数据仓储
现代数据仓库不再将存储与计算紧密耦合。相反,存储、治理和查询处理这些彼此独立但相互连接的层,让你能够灵活地为工作流选择合适的工具。
通过将开放表格式和 ClickHouse 这样的高性能查询引擎添加到云对象存储中,你可以在不牺牲数据湖开放性的前提下,获得数据库级能力——ACID 事务、schema 约束以及快速分析查询。这种组合将高性能与可互操作、成本效益高的存储结合起来,可支持传统分析和现代 AI/ML 工作负载。
这种架构带来的优势
通过将开放对象存储和表格式与 ClickHouse 查询引擎结合使用,您将获得:
| 优势 | 描述 |
|---|---|
| 一致的表更新 | 对表状态的原子提交意味着并发写入不会产生损坏或不完整的数据。这解决了原始数据湖中最棘手的问题之一。 |
| schema 管理 | 强制验证和可跟踪的 schema 演进可防止出现“数据沼泽”问题,即数据因 schema 不一致而变得无法使用。 |
| 查询性能 | 索引、统计信息以及数据跳过、聚类等数据布局优化,使 SQL 查询能够达到接近专用数据仓库的速度。结合 ClickHouse 的列式引擎,即使数据存储在对象存储中,这一点也同样成立。 |
| 治理 | 目录和表格式可在行级和列级提供细粒度的访问控制与审计,从而弥补基础数据湖安全控制有限的问题。 |
| 存储与计算分离 | 存储和计算可在通用对象存储上独立扩展,其成本显著低于专有数据仓库存储。虽然这种分离在现代云数据仓库中已是标准做法,但开放格式让您可以选择究竟由哪种计算引擎随数据一同扩展。 |
ClickHouse 如何驱动您的数据仓库
数据从流式平台和现有数据仓库经由对象存储进入 ClickHouse,在其中完成转换和优化,然后提供给您的 BI/AI 工具。
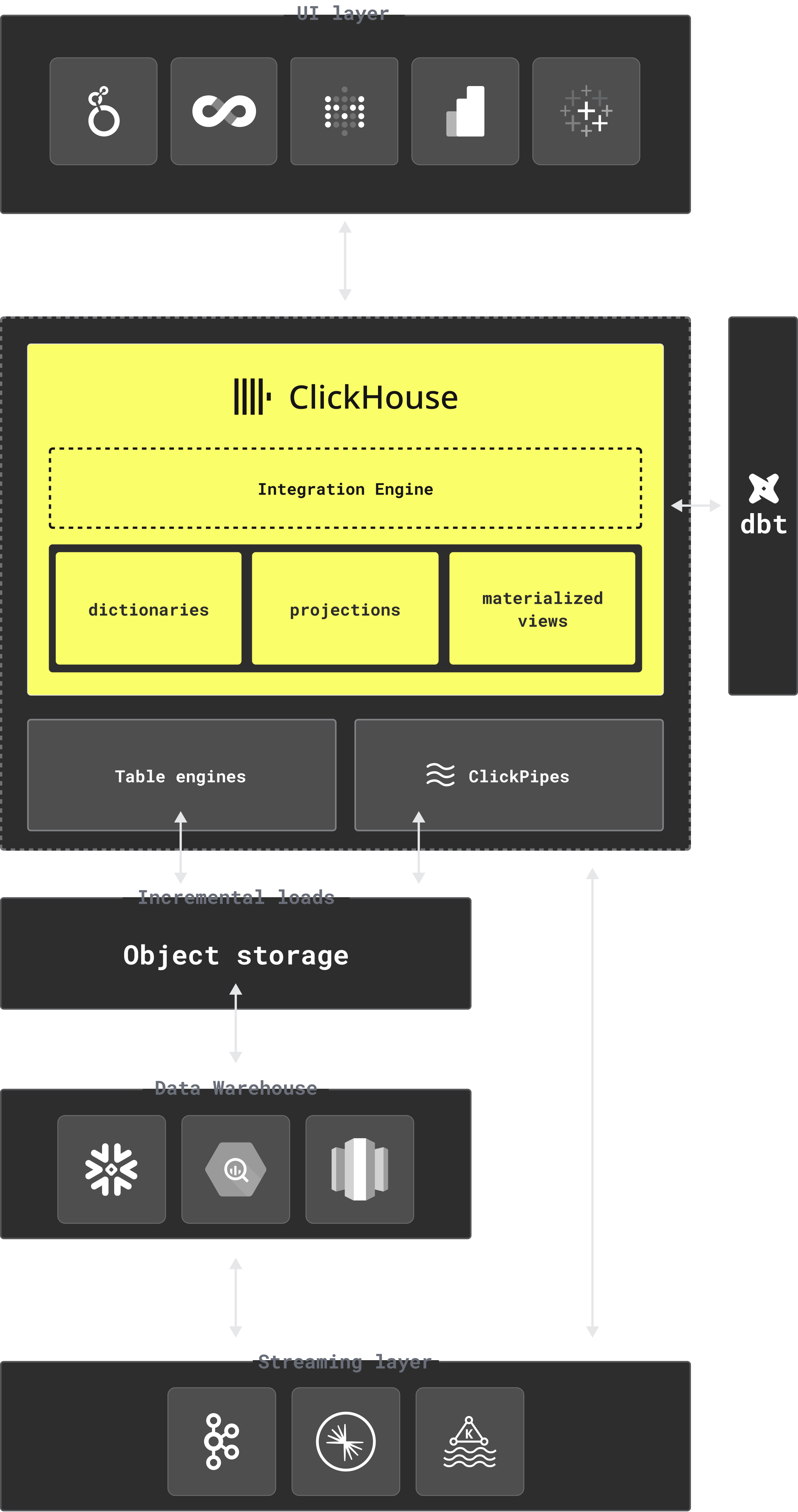
ClickHouse 覆盖了数据仓库工作流中的四个关键环节:数据导入、查询、转换,以及连接到团队已经在使用的工具。
数据摄取
对于批量数据导入,通常会使用 S3 或 GCS 之类的对象存储作为中间层。ClickHouse 出色的 Parquet 读取性能,使您能够借助 S3 table engine 以每秒数亿行的速度导入数据。对于实时流数据,ClickPipes 可直接连接到 Kafka 和 Confluent 等平台。
您还可以从 Snowflake、BigQuery 和 Databricks 等现有数据仓库迁移,方法是先导出到对象存储,再通过 table engines 导入 ClickHouse。
查询
您可以直接查询 S3 和 GCS 等对象存储中的数据,也可以查询采用 Iceberg、Delta Lake 和 Hudi 等开放表格式的数据湖中的数据。您既可以直接连接这些格式,也可以通过 AWS Glue Catalog、Unity Catalog 和 Iceberg REST 等数据目录进行连接。
对 materialized views 的查询速度很快,因为其汇总结果会自动存储在专用表中,因此无论分析的数据量有多大,下游查询都能保持良好的响应性。其他数据库提供商通常会将这类加速功能放在更高等级的定价方案中,或额外收费;而 ClickHouse Cloud 开箱即用地提供 查询缓存、稀疏索引 和 投影,适用于重复执行且对延迟敏感的查询。
ClickHouse 支持 70 多种文件格式和 SQL 函数,可大规模处理日期、数组、JSON、地理空间数据和近似聚合。
数据转换
数据转换是商业智能和分析工作流中的常见支柱。ClickHouse 中的 materialized views 可将其自动化——当新数据插入源表时,这些基于 SQL 的视图就会被触发,因此您可以在数据到达时提取、聚合和修改数据,而无需构建和管理定制的转换管道。
对于更复杂的建模工作流,ClickHouse 的 dbt integration 允许您将转换定义为版本控制的 SQL 模型,并将现有 dbt jobs 迁移为直接在 ClickHouse 上运行。
集成
ClickHouse 为 Tableau 和 Looker 等 BI 工具提供原生连接器。没有原生连接器的工具可以通过 MySQL wire 协议 连接,无需额外配置。对于语义层工作流,ClickHouse 可与 Cube 集成,让您的团队只需定义一次指标,即可从任何下游工具中查询这些指标。金融服务、游戏、电商等多个行业的公司都依赖这些集成,在数据到达后立即释放其价值,为实时仪表板和商业智能工作流提供支持。
ClickHouse 还支持 REST 接口,因此您可以在不依赖复杂二进制协议的情况下构建轻量级应用。MCP server 可将 ClickHouse 连接到 LLM,并通过 LibreChat 或 Claude 等工具实现对话式分析。灵活的 RBAC 和配额控制让您可以公开只读表,以供客户端获取数据。
混合架构:两全其美
除了查询您的数据湖之外,您还可以将对性能要求严苛的数据摄取到 ClickHouse 原生的 MergeTree 存储中,以支持需要超低延迟的用例——例如实时仪表板、运营分析或交互式应用。
这为您提供了一种分等级数据策略。热点且经常访问的数据存放在 ClickHouse 优化的存储中,以实现亚秒级查询响应;而完整的数据历史则保留在数据湖中,并且仍可查询。您还可以使用 ClickHouse materialized view,持续将数据湖中的数据转换并聚合到优化表中,从而自动衔接这两个等级。
您可以根据性能要求而非技术限制来决定数据的存放位置。
参加免费的 Data Warehousing with ClickHouse 课程,了解更多信息。
