使用 PeerDB 迁移到 Managed Postgres
本指南提供了有关如何使用 PeerDB 将您的 PostgreSQL 数据库迁移到 ClickHouse Managed Postgres 的分步说明。
Beta前置条件
- 访问源 PostgreSQL 数据库的权限。
- 一个 ClickHouse Managed Postgres 实例,作为要迁移数据的目标。
- 在一台机器上已安装 PeerDB。你可以按照 PeerDB GitHub 仓库中的安装说明进行操作。你只需克隆该仓库并运行
docker-compose up。在本指南中,我们将使用 PeerDB UI,当 PeerDB 运行后,可通过http://localhost:3000访问。
迁移前的注意事项
在开始迁移之前,请注意以下事项:
- 数据库对象:PeerDB 会根据源数据库的 schema 在目标数据库中自动创建表。不过,某些数据库对象(如索引、约束和触发器)不会自动迁移。你需要在迁移完成后,在目标数据库中手动重新创建这些对象。
- DDL 变更:如果你启用了持续复制,PeerDB 会将源数据库中的 DML 操作(INSERT、UPDATE、DELETE)同步到目标数据库,并会同步 ADD COLUMN 操作。不过,其他 DDL 变更(例如 DROP COLUMN、ALTER COLUMN)不会被自动同步。有关对 schema 变更支持的更多信息,请参见此处。
- 网络连通性:确保源数据库和目标数据库都可以从运行 PeerDB 的机器访问。你可能需要配置防火墙规则或安全组设置以允许连接。
创建 peers
首先,我们需要为源数据库和目标数据库各创建一个 peer。一个 peer 表示与某个数据库的连接。在 PeerDB UI 中,点击侧边栏中的“Peers”进入对应页面。要创建新的 peer,点击 + New peer 按钮。
创建源端 peer
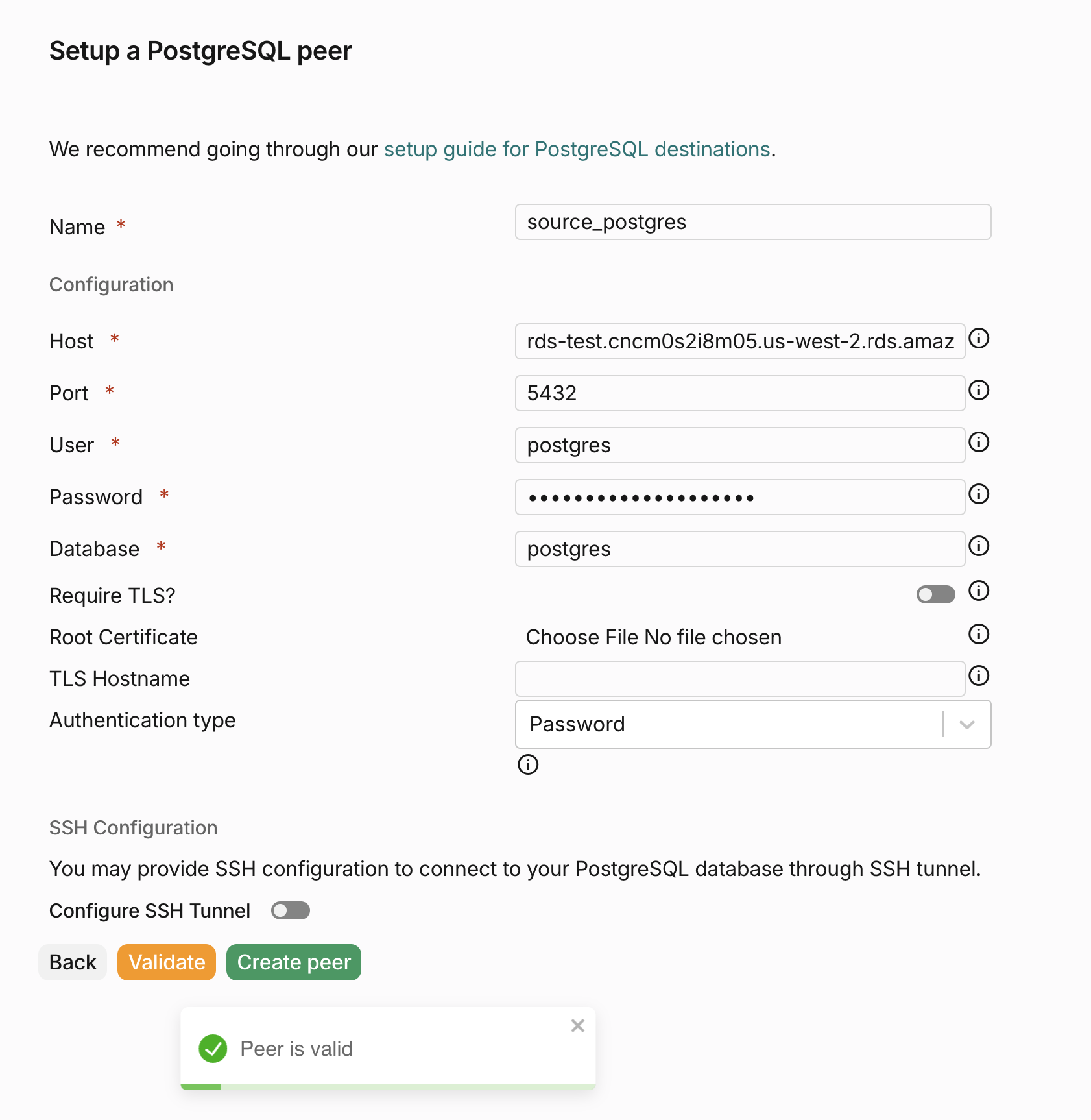
通过填写连接信息(例如主机、端口、数据库名、用户名和密码),为你的源 PostgreSQL 数据库创建一个 peer。填写完所有信息后,点击 Create peer 按钮以保存该 peer。
创建目标 peer
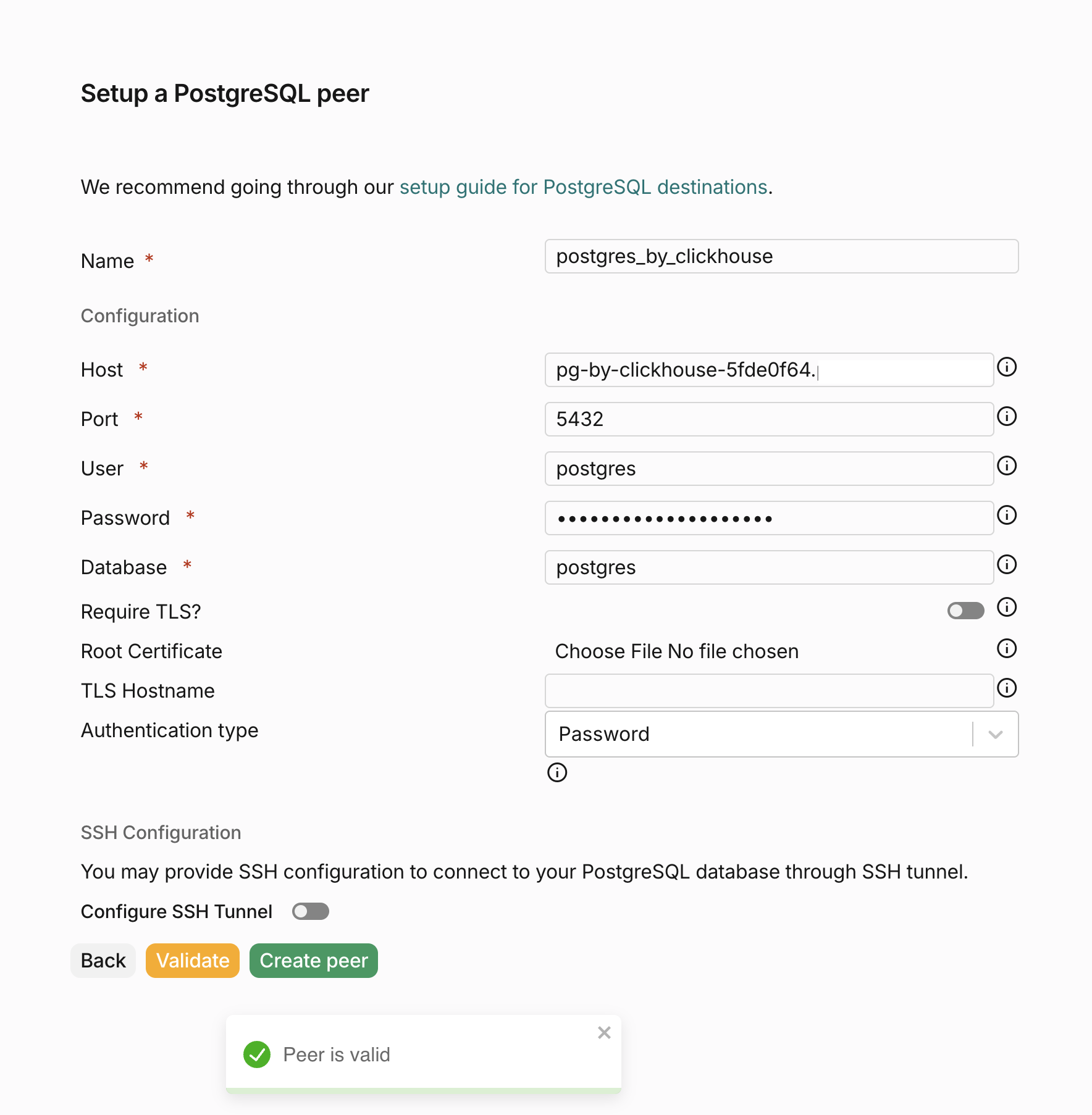
同样,通过提供必要的连接信息,为你的 ClickHouse Managed Postgres 实例创建一个 peer。你可以在 ClickHouse Cloud 控制台中获取该实例的连接信息。在填写完所有信息后,点击 Create peer 按钮以保存目标 peer。
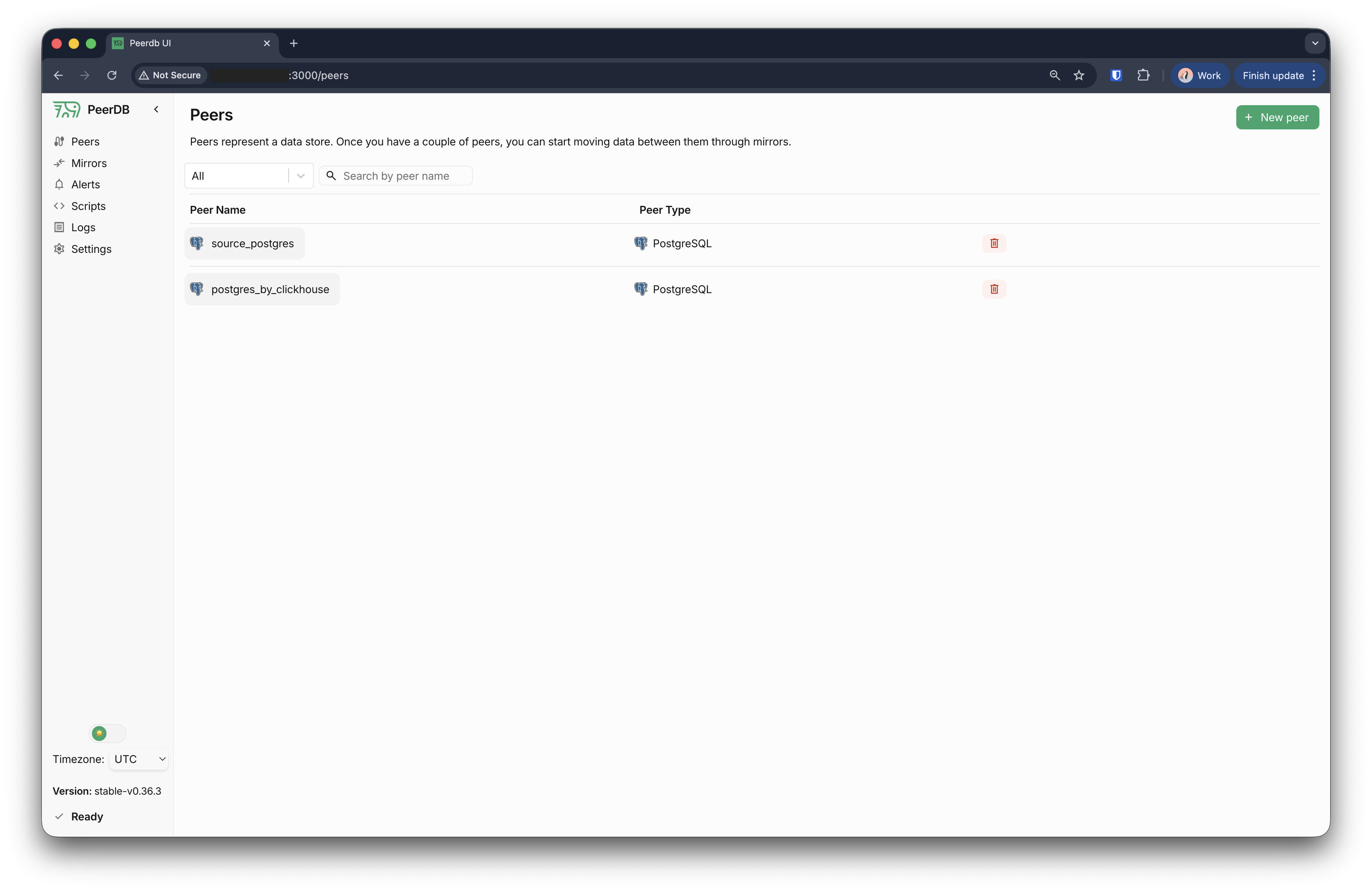
现在,你应该能在 “Peers” 部分看到源 peer 和目标 peer 都已列出。
获取源数据库的模式转储
为了在目标数据库中复刻源数据库的结构,我们需要获取源数据库的模式转储。可以使用 pg_dump 为源 PostgreSQL 数据库创建仅包含模式的转储:
安装 pg_dump
Ubuntu:
更新软件包列表:
安装 PostgreSQL 客户端:
macOS:
方法一:使用 Homebrew(推荐)
如果尚未安装 Homebrew,请先安装:
安装 PostgreSQL:
验证安装:
从模式转储中移除唯一约束和索引
在将其应用到目标数据库之前,我们需要从 dump 文件中移除 UNIQUE 约束和索引,以避免这些约束阻止 PeerDB 向目标表摄取数据。可以使用以下方式将它们移除:
将 schema dump 应用于目标数据库
在清理完 schema dump 文件后,可以通过 psql 连接 到目标 ClickHouse Managed Postgres 数据库,并执行该 schema dump 文件,将其应用到目标数据库中:
在目标端,我们希望 PeerDB 的数据摄取不会因为外键约束而被阻塞。为此,可以修改(在上文 target peer 中使用的)目标角色,将其 session_replication_role 设置为 replica:
创建 mirror
接下来,我们需要创建一个 mirror,用于定义源和目标 peer 之间的数据迁移流程。在 PeerDB UI 中,点击侧边栏中的 "Mirrors",进入 "Mirrors" 部分。要创建一个新的 mirror,点击 + New mirror 按钮。
- 为你的 mirror 指定一个能够描述此次迁移的名称。
- 从下拉菜单中选择之前创建的源和目标 peer。
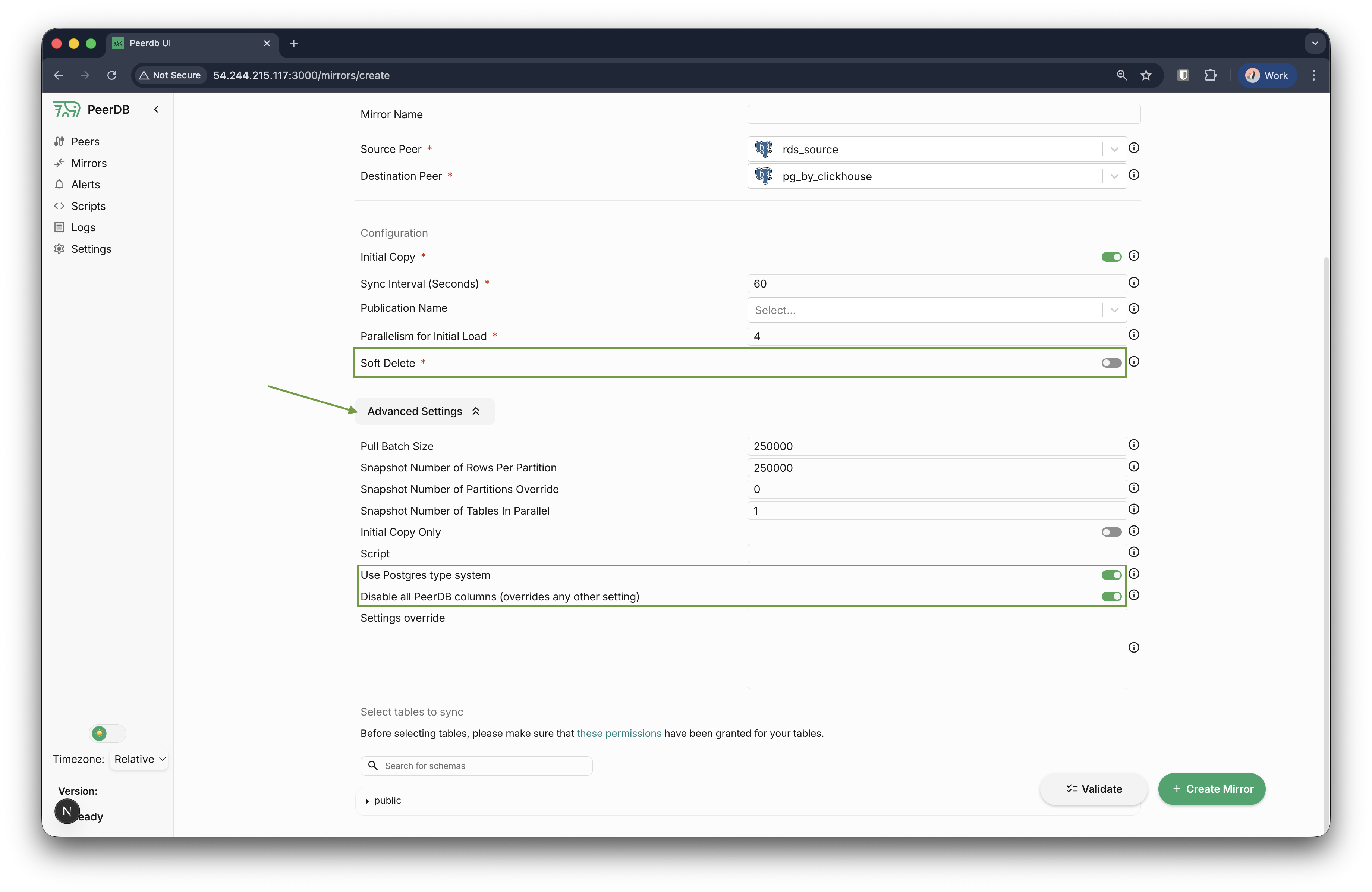
- 请确保:
- Soft delete 为关闭状态(OFF)。
- 展开
Advanced settings。确保 Postgres type system is enabled 已启用,并且 PeerDB columns are disabled 处于禁用状态。
- 选择你要迁移的表。你可以选择特定的表,也可以从源数据库中选择所有表。
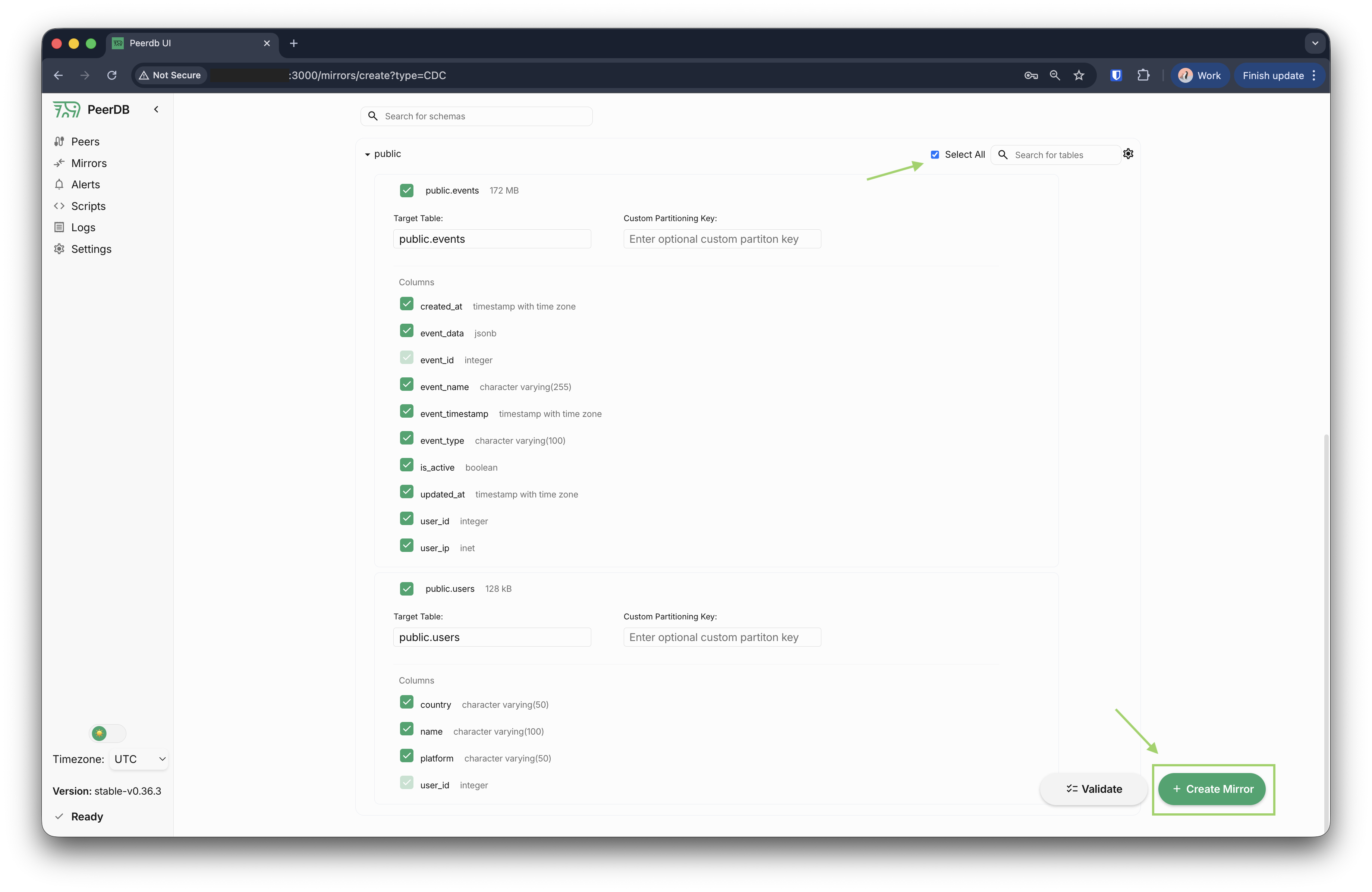
请确保目标数据库中的目标表名与源表名保持一致,因为在前面的步骤中我们是直接迁移了 schema 本身。
- 配置完成 mirror 的相关设置后,点击
Create mirror按钮。
此时你应该可以在 "Mirrors" 部分看到新创建的 mirror。
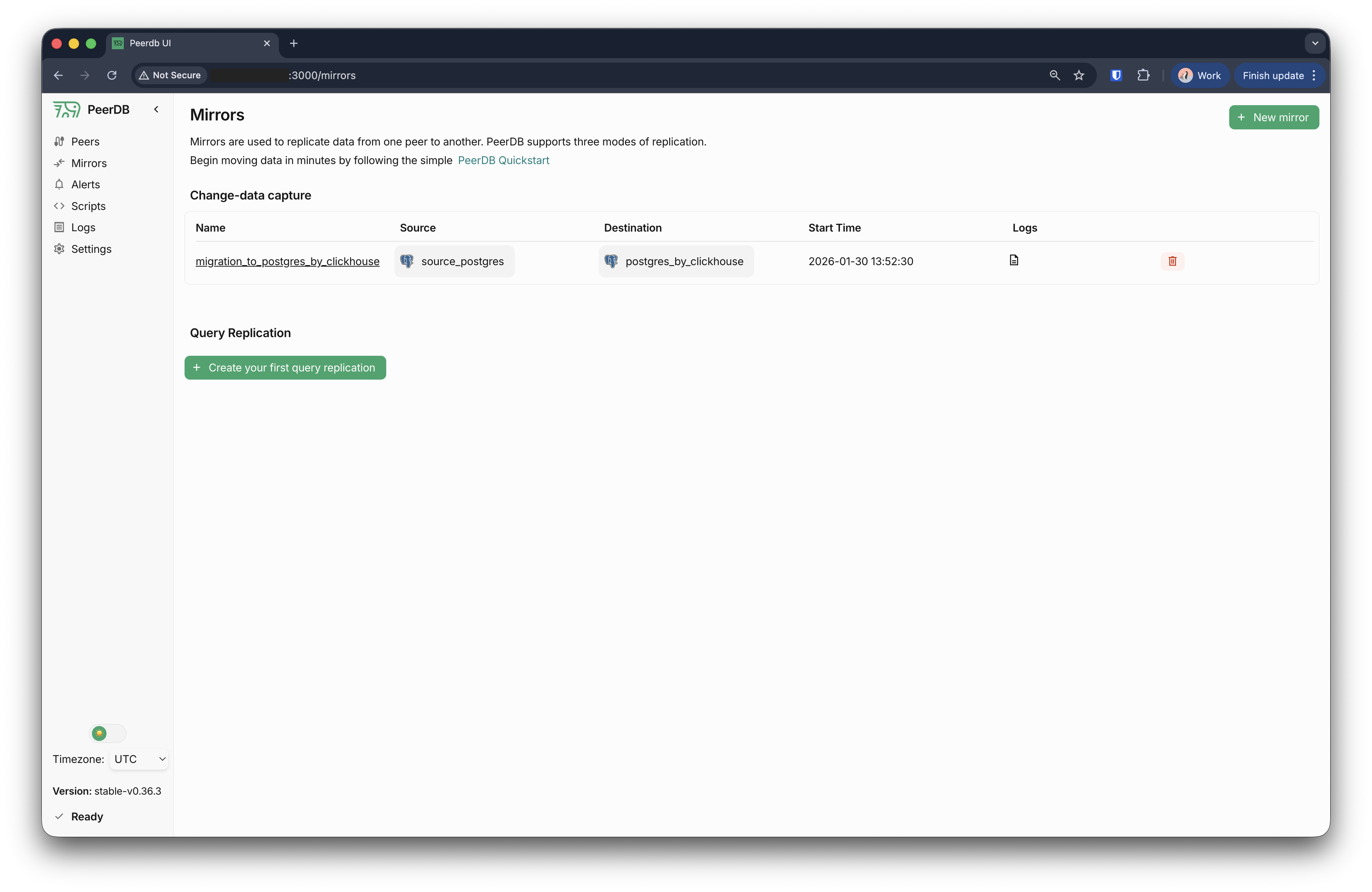
等待初始加载
创建 mirror 后,PeerDB 会开始执行从源数据库到目标数据库的初始数据加载。你可以单击该 mirror,然后单击 Initial load 选项卡来监控初始数据迁移的进度。
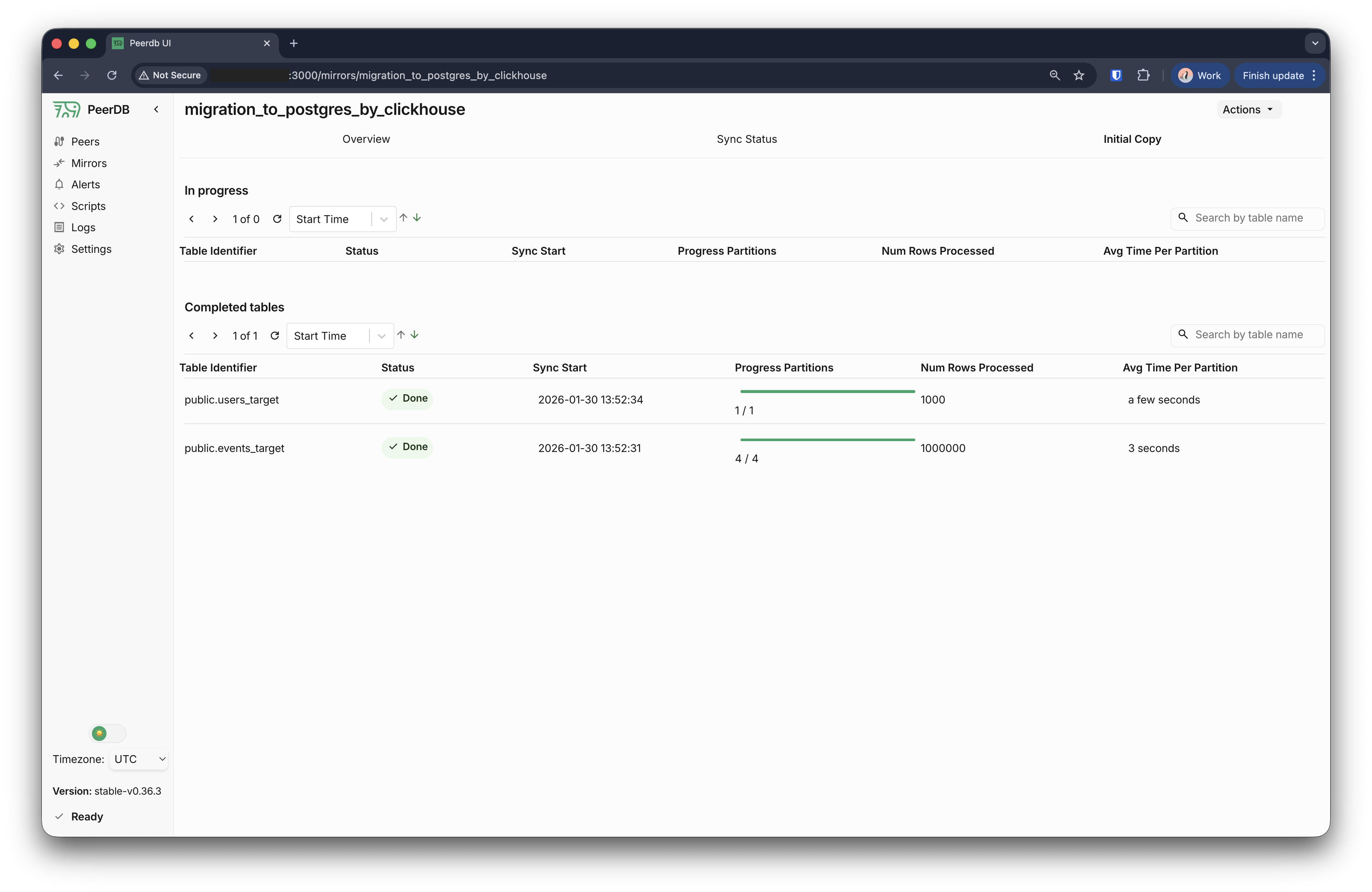
初始加载完成后,你应当会看到状态显示迁移已完成。
监控初始加载和复制
点击源 peer 后,你可以看到 PeerDB 正在运行的命令列表。例如:
- 首先我们会运行一个 COUNT 查询,用于估算每个表中的行数。
- 然后我们使用 NTILE 运行一个分区查询,将大型表拆分为更小的块,以实现高效的数据传输。
- 接着我们执行 FETCH 命令,从源数据库拉取数据,然后由 PeerDB 将其同步到目标数据库。
迁移后的任务
这些步骤可能会因您的具体使用场景和应用需求而异。关键是要确保数据一致性、尽量减少停机时间,并在完全切换到新系统之前验证迁移后数据的完整性。
迁移完成后:
- 执行切换前验证检查
在切换流量之前,比较源端和目标端的关键表:
- 停止源系统的写入
先暂停应用写入。作为额外的保护措施,在切换期间将源数据库设为只读:
如果需要回滚,您可以重新开启写入:
- 确认复制已完全追平
检查一个或多个写入量较高的表中最新的行在源端和目标端是否一致:
- 重新创建并启用约束、索引和触发器
如果你为了摄取而移除了约束/索引,或将其延后处理,请现在重新应用。此外,如果你之前将目标端的复制角色设置为 replica,也请立即将其重置:
- 重置目标表的序列
数据导入后,使序列与当前表中的值保持一致:
- 切换应用流量
验证通过且序列和约束已就位后:
- 将读流量切换到 ClickHouse Managed Postgres。
- 将写流量切换到 ClickHouse Managed Postgres。
- 监控应用错误、约束违反情况以及数据库健康状况。
- 清理资源
当你确认迁移无误,并且已将应用切换为使用 ClickHouse Managed Postgres 后,即可删除 PeerDB 中的镜像和对等端。
如果你启用了持续复制,PeerDB 会在源 PostgreSQL 数据库上创建一个复制槽。迁移完成后,请务必从源数据库中手动删除该复制槽,以避免不必要的资源占用。
参考资料
后续步骤
恭喜!您已使用 pg_dump 和 pg_restore 成功将 PostgreSQL 数据库迁移至 ClickHouse Managed Postgres。现在,您已经可以开始探索 Managed Postgres 的各项功能及其与 ClickHouse 的集成。以下是 10 分钟快速入门,帮助您快速上手:
