ClickHouse Cloud 快速入门
开始使用 ClickHouse 最快、最简单的方法是在 ClickHouse Cloud 中创建一个新的 服务。在本快速入门指南中,我们将通过三个简单步骤带你完成设置。
创建 ClickHouse 服务
要在 ClickHouse Cloud 中创建免费的 ClickHouse 服务,只需按照以下步骤完成注册:
- 在注册页面上创建账户
- 你可以选择使用邮箱注册,或者通过 Google SSO、Microsoft SSO、AWS Marketplace、Google Cloud 或 Microsoft Azure 注册
- 如果你使用邮箱和密码注册,请记得在接下来的 24 小时内,通过邮件中提供的链接验证你的邮箱地址
- 使用刚刚创建的用户名和密码登录
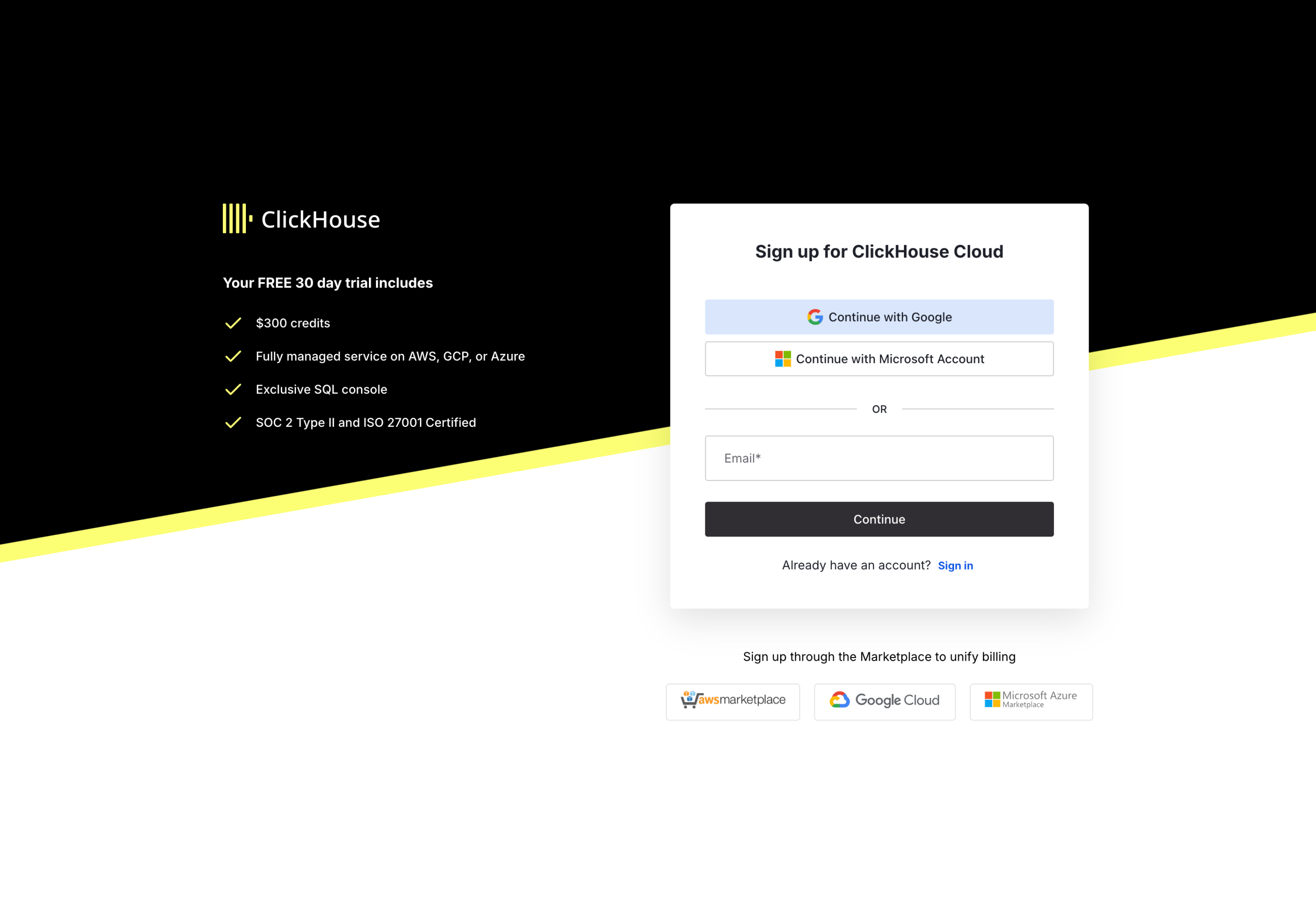
登录后,ClickHouse Cloud 会启动接入流程向导,带您完成新 ClickHouse 服务的创建。请选择要部署服务的区域,并为新服务命名:
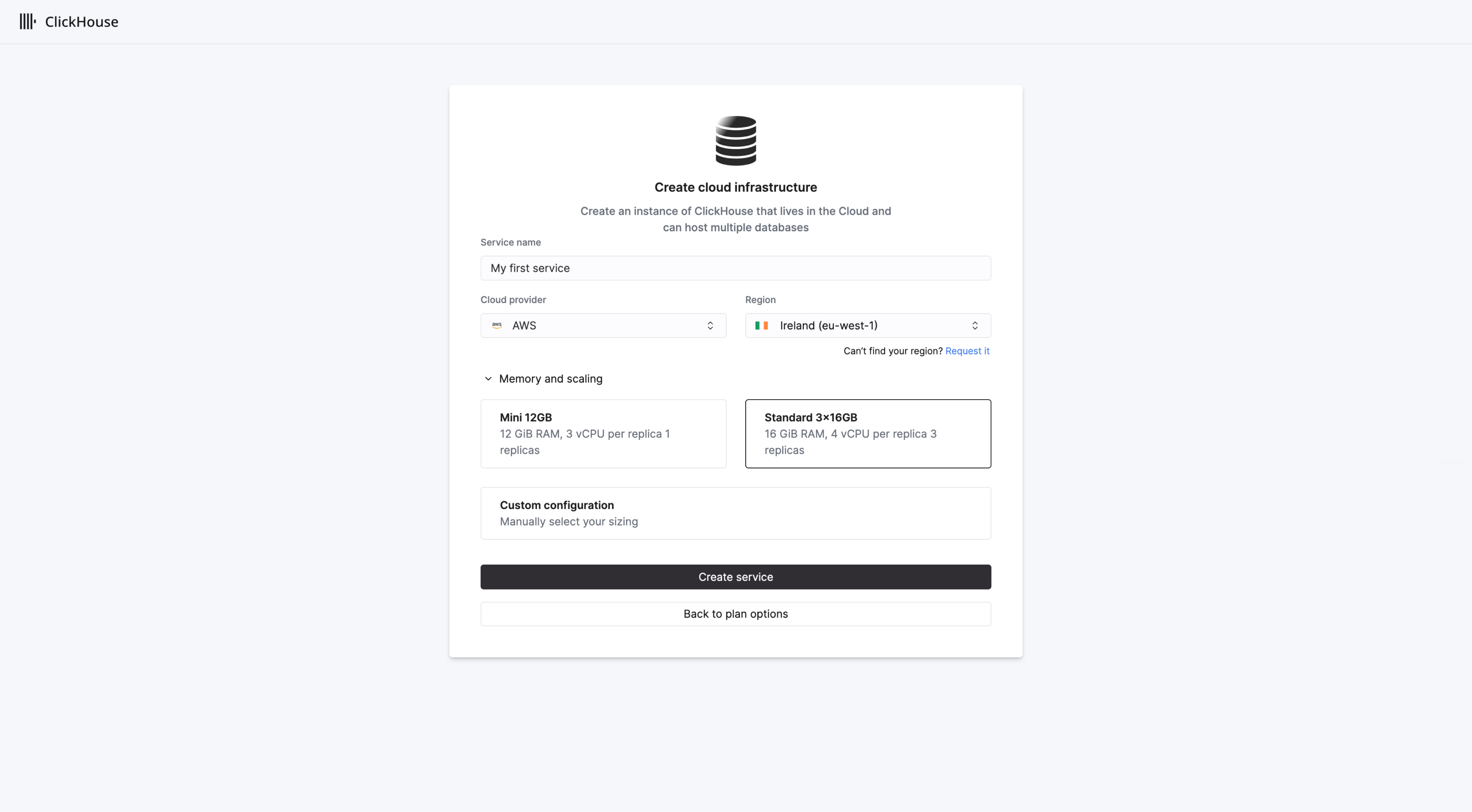
默认情况下,新组织将采用 Scale 层级,并创建 3 个副本,每个副本配置 4 个 vCPUs 和 16 GiB 内存。Scale 层级默认启用垂直自动扩展。您可以稍后在'Plans'页面更改组织层级。
如有需要,可通过指定副本的最小和最大数量来自定义服务资源以进行扩缩容。准备就绪后,选择 Create service。
恭喜!您的 ClickHouse Cloud 服务已启动并运行,接入流程已完成。请继续阅读,了解如何开始摄取并查询您的数据。
连接到 ClickHouse
连接 ClickHouse 有两种方式:
- 通过我们的基于 Web 的 SQL 控制台进行连接
- 连接您的应用
使用 SQL 控制台连接
为便于快速上手,ClickHouse 提供了基于 Web 的 SQL 控制台,完成初始配置后系统会将您自动重定向到该控制台。
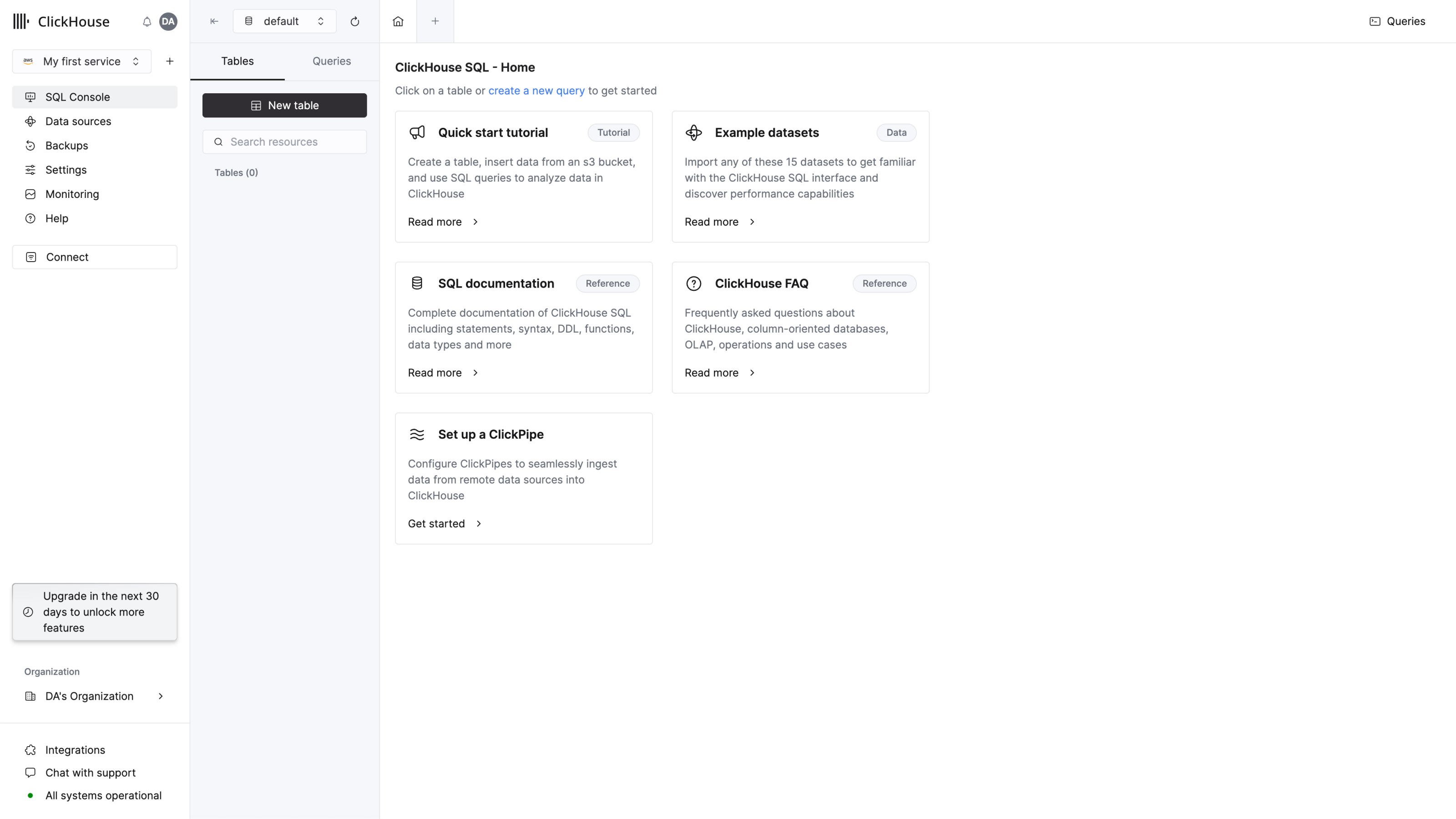
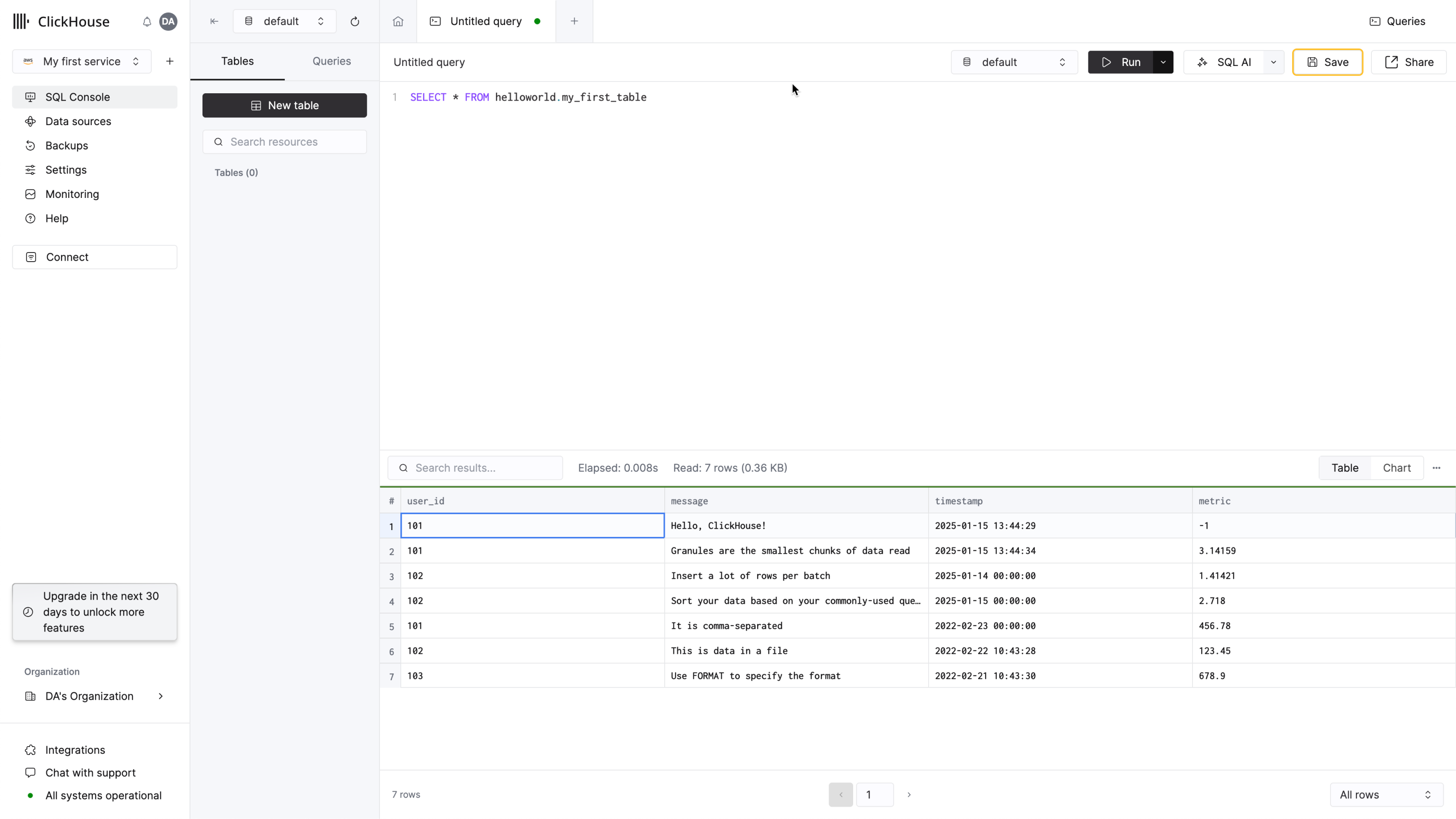
创建一个查询标签页并输入简单查询以验证连接是否正常:
您应该在列表中看到 4 个数据库,以及您可能添加的任何数据库。
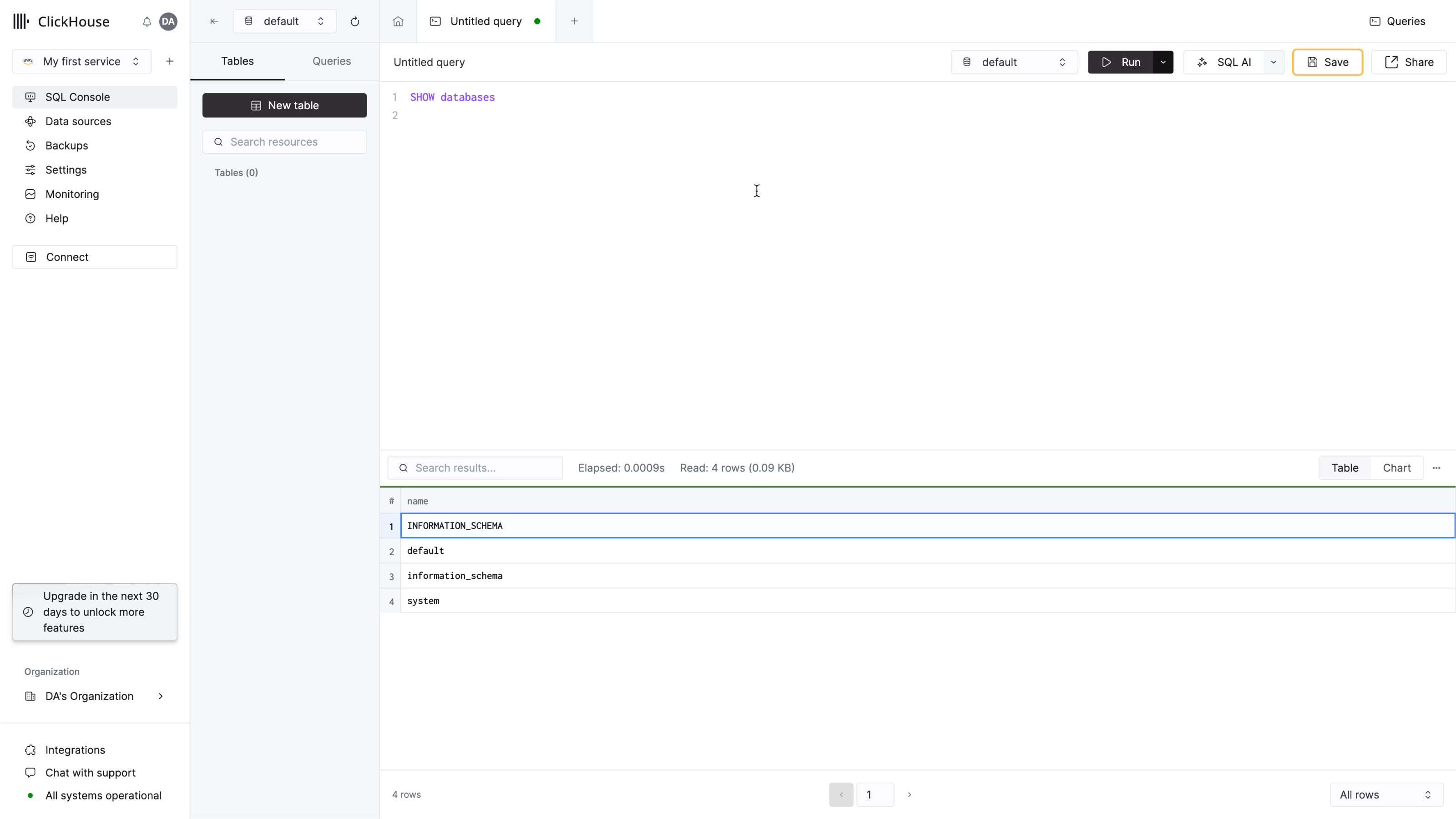
完成了 - 您现在可以开始使用新的 ClickHouse 服务了!
