ClickHouse Cloud 架构
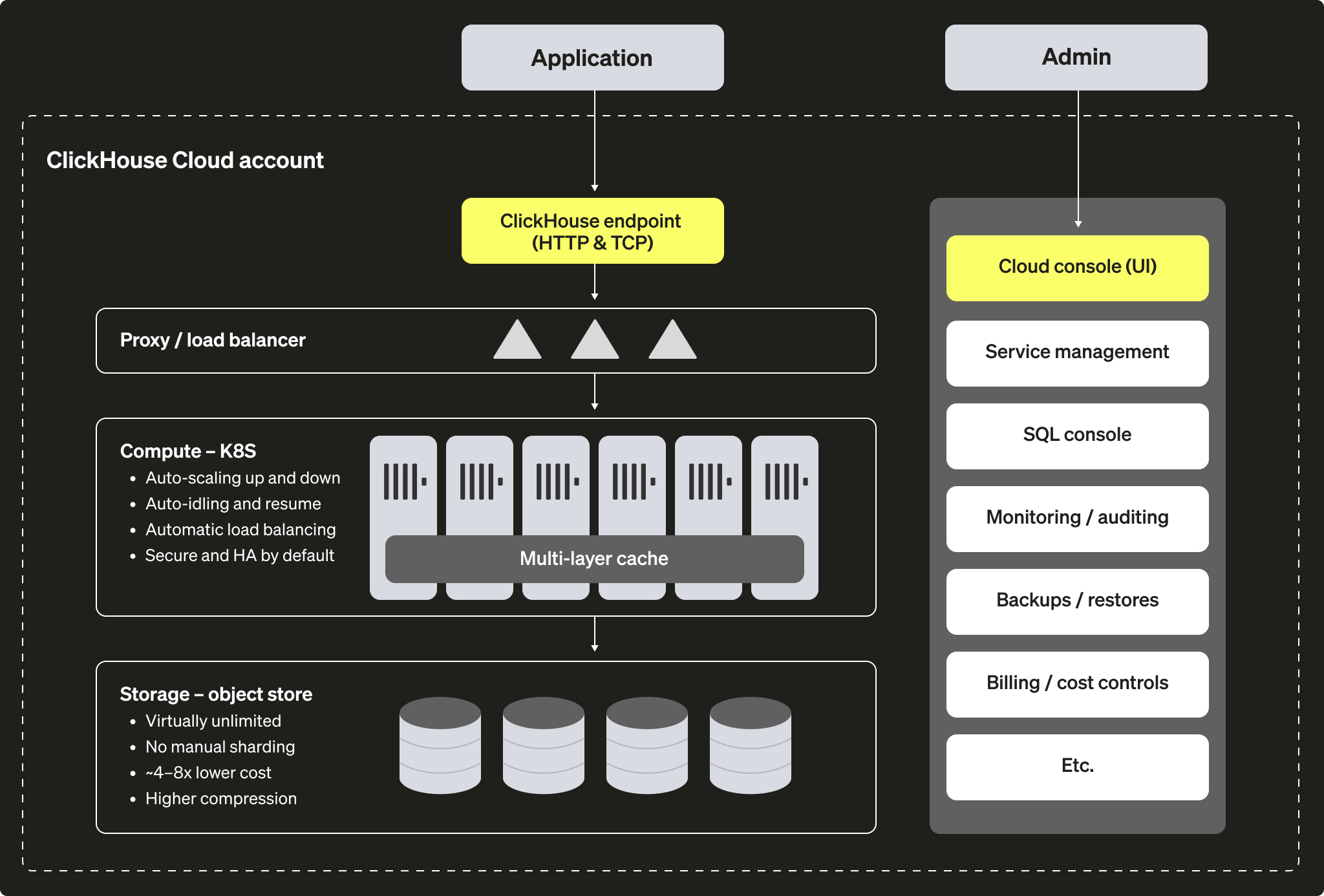
基于对象存储的存储
- 几乎无限的存储容量
- 无需手动对数据进行分片
- 存储数据的成本显著更低,尤其适用于访问频率较低的数据
计算
- 自动伸缩与闲置管理:无需提前规划规格,也无需为峰值用量过度预留资源
- 自动闲置与唤醒:在无人使用时无需让空转的计算资源持续运行
- 默认安全且高可用
管理
- 设置、监控、备份和计费等工作由我们代为处理。
- 成本控制默认启用,您可以通过 Cloud 控制台进行调整。
服务隔离
网络隔离
所有服务在网络层面上彼此隔离。
计算隔离
所有服务都部署在各自 Kubernetes 命名空间中的独立 pod(容器组)中,并在网络层面实现隔离。
存储隔离
所有服务都在共享的 bucket(AWS、GCP)或存储容器(Azure)中使用各自独立的子路径。
对于 AWS,访问存储通过 AWS IAM 控制,每个 IAM 角色都与单个服务唯一对应。对于 Enterprise 服务,可以启用 CMEK,以在数据静态存储(at rest)时提供更高级的数据隔离。CMEK 目前仅支持 AWS 服务。
对于 GCP 和 Azure,各服务在对象存储层面是隔离的(每个服务都有自己的 bucket 或存储容器)。
计算-计算分离
计算-计算分离 允许你创建多个计算节点组,每个计算节点组都有自己的服务 URL,并共享同一个对象存储。这样可以在共享同一份数据的前提下,将不同用例(例如读写分离)的计算负载进行隔离。同时,通过按需独立伸缩各个计算组,还能实现更高效的资源利用。
并发限制
在 ClickHouse Cloud 服务中,每秒查询数 (QPS) 没有上限。不过,每个副本的并发查询数上限为 1000。QPS 最终取决于平均查询执行时间以及服务中的副本数量。
与自管理的 ClickHouse 实例或其他数据库/数据仓库相比,ClickHouse Cloud 的一大优势是,可以通过增加副本数量 (水平扩展) 轻松提升并发能力。
