将 Amazon S3 与 ClickHouse Cloud 集成
S3 ClickPipe 提供了一种完全托管且高可用的方式,将数据从 Amazon S3 和兼容 S3 的对象存储中摄取到 ClickHouse Cloud 中。它支持具有精确一次语义的一次性摄取和持续摄取。
可以通过 ClickPipes UI 手动部署和管理 S3 ClickPipes,也可以通过 OpenAPI 和 Terraform 以编程方式进行部署和管理。
支持的数据源
| 名称 | 标志 | 详情 |
|---|---|---|
| Amazon S3 | 持续摄取默认要求按词典序排序,但可以配置为以任意顺序摄取文件。 | |
| Cloudflare R2 兼容 S3 | 持续摄取要求按词典序排序。不支持无序模式。 | |
| DigitalOcean Spaces 兼容 S3 | 持续摄取要求按词典序排序。不支持无序模式。 | |
| OVH Object Storage 兼容 S3 |  | 持续摄取要求按词典序排序。不支持无序模式。 |
由于各对象存储服务提供商在 URL 格式和 API 实现上的差异,并非所有兼容 S3 的服务都能直接获得支持。如果您在使用上面未列出的服务时遇到问题,请联系我们的团队。
支持的格式
功能特性
一次性摄取
默认情况下,S3 ClickPipe 会在一次批处理操作中,将指定 bucket 中所有与指定模式匹配的文件加载到 ClickHouse 目标表中。摄取任务完成后,ClickPipe 会自动停止。此一次性摄取模式提供精确一次(exactly-once)语义,确保每个文件都能被可靠处理且不会出现重复。
持续摄取
启用持续摄取后,ClickPipes 会从指定路径持续摄取数据。默认情况下,S3 ClickPipe 依赖文件的隐式字典序来确定摄取顺序。也可以通过使用连接到该存储桶的 Amazon SQS 队列,将其配置为以任意顺序摄取文件。
词典序
默认情况下,S3 ClickPipe 假定文件是按照词典序依次添加到存储桶(bucket)中,并依赖这种隐式顺序顺序摄取文件。这意味着任何新文件必须在词典序上大于上一个已摄取的文件。举例来说,命名为 file1、file2 和 file3 的文件会按顺序被摄取,但如果向存储桶中添加一个新的 file 0,它将被忽略,因为该文件名在词典序上并不大于上一个已摄取的文件。
在此模式下,S3 ClickPipe 会对指定路径中的所有文件进行初始加载,然后以可配置的时间间隔轮询新文件(默认 30 秒)。无法从某个特定文件或时间点开始摄取——ClickPipes 始终会加载指定路径中的所有文件。
任意顺序
有关分步说明,请参阅为连续摄取配置无序模式。
