将数据写入 ClickHouse
将数据写入 ClickHouse 与 OLTP 数据库的对比
作为一款 OLAP(联机分析处理,Online Analytical Processing)数据库,ClickHouse 针对高性能和可扩展性进行了优化,最高可支持每秒插入数百万行数据。 这是通过高度并行化的架构与高效的列式压缩相结合实现的,但代价是对立即一致性的妥协。 更具体地说,ClickHouse 针对仅追加(append-only)操作进行了优化,并且只提供最终一致性(eventual consistency)保证。
相比之下,Postgres 等 OLTP(联机事务处理,Online Transaction Processing)数据库专门针对具备完整 ACID 特性的事务性插入进行了优化,确保强一致性和可靠性保证。 PostgreSQL 使用 MVCC(多版本并发控制,Multi-Version Concurrency Control)来处理并发事务,这涉及维护同一数据的多个版本。 这些事务一次通常只涉及少量行数据,但由于需要满足可靠性保证,会引入相当大的开销,从而限制插入性能。
为了在保持强一致性保证的同时获得高插入性能,你在向 ClickHouse 插入数据时应遵循下文所述的一些简单规则。 遵循这些规则将有助于避免用户在首次使用 ClickHouse 时,尝试照搬适用于 OLTP 数据库的插入策略而常见的问题。
插入操作最佳实践
使用较大的批量进行插入
默认情况下,发送到 ClickHouse 的每个插入操作都会使 ClickHouse 立即创建一个存储部件(part),其中包含该次插入的数据以及需要存储的其他元数据。 因此,与其发送大量每次只包含少量数据的插入操作,不如发送次数更少但每次包含更多数据的插入操作,这样可以减少所需的写入次数。 通常我们建议一次性插入较大批量的数据,每次至少 1,000 行,理想情况下在 10,000 到 100,000 行之间。 (更多详细说明见此处。)
如果无法使用大批量插入,请使用下文描述的异步插入。
确保批次一致以支持幂等重试
默认情况下,对 ClickHouse 的插入是同步且幂等的(即多次执行相同的插入操作,其效果与执行一次相同)。 对于 MergeTree 引擎系列的表,ClickHouse 默认会自动在插入时去重。
这意味着插入在以下情况中仍然具有良好的容错性:
-
- 如果接收数据的节点出现问题,插入查询会超时(或返回更具体的错误),并且不会获得确认。
-
- 如果节点已经写入数据,但由于网络中断无法将确认返回给查询发送方,则发送方会收到超时或网络错误。
从客户端的角度来看,(1)和(2)可能难以区分。然而,在这两种情况下,未被确认的插入都可以立即重试。 只要重试的插入查询包含相同顺序的相同数据,如果(未确认的)原始插入实际上已成功,ClickHouse 将自动忽略这次重试插入。
插入到 MergeTree 表或分布式表中
我们建议直接插入到 MergeTree(或 Replicated 表)中;如果数据被分片,则在一组节点之间对请求进行负载均衡,并设置 internal_replication=true。
这样可以让 ClickHouse 将数据复制到任意可用的副本分片,并确保数据最终一致。
如果客户端侧负载均衡不方便,用户也可以通过分布式表进行插入,由其负责将写入分发到各个节点。同样建议设置 internal_replication=true。
但需要注意,这种方式的性能会略差一些,因为写入必须先在拥有分布式表的本地节点上完成,然后再发送到各个分片。
对小批量使用异步插入
在某些场景下,客户端侧批量聚合不可行,例如可观测性场景中存在数百或数千个单一用途的代理发送日志、指标、追踪等数据。 在这种场景中,数据的实时传输是尽快检测问题和异常的关键。 此外,被观测系统中存在事件突发的风险,当尝试在客户端缓冲可观测性数据时,可能会导致内存突增及相关问题。 如果无法进行大批量插入,用户可以使用异步插入,将批量聚合委托给 ClickHouse。
使用异步插入时,数据首先会被插入到缓冲区中,然后再分三步写入数据库存储,如下图所示:
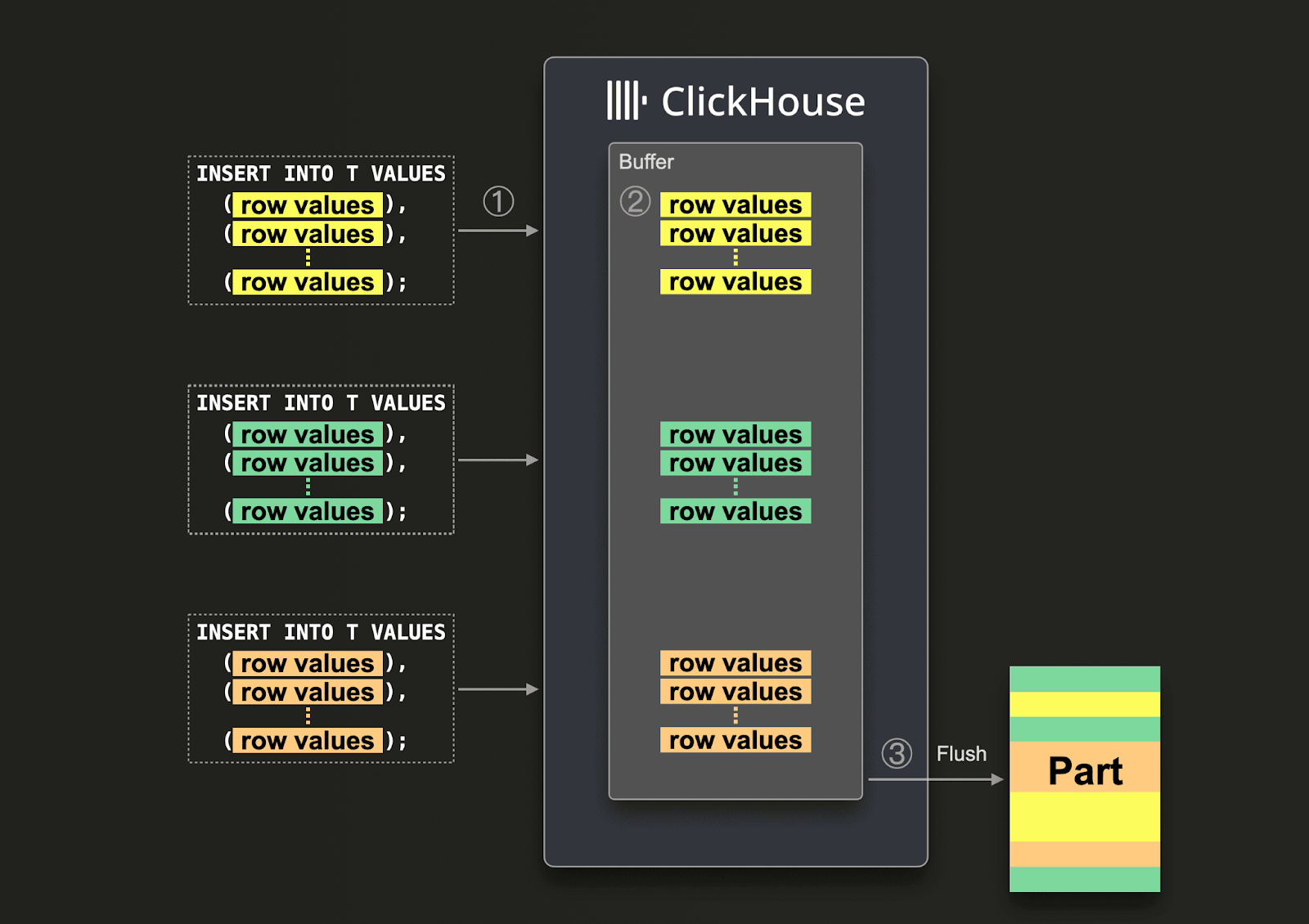
启用异步插入后,ClickHouse 会执行以下操作:
(1) 异步接收插入查询。
(2) 先将查询中的数据写入内存缓冲区。
(3) 仅在下次缓冲区刷新的时候,才对数据进行排序并以一个 part 的形式写入数据库存储。
在缓冲区被刷新之前,可以收集来自同一或其他客户端的其他异步插入查询的数据。 通过缓冲区刷新创建的 part 可能会包含来自多个异步插入查询的数据。 总体而言,这些机制将数据批量处理从客户端侧转移到了服务端(ClickHouse 实例)。
使用官方 ClickHouse 客户端
ClickHouse 为最流行的编程语言提供了客户端。 这些客户端经过优化,以确保插入被正确执行,并且对异步插入提供了原生支持:要么像 Go 客户端那样直接支持,要么通过在查询、用户或连接级别启用相关设置而间接支持。
有关可用 ClickHouse 客户端和驱动的完整列表,请参阅 Clients and Drivers。
优先使用 Native 格式
ClickHouse 在插入(以及查询)时支持多种输入格式。 这与 OLTP 数据库有显著差异,使得从外部来源加载数据更加容易——尤其是在结合表函数以及从磁盘文件加载数据的能力时。 这些格式非常适合临时数据加载和数据工程任务。
对于希望获得最佳插入性能的应用,你应使用 Native 格式进行插入。 大多数客户端(如 Go 和 Python)都支持该格式,并且由于该格式已经是列式的,因此可确保服务器所需的处理工作最少。 通过这种方式,将数据转换为列式格式的责任由客户端承担。这对于高效扩展插入能力非常重要。
或者,如果更偏好行格式,你可以使用 RowBinary 格式(Java 客户端所使用的格式)——通常比 Native 格式更容易写入。 与其他行格式(如 JSON)相比,它在压缩、网络开销以及服务器端处理方面更高效。 如果你的写入吞吐量要求较低、希望快速集成,可以考虑使用 JSONEachRow 格式。需要注意的是,此格式会在 ClickHouse 中引入额外的 CPU 解析开销。
使用 HTTP 接口
与许多传统数据库不同,ClickHouse 支持 HTTP 接口。 用户可以使用该接口以任意上述格式进行数据插入和查询。 这通常优于 ClickHouse 的原生协议,因为它允许通过负载均衡器轻松切换流量。 预计与原生协议相比,插入性能会有轻微差异,原生协议的开销略低。 现有客户端会使用这两种协议中的任意一种(有些情况下两种都支持,例如 Go 客户端)。 原生协议还允许更方便地跟踪查询进度。
更多详情请参见 HTTP 接口。
基本示例
你可以在 ClickHouse 中使用熟悉的 INSERT INTO TABLE 命令。现在让我们向在入门指南“在 ClickHouse 中创建表”中创建的表插入一些数据。
为验证其是否已生效,我们将运行以下 SELECT 查询:
将返回:
从 Postgres 加载数据
要从 Postgres 加载数据,用户可以使用:
ClickPipes,一种专门为 PostgreSQL 数据库复制设计的 ETL 工具。它可以通过以下两种方式使用:- ClickHouse Cloud —— 通过 ClickPipes 中我们的托管摄取服务。
- 自托管部署 —— 通过 PeerDB 开源项目。
- 使用 PostgreSQL 表引擎 按照前面示例所示直接读取数据。通常适用于基于已知水位标记(例如时间戳)的批量复制已足够,或只是执行一次性迁移的场景。该方法可以处理数千万行数据。希望迁移更大数据集的用户应考虑发起多次请求,每次处理一部分数据。在将分区移动到最终表之前,可以为每个数据块使用中间表。这样可以在请求失败时进行重试。有关此批量加载策略的更多详细信息,请参阅此处。
- 可以将 PostgreSQL 中的数据导出为 CSV 格式。然后可以从本地文件或通过使用表函数访问对象存储,将数据插入到 ClickHouse 中。
如果您在插入大型数据集时需要帮助,或在向 ClickHouse Cloud 导入数据时遇到任何错误,请通过 support@clickhouse.com 联系我们,我们会提供协助。
从命令行插入数据
前提条件
- 您已经安装了 ClickHouse
clickhouse-server正在运行- 您可以访问带有
wget、zcat和curl的终端
在本示例中,您将看到如何在命令行中使用批处理模式的 clickhouse-client 将一个 CSV 文件插入到 ClickHouse 中。关于使用批处理模式的 clickhouse-client 通过命令行插入数据的更多信息和示例,请参阅 “Batch mode”。
在本示例中我们将使用 Hacker News 数据集,其中包含 2800 万行 Hacker News 数据。
创建表
在 clickhouse-server 运行的情况下,您可以在命令行中使用批处理模式的 clickhouse-client,直接按照以下表结构创建一个空表:
如果没有报错,则说明表已成功创建。上面命令中在 heredoc 分隔符 (_EOF) 外使用了单引号,以避免任何变量替换。如果不使用单引号,则需要对列名周围的反引号进行转义。
从命令行插入数据
接下来运行下面的命令,将之前下载的文件中的数据插入到您的表中:
由于我们的数据是压缩的,因此首先需要使用 gzip、zcat 或类似工具解压文件,然后通过管道将解压后的数据传入 clickhouse-client,并使用相应的 INSERT 语句和 FORMAT。
在使用交互模式的 clickhouse-client 插入数据时,可以在插入时使用 COMPRESSION 子句,让 ClickHouse 为您处理解压。ClickHouse 可以根据文件扩展名自动检测压缩类型,您也可以显式指定。
插入数据的查询将如下所示:
当数据插入完成后,您可以运行以下命令查看 hackernews 表中的行数:
使用 curl 从命令行插入数据
在前面的步骤中,您首先使用 wget 将 CSV 文件下载到本地机器。您也可以通过一条命令,直接从远程 URL 插入数据。
运行以下命令,清空 hackernews 表中的数据,这样您就可以在无需先下载到本地的情况下重新插入数据:
现在运行:
您现在可以像之前一样运行相同的命令,验证数据已再次成功插入:
