仓库
计算-计算分离 is available in the Scale and Enterprise plans. To upgrade, visit the plans page in the cloud console.
什么是计算-计算分离?
在讨论什么是计算-计算分离之前,先了解 ClickHouse Cloud 中 service 的含义会很有帮助。
每个 ClickHouse Cloud service 包括:
- ClickHouse 计算节点 (称为 副本) ,配备专用的 CPU 和内存资源集群
- 一个端点 (或通过 ClickHouse Cloud UI 控制台创建的多个端点) ,用于连接到该 service (例如,
https://dv2fzne24g.us-east-1.aws.clickhouse.cloud:8443) ,供本地和第三方应用程序连接 - 一个对象存储文件夹,service 在其中存储所有数据以及部分元数据:
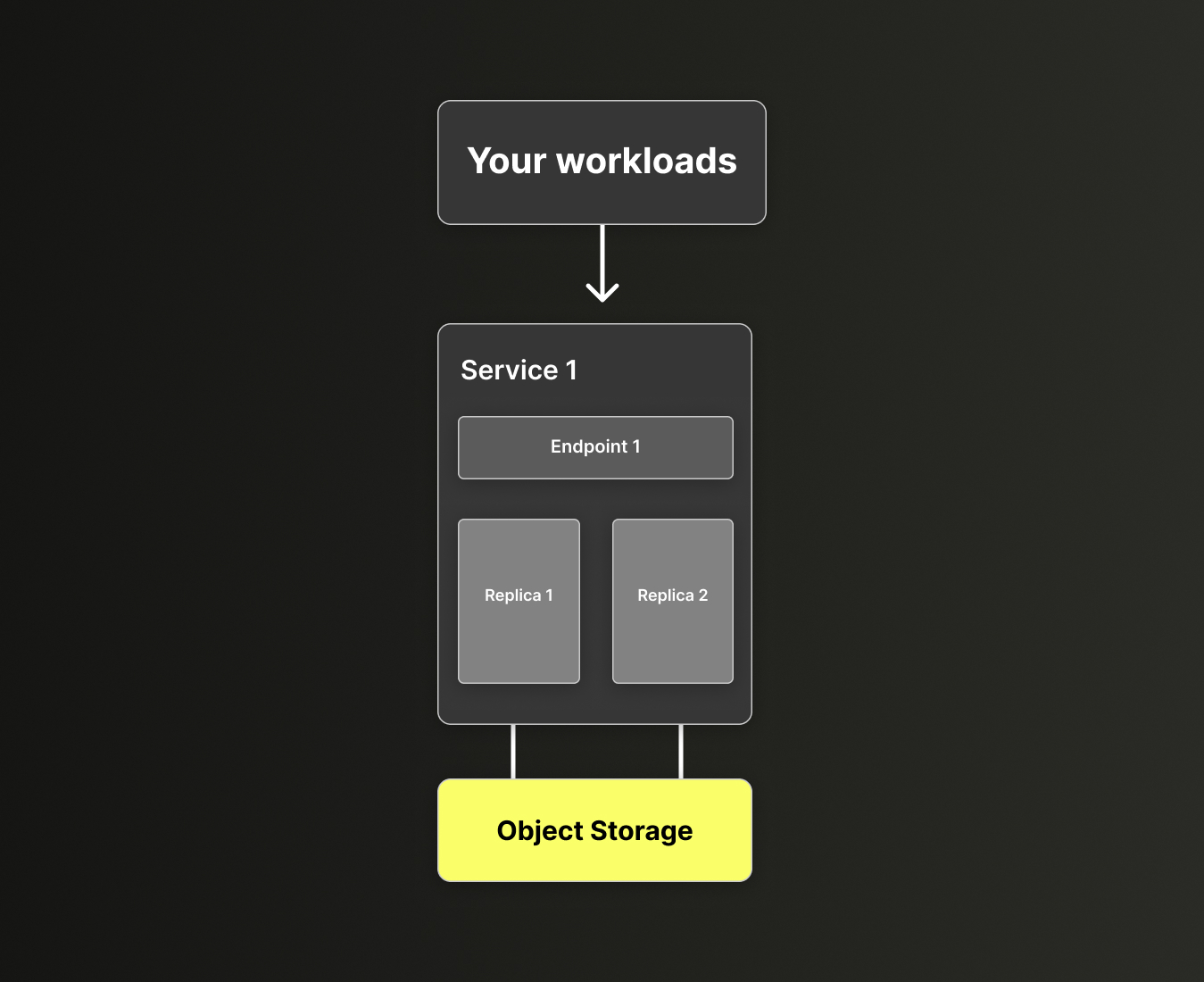
图 1 - ClickHouse Cloud 中的单个 service
你可以创建多个可访问同一共享存储的 service,而不只是使用单个 service。这样就能为特定工作负载分配专用资源,而无需复制数据。 这一概念称为 计算-计算分离。
计算-计算分离意味着每个 service 都有自己的一组副本和一个端点,但它们使用相同的对象存储文件夹,并访问相同的表、视图等。 这意味着你可以为工作负载选择合适规格的计算资源。有些工作负载可能只需一个小规格副本即可满足,而另一些则可能需要完整的高可用性 (HA) ,以及多个副本上的数百 GB 内存。
计算-计算分离还允许你将读操作与写操作分离开来,使它们不会相互干扰:
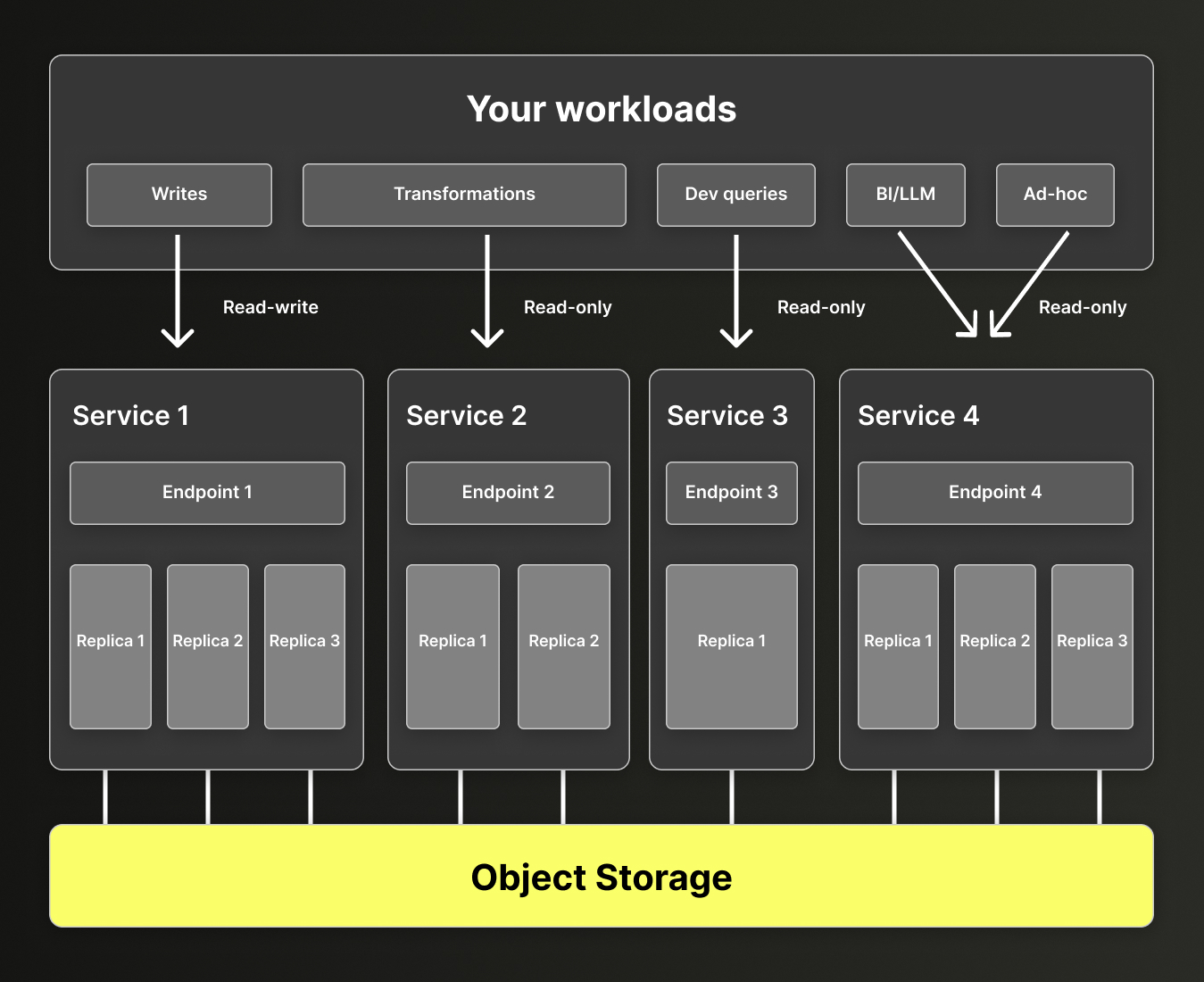
图 2 - ClickHouse Cloud 中的计算分离
什么是仓库?
在 ClickHouse Cloud 中,仓库 (warehouse) 是共享同一数据的一组 服务。 每个仓库都有一个主服务 (最先创建的服务) 和一个或多个次级服务。例如,在下面的截图中,您可以看到一个名为 "DWH Prod" 的仓库,其中包含两个服务:
- 主服务
DWH Prod - 次级服务
DWH Prod Subservice

图 3 - 仓库示例
同一仓库中的所有服务共享以下内容:
- 区域 (例如,us-east1)
- 云服务提供商 (AWS、GCP 或 Azure)
- ClickHouse 数据库版本
- ClickHouse Keeper (用于管理副本)
访问控制
数据库凭证
由于同一仓库中的所有服务共享同一组表,它们也共享跨服务的访问控制。 这意味着,在 Service 1 中创建的所有数据库用户,也能够以相同的权限 (对表、视图等的授权) 使用 Service 2,反之亦然。 每个服务使用不同的访问端点 (endpoint) ,但所有服务都使用相同的用户名和密码。换句话说,如下图所示,在使用同一存储的服务之间,用户是共享的:
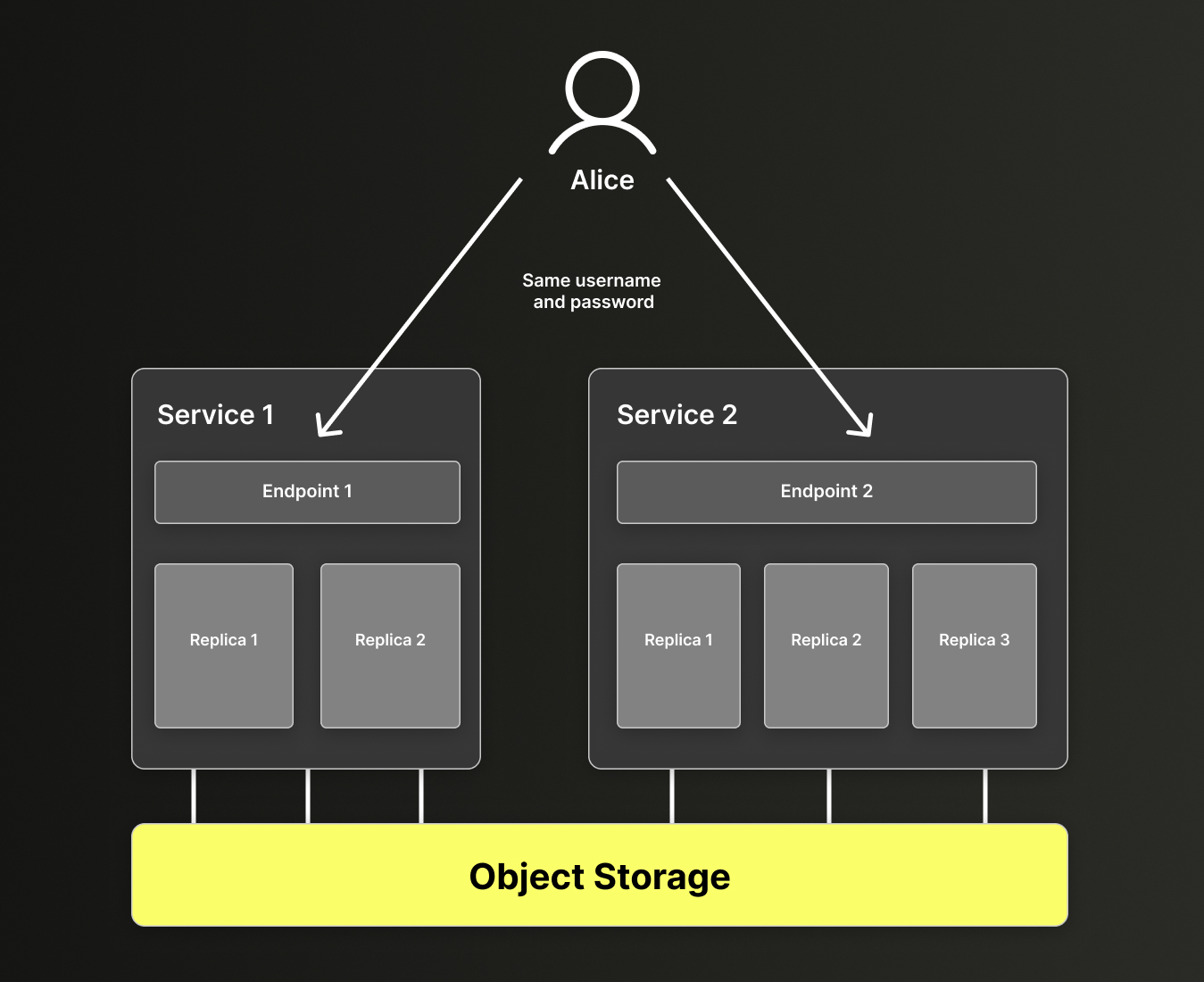
图 4 - 用户 Alice 在 Service 1 中创建,但她可以使用相同的凭证访问所有共享同一数据的服务
网络访问控制
要限制其他应用或临时用户对特定服务的访问,可以应用网络访问限制。 为此,请在 ClickHouse Cloud 控制台中,进入你希望限制访问的特定服务的服务选项卡中的 Settings。
IP 过滤设置可分别应用于每个服务,这意味着你可以控制哪个应用可以访问哪个服务。 这样一来,你就可以限制用户使用特定服务。
在下面的示例中,Alice 被限制访问仓库中的服务 2:
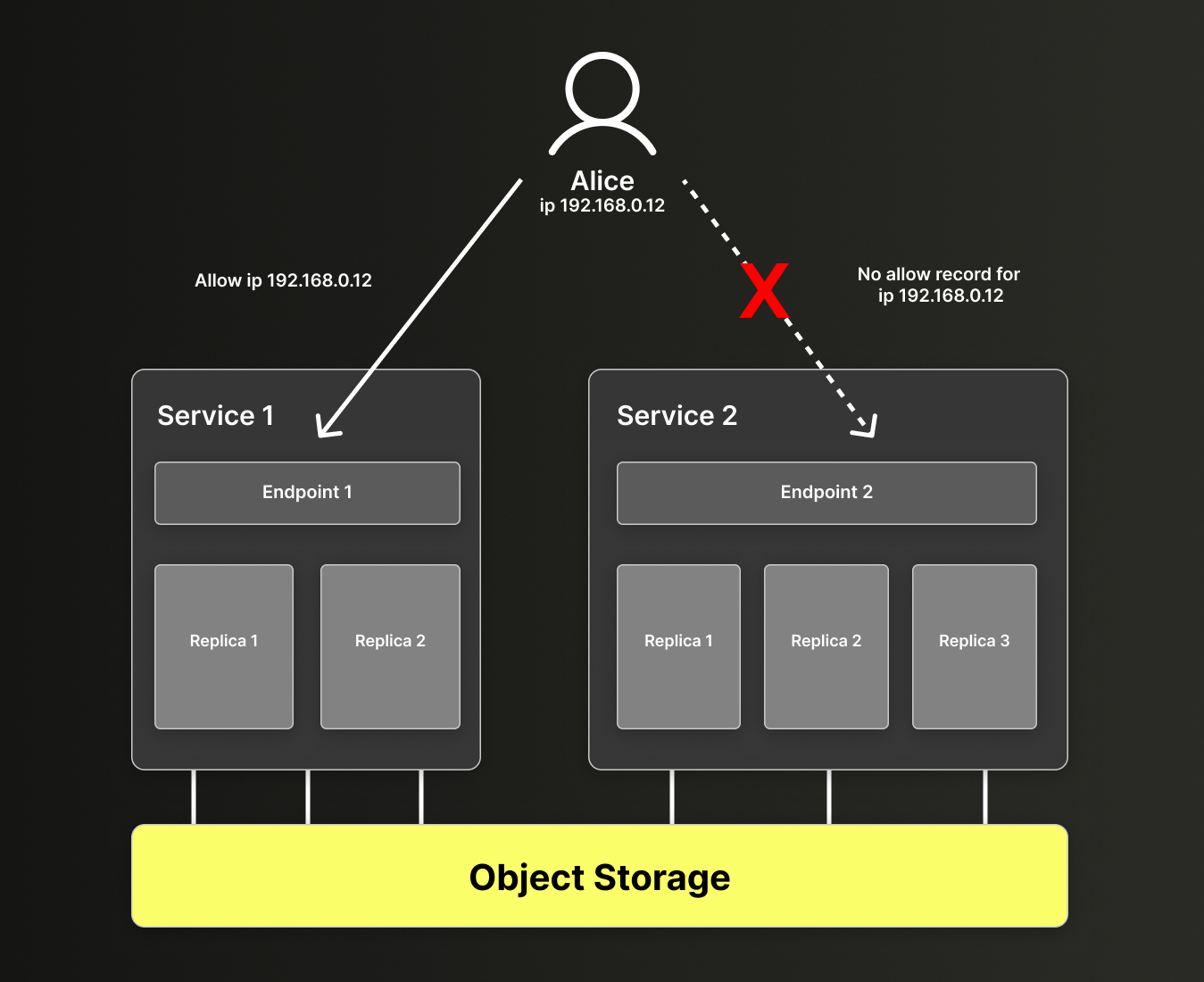
图 5 - 由于网络访问控制设置,Alice 被限制访问服务 2
当用户以个人身份连接,而不是使用 default 用户时,也可以使用 ClickHouse 角色和授权来控制其对数据的访问。
只读与读写服务
服务类型可以是以下之一:
- 读写
- 既可以读取 ClickHouse 中的数据,也可以向其中写入数据
- 执行后台合并操作 (例如,数据插入后合并 parts) ,这会消耗 CPU 和内存
- 可以将数据导出到外部
- 只读
- 只能读取数据;不能在 ClickHouse 中写入或修改数据
- 除系统表外,不执行后台合并操作,因此其资源可完全用于读查询
- 仍然可以将数据导出到外部 (例如,通过 table function) ,但不能更改 ClickHouse 内部的数据
- 可立即进入空闲状态;而读写服务可能因后台合并而持续保持唤醒状态。
有时,你可能希望将关键读取工作负载与写入/合并开销隔离,因此会将某个服务配置为只读。 你可以对第二个服务以及后续创建的任何附加服务这样做;但是,第一个服务始终是读写的,如下图所示:
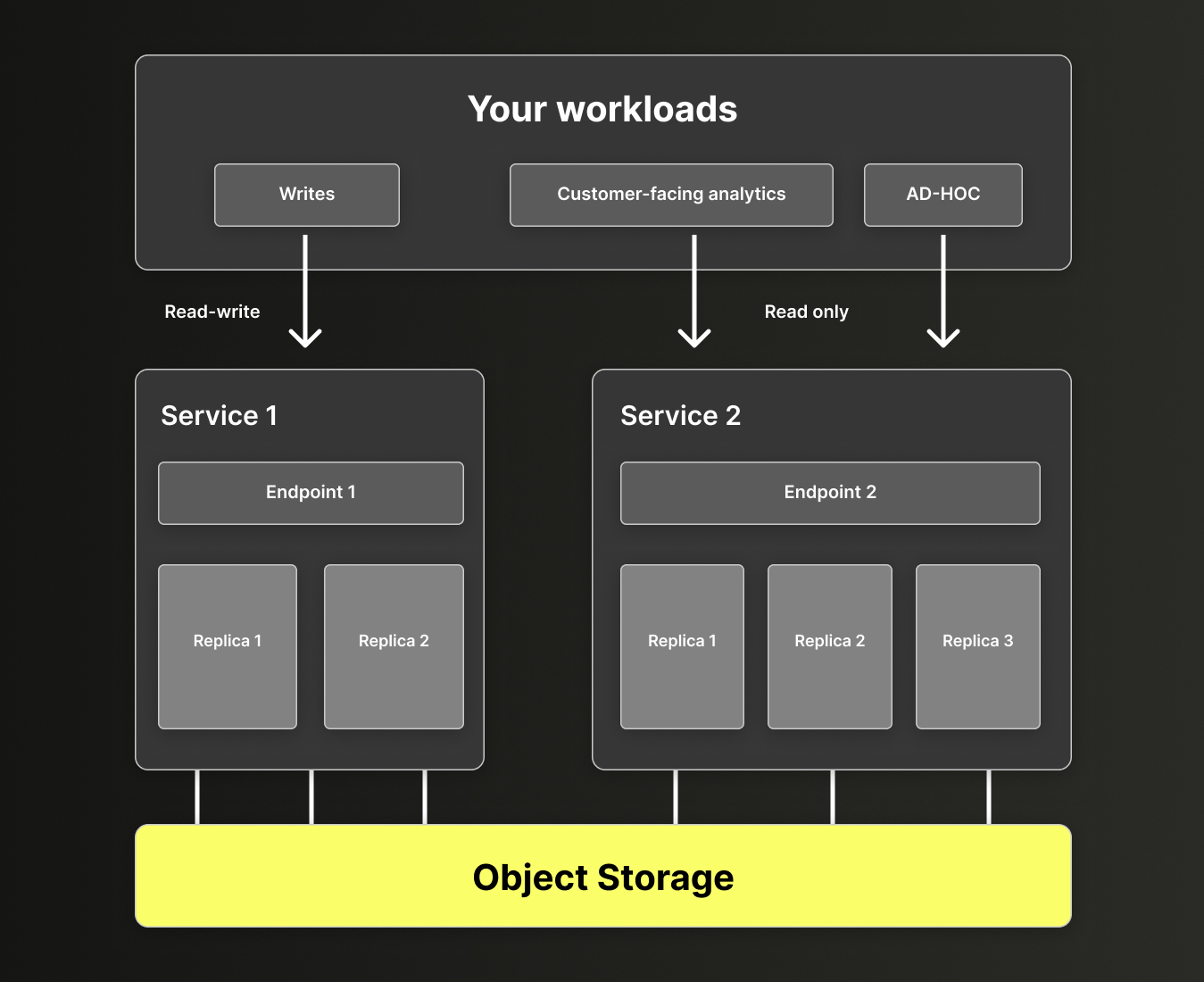
图 6 - 仓库中的读写与只读服务
- 只读服务当前支持用户管理操作 (CREATE、DROP 等) 。
- 可刷新materialized view 仅在仓库中的读写 (RW) 服务上运行。
- 服务类型 (只读或读写) 在创建时即已固定,之后无法在 Cloud Console 中修改。若要在只读和读写访问之间切换,请在该仓库中创建一个具有所需类型的新服务。
扩展
仓库中的每个服务都可以根据您的工作负载在以下方面进行调整:
- 节点 (副本) 数量。主服务 (在该仓库中首先创建的服务) 应具有 2 个或更多节点。每个次级服务可以有 1 个或更多节点。
- 节点 (副本) 规格
- 服务是否应自动扩展 (水平和垂直)
- 服务在空闲时是否应被停用
有关更多信息,请参阅"自动扩展"页面。
clusterAllReplicas 行为的变化
一旦一个仓库拥有多个服务,clusterAllReplicas() 的行为就会发生变化。
使用 default 集群名称时,只会定位当前服务内的副本,而不是仓库中的所有服务。
例如,如果你从服务 1 调用 clusterAllReplicas(default, system, processes),只会返回在服务 1 上运行的进程。
要查询仓库中的所有服务,请改用 all_groups.default 集群名称:
次级单节点服务可以垂直扩展,而主单节点服务则不能。
限制
工作负载隔离限制
某些工作负载无法隔离到特定服务;在某些边缘场景下,一个服务中的工作负载会影响同一工作区中的另一个服务。这些情况包括:
-
默认情况下,所有读写服务都会处理后台合并操作。 当向 ClickHouse 插入数据时,数据库首先会将数据插入到某些临时分区中,然后在后台执行合并。这些合并操作会消耗内存和 CPU 资源。当两个读写服务共享同一存储时,它们都会执行后台操作。这意味着可能会出现这样的情况:在服务 1 中执行了
INSERT查询,但合并操作由服务 2 完成。 请注意,只读服务不会执行后台合并,因此它们不会在此操作上消耗自身资源。我们的支持团队可以关闭某个服务上的合并操作。 -
所有读写服务都会执行 S3Queue 表引擎的插入操作。 当在一个读写服务上创建 S3Queue 表时,同一工作区中的所有其他读写服务也可能会从 S3 读取数据并将其写入数据库。
-
在一个读写服务上的插入操作可能会阻止另一个读写服务进入休眠 (当启用休眠时) 。 在某些情况下, 一个服务会为另一个服务执行后台合并操作。这些后台操作可能会阻止第二个服务进入休眠。一旦后台操作完成,该服务就会进入休眠。只读服务不受影响。
实用提示
-
ClickHouse 版本:升级计划 由主服务的设置决定。次级服务不能拥有独立于主服务的发布计划。
-
默认情况下,
CREATE/RENAME/DROP DATABASE查询可能会因服务处于休眠/停止状态而被阻塞。 如果在服务处于休眠或停止状态时执行这些查询,查询可能会挂起。要绕过此问题,你可以在会话级别或单条查询级别使用settings distributed_ddl_task_timeout=0运行数据库管理查询。
例如:
如果您手动停止某个服务,则需要再次将其启动,查询才能执行。
- 单副本主服务 当前默认情况下,次级服务可以只有一个副本,但主服务必须至少有 2 个副本。 要启用单副本主服务,请联系支持。此行为将在 2026 年第二季度默认启用。
- 主服务休眠:主服务自动休眠已默认启用。
定价
在同一个仓库中,所有服务 (主和次级) 的计算价格都相同。存储只计费一次——它包含在第一个 (原始) 服务中。
请参阅定价页面上的价格计算器,它可以根据您的工作负载规模和所选层级帮助估算成本。Usage Breakdown 表将显示各服务的计算成本明细。
备份
- 由于同一仓库中的所有服务共享同一存储,因此只在主 (初始) 服务上执行备份。通过这种方式,可以备份该仓库中所有服务的数据。
- 如果你从某个仓库的主服务还原备份,该备份会被还原到一个全新的服务,而不是还原到与现有仓库关联的服务上。还原完成后,你可以立即为这个新服务添加更多服务。
如何创建仓库
创建仓库
要创建一个仓库,需要创建第二个服务,以与现有服务共享数据。可以通过单击任一现有服务上的加号来完成此操作:
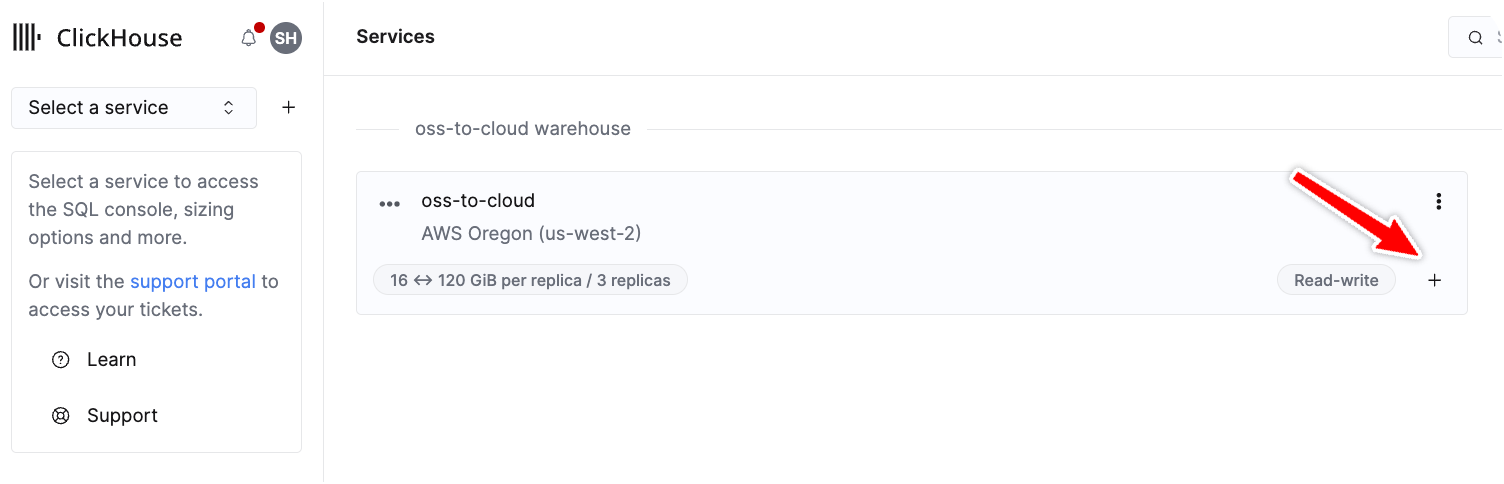
图 7 - 单击加号以在仓库中创建新服务
在服务创建界面中,原始服务会在下拉列表中被选为新服务的数据来源。创建完成后,这两个服务将共同组成一个仓库。
重命名仓库
重命名仓库有两种方法:
- 在服务页面右上角选择“Sort by warehouse”,然后点击仓库名称旁边的铅笔图标;
- 点击任一服务上的仓库名称,并在弹出的界面中重命名仓库。
删除仓库
删除仓库意味着删除所有计算服务以及其中的数据(表、视图、用户等)。此操作无法撤销。 只能通过删除第一个创建的服务来删除一个仓库。执行步骤如下:
- 删除除最先创建的服务之外的所有后续创建的服务;
- 删除第一个服务(警告:在此步骤中将删除该仓库的所有数据)。