可以通过为存储桶配置一个 Amazon SQS 队列,并可选地使用 Amazon EventBridge 作为事件路由器,将 S3 ClickPipe 配置为摄取没有隐式顺序的文件。这样 ClickPipes 就可以监听对象创建事件,并摄取任何新文件,而不受文件命名约定的限制。
无序模式仅支持 Amazon S3,且不支持公共存储桶或兼容 S3 的服务。需要为该存储桶配置一个 Amazon SQS 队列,并可选地使用 Amazon EventBridge 作为事件路由器。
在此模式下,S3 ClickPipe 会对选定路径中的所有文件进行初始加载,然后在队列中监听与指定路径匹配的 ObjectCreated:* 事件。针对已处理过的文件、路径不匹配的文件或其他类型事件的任何消息都将被忽略。
为事件设置前缀/后缀是可选的。如果设置,确保它与 ClickPipe 配置的路径匹配。S3 不允许针对相同事件类型配置多个重叠的通知规则。
文件会在达到 max insert bytes 或 max file count 中配置的阈值后被摄取,或者在经过一个可配置的时间间隔后被摄取 (默认 30 秒) 。无法从某个特定文件或时间点开始摄取——ClickPipes 始终会加载选定路径中的所有文件。如果配置了 DLQ,失败的消息将被重新入队并重新处理,最多重试 DLQ 中 maxReceiveCount 参数配置的次数。
我们强烈建议为 SQS 队列配置死信队列 (Dead-Letter-Queue,DLQ) ,以便更容易调试和重试失败的消息。
EventBridge 到 SQS
也可以通过 Amazon EventBridge 将 S3 事件通知发送到 SQS。对于大多数用例,推荐采用这种方法,因为 EventBridge 支持更丰富的事件过滤、将事件扇出到多个目标,而且不受 S3“每个前缀下每种事件类型只能配置一条通知规则”这一限制的影响。有关分步说明,请参阅 为持续摄取配置无序模式。
SNS to SQS
也可以通过 SNS 主题将 S3 事件通知发送到 SQS。当直接 S3 → SQS 集成的某些限制条件成为问题时,可以采用这种方式。在这种情况下,需要启用 raw message delivery 选项。
文件模式匹配
对象存储 ClickPipes 遵循 POSIX 标准的文件模式匹配规则。所有模式均区分大小写,并且匹配的是桶名之后的完整路径。为获得更好的性能,请尽可能使用更具体的模式(例如使用 data-2024-*.csv 而不是 *.csv)。
支持的模式
| 模式 | 描述 | 示例 | 匹配结果 |
|---|---|---|---|
? | 精确匹配一个字符(不包含 /) | data-?.csv | data-1.csv, data-a.csv, data-x.csv |
* | 匹配零个或多个字符(不包含 /) | data-*.csv | data-1.csv, data-001.csv, data-report.csv, data-.csv |
** 递归 | 匹配零个或多个字符(包含 /),并启用 递归目录遍历。 | logs/**/error.log | logs/error.log, logs/2024/error.log, logs/2024/01/error.log |
示例:
https://bucket.s3.amazonaws.com/folder/*.csvhttps://bucket.s3.amazonaws.com/logs/**/data.jsonhttps://bucket.s3.amazonaws.com/file-?.parquethttps://bucket.s3.amazonaws.com/data-2024-*.csv.gz
不支持的模式
| Pattern | Description | Example | Alternatives |
|---|---|---|---|
{abc,def} | 花括号展开 | {logs,data}/file.csv | 为每个路径创建单独的 ClickPipes。 |
{N..M} | 数值范围展开 | file-{1..100}.csv | 使用 file-*.csv 或 file-?.csv。 |
示例:
https://bucket.s3.amazonaws.com/{documents-01,documents-02}.jsonhttps://bucket.s3.amazonaws.com/file-{1..100}.csvhttps://bucket.s3.amazonaws.com/{logs,metrics}/data.parquet
精确一次语义
在摄取大规模数据集时可能会发生各种类型的故障,从而导致只插入了部分数据或出现重复数据。Object Storage ClickPipes 能够很好地应对插入失败,并提供精确一次(exactly-once)语义。其实现方式是使用临时的 “staging” 表。数据首先被插入到 staging 表中。如果此次插入出现问题,可以截断 staging 表,并在干净状态下重试插入。只有在一次插入完成且成功之后,staging 表中的分区才会被迁移到目标表。要进一步了解这一策略,请参阅这篇博文。
虚拟列
要跟踪哪些文件已被摄取,请在列映射列表中包含 _file 虚拟列。_file 虚拟列包含源对象的文件名,可用于查询哪些文件已被处理。
访问控制
权限
S3 ClickPipe 支持公共和私有存储桶。Requester Pays 类型的存储桶不受支持。
