如果您在 Google Cloud 上使用 ClickHouse Cloud,则本页不适用,因为您的服务已在使用 Google Cloud Storage。如果您想从 GCS
SELECT 或向 GCS INSERT 数据,请参阅 gcs 表函数。基于 GCS 的 MergeTree
创建磁盘
conf.d 下的某个文件中,在 ClickHouse 配置里声明它。下面展示了一个 GCS 磁盘声明示例。此配置包含多个部分,分别用于配置 GCS“磁盘”、缓存,以及在需要在 GCS 磁盘上创建表时在 DDL queries 中指定的策略。下面将分别介绍这些部分。
存储配置 > disks > gcs
- 磁盘类型为
s3,因为这里使用的是 S3 API。 - GCS 提供的端点
- 服务账号的 HMAC 密钥和 secret
- 本地磁盘上的元数据路径
存储配置 > disks > cache
gcs 磁盘启用 10Gi 的内存缓存。
存储配置 > 策略 > gcs_main
gcs_main,允许将数据存储在磁盘 gcs 上。例如:CREATE TABLE ... SETTINGS storage_policy='gcs_main'。
创建表
system.processes 表查看进度。你也可以将行数提高到 1000 万的上限,并尝试运行一些示例查询。
实现复制
ReplicatedMergeTree 表引擎实现复制。详情请参阅使用 GCS 在两个 GCP 区域间复制单个分片指南。
了解更多
使用 Google Cloud Storage (GCS)
规划部署
- 两个 ClickHouse 服务器 节点,位于两个 GCP 区域
- 两个 GCS 存储桶,部署在与这两个 ClickHouse 服务器 节点相同的区域
- 三个 ClickHouse Keeper 节点,其中两个部署在与 ClickHouse 服务器 节点相同的区域。第三个可以与前两个 Keeper 节点中的一个位于同一区域,但需处于不同的可用区。
准备虚拟机
* 这也可以是在与 1 或 2 相同区域内的另一个可用区。
部署 ClickHouse
chnode1 和 chnode2。
