回填数据
无论是刚接触 ClickHouse,还是负责维护现有部署,用户往往需要将历史数据回填到表中。在某些情况下,这相对简单,但当需要填充materialized view时,就可能变得更加复杂。本指南介绍了一些可用于执行此任务的流程,用户可以根据自己的用例进行应用。
本指南假定用户已经熟悉 增量materialized view 的概念,以及 使用诸如 S3 和 GCS 等表函数进行数据加载。我们还建议用户阅读我们的从对象存储优化插入性能指南,其中的建议适用于本指南中涉及的所有插入操作。
示例数据集
在本指南中,我们将一直使用一个 PyPI 数据集。该数据集中的每一行都表示一次使用 pip 等工具下载 Python 包的记录。
例如,该数据子集只涵盖一天 —— 2024-12-17,并可通过 https://datasets-documentation.s3.eu-west-3.amazonaws.com/pypi/2024-12-17/ 公开访问。你可以通过以下方式查询:
该 bucket 的完整数据集包含超过 320 GB 的 Parquet 文件。在下面的示例中,我们有意使用 glob 模式来选取数据子集。
我们假定用户正在消费这批数据的数据流,例如来自 Kafka 或对象存储,且仅包含该日期之后的数据。该数据的模式(schema)如下所示:
完整的 PyPI 数据集(包含超过 1 万亿行数据)可在我们的公共演示环境 clickpy.clickhouse.com 中访问。关于该数据集的更多详情(包括演示如何利用物化视图提升性能,以及数据如何按日写入和更新),请参见此处。
回填场景
通常在从某个时间点开始消费数据流时,需要进行回填。这些数据会被插入到带有增量materialized view的 ClickHouse 表中,并在数据块被插入时触发。这些视图可能在插入前对数据进行转换,或者计算聚合并将结果发送到目标表,以便下游应用后续使用。
本文将讨论以下场景:
- 在现有数据摄取流程下回填数据 - 新数据正在被加载,同时需要对历史数据进行回填。这些历史数据已经被确定。
- 为现有表添加 materialized view - 需要在历史数据已被填充且当前已有数据持续写入的环境中添加新的 materialized view。
我们假设数据将从对象存储中进行回填。在所有情况下,我们的目标都是避免中断数据插入。
我们建议从对象存储中回填历史数据。应尽可能将数据导出为 Parquet 格式,以获得最佳的读取性能和压缩效果(减少网络传输)。文件大小通常以约 150MB 为佳,但 ClickHouse 支持超过 70 种文件格式,并能够处理各种大小的文件。
使用副本表和视图
在所有这些场景中,我们依赖“副本表和视图”的概念。这些表和视图是用于实时流式数据的那些表和视图的副本,使我们可以在隔离环境中执行回填操作,并且在发生故障时能够轻松恢复。比如,我们有如下主 pypi 表和物化视图,用于计算每个 Python 项目的下载次数:
我们用一部分数据填充主表及其相关视图:
假设我们希望加载另一个数据子集 {101..200}。虽然我们可以直接插入到 pypi 中,但通过创建表副本,我们可以在隔离环境中完成这次回填。
如果回填失败,我们并不会影响主表,可以直接截断副本表并重试。
要创建这些视图的新副本,我们可以使用带有 _v2 后缀的 CREATE TABLE AS 子句:
我们将第二个规模大致相同的数据子集加载到该表中,并确认加载成功。
如果我们在第二次加载的任意阶段遇到失败,可以直接截断我们的 pypi_v2 和 pypi_downloads_v2,然后重新执行数据加载。
在完成数据加载后,我们可以使用 ALTER TABLE MOVE PARTITION 子句,将数据从副本表移动到主表中。
上面的 MOVE PARTITION 调用使用了分区名 ()。这代表该表的单个分区(该表未进行分区)。对于已分区的表,用户需要多次调用 MOVE PARTITION——每个分区调用一次。当前各分区的名称可以从 system.parts 表中获取,例如:SELECT DISTINCT partition FROM system.parts WHERE (table = 'pypi_v2')。
现在我们可以确认 pypi 和 pypi_downloads 已包含全部数据。pypi_downloads_v2 和 pypi_v2 可以安全删除。
值得注意的是,MOVE PARTITION 操作既是轻量级的(利用硬链接),又是原子的,即要么失败要么成功,不会出现中间状态。
在下面的回填场景中,我们大量使用了这一机制。
请注意,此过程要求用户自行选择每次插入操作的数据量。
单次插入越大(即包含的行数越多),所需的 MOVE PARTITION 操作就越少。不过,这需要与插入失败(例如由于网络中断)时的恢复成本进行权衡。用户可以通过将文件分批处理来降低风险,以配合这一过程。可以使用范围查询(例如 WHERE timestamp BETWEEN 2024-12-17 09:00:00 AND 2024-12-17 10:00:00)或 glob 通配符模式来执行此操作。例如,
ClickPipes 在从对象存储加载数据时会使用这种方法,自动创建目标表及其 materialized view 的副本,从而避免用户手动执行上述步骤。通过同时使用多个 worker 线程(每个线程处理不同的子集(通过 glob 通配符模式)并拥有自己的一组副本表),可以在确保 exactly-once 语义的同时快速加载数据。感兴趣的读者可以在这篇博客中了解更多详情。
场景 1:在现有数据摄取基础上回填数据
在此场景中,我们假设需要回填的数据并不在一个独立的 bucket 中,因此需要进行过滤。数据已经在持续写入,并且可以确定一个时间戳或单调递增的列,用于界定需要回填的历史数据起点。
该过程包括以下步骤:
- 确定检查点——即需要恢复历史数据的起始时间戳或列值。
- 为主表和物化视图对应的目标表创建副本。
- 为步骤 (2) 中创建的目标表创建对应的物化视图副本。
- 将数据插入到在步骤 (2) 中创建的主表副本中。
- 将所有分区从副本表移动回其原始表,然后删除副本表。
例如,在我们的 PyPI 数据中,假设我们已经加载了数据。我们可以确定最小时间戳,并据此得到我们的“检查点”。
从上述结果可知,我们需要加载早于 2024-12-17 09:00:00 的数据。使用前面介绍的流程,我们创建主表和视图的副本,并通过在时间戳上添加过滤条件来加载这部分数据子集。
在 Parquet 中对时间戳列进行过滤可以非常高效。ClickHouse 只会读取时间戳列来确定需要加载的完整数据范围,从而将网络流量降到最低。Parquet 索引(例如 min-max)也可以被 ClickHouse 查询引擎充分利用。
一旦该插入操作完成,我们就可以移动相关的分区。
如果历史数据位于一个单独的 bucket,则不需要使用上述时间过滤器。若没有可用的时间列或单调递增列,请将历史数据单独隔离出来。
如果正在使用 ClickHouse Cloud,并且数据可以隔离在其自身的 bucket 中(且不需要过滤器),则应使用 ClickPipes 来恢复历史备份。除了可以通过多个 worker 并行加载以减少加载时间外,ClickPipes 还会将上述流程自动化——为主表和物化视图创建对应的副本表。
场景 2:向现有表添加物化视图
在已经填充了大量数据并且仍在持续插入数据的环境中,需要新增物化视图的情况并不少见。此时,如果能够利用时间戳或单调递增列来标识数据流中的某个时间点,将会非常有用,并且可以避免暂停数据摄取。在下面的示例中,我们假设两种情况都会存在,并优先采用不会中断摄取的方案。
我们不建议在除小型数据集且已暂停摄取的场景之外,使用 POPULATE 命令对物化视图进行回填。该操作可能会遗漏在其源表中插入的部分行,因为物化视图是在 populate 阶段完成之后才创建的。此外,该 populate 操作会作用于全部数据,在大数据集上容易受到中断或内存限制的影响。
存在时间戳或单调递增列
在这种情况下,我们建议在新的物化视图中添加一个过滤条件,仅保留那些时间大于某个将来的任意时间点的行。随后,可以从该时间点开始,使用主表中的历史数据对该物化视图进行回填。具体的回填方法取决于数据规模以及关联查询的复杂度。
最简单的方法包括以下步骤:
- 创建一个物化视图,并添加过滤条件,仅考虑时间大于某个临近未来任意时间点的行。
- 运行一条
INSERT INTO SELECT查询,从源表中读取数据并执行视图中的聚合查询,将结果插入物化视图的目标表。
在步骤 (2) 中,还可以进一步改进,仅针对数据子集进行处理,和/或为该物化视图使用一个单独的目标表(在插入完成后将分区附加到原始表中),以便在发生故障后更容易恢复。
考虑以下物化视图示例,它用于计算每小时最受欢迎的项目。
虽然我们可以先添加目标表,但在添加物化视图之前,我们会先修改其 SELECT 子句,添加一个过滤条件,仅考虑时间大于不久将来某个任意时间点的行——在本例中,我们假设 2024-12-17 09:00:00 是几分钟后的时间点。
添加此视图后,我们可以为该物化视图回填早于该时间点的所有历史数据。
最简单的方式是直接在主表上运行物化视图中的查询,并添加一个过滤条件以忽略最近新增的数据,然后通过 INSERT INTO SELECT 将结果插入到视图的目标表中。以上述视图为例:
在上述示例中,我们的目标表是 SummingMergeTree。在这种情况下,我们可以直接使用原始聚合查询。对于更复杂、基于 AggregatingMergeTree 的用例,则需要为聚合使用带有 -State 后缀的函数。相关示例见此集成指南。
在我们的示例中,这是一个相对轻量的聚合,在 3 秒内即可完成,且内存占用不到 600MiB。对于更复杂或运行时间更长的聚合,你可以通过前面提到的“复制目标表”方法来提高该过程的健壮性,即创建一个影子目标表,例如 pypi_downloads_per_day_v2,将数据先插入该表,然后再将其生成的分区附加到 pypi_downloads_per_day。
通常,物化视图对应的查询会更加复杂(这并不罕见,否则用户也没必要使用视图!),并且会消耗更多资源。在极少数情况下,该查询所需的资源甚至会超出单台服务器的能力范围。这也凸显了 ClickHouse 物化视图的一个优势——它们是增量式的,而不是一次性处理整个数据集!
在这种情况下,用户有多种可选方案:
- 修改查询以按时间范围回填,例如
WHERE timestamp BETWEEN 2024-12-17 08:00:00 AND 2024-12-17 09:00:00、WHERE timestamp BETWEEN 2024-12-17 07:00:00 AND 2024-12-17 08:00:00等。 - 使用 Null table engine 来填充物化视图。这会模拟物化视图典型的增量填充方式,即在数据块(大小可配置)上执行其查询。
(1) 是最简单且通常已经足够的方法。为简洁起见,我们不包含示例。
我们在下文进一步探讨 (2)。
使用 Null table engine 填充物化视图
Null table engine 提供了一种不会持久化数据的存储引擎(可以将其视为表引擎世界中的 /dev/null)。虽然这看起来有些矛盾,但对插入到该表引擎中的数据,物化视图仍然会照常执行。这样就允许在不持久化原始数据的情况下构建物化视图——从而避免 I/O 及相关存储开销。
需要重点注意的是,任何附加到该表引擎的物化视图在数据插入时,仍然会按数据块执行,并将其结果发送到一个目标表。这些数据块的大小是可配置的。较大的数据块可能更高效(并且处理速度更快),但会消耗更多资源(主要是内存)。使用该表引擎意味着我们可以以增量方式构建物化视图,即一次处理一个数据块,而无需将整个聚合过程都保存在内存中。
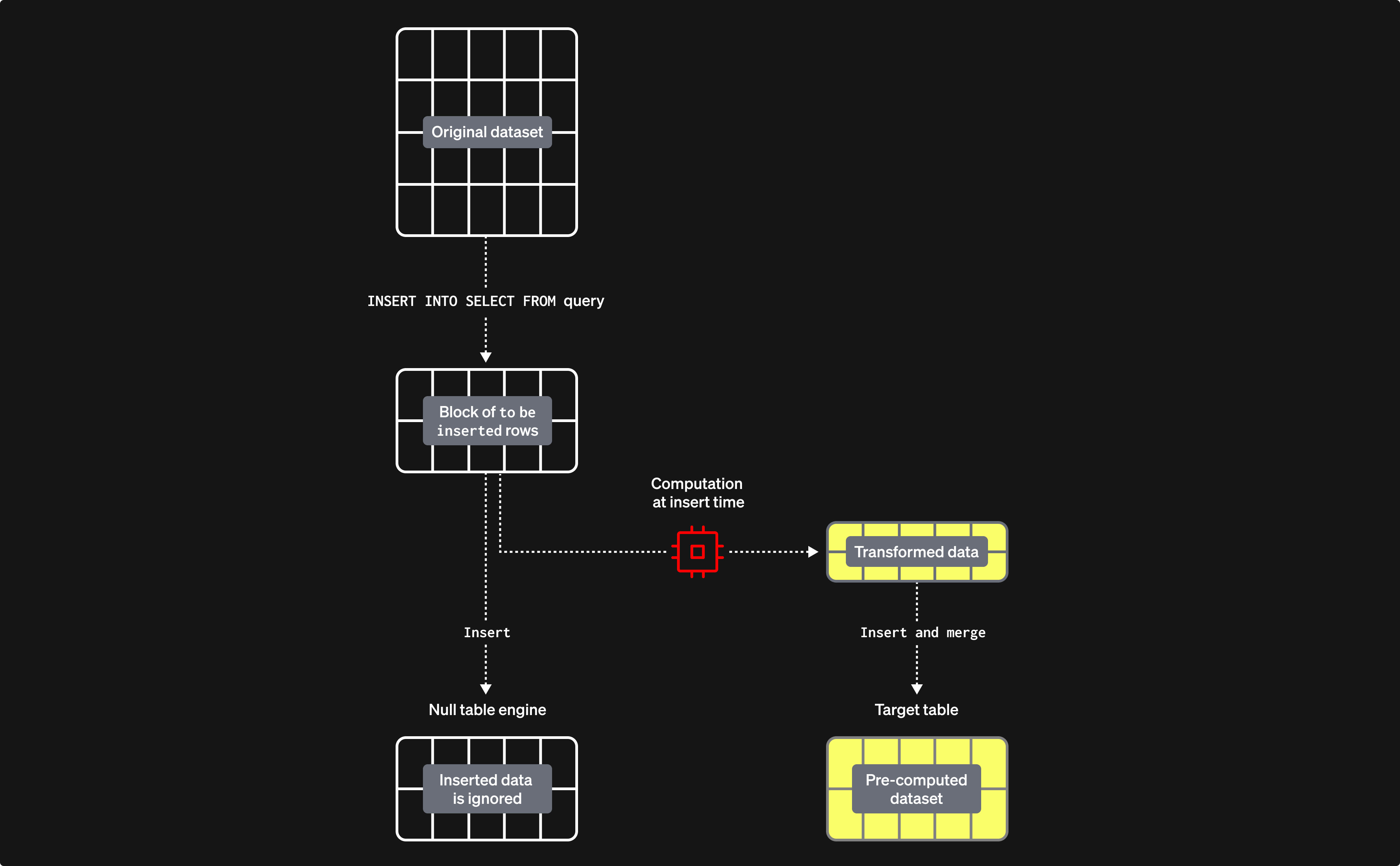
考虑下面的示例:
在这里,我们创建一个 Null 引擎表 pypi_v2,用于接收将被用来构建物化视图的行。注意我们将表结构限制为仅包含我们需要的列。我们的物化视图会对插入到该表中的行进行聚合(一次处理一个数据块),并将结果写入目标表 pypi_downloads_per_day。
在这里我们使用 pypi_downloads_per_day 作为目标表。为了获得更高的可靠性,用户可以创建一个副本表 pypi_downloads_per_day_v2,并像前面的示例那样将其作为视图的目标表。在插入完成后,可以将 pypi_downloads_per_day_v2 中的分区再移动到 pypi_downloads_per_day 中。这样在插入因内存问题或服务器中断而失败的情况下,仍然可以进行恢复,即只需截断 pypi_downloads_per_day_v2,调整设置,然后重试。
为了填充这个物化视图,我们只需将需要回填的相关数据从 pypi 插入到 pypi_v2 中。
请注意,这里的内存占用为 639.47 MiB。
调优性能和资源
在上述场景中,有多个因素会影响性能和资源使用情况。在尝试调优之前,建议先理解《Optimizing for S3 Insert and Read Performance》指南中 Using Threads for Reads 一节所详细说明的写入机制。总结如下:
- 读取并行度(Read Parallelism) - 用于读取的线程数,通过
max_threads控制。在 ClickHouse Cloud 中,该值由实例规格决定,默认等于 vCPU 数量。增大该值可能提升读取性能,但会增加内存占用。 - 写入并行度(Insert Parallelism) - 用于执行写入的线程数,通过
max_insert_threads控制。注意:该值受max_threads限制,因此实际有效的写入并行度为min(max_insert_threads, max_threads)。在 ClickHouse Cloud 中,该值由实例规格决定(介于 2 到 4 之间),在 OSS 中默认为 1。增大该值可能提升写入性能,但会增加内存占用。 - 写入块大小(Insert Block Size) - 数据在一个循环中被处理:从源拉取、解析,并根据分区键 组装成内存中的写入块。这些块随后会被排序、优化、压缩,并作为新的数据 part 写入存储。写入块的大小由
min_insert_block_size_rows和min_insert_block_size_bytes(未压缩)设置控制,会影响内存使用和磁盘 I/O。更大的块会占用更多内存,但会生成更少的 part,从而减少 I/O 和后台合并。这些设置表示最小阈值(先达到的阈值会触发一次刷新(flush))。 - 物化视图块大小(Materialized view block size) - 除了上述针对主表写入的机制外,在写入物化视图之前,数据块同样会被压缩合并(squash),以实现更高效的处理。这些块的大小由
min_insert_block_size_bytes_for_materialized_views和min_insert_block_size_rows_for_materialized_views设置决定。更大的块可以更高效地处理数据,但会增加内存占用。默认情况下,这些设置会分别回退到源表设置min_insert_block_size_rows和min_insert_block_size_bytes的值。
针对简单 INSERT SELECT 查询的提示:对于不包含复杂转换的简单 INSERT INTO t1 SELECT * FROM t2 查询,可以考虑启用 optimize_trivial_insert_select=1。该设置(自 24.7 版本起默认禁用)会自动将 SELECT 的并行度调整为与 max_insert_threads 一致,从而降低资源使用并减少创建的分区片段数量。这对于在表之间执行大量数据迁移尤其有用。
为了提升性能,你可以参考《Optimizing for S3 Insert and Read Performance》指南中 Tuning Threads and Block Size for Inserts 一节的指导。在大多数情况下,无需另外修改 min_insert_block_size_bytes_for_materialized_views 和 min_insert_block_size_rows_for_materialized_views 也能获得性能提升。如果确实需要修改它们,请遵循对 min_insert_block_size_rows 和 min_insert_block_size_bytes 所讨论的相同最佳实践。
为尽量减少内存使用,你可以尝试调整这些设置,但这几乎必然会降低性能。基于前文的查询,我们在下面展示了一些示例。
将 max_insert_threads 降低为 1 可以减少内存开销。
通过将 max_threads 设置为 1,我们可以进一步降低内存占用。
最后,我们可以通过将 min_insert_block_size_rows 设置为 0(禁用其作为决定块大小的因素)以及将 min_insert_block_size_bytes 设置为 10485760(10MiB)来进一步减少内存占用。
最后,请注意,减小块大小会产生更多的分区片段,并带来更大的合并压力。正如此处所讨论的,应谨慎调整这些设置。
没有时间戳或单调递增列
上述过程依赖于表中存在时间戳或单调递增列。在某些情况下,这样的列并不存在。此时,我们推荐以下流程,它复用前面概述的许多步骤,但需要用户暂停数据摄取。
- 暂停向主表执行
INSERT。 - 使用
CREATE AS语法创建主目标表的副本。 - 使用
ALTER TABLE ATTACH将原始目标表中的分区附加到副本上。注意: 此附加操作不同于之前使用的移动操作。虽然依赖硬链接,但原始表中的数据会被保留。 - 创建新的物化视图。
- 重新开始执行
INSERT。注意:INSERT只会更新目标表,而不会更新副本,副本仅引用原始数据。 - 为物化视图进行回填,复用上文对带时间戳数据使用的相同流程,将副本表作为数据源。
考虑以下使用 PyPI 和我们之前创建的新物化视图 pypi_downloads_per_day 的示例(我们假设无法使用时间戳):
在倒数第二步中,我们使用前文介绍的简单 INSERT INTO SELECT 方法为 pypi_downloads_per_day 进行回填。也可以结合上文中记录的 Null 表方案进行增强,并可选择使用副本表以提高可靠性。
虽然此操作确实需要暂停插入,但中间操作一般可以较快完成,从而将数据写入中断降到最低。
