在已经遵循前文最佳实践的前提下 (例如已优化数据类型、选定了合理的主键并充分利用了物化视图) ,才应考虑使用数据跳过索引。如果你是首次接触跳过索引,本指南 是一个很好的起点。
在充分理解其工作原理并谨慎使用的情况下,这类索引可以显著加速查询。
ClickHouse 提供了一种强大的机制,称为 数据跳过索引 (data skipping indices) ,它可以在查询执行过程中大幅减少扫描的数据量——尤其是在主键对特定过滤条件帮助不大的场景中。与依赖基于行的二级索引 (如 B-tree) 的传统数据库不同,ClickHouse 是列式存储,不会以支持此类结构的方式存储行位置。相应地,它使用跳过索引来避免读取那些可以确定不满足查询过滤条件的数据块。
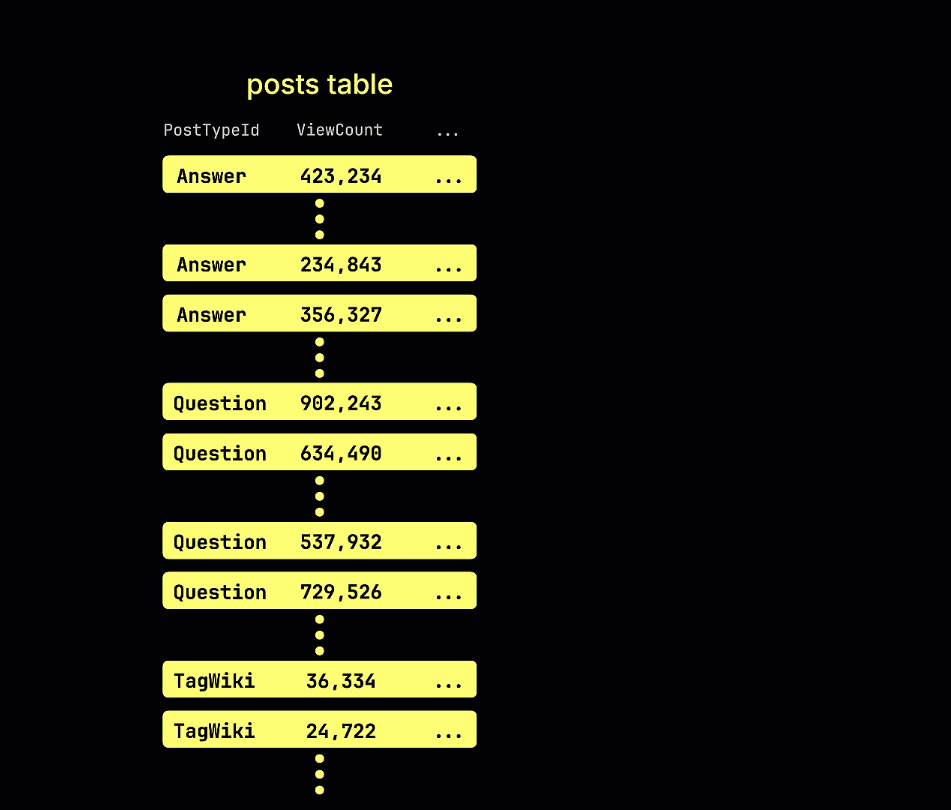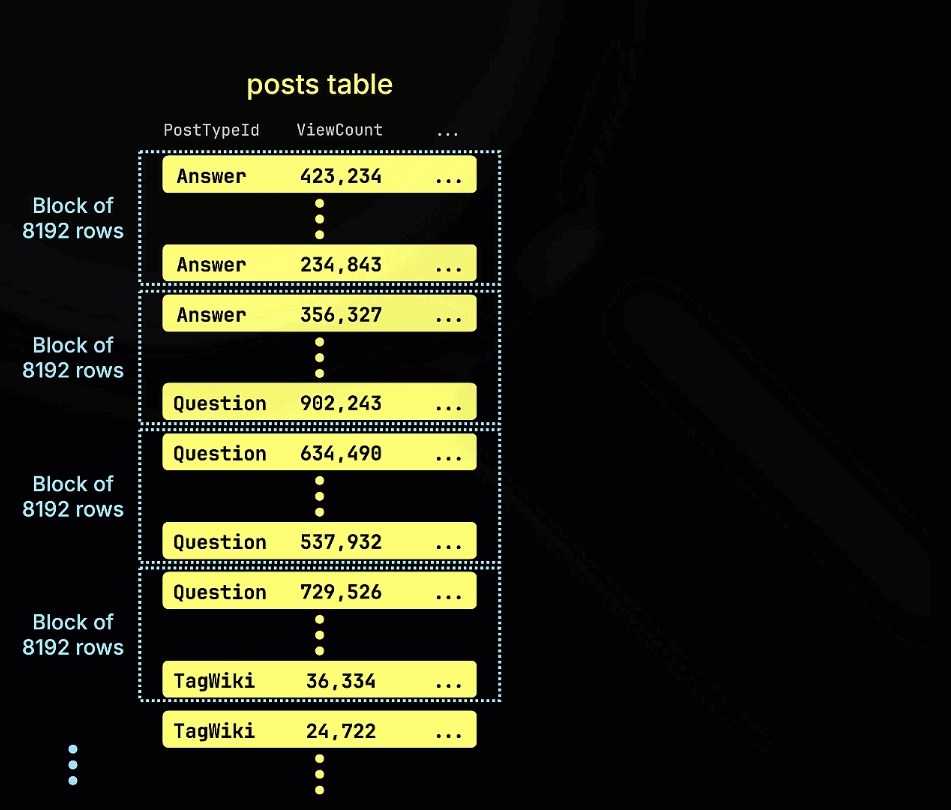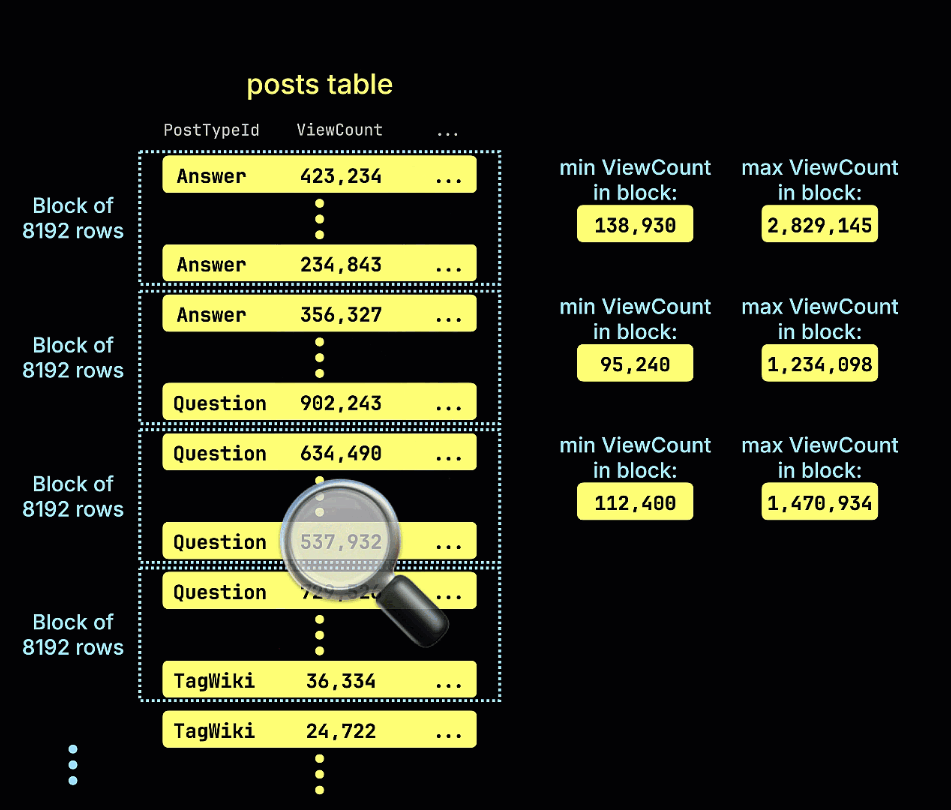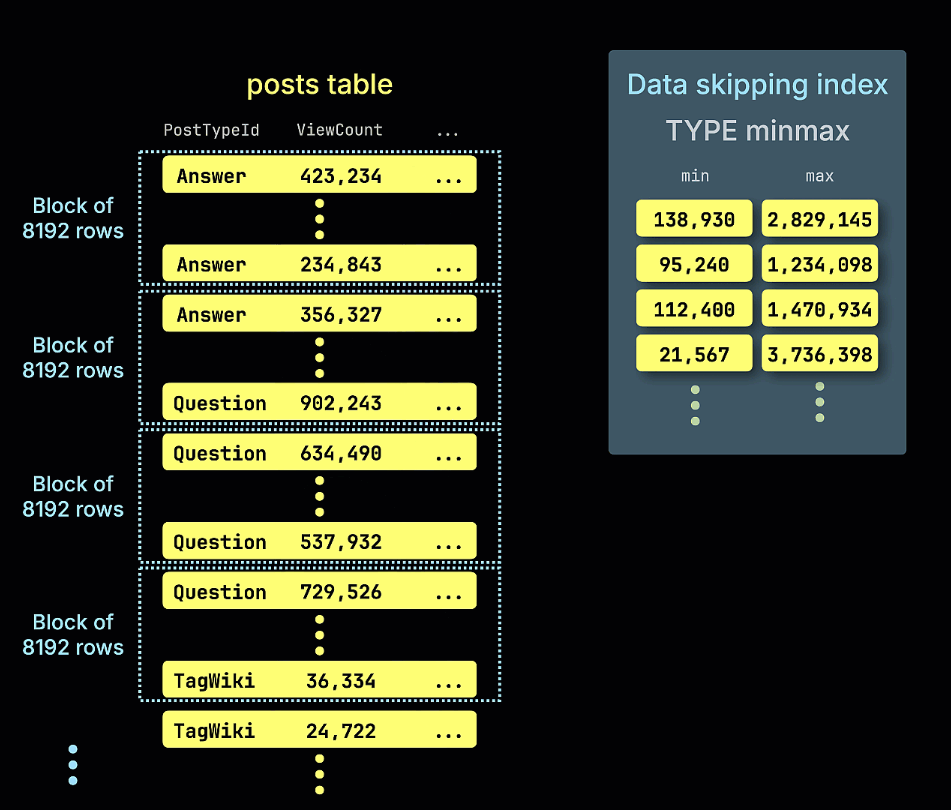
跳过索引通过存储数据块的元数据——例如最小/最大值、值集合或 Bloom filter 表示——并在查询执行期间利用这些元数据来判断哪些数据块可以完全跳过。它们仅适用于 MergeTree family 表引擎,并通过一个表达式、索引类型、名称以及定义每个被索引数据块大小的 granularity 来进行定义。这些索引与表数据一同存储,并在查询过滤条件与索引表达式匹配时被使用。