将 chnode1 放在一个 GCP 区域中,将 chnode2 放在另一个区域中。本指南中,Compute Engine 虚拟机和 GCS 存储桶分别使用 us-east1 和 us-east4。
在完成配置之前,不要启动
clickhouse server,只需先安装即可。部署 ClickHouse Keeper
keepernode1、keepernode2 和 keepernode3。keepernode1 可部署在与 chnode1 相同的区域,keepernode2 可与 chnode2 部署在同一区域,keepernode3 则可部署在任一区域,但需与该区域中的 ClickHouse 节点位于不同的可用区。
在 ClickHouse Keeper 节点上执行部署步骤时,请参阅安装说明。
创建两个存储桶
us-east1 和 us-east4。这些存储桶均为单区域、标准存储类别,且不公开。出现提示时,请启用公共访问防护。不要创建文件夹;ClickHouse 在写入存储时会自动创建它们。
如果你需要创建存储桶和 HMAC 密钥的分步说明,请展开 创建 GCS 存储桶和 HMAC 密钥 并按步骤操作:
创建 GCS 存储桶和 HMAC 密钥
创建 GCS 存储桶和 HMAC 密钥
ch_bucket_us_east1
ch_bucket_us_east4
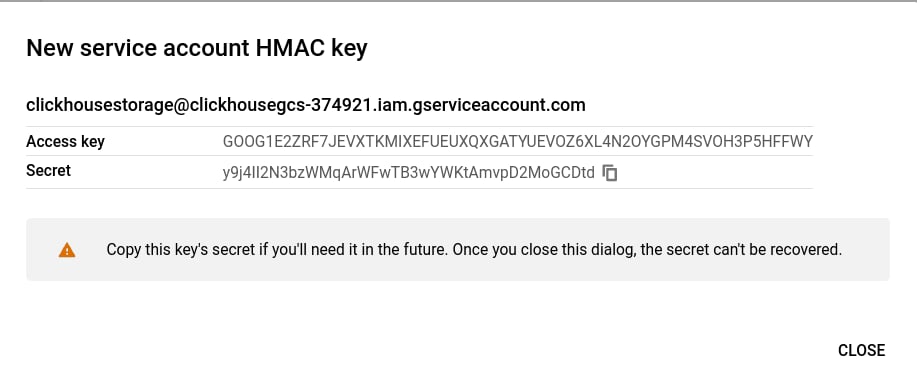
生成访问密钥
创建服务账号 HMAC 密钥和密钥值
打开 Cloud Storage > Settings > Interoperability,选择现有的 Access key,或选择 CREATE A KEY FOR A SERVICE ACCOUNT。本指南介绍的是为新的服务账号创建新密钥的流程。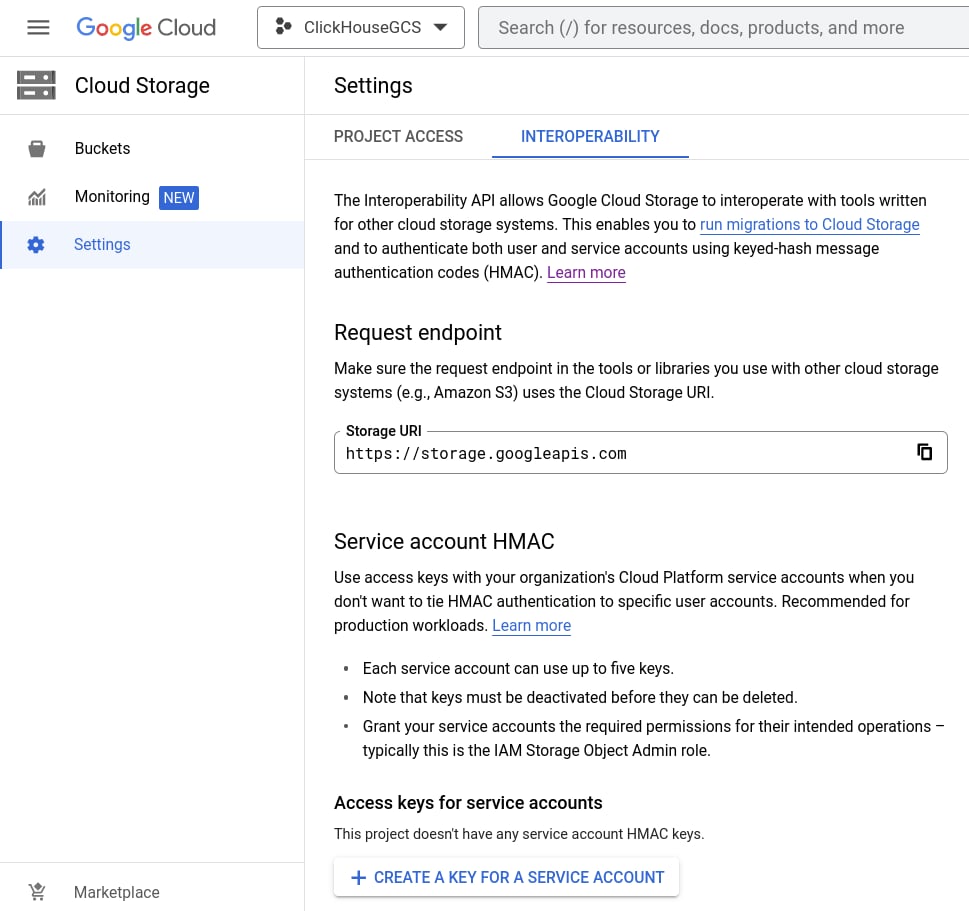
添加新的服务账号
如果该项目中还没有服务账号,请选择 CREATE NEW ACCOUNT。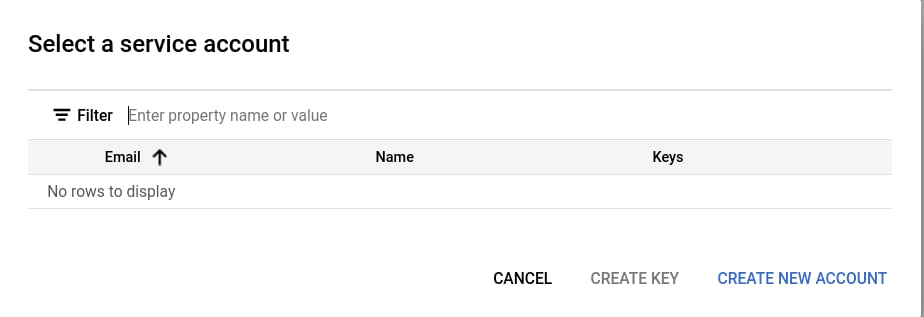
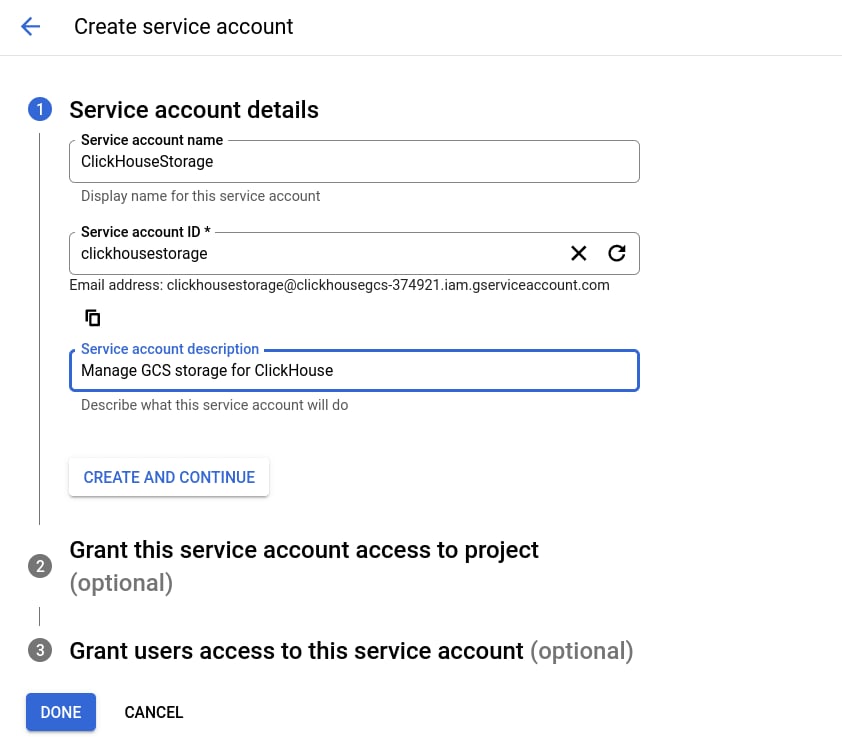
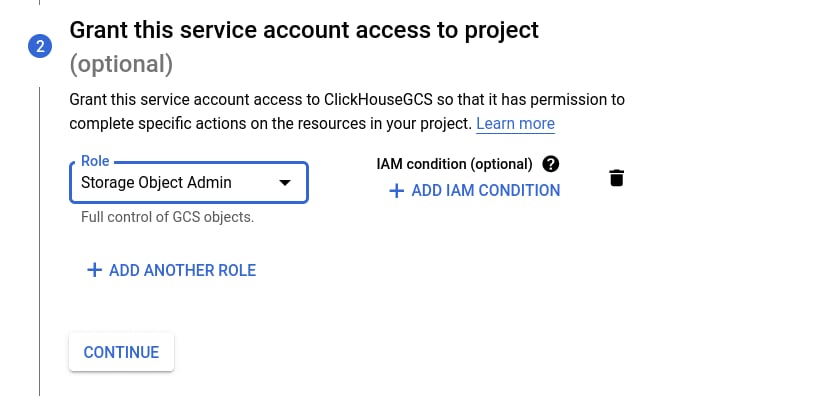
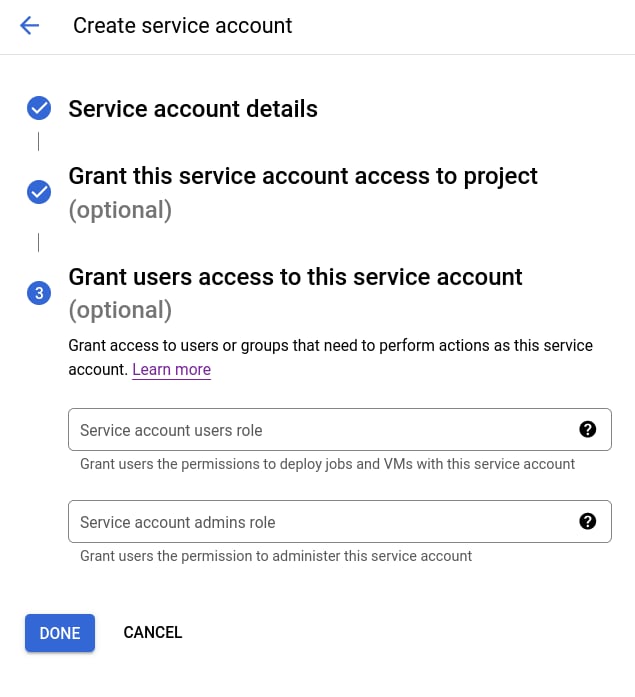
