1
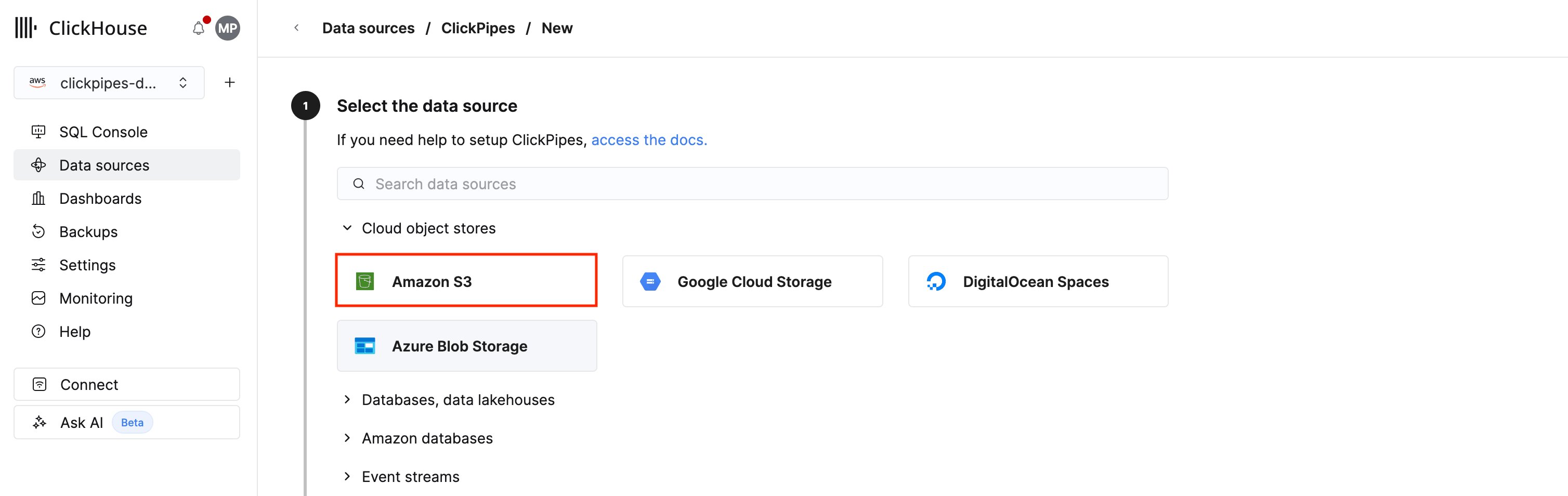
选择数据源
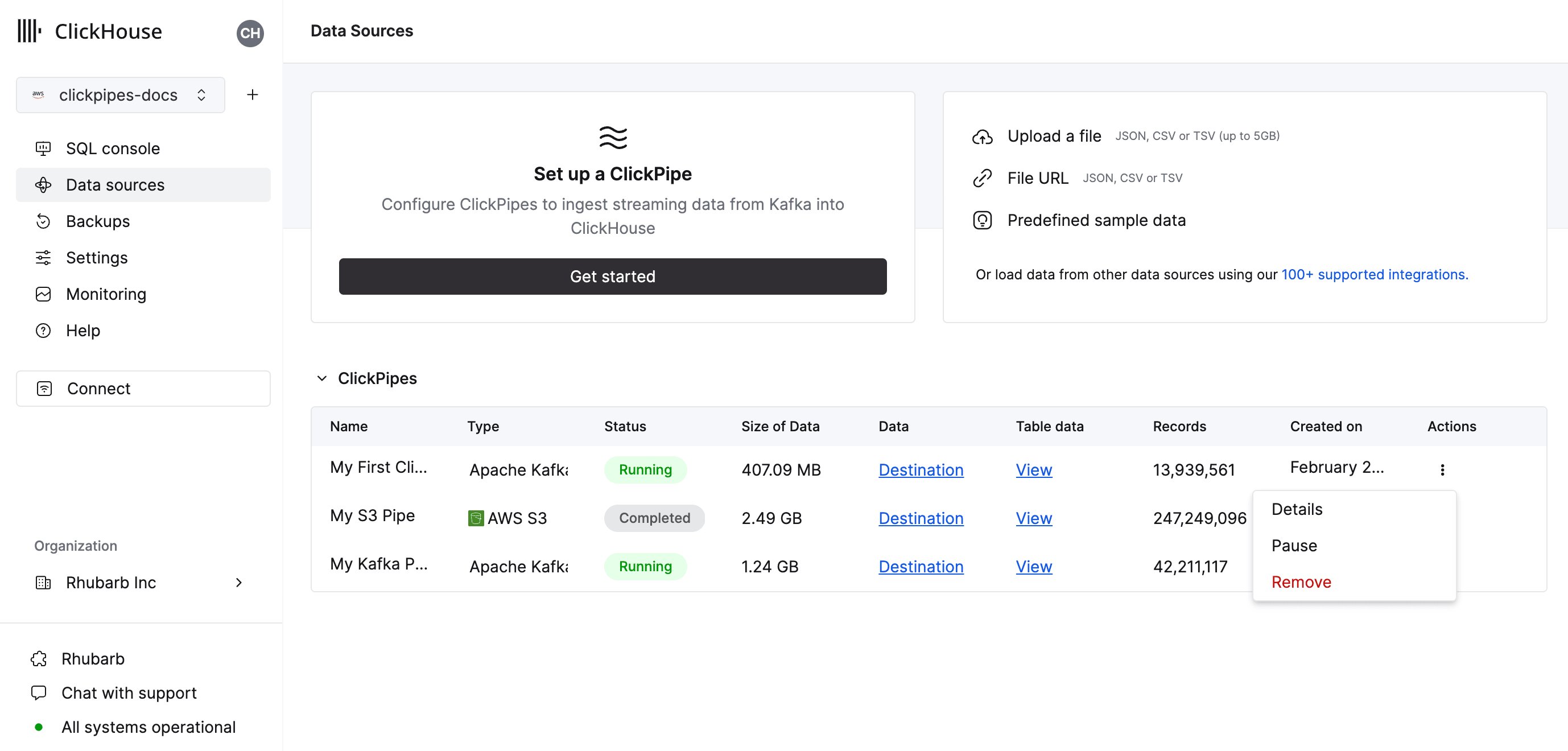
1. 在 ClickHouse Cloud 中,从主导航菜单中选择 数据源,然后点击 创建 ClickPipe。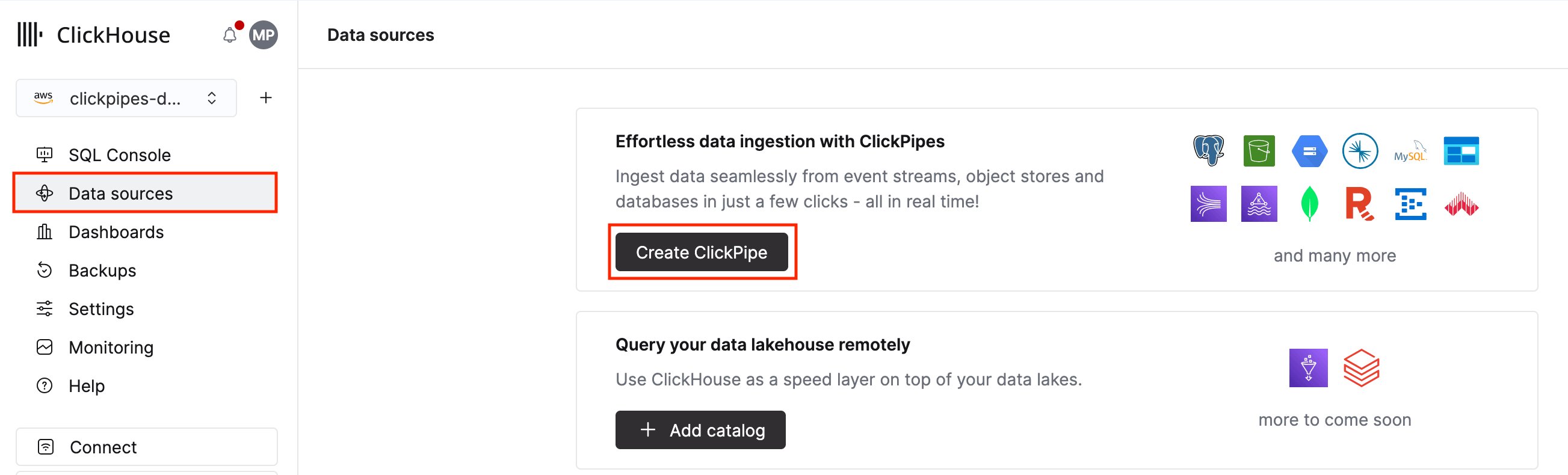
2
设置 ClickPipe 连接
1. 要设置新的 ClickPipe,您需要提供对象存储服务的连接和身份验证详细信息。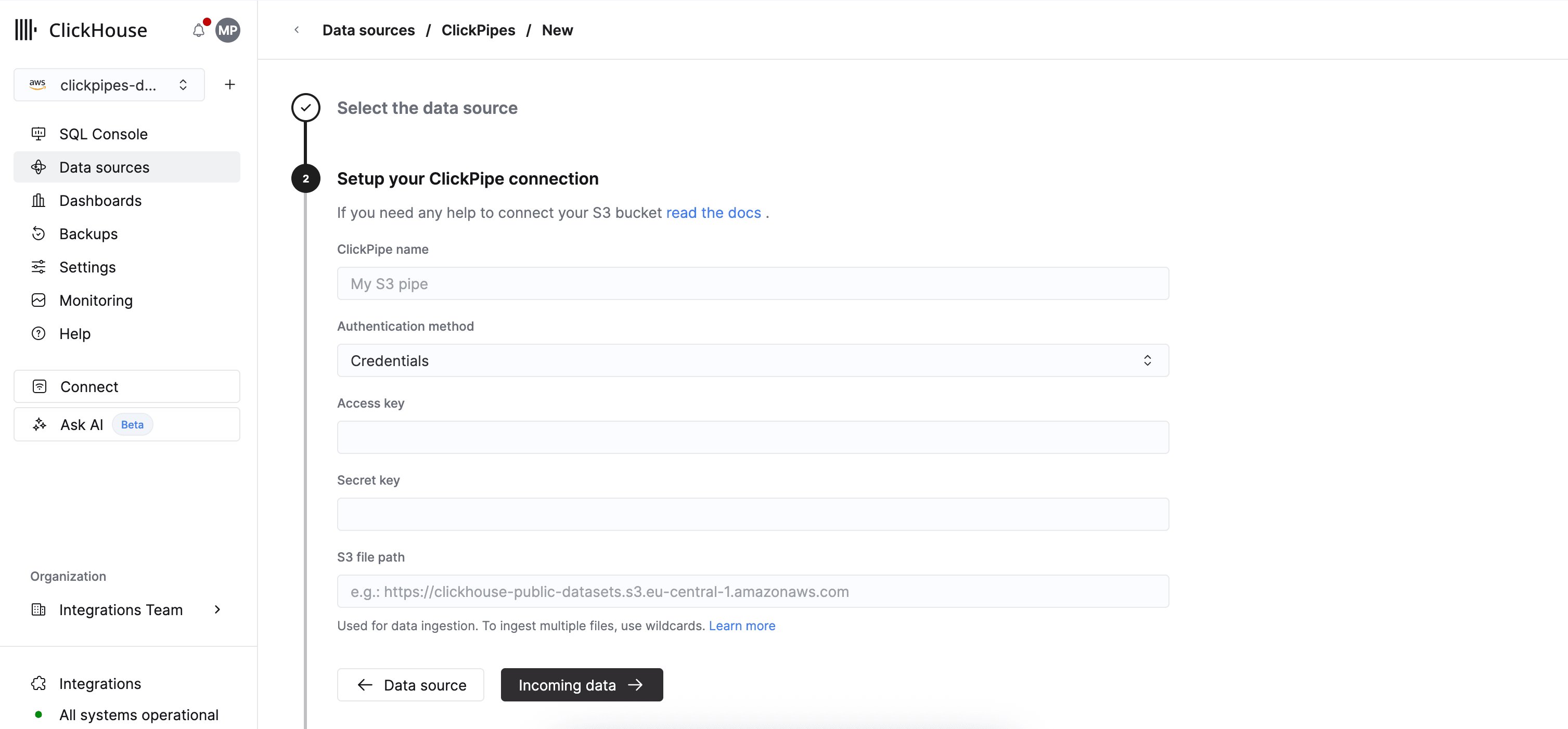
-
身份验证方法:S3 ClickPipe 支持 IAM 凭证 (
Credentials) 和 基于 IAM role 的身份验证 (IAM role) 。有关身份验证和权限的说明,请参阅参考文档。-
S3 文件路径:S3 ClickPipe 要求使用 virtual-hosted-style URI。
您可以使用 POSIX 通配符来匹配多个文件或前缀。有关支持的匹配模式,请参阅参考文档。
-
S3 文件路径:S3 ClickPipe 要求使用 virtual-hosted-style URI。
3
选择数据格式
界面将显示指定 bucket 中的文件列表。
选择数据格式 (目前支持部分 ClickHouse 格式) ,并决定是否启用持续摄取。
更多详细信息,请参阅概览页面中的“持续摄取”部分。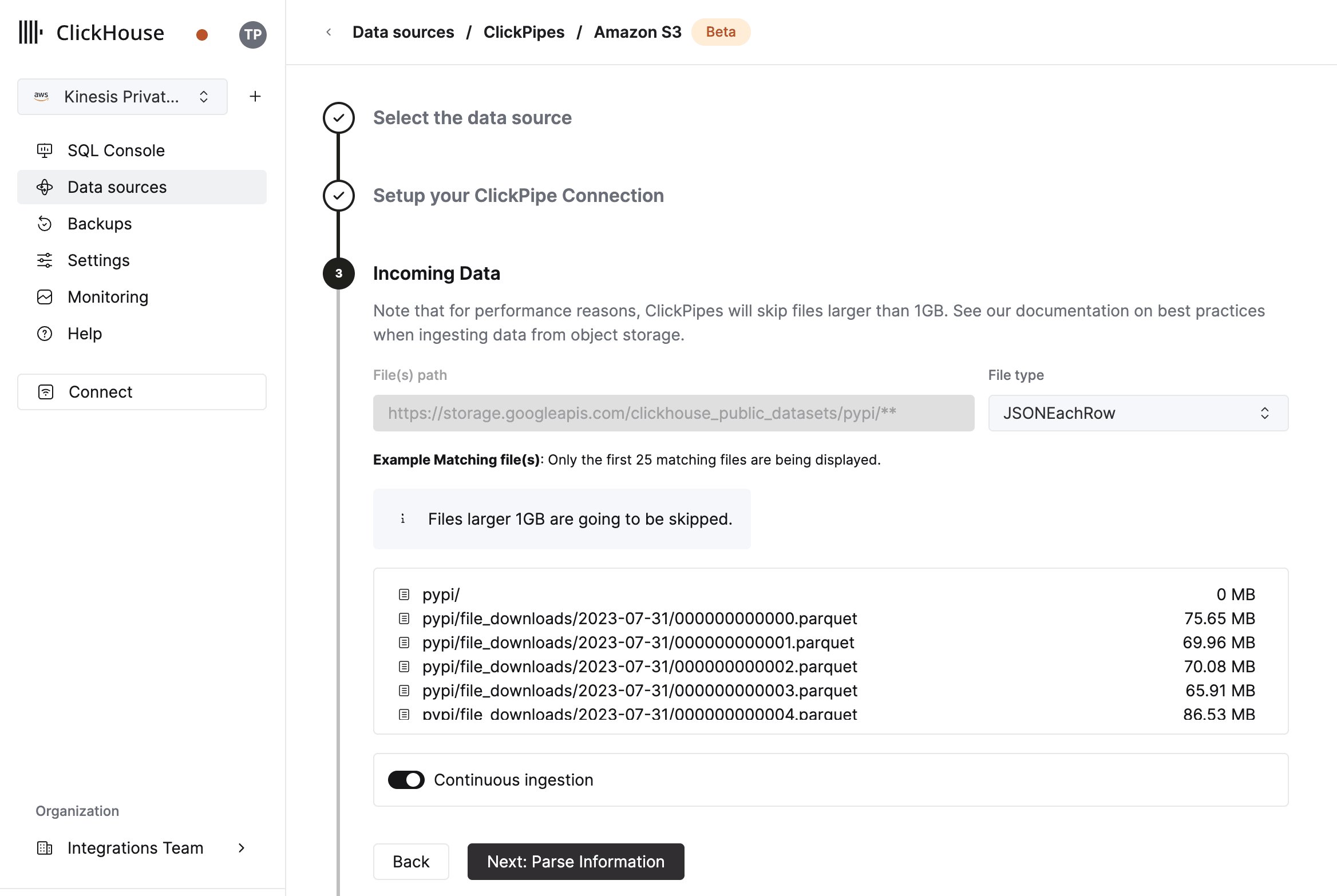
4
配置表、schema 和设置
在下一步中,您可以选择将数据摄取到新的 ClickHouse 表中,或复用现有表。
按照界面上的说明修改表名、schema 和设置。
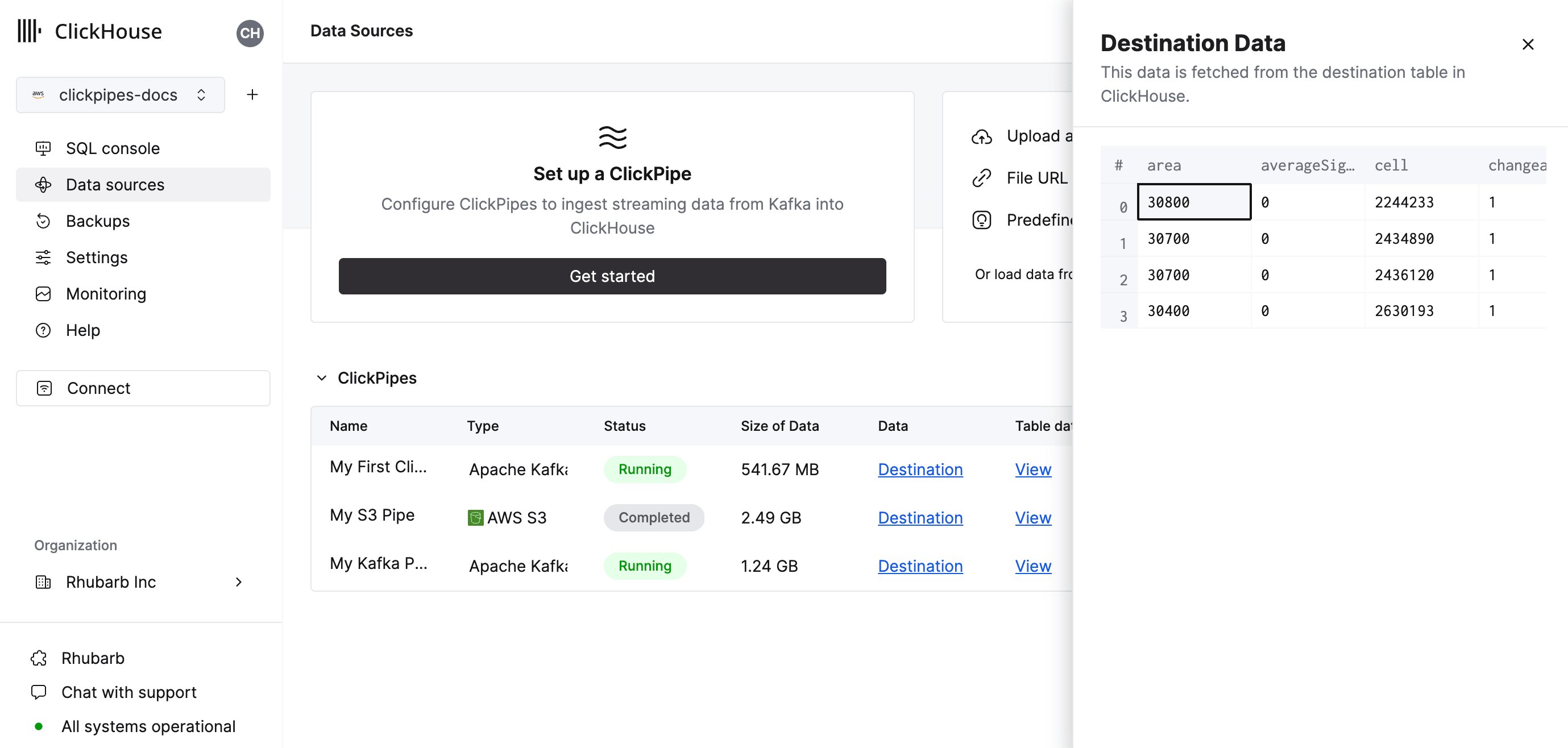
您可以在顶部的样本表中实时预览这些更改。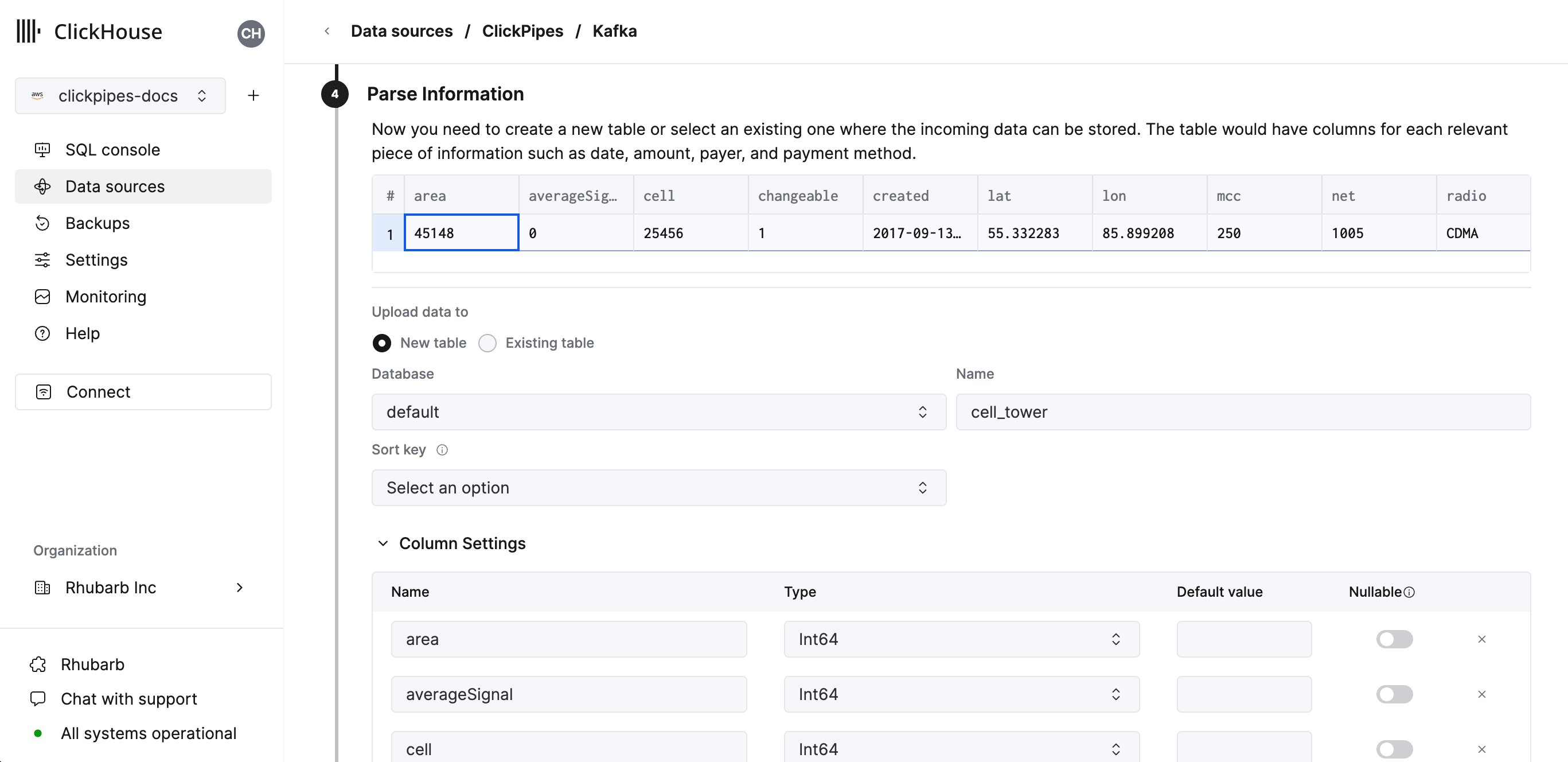
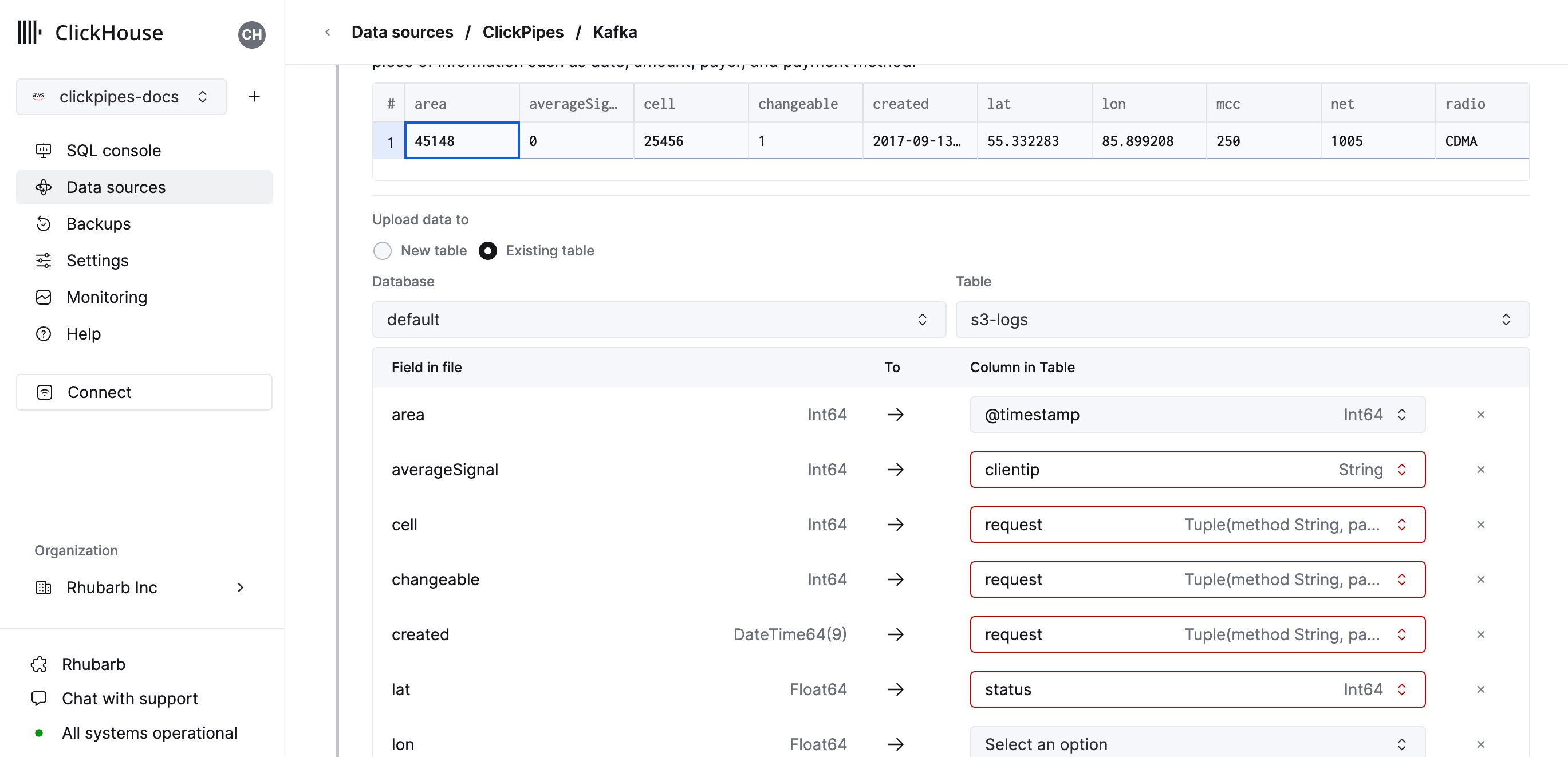
您还可以将虚拟列 (如
_path 或 _size) 映射到字段。5
配置权限
最后,您可以为内部 ClickPipes 用户配置权限。权限: ClickPipes 会创建一个专用用户,用于将数据写入目标表。您可以为该内部用户选择角色,可使用自定义角色或预定义角色之一: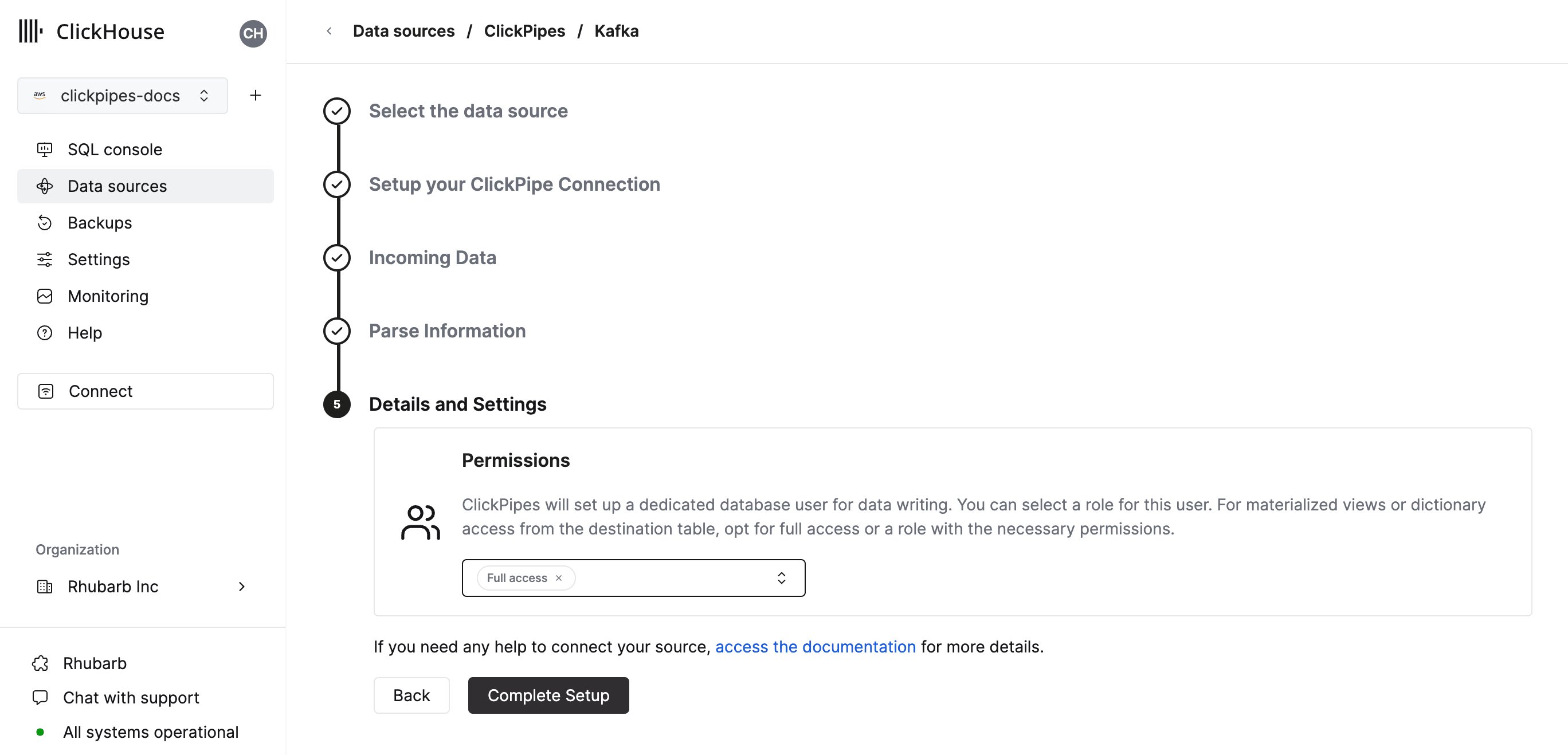
Full access:拥有整个 cluster 的完全访问权限。如果目标表使用了 materialized view 或 字典,则需要选择此项。Only destination table:仅拥有目标表的INSERT权限。
6
完成设置
点击“Complete Setup”后,系统将注册您的 ClickPipe,随后您可以在摘要表中看到它。