关键概念
设置指南
1
收集 ClickHouse 连接详细信息
要通过 HTTP(S) 连接到 ClickHouse,你需要以下信息:
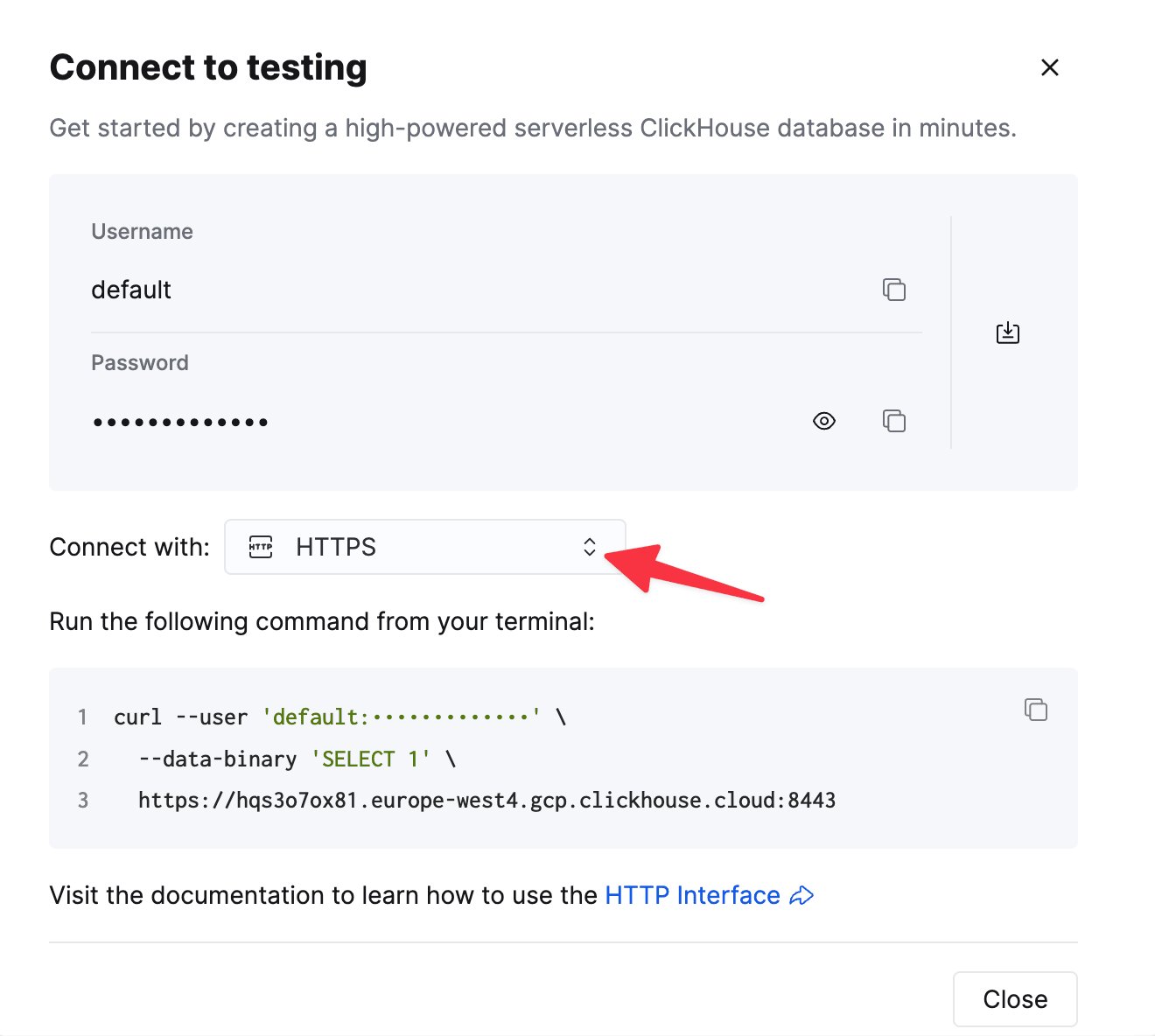
你的 ClickHouse Cloud 服务的连接信息可在 ClickHouse Cloud 控制台中查看。
选择一个服务,然后点击 Connect:
curl 命令中。2
Apify 前置条件
你还需要:
- 一个 Apify 账户 (提供免费层级) 。
- 一个 Apify API 令牌,可在 Apify Console 的 Settings > Integrations 中找到。
- 在本地安装 Node.js 18+ (用于 JavaScript 示例) 。
3
安装依赖
安装 Apify JavaScript 客户端 和 ClickHouse JavaScript 客户端:
Apify 还提供 Python 客户端。如果你更习惯使用 Python,请通过 pip 安装
apify-client,并使用 clickhouse-connect 连接 ClickHouse。4
在 ClickHouse 中创建目标表
创建一个用于存放抓取数据的表。schema 取决于你使用的 Actor。下面的示例针对一个产品抓取 Actor 使用 MergeTree:
5
拉取 Apify dataset 并加载到 ClickHouse
以下脚本会拉取一次 Apify Actor 运行的结果,并将其插入 ClickHouse:
6
使用 webhooks 实现自动化
与其手动运行脚本,不如将该管道自动化,这样每次 Actor 完成时,数据都会自动加载到 ClickHouse:
- 在 Apify Console 中,进入你的 Actor 并打开 Integrations 选项卡。
- 添加一个新的 webhook,配置如下:
- Event type:
ACTOR.RUN.SUCCEEDED - Action: 向你的加载器端点发送 HTTP POST,或触发另一个负责向 ClickHouse 插入数据的 Actor。
- Event type:
- webhook 载荷中包含
defaultDatasetId,你可以用它拉取该次运行的结果。
最佳实践
从 Apify 拉取数据
apify-client,Python 使用对应客户端) ,不要直接发起原始 HTTP 请求。它会为你处理分页、重试和身份验证。对于大型数据集,请使用 List dataset items 端点中的 limit 和 offset 参数对结果进行分页。
加载到 ClickHouse
JSONEachRow 格式。它与 Apify 的 JSON 输出直接对应,无需任何转换。
请确保 ClickHouse 表的 schema 与 Actor 的输出字段一致。你可以在 Actor 的 Apify Store 页面上,或运行完成后的 Dataset 选项卡中查看其输出 schema。
性能
安全
default 用户和数据库。在生产环境中,请创建一个专用用户,并仅授予其向目标表执行 insert 所需的最小权限;同时妥善保管凭证 (例如存放在环境变量或 secrets 管理器中,而不要提交到源代码仓库) 。有关说明,请参阅 云访问管理。