配置 ClickHouse Keeper
server_id 这一行 (下方第一处高亮的行) 外,所有 ClickHouse Keeper 节点的配置文件都相同。请将文件中的主机名替换为你的 ClickHouse Keeper 服务器主机名,并在每台服务器上将 server_id 设置为与 raft_configuration 中对应 server 条目一致的值。由于此示例中的 server_id 设为 3,我们在 raft_configuration 中高亮了对应的行。
- 用你的主机名编辑此文件,并确保这些主机名能够被 ClickHouse 服务器 节点和 Keeper 节点解析
- 将文件复制到相应位置 (每台 Keeper 服务器上的
/etc/clickhouse-keeper/keeper_config.xml) - 根据每台机器在
raft_configuration中的条目编号,修改其server_id
/etc/clickhouse-keeper/keeper_config.xml
配置 ClickHouse 服务器
最佳实践本指南中的某些步骤会要求你将配置文件放到
/etc/clickhouse-server/config.d/ 中。这是 Linux 系统中配置覆盖文件的默认位置。将这些文件放入该目录后,ClickHouse 会把其中的内容与默认配置合并。把这些文件放在 config.d 目录中,可以避免在升级时丢失配置。网络
/etc/clickhouse-server/config.d/network.xml
远程 ClickHouse Keeper 服务器
- 将主机名修改为与您的 Keeper 主机一致
/etc/clickhouse-server/config.d/use-keeper.xml
远程 ClickHouse 服务器
remote_servers 条目中添加 replace="true" 标签。这样,当此配置与默认配置合并时,它会替换 remote_servers 部分,而不是在其中追加内容。
- 用你的主机名编辑此文件,并确保这些主机名可从 ClickHouse 服务器节点解析
/etc/clickhouse-server/config.d/remote-servers.xml
副本标识
replica_1,而在另一台服务器上则应指定为 replica_2。这些名称可以更改;根据我们的示例,如果一个副本存储在南卡罗来纳,另一个存储在北弗吉尼亚,那么相应的值也可以设为 carolina 和 virginia;只需确保它们在每台机器上各不相同即可。
/etc/clickhouse-server/config.d/macros.xml
GCS 中的存储
disks 和 policies。下面配置的磁盘名为 gcs,其 type 为 s3。之所以使用 s3 类型,是因为 ClickHouse 访问 GCS 存储桶时,会将其视为 AWS S3 存储桶。此配置需要准备两份,每个 ClickHouse 服务器 节点各一份。
需要在下面的配置中进行以下替换。
以下替换项在两个 ClickHouse 服务器 节点之间有所不同:
REPLICA 1 BUCKET应设置为与 server 位于同一区域的存储桶名称REPLICA 1 FOLDER应在其中一个 server 上改为replica_1,在另一个 server 上改为replica_2
access_key_id应设置为之前生成的 HMAC Keysecret_access_key应设置为之前生成的 HMAC Secret
/etc/clickhouse-server/config.d/storage.xml
启动 ClickHouse Keeper
检查 ClickHouse Keeper 状态
netcat 向 ClickHouse Keeper 发送命令。例如,mntr 会返回 ClickHouse Keeper 集群的状态信息。如果在每个 Keeper 节点上运行该命令,你会看到其中一个是 leader,另外两个是跟随者:
启动 ClickHouse 服务器
chnode1 和 chnode 上运行:
验证
验证磁盘配置
system.disks 中应包含每个磁盘对应的记录:
- default
- gcs
- cache
验证在集群上创建的表是否已在两个节点上创建成功
验证数据可成功插入
验证该表是否使用存储策略 gcs_main。
在 Google Cloud Console 中验证
storage.xml 配置文件中使用的名称相同。展开这些文件夹后,你会看到许多文件,对应各个数据分区。