数据跳过索引有多种类型,每种适用于不同类型的查询和数据分布:
- minmax:为每个数据块跟踪某个表达式的最小值和最大值。非常适合在松散排序数据上的范围查询。
- set(N):为每个数据块跟踪至多大小为 N 的值集合。对每块基数较低的列效果显著。
- text:在分词后的字符串数据之上构建倒排索引,从而实现高效且确定性的全文搜索。推荐用于自然语言或大规模自由文本列,在这些场景下,相比基于 Bloom filter 的近似方法,更需要精确的 token 查找和可扩展的多词项搜索能力。
- bloom_filter:以概率方式判断某个值是否存在于块中,从而为集合成员关系提供快速的近似过滤。特别适合优化“在大海捞针”式的查询,即需要找到极少数正匹配结果的场景。
- tokenbf_v1 / ngrambf_v1: (已弃用) 专门为在字符串中搜索 token 或字符序列而设计的 Bloom filter 变体——对日志数据或文本搜索场景尤其有用。在 ClickHouse 版本 >= 26.2 中已弃用,推荐改用文本索引。
尽管功能强大,跳过索引必须谨慎使用。只有在能够过滤掉足够多的数据块时,它们才会带来收益;如果查询模式或数据结构与之不匹配,反而会引入额外开销。一旦某个块中存在哪怕一个匹配值,该整个块仍然必须被读取。
要高效地使用跳过索引,通常需要被索引列与表主键之间具有较强的相关性,或者以能将相似值聚集在一起的方式插入数据。
一般而言,应在确保合理的主键设计和类型优化之后,再考虑应用数据跳过索引。它们特别适用于以下场景:
- 整体基数很高,但在单个块内基数较低的列。
- 对搜索至关重要的稀有值 (例如错误代码、特定 ID) 。
- 在具有局部化分布的非主键列上进行过滤的场景。
务必:
- 在真实数据和接近真实的查询上测试跳过索引,尝试不同的索引类型和 granularity 取值。
- 使用诸如 send_logs_level='trace' 和
EXPLAIN indexes=1 等工具评估其效果,以查看索引的实际有效性。
- 始终评估索引大小以及 granularity 对其的影响。减小 granularity 通常会在一定范围内提升性能,因为这会产生更多可被过滤掉的 granule,从而减少需要扫描的块。但随着 granularity 降低导致索引大小增加,性能也可能随之下降。应针对不同 granularity 取值测量性能和索引大小。这对 Bloom filter 索引尤为重要。
在合理使用的情况下,跳过索引可以带来可观的性能提升——而在盲目使用时,则可能增加不必要的成本。
关于数据跳过索引的更详细指南请参见此处。
考虑下面这个经过优化的表。该表包含 Stack Overflow 数据,每行对应一篇帖子。
CREATE TABLE stackoverflow.posts
(
`Id` Int32 CODEC(Delta(4), ZSTD(1)),
`PostTypeId` Enum8('Question' = 1, 'Answer' = 2, 'Wiki' = 3, 'TagWikiExcerpt' = 4, 'TagWiki' = 5, 'ModeratorNomination' = 6, