File): 由
--template-file-gcs-location指定的 JSON 文件定义了模板结构以及可接受参数的详细信息。上述文件路径是公开的,可直接使用。 - 参数(Parameters): 参数之间用逗号分隔。对于字符串类型的参数,请使用双引号包裹参数值。
预期响应
运行命令后,你应会看到类似如下的响应:
监控作业
在 Google Cloud 控制台中导航到 Dataflow Jobs 选项卡,以监控作业状态。你可以查看作业详情,包括进度和任何错误信息:
监控作业
在 Google Cloud 控制台中导航到 Dataflow Jobs 选项卡,以监控作业状态。你可以查看作业详情,包括进度和任何错误信息:

疑难解答
内存总量限制超出错误(代码 241)
当 ClickHouse 在处理大批量数据时内存耗尽,就会出现此错误。要解决此问题:
- 增加实例资源:将 ClickHouse 服务器升级为具有更多内存的更大实例,以应对数据处理负载。
- 减小批大小:在 Dataflow 作业配置中调整批大小,以较小的数据块发送到 ClickHouse,从而降低每个批次的内存消耗。这些更改有助于在数据摄取过程中平衡资源使用。
模板源代码
该模板的源代码可在以下位置获取:
GoogleCloudPlatform/DataflowTemplates— 上游 Google Cloud Platform 仓库。ClickHouse/DataflowTemplates— ClickHouse 的派生仓库 (fork) 。