连接您的应用
从导航菜单中点击连接按钮。将弹出一个对话框,显示您的服务凭据,并提供使用界面或语言客户端进行连接的操作说明。
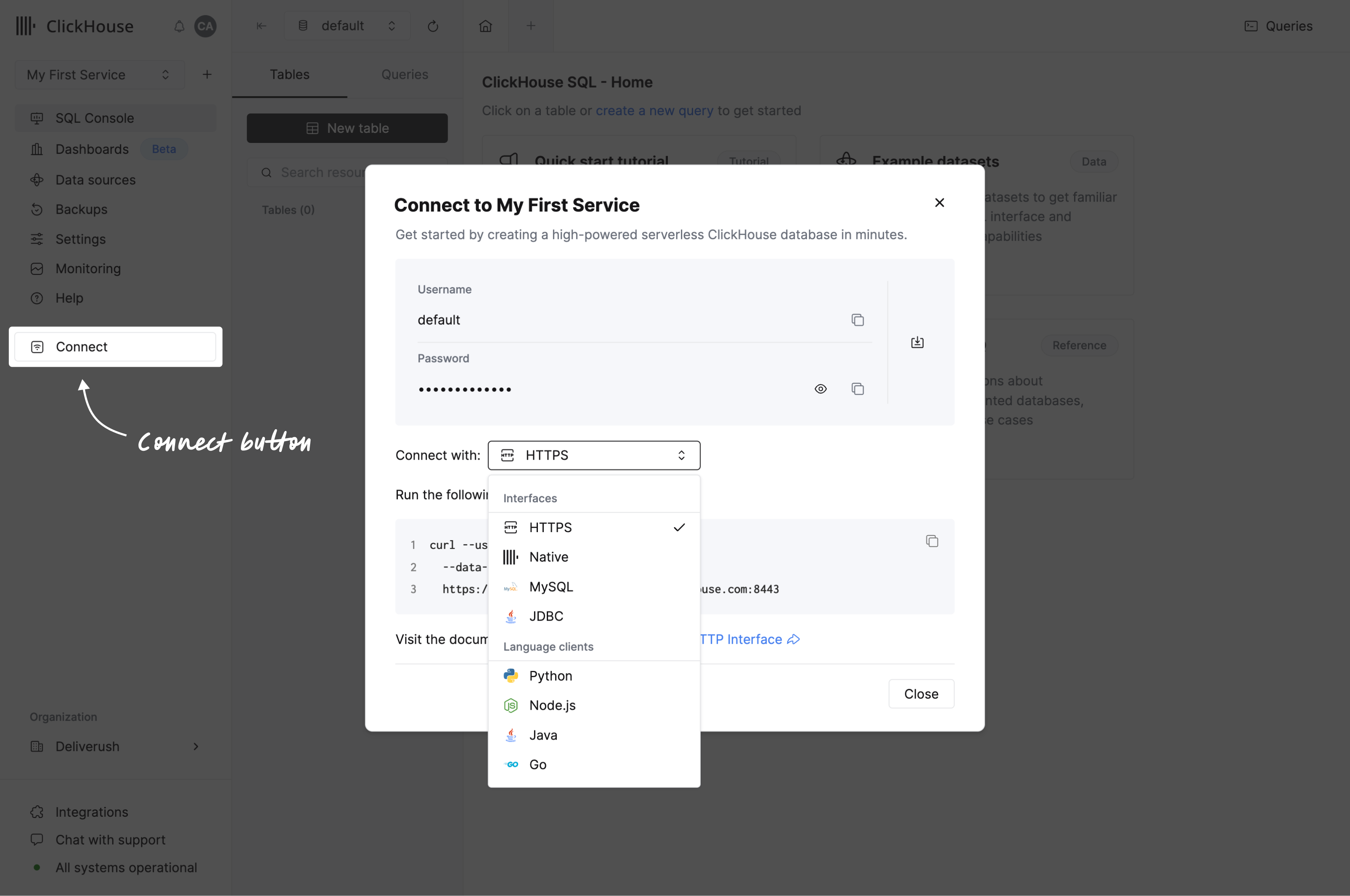
如果您找不到所需的语言客户端,请查看我们的集成列表。
添加数据
ClickHouse 需要数据才能发挥最佳性能!添加数据有多种方式,大部分可通过导航菜单中的"数据源"页面访问。
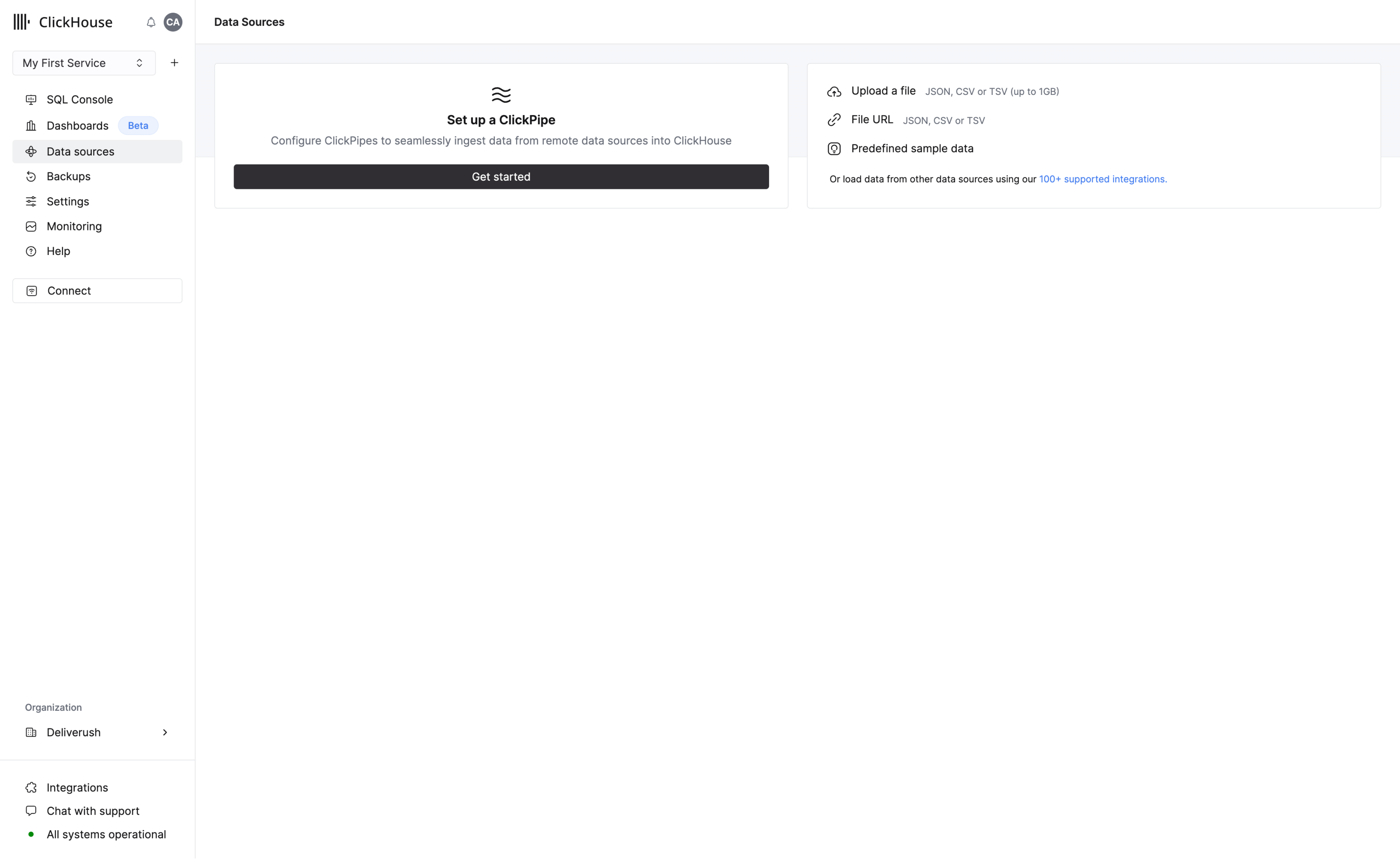
您可以使用以下方法上传数据:
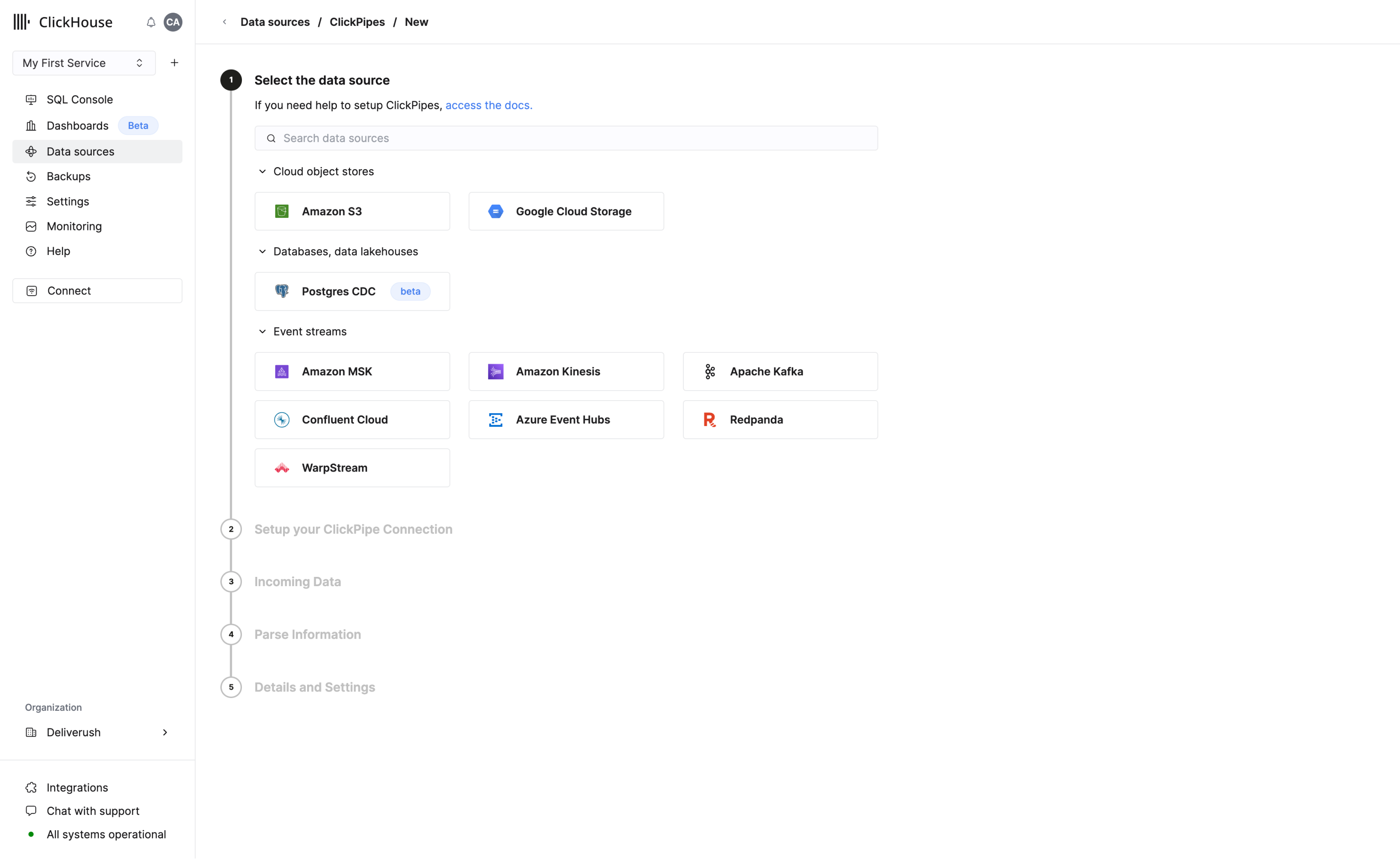
- 设置 ClickPipe,以从 S3、Postgres、Kafka、GCS 等数据源开始摄取数据
- 使用 SQL 控制台
- 使用 ClickHouse 客户端
- 上传文件 - 支持的格式包括 JSON、CSV 和 TSV
- 通过文件 URL 上传数据
ClickPipes
ClickPipes 是一个托管的集成平台,只需点击几下即可轻松从多种来源摄取数据。ClickPipes 专为最苛刻的工作负载而设计,其强大且可扩展的架构确保了持续的性能和可靠性。ClickPipes 可用于长期的流式处理需求或一次性的数据加载任务。
使用 SQL 控制台添加数据
与大多数数据库管理系统一样,ClickHouse 在逻辑上将表组织到数据库中。使用 CREATE DATABASE 命令在 ClickHouse 中创建新数据库:
运行以下命令在 helloworld 数据库中创建名为 my_first_table 的表:
在上述示例中,my_first_table 是一个 MergeTree 表,包含四列:
user_id: 32 位无符号整数 (UInt32)message:一种 String 数据类型,用于替代其他数据库系统中的VARCHAR、BLOB、CLOB等数据类型timestamp:一个 DateTime 值,表示某个具体时间点metric:32 位浮点数 (Float32)
主键简介
在继续操作之前,务必了解 ClickHouse 中主键的工作原理(主键的实现方式可能会出乎意料!):
- 在 ClickHouse 中,表中的主键对每一行都不是唯一的
ClickHouse 表的主键决定了数据写入磁盘时的排序方式。每 8,192 行或 10MB 的数据 (称为 索引粒度) 都会在主键索引文件中创建一个条目。这种粒度设计形成了一个可以轻松放入内存的 稀疏索引,而粒度块 (granule) 则表示在 SELECT 查询期间会被处理的最小列数据条带。
主键可以使用 PRIMARY KEY 参数定义。如果在定义表时未指定 PRIMARY KEY,
则该键为 ORDER BY 子句中指定的元组。如果同时指定了 PRIMARY KEY 和 ORDER BY,则主键必须是排序键的子集。
