SharedMergeTree 表引擎
SharedMergeTree 表引擎家族是 ReplicatedMergeTree 引擎的云原生替代方案,经过优化以在共享存储之上运行 (例如 Amazon S3、Google Cloud Storage、MinIO、Azure Blob Storage) 。每一种具体的 MergeTree 引擎类型都有对应的 SharedMergeTree 版本,例如 SharedReplacingMergeTree 替代 ReplicatedReplacingMergeTree。
SharedMergeTree 表引擎家族为 ClickHouse Cloud 提供支持。对于终端用户而言,无需进行任何更改,即可开始使用 SharedMergeTree 引擎家族来替代基于 ReplicatedMergeTree 的引擎。它带来了以下额外优势:
- 更高的插入吞吐量
- 更高的后台合并吞吐量
- 更高的变更吞吐量
- 更快速的扩容和缩容操作
- 为 select 查询提供更加轻量的强一致性保证
SharedMergeTree 带来的一个重要改进是,相比 ReplicatedMergeTree,它在计算与存储之间实现了更深层次的分离。下面展示了 ReplicatedMergeTree 如何分离计算与存储:
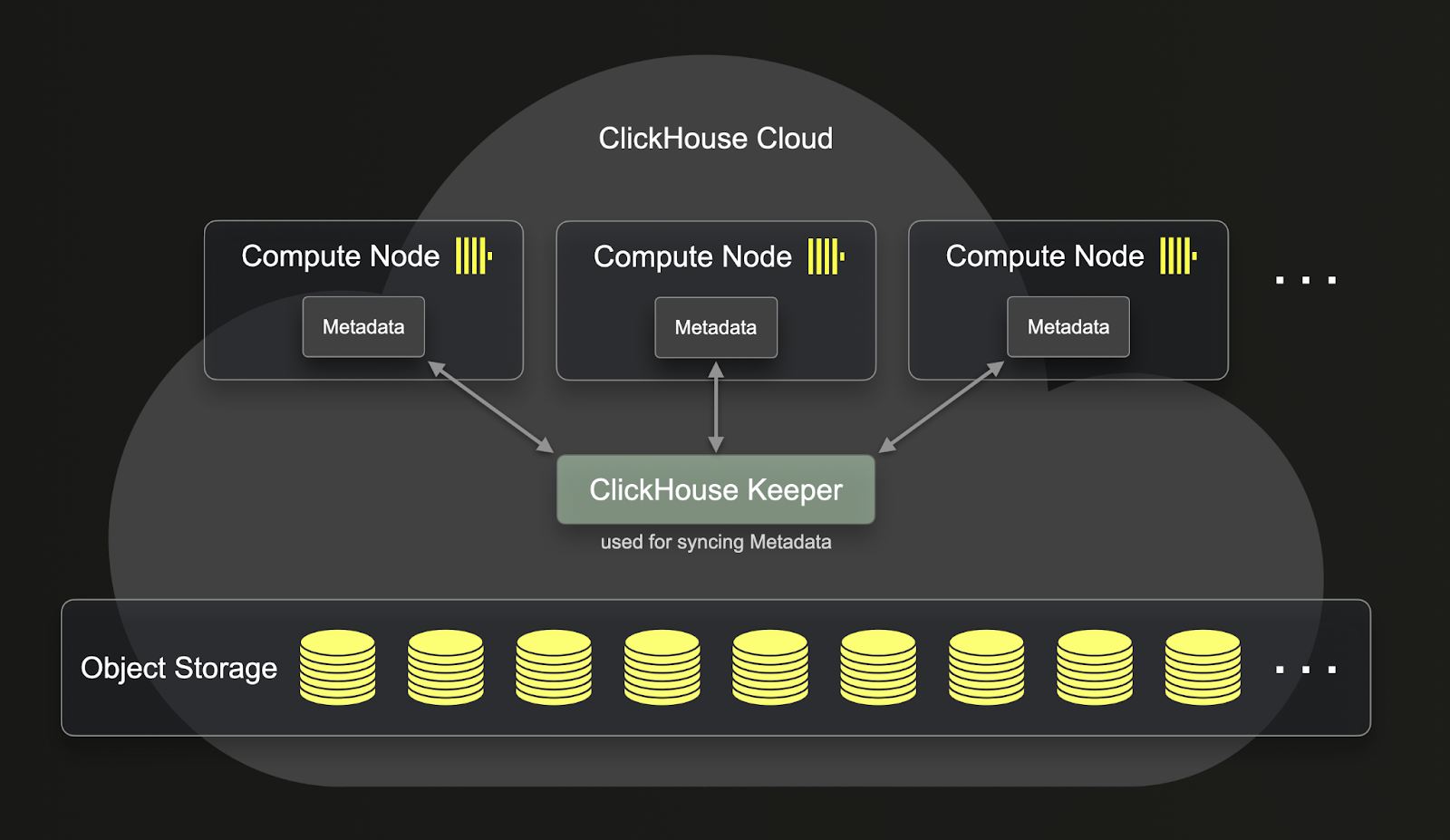
可以看到,即使 ReplicatedMergeTree 中的数据存储在对象存储中,元数据仍然保存在每个 clickhouse-server 上。这意味着对于每一次复制操作,元数据也需要在所有副本上进行复制。
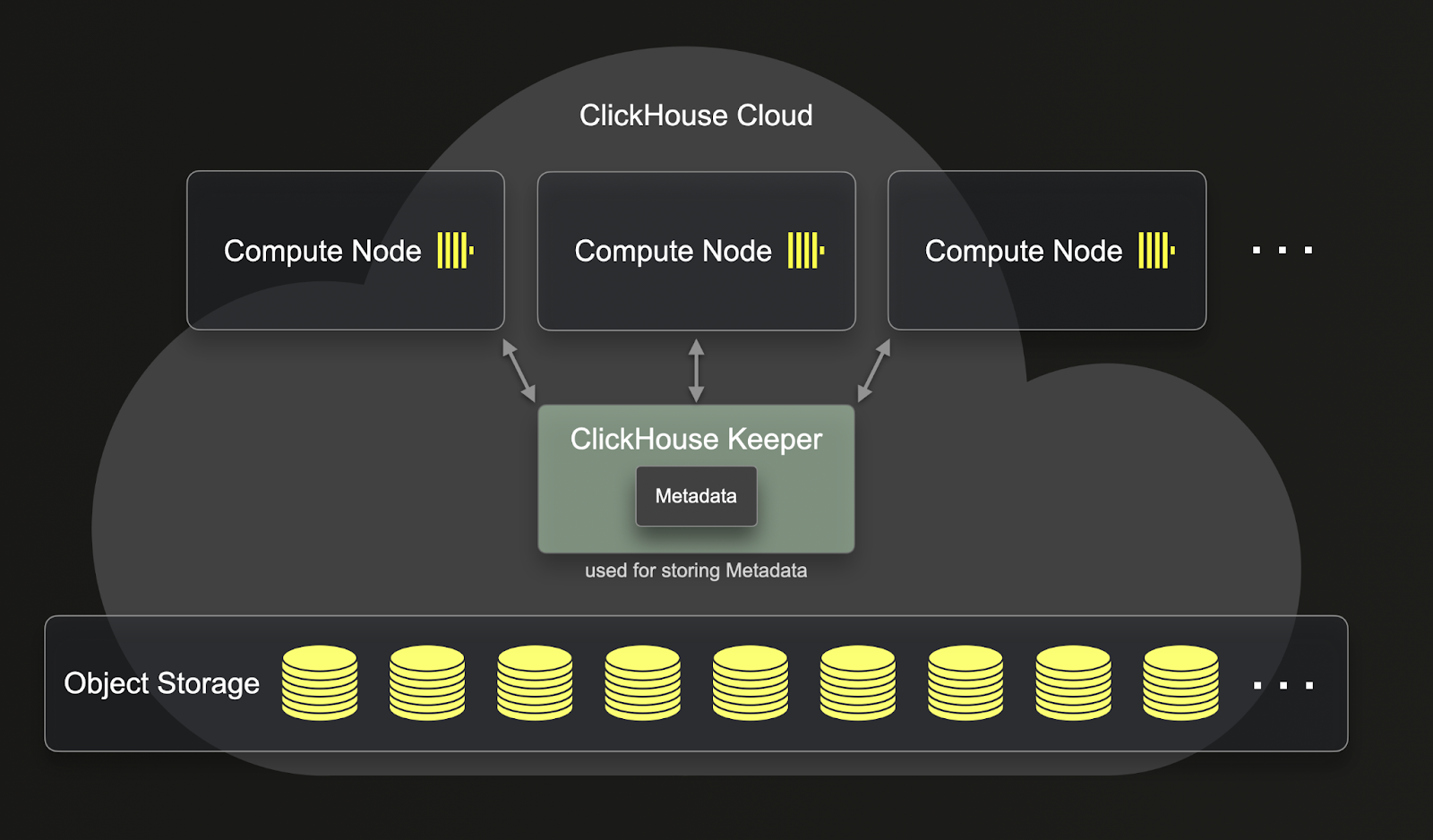
与 ReplicatedMergeTree 不同,SharedMergeTree 不需要副本之间互相通信。相反,所有通信都通过共享存储和 clickhouse-keeper 完成。SharedMergeTree 实现了异步的无主复制,并使用 clickhouse-keeper 进行协调和元数据存储。这意味着当你的服务扩容和缩容时,无需复制元数据。这带来了更快速的复制、变更、合并以及扩容操作。SharedMergeTree 允许每张表拥有数百个副本,从而可以在无需分片的情况下实现动态伸缩。在 ClickHouse Cloud 中,会使用分布式查询执行方式,为单个查询利用更多的计算资源。
内省
用于对 ReplicatedMergeTree 进行内省的大多数系统表在 SharedMergeTree 中同样存在,system.replication_queue 和 system.replicated_fetches 除外,因为 SharedMergeTree 中不会发生数据和元数据的复制。不过,SharedMergeTree 为这两个表提供了相应的替代表。
system.virtual_parts
此表在 SharedMergeTree 中作为 system.replication_queue 的替代表。它存储最近一组当前分区片段的信息,以及正在进行中的、即将生成的分区片段的信息,例如合并(merge)、变更(mutation)和被删除的分区。
system.shared_merge_tree_fetches
此表是 SharedMergeTree 中 system.replicated_fetches 的替代表。它包含当前正在进行中的将主键和校验和拉取到内存的操作信息。
启用 SharedMergeTree
SharedMergeTree 默认已启用。
对于支持 SharedMergeTree 表引擎的服务,您无需手动启用任何功能。您可以像之前一样创建表,系统会自动使用基于 SharedMergeTree 的表引擎,该引擎与在 CREATE TABLE 语句中指定的引擎相对应。
这将使用 SharedMergeTree 表引擎创建名为 my_table 的表。
在 ClickHouse Cloud 中,您无需指定 ENGINE=MergeTree,因为已将 default_table_engine 设置为 MergeTree。下面的查询与上面的查询是等价的。
如果您使用 ReplacingMergeTree、CollapsingMergeTree、AggregatingMergeTree、SummingMergeTree、VersionedCollapsingMergeTree 或 GraphiteMergeTree 表,它们会自动转换为相应的 SharedMergeTree 系列表引擎。
对于某个表,可以通过执行 SHOW CREATE TABLE 命令来查看其 CREATE TABLE 语句中使用的表引擎:
设置
某些设置的行为发生了显著变化:
insert_quorum-- 所有对 SharedMergeTree 的插入都是 quorum 插入(写入到共享存储),因此在使用 SharedMergeTree 表引擎时无需配置该设置。insert_quorum_parallel-- 所有对 SharedMergeTree 的插入都是 quorum 插入(写入到共享存储),因此在使用 SharedMergeTree 表引擎时无需配置该设置。select_sequential_consistency-- 不要求使用 quorum 插入,但会在执行SELECT查询时给 clickhouse-keeper 带来额外负载。
一致性
SharedMergeTree 相比 ReplicatedMergeTree 提供更好的轻量级一致性。向 SharedMergeTree 执行插入时,无需设置诸如 insert_quorum 或 insert_quorum_parallel 之类的参数。插入本身就是 quorum 插入,这意味着元数据会存储在 ClickHouse-Keeper 中,并会被复制到至少达到 quorum 的 ClickHouse-Keeper 节点。集群中的每个副本都会从 ClickHouse-Keeper 异步拉取最新的元数据信息。
在大多数情况下,无需使用 select_sequential_consistency 或 SYSTEM SYNC REPLICA LIGHTWEIGHT。异步复制足以覆盖绝大多数场景,并且具有非常低的延迟。只有在极少数确实需要避免陈旧读的情况下,才需要按以下优先级进行处理:
-
如果在同一会话或同一节点上执行读写查询,则无需使用
select_sequential_consistency,因为该副本已经拥有最新的元数据。 -
如果向一个副本写入而从另一个副本读取,可以使用
SYSTEM SYNC REPLICA LIGHTWEIGHT强制该副本从 ClickHouse-Keeper 获取元数据。 -
在查询中通过设置启用
select_sequential_consistency。
