ClickHouse Cloud 控制台中的监控
ClickHouse Cloud 中的服务内置了开箱即用的监控组件,可为用户提供仪表板和通知。默认情况下,Cloud 控制台中的所有用户都可以访问这些仪表板。
仪表板
服务健康
“服务健康”仪表板可用于监控服务的整体健康状况。ClickHouse Cloud 会从系统表中抓取并存储此仪表板显示的指标,以便在服务闲置时也能查看。
资源利用率
Infrastructure 仪表板详细展示了 ClickHouse 进程使用的资源情况。ClickHouse Cloud 会从系统表中抓取并存储此仪表板显示的指标,以便在服务处于闲置状态时仍可查看这些指标。
内存和 CPU
Allocated CPU 和 Allocated Memory 图表显示服务中每个副本可用的总计算资源。这些资源分配可通过 ClickHouse Cloud 的扩缩容功能进行调整。
Memory Usage 和 CPU Usage 图表用于估算每个副本中 ClickHouse 进程实际使用的 CPU 和内存量,其中既包括查询,也包括合并等后台进程。
以下是这些图表中显示的对应 system table 指标:
| 图表 | 对应指标名称 | 聚合 | 说明 |
|---|---|---|---|
| 已分配内存 | CGroupMemoryTotal | 最大值 | |
| 已分配 CPU | CGroupMaxCPU | 最大值 | |
| 已用内存 | MemoryResident | 最大值 | |
| 已用 CPU | 系统 CPU 指标 | 最大值 | 通过 Prometheus endpoint 获取的 ClickHouseServer_UsageCores |
数据传输
图表显示 ClickHouse Cloud 的数据流入和流出情况。更多信息,请参阅网络数据传输。
高级仪表板
此仪表板是内置高级可观测性仪表板的修改版,其中每条序列表示各副本的指标。该仪表板可用于监控和故障排查 ClickHouse 相关问题。
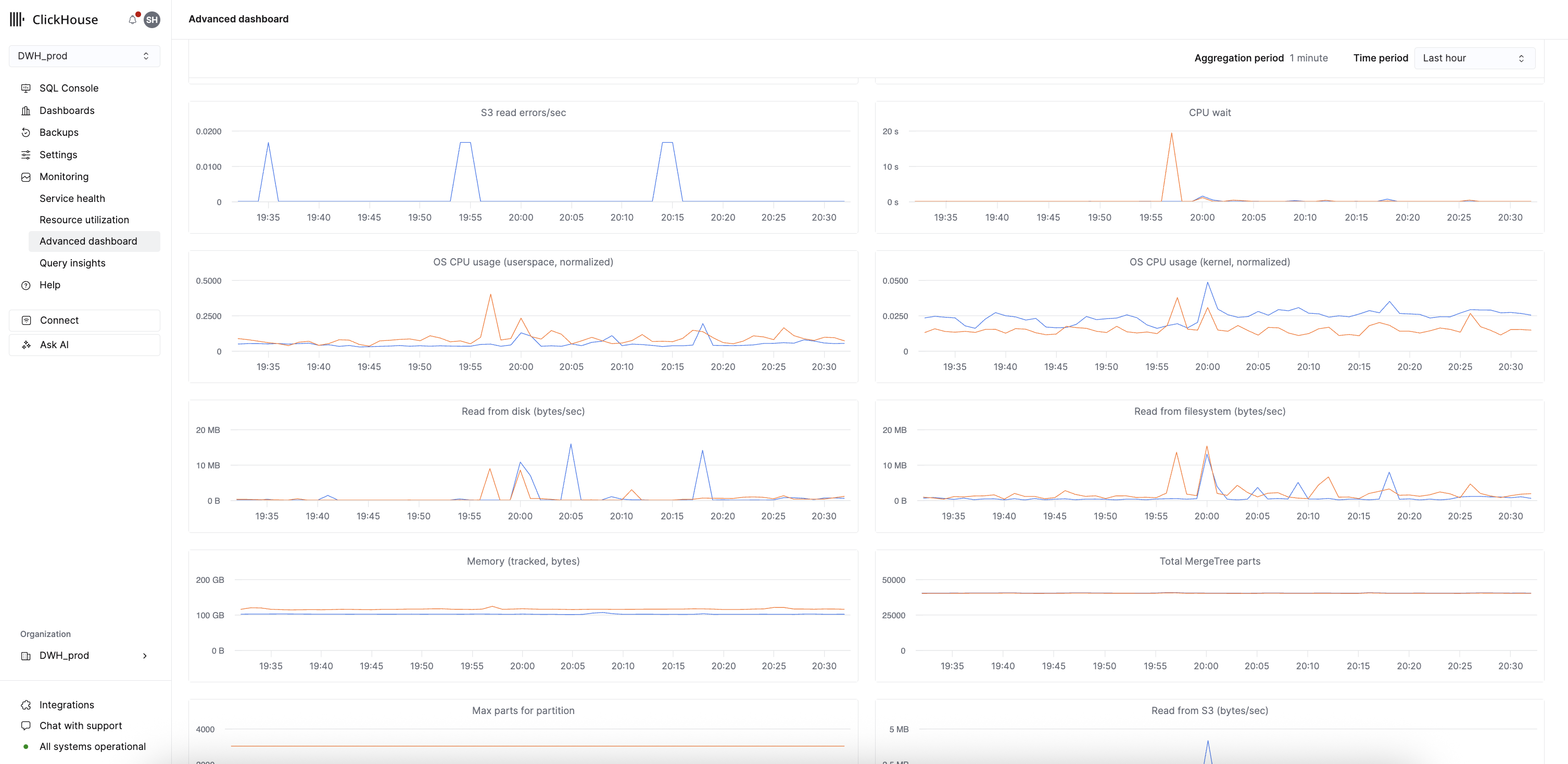
ClickHouse Cloud 会从系统表中抓取并存储此仪表板显示的指标,因此即使服务已空闲,也仍可查看这些指标。访问这些指标不会向底层服务发出查询,也不会唤醒空闲服务。
下表将高级仪表板中的每个图表映射到其对应的 ClickHouse 指标名称、系统表来源和聚合类型:
| 图表 | 对应的 ClickHouse 指标名称 | 系统表 | 聚合类型 |
|---|---|---|---|
| 查询数/秒 | ProfileEvent_Query | metric_log | Sum / bucketSizeSeconds |
| 运行中的查询 | CurrentMetric_Query | metric_log | Avg |
| 运行中的合并 | CurrentMetric_Merge | metric_log | Avg |
| 选中字节数/秒 | ProfileEvent_SelectedBytes | metric_log | Sum / bucketSizeSeconds |
| IO 等待 | ProfileEvent_OSIOWaitMicroseconds | metric_log | Sum / bucketSizeSeconds |
| S3 读取等待 | ProfileEvent_ReadBufferFromS3Microseconds | metric_log | Sum / bucketSizeSeconds |
| S3 读取错误数/秒 | ProfileEvent_ReadBufferFromS3RequestsErrors | metric_log | Sum / bucketSizeSeconds |
| CPU 等待 | ProfileEvent_OSCPUWaitMicroseconds | metric_log | Sum / bucketSizeSeconds |
| OS CPU 使用率 (用户态,归一化) | OSUserTimeNormalized | asynchronous_metric_log | |
| OS CPU 使用率 (内核态,归一化) | OSSystemTimeNormalized | asynchronous_metric_log | |
| 从磁盘读取 | ProfileEvent_OSReadBytes | metric_log | Sum / bucketSizeSeconds |
| 从文件系统读取 | ProfileEvent_OSReadChars | metric_log | Sum / bucketSizeSeconds |
| 内存 (跟踪值,字节) | CurrentMetric_MemoryTracking | metric_log | |
| MergeTree parts 总数 | TotalPartsOfMergeTreeTables | asynchronous_metric_log | |
| 单个分区的最大 parts 数 | MaxPartCountForPartition | asynchronous_metric_log | |
| 从 S3 读取 | ProfileEvent_ReadBufferFromS3Bytes | metric_log | Sum / bucketSizeSeconds |
| 文件系统缓存大小 | CurrentMetric_FilesystemCacheSize | metric_log | |
| 磁盘 S3 写请求数/秒 | ProfileEvent_DiskS3PutObject + ProfileEvent_DiskS3UploadPart + ProfileEvent_DiskS3CreateMultipartUpload + ProfileEvent_DiskS3CompleteMultipartUpload | metric_log | Sum / bucketSizeSeconds |
| 磁盘 S3 读请求数/秒 | ProfileEvent_DiskS3GetObject + ProfileEvent_DiskS3HeadObject + ProfileEvent_DiskS3ListObjects | metric_log | Sum / bucketSizeSeconds |
| FS 缓存命中率 | sum(ProfileEvent_CachedReadBufferReadFromCacheBytes) / (sum(ProfileEvent_CachedReadBufferReadFromCacheBytes) + sum(ProfileEvent_CachedReadBufferReadFromSourceBytes)) | metric_log | |
| 页缓存命中率 | greatest(0, (sum(ProfileEvent_OSReadChars) - sum(ProfileEvent_OSReadBytes)) / (sum(ProfileEvent_OSReadChars) + sum(ProfileEvent_ReadBufferFromS3Bytes))) | metric_log | |
| 网络接收字节数/秒 | NetworkReceiveBytes | asynchronous_metric_log | Sum / bucketSizeSeconds |
| 网络发送字节数/秒 | NetworkSendBytes | asynchronous_metric_log | Sum / bucketSizeSeconds |
| 并发 TCP 连接数 | CurrentMetric_TCPConnection | metric_log | |
| 并发 MySQL 连接数 | CurrentMetric_MySQLConnection | metric_log | |
| 并发 HTTP 连接数 | CurrentMetric_HTTPConnection | metric_log |
有关每个可视化及如何使用它们进行故障排查的详细信息,请参阅高级仪表板文档。
查询洞察
查询洞察 功能通过各种可视化和表格,让 ClickHouse 内置的查询日志更易于使用。ClickHouse 的 system.query_log 表是查询优化、调试以及监控整个集群健康状态和性能的关键信息来源。
选择一个服务后,左侧边栏中的 监控 导航项会展开,并显示 查询洞察 子项:
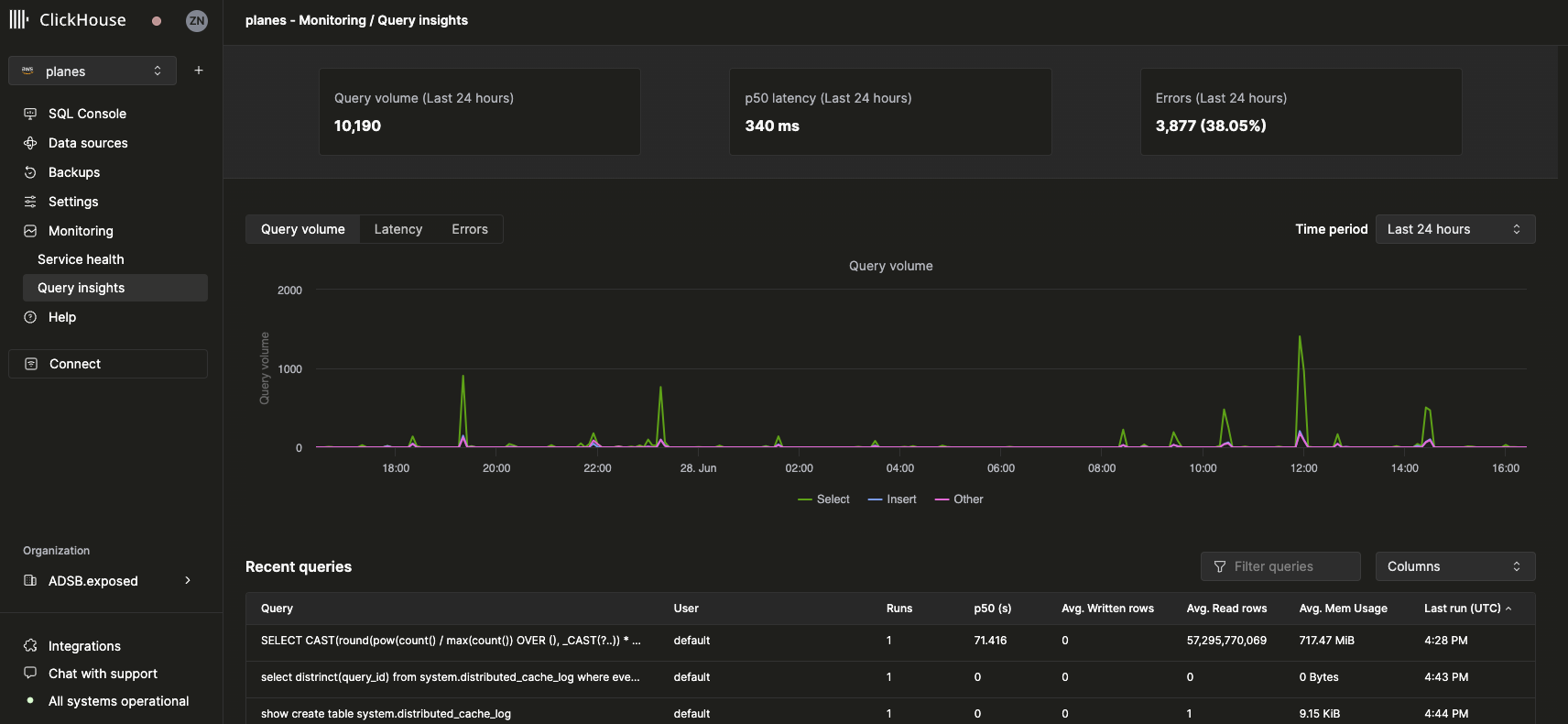
顶层指标
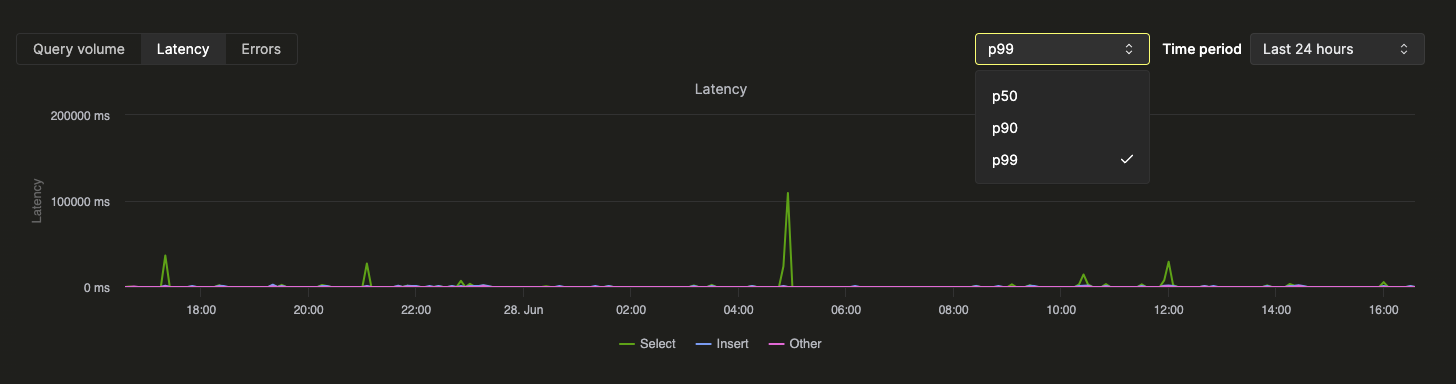
顶部的统计框显示所选时间段内的基础查询指标。其下方的时间序列图表按查询类型 (select、insert、other) 细分展示查询量、延迟和错误率。延迟 chart 可调整为显示 p50、p90 和 p99 延迟:
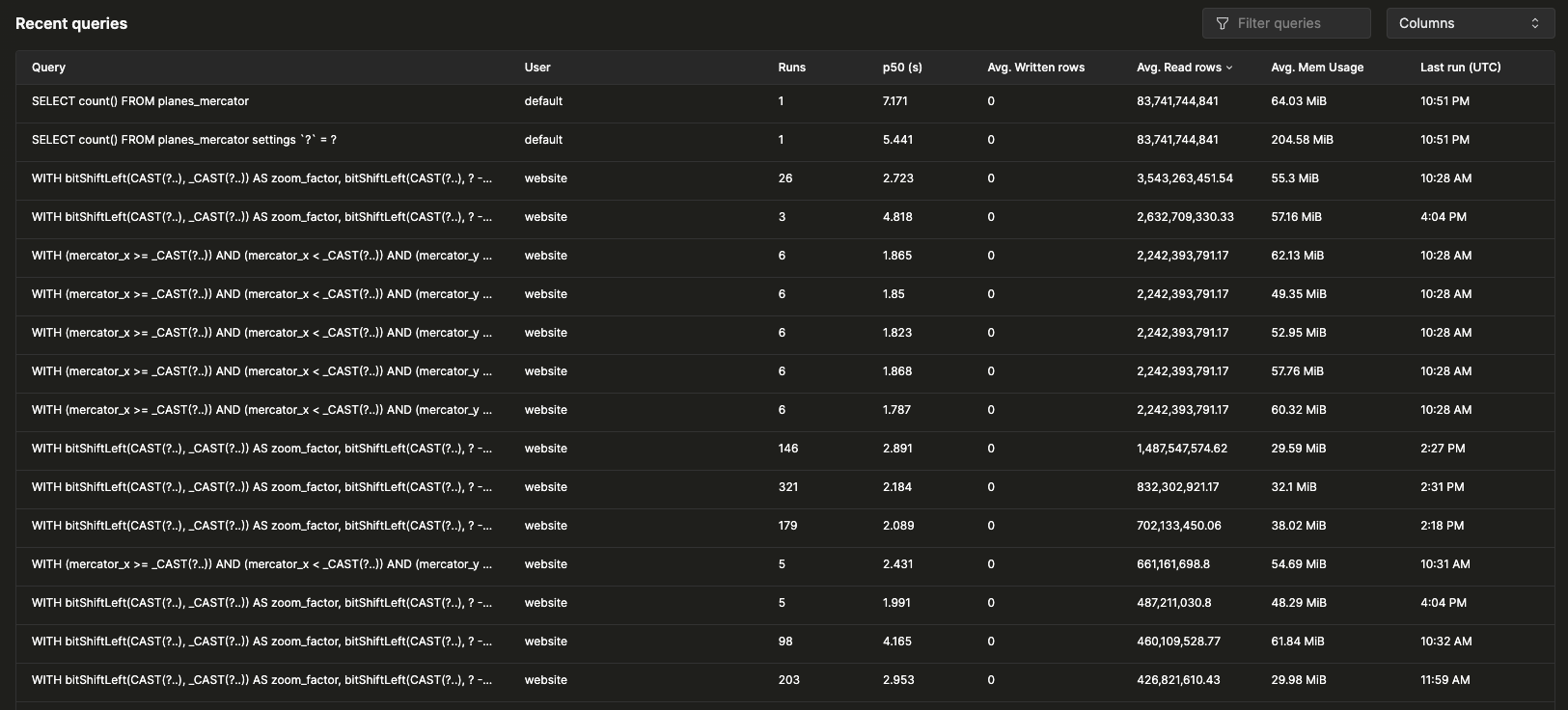
最近查询
表格会显示所选时间窗口内按归一化查询哈希和用户分组的查询日志条目。可按任意可用字段对最近查询进行筛选和排序,也可将表格配置为显示或隐藏其他字段,例如表、p90 和 p99 延迟:
查询下钻
在最近查询表中选择某个查询后,会打开一个 flyout,其中包含该查询特有的指标和信息:
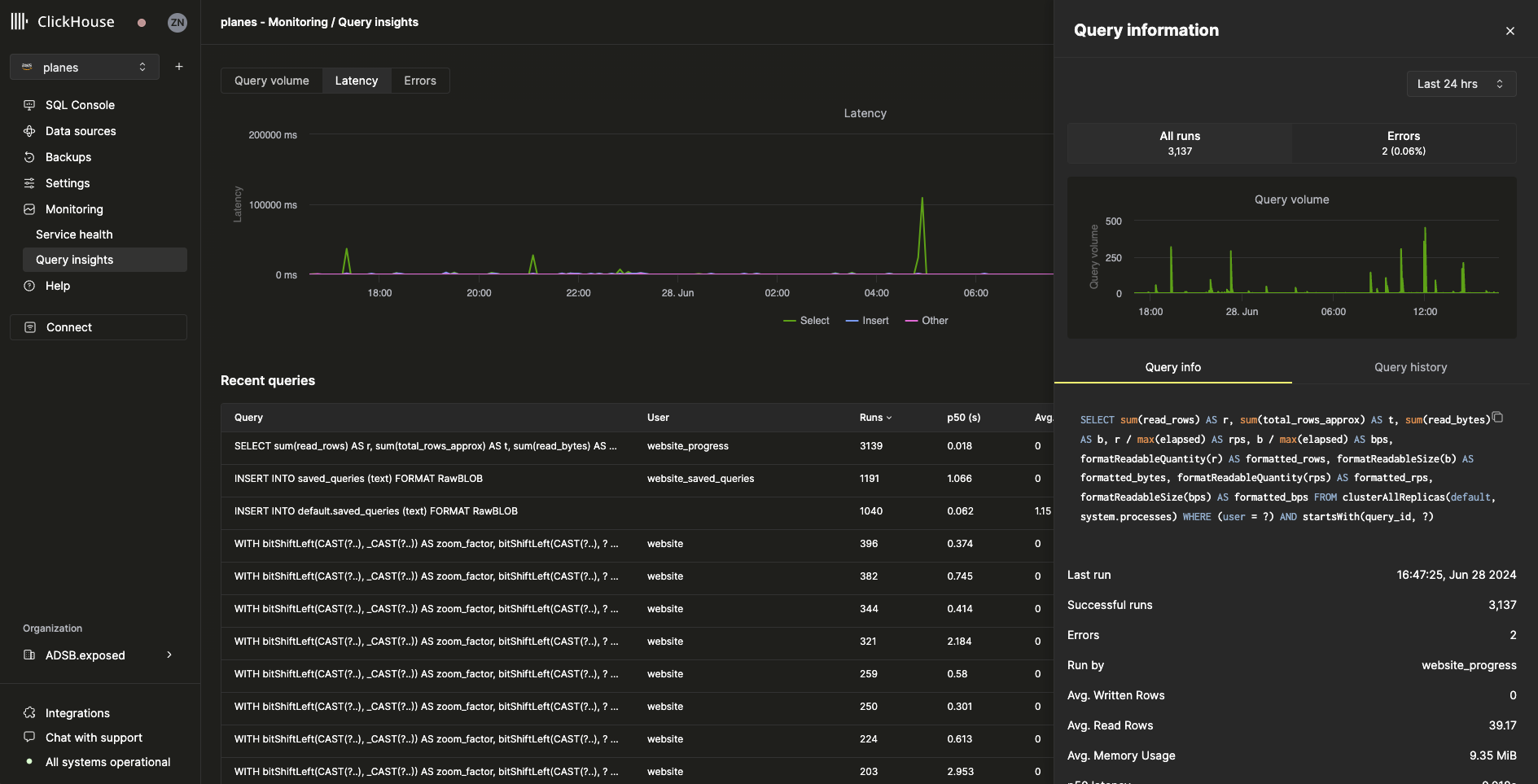
Query info 选项卡中的所有指标都是聚合指标,但我们也可以通过选择 Query history 选项卡来查看各次单独执行的指标:
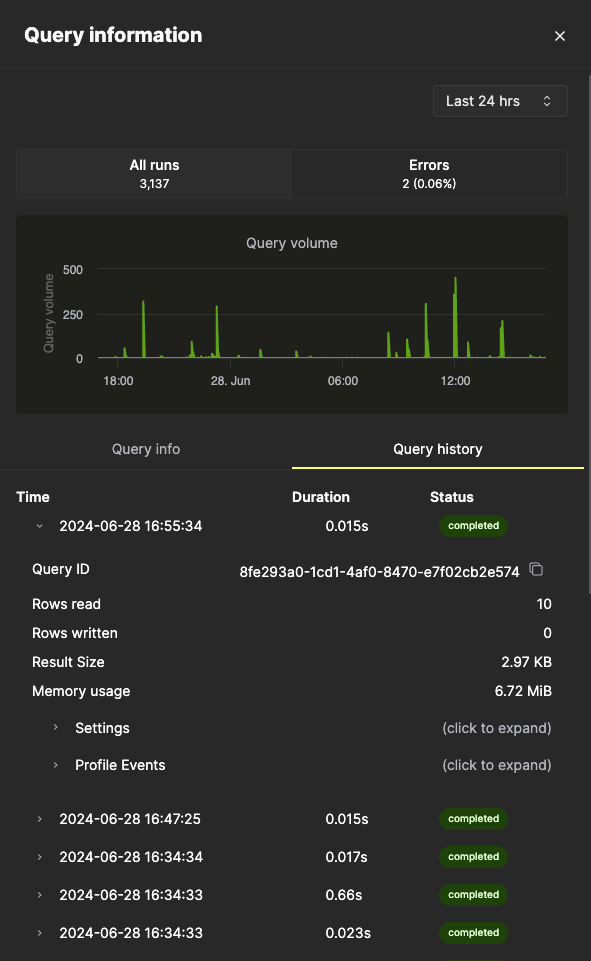
在此面板中,每次查询执行对应的 Settings 和 Profile Events 项都可以展开,以显示更多信息。
相关页面
- Notifications — 为扩缩容事件、错误和计费配置告警
- Advanced dashboard — 各项仪表板可视化的详细参考
- Querying system tables — 对系统表运行自定义 SQL 查询,以进行深入分析
- Prometheus endpoint — 将指标导出到 Grafana、Datadog 或其他兼容 Prometheus 的工具