主键同时也是排序键,为 (user_id, timestamp) 这一元组。因此,每个列文件中存储的数据会先按 user_id,再按 timestamp 排序。
如需深入了解 ClickHouse 的核心概念,请参阅"核心概念"。
向表中插入数据
您可以使用熟悉的 INSERT INTO TABLE 命令向 ClickHouse 插入数据,但需要注意的是,每次向 MergeTree 表执行插入操作都会在存储中创建一个分区片段(part)。
每批次插入大量数据行——一次性插入数万甚至数百万行。无需担心——ClickHouse 能够轻松处理这种数据量级,并且通过减少向服务发送的写入请求次数来节省成本。
即使是这个简单示例,我们也一次插入多行数据:
验证是否成功:
使用 ClickHouse 客户端添加数据
您还可以使用名为 clickhouse client 的命令行工具连接到 ClickHouse Cloud 服务。点击左侧菜单中的 Connect 以查看这些详细信息。在弹出的对话框中从下拉菜单选择 Native:
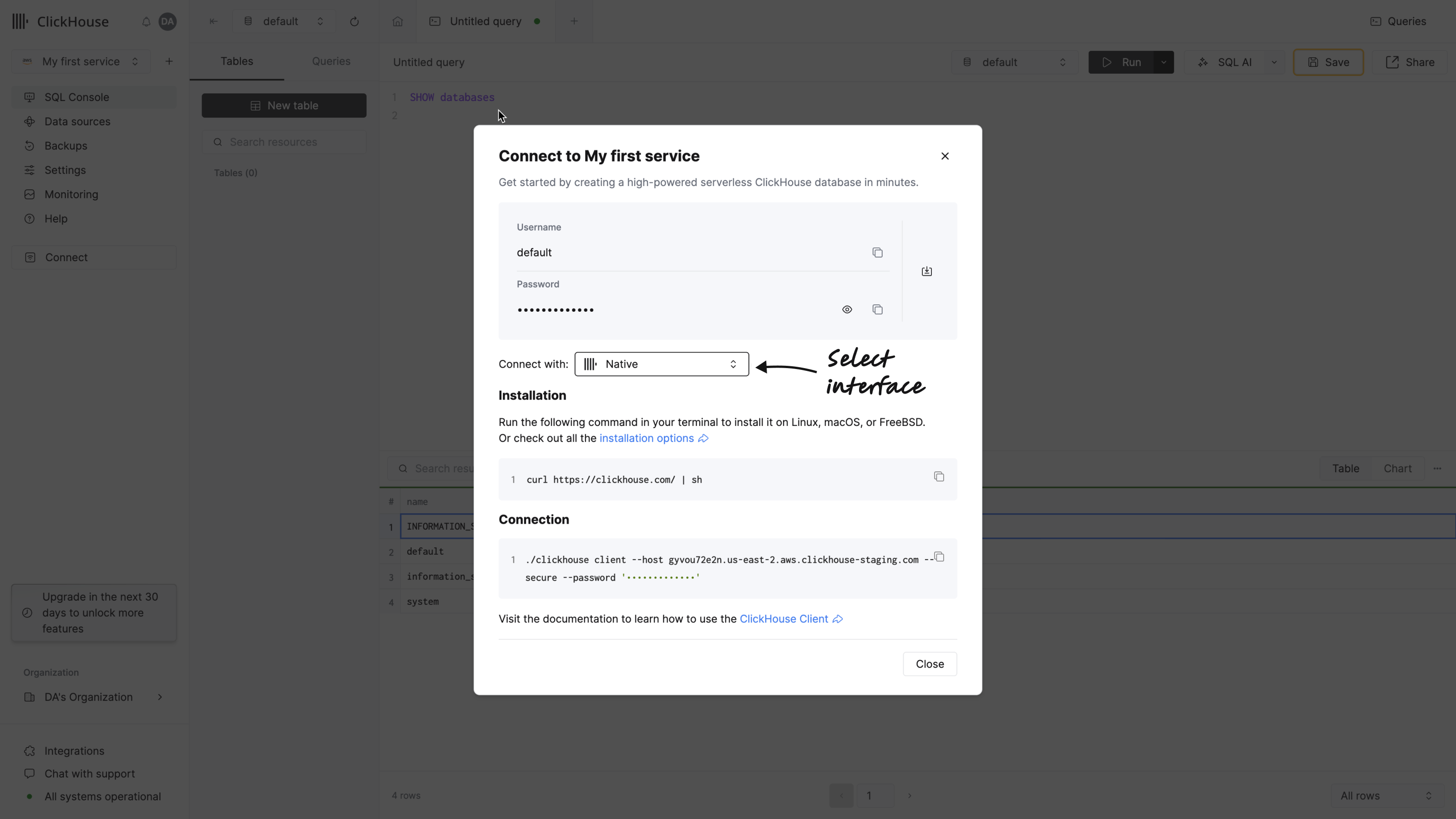
-
安装 ClickHouse。
-
运行以下命令,并将其中的主机名、用户名和密码替换为您的实际信息:
如果看到笑脸提示符,说明您已准备好运行查询!
- 试着运行以下查询:
注意响应以表格格式返回:
- 添加
FORMAT子句,以指定 ClickHouse 支持的多种输出格式之一:
在上述查询中,输出结果以制表符分隔的格式返回:
- 要退出
clickhouse client,请输入 exit 命令:
上传文件
开始使用数据库时的一项常见任务是插入已有文件中的数据。我们提供了一些在线示例数据供您插入,这些数据代表点击流数据,包括用户 ID、访问的 URL 以及事件时间戳。
假设我们有一个名为 data.csv 的 CSV 文件,其中包含以下文本:
- 以下命令将数据插入到
my_first_table中:
- 请注意,现在如果在 SQL 控制台中查询,就会发现表中已经出现了新行:
在继续之前,建议先配置 IP 访问列表过滤。 有关详情,请参阅"设置 IP 过滤器"。
接下来做什么?
- 教程 将指导你向一张表中插入 200 万行数据,并编写一些分析查询
- 我们提供了一份示例数据集列表,其中包含如何插入这些数据集的说明
- 查看我们时长 12 分钟的 ClickHouse 入门视频
- 如果数据来自外部数据源,请查看我们的集成指南合集,了解如何连接消息队列、数据库、数据管道等
- 如果你在使用 UI/BI 可视化工具,请查看将 UI 连接到 ClickHouse 的用户指南
- 关于主键的用户指南涵盖了你需要了解的所有主键相关内容及其定义方式