S3 存储桶
存储桶必须在其存储桶策略中允许以下操作:
SQS 队列
在使用无序模式时,SQS 队列策略中必须允许以下操作:
身份验证
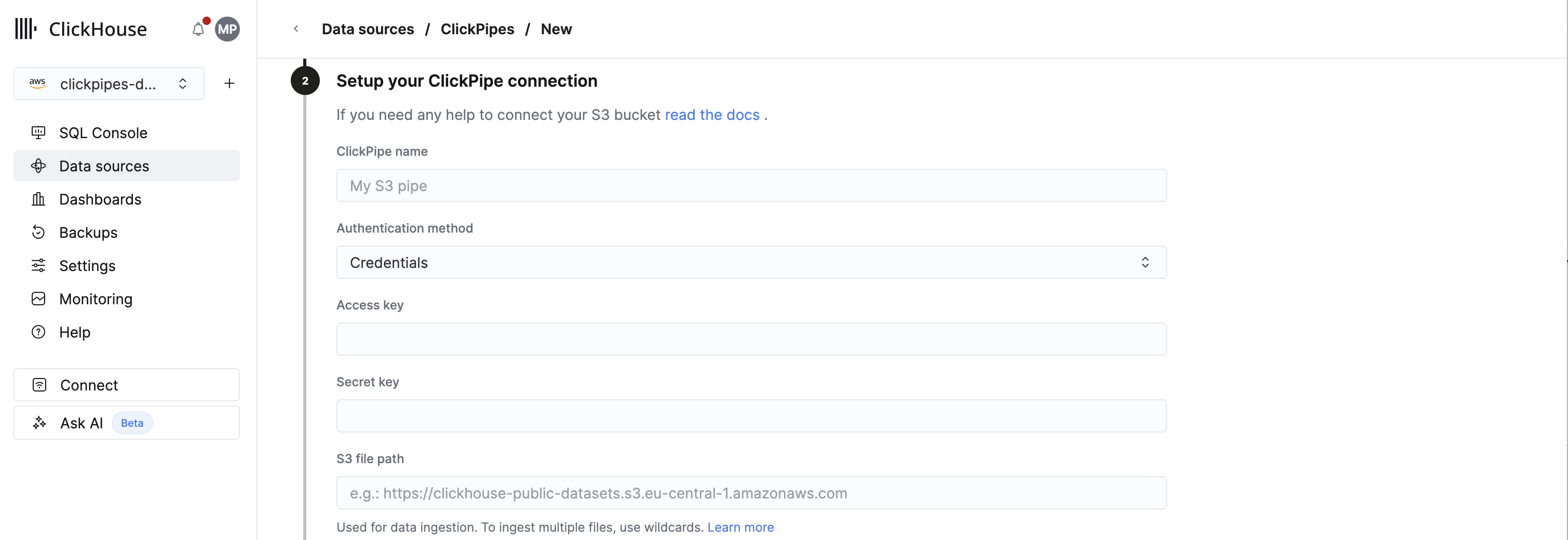
IAM 凭证
要使用 access keys 进行身份验证,在设置 ClickPipe 连接时,在 Authentication method 下选择 Credentials。然后分别在 Access key 和 Secret key 中填写访问密钥 ID(例如 AKIAIOSFODNN7EXAMPLE)和秘密访问密钥(例如 wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY)。
IAM 角色
要使用基于角色的访问控制进行身份验证,请在设置 ClickPipe 连接时,将 Authentication method 设置为 IAM role。
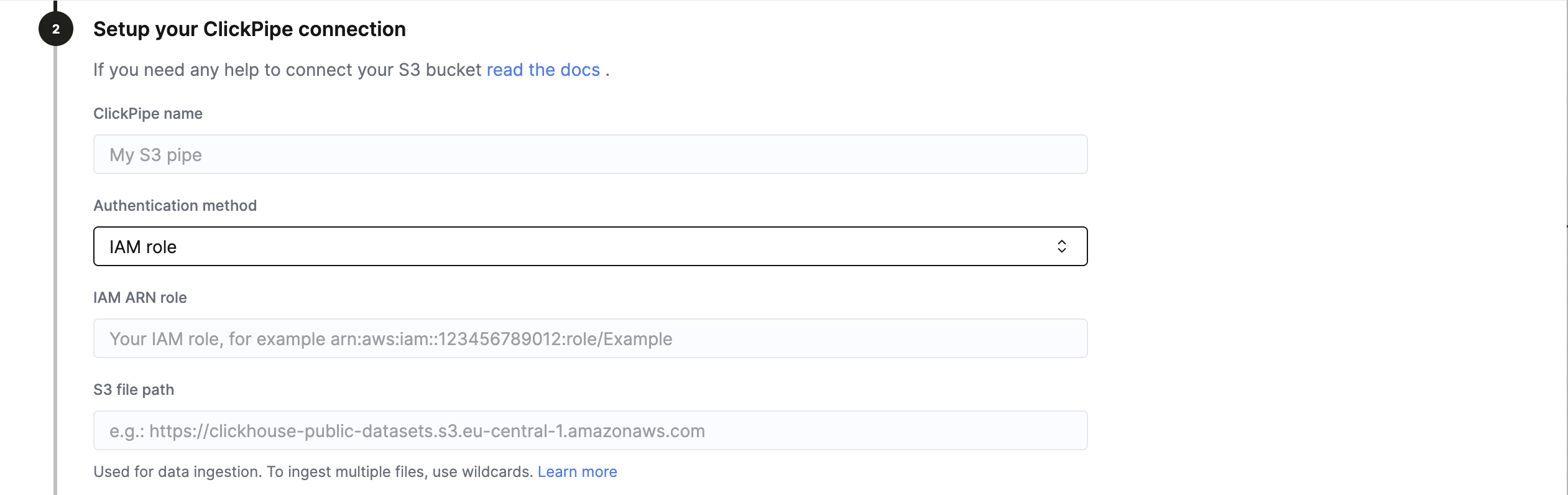
请按照本指南中的说明,创建一个 IAM 角色,并为 S3 访问配置所需的信任策略。然后,在 IAM role ARN 字段中填写该 IAM 角色的 ARN。
网络访问
S3 ClickPipes 会使用两条不同的网络路径分别执行元数据发现和数据摄取:分别通过 ClickPipes 服务和 ClickHouse Cloud 服务。如果你希望配置额外一层网络安全(例如出于合规性原因),则 必须为这两条路径都配置网络访问。
-
对于 基于 IP 的访问控制,S3 存储桶策略必须同时允许 ClickPipes 服务区域中列出的静态 IP(见此处),以及 ClickHouse Cloud 服务的静态 IP。要获取你所使用的 ClickHouse Cloud 区域的静态 IP,请打开终端并运行:
-
对于 基于 VPC endpoint 的访问控制,S3 存储桶必须与 ClickHouse Cloud 服务处于同一 region,并且将
GetObject操作限制为 ClickHouse Cloud 服务的 VPC endpoint ID。要获取你所使用的 ClickHouse Cloud 区域的 VPC endpoint,请打开终端并运行:
高级设置
ClickPipes 提供了合理的默认值,能够满足大多数用例的需求。如果您的用例需要进一步微调,可以调整以下设置:
| 设置 | 默认值 | 描述 |
|---|---|---|
Max insert bytes | 10GB | 单个插入批次中要处理的字节数。 |
Max file count | 100 | 单个插入批次中要处理的最大文件数。 |
Max threads | auto(3) | 用于文件处理的最大并发线程数。 |
Max insert threads | 1 | 用于插入操作的最大并发插入线程数。 |
Min insert block size bytes | 1GB | 可以插入到表中的数据块的最小字节大小。 |
Max download threads | 4 | 最大并发下载线程数。 |
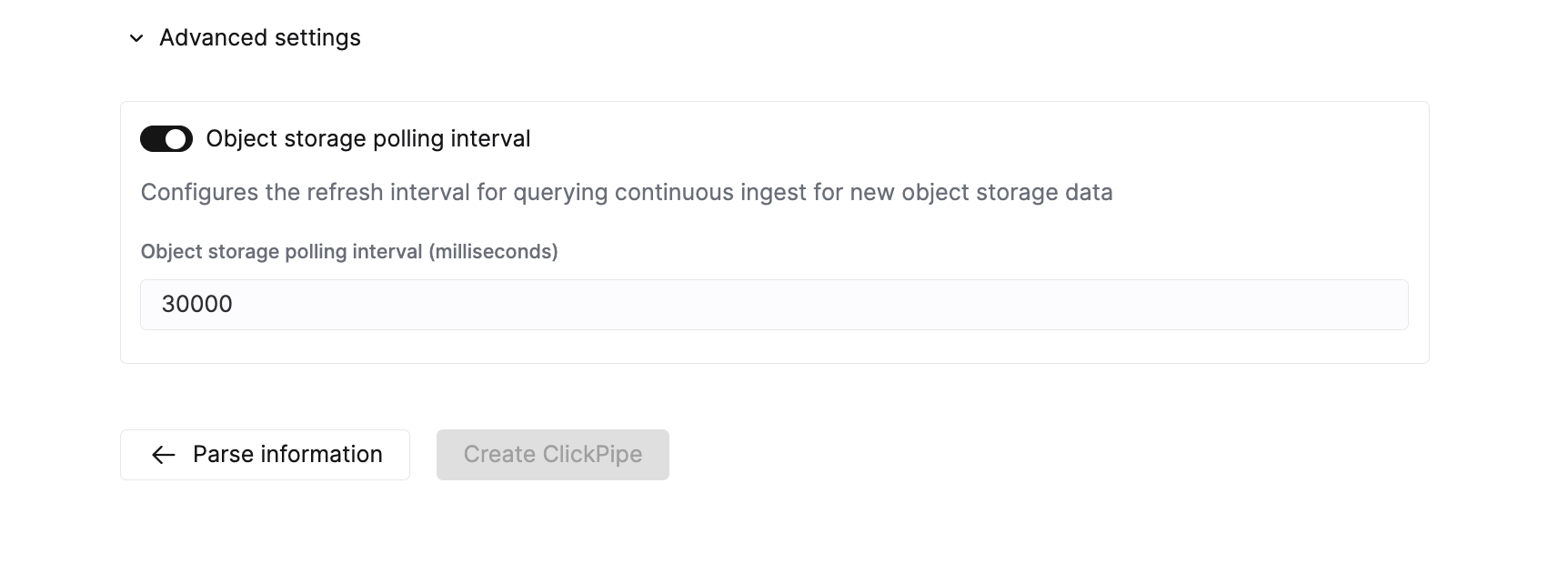
Object storage polling interval | 30s | 用于配置在向 ClickHouse 集群插入数据前的最大等待时间。 |
Parallel distributed insert select | 2 | 并行分布式 insert select 设置。 |
Parallel view processing | false | 是否启用并发而非顺序地向附加的 VIEW 推送数据。 |
Use cluster function | true | 是否在多个节点之间并行处理文件。 |
扩缩容
对象存储 ClickPipes 的扩缩容基于 已配置的纵向自动扩缩容设置 所确定的 ClickHouse 服务最小规格。ClickPipe 的规格在创建 ClickPipe 时确定。之后对 ClickHouse 服务设置所做的更改不会影响 ClickPipe 的规格。
若要提高大型摄取作业的吞吐量,建议在创建 ClickPipe 之前先对 ClickHouse 服务进行扩容。
已知限制
文件大小
ClickPipes 只会尝试摄取大小不超过 10GB 的对象。若文件大于 10GB,则会在 ClickPipes 的专用错误表中追加一条错误记录。
兼容性
尽管具备 S3 兼容性,但某些服务使用了不同的 URL 结构,可能导致 S3 ClickPipe 无法解析(例如 Backblaze B2),或者需要与特定云厂商的队列服务集成,才能实现持续的、无序的摄取。如果您在使用未列在支持的数据源中的服务时遇到问题,请联系我们的团队。
视图支持
目标表上的 materialized view 也受支持。ClickPipes 不仅会为目标表创建暂存表(staging table),还会为所有依赖的 materialized view 创建暂存表。
我们不会为普通(非 materialized view)视图创建暂存表。这意味着,如果您的目标表有一个或多个下游的 materialized view,这些 materialized view 应避免通过另一个视图(view)从目标表中读取数据。否则,可能会导致该 materialized view 中出现数据缺失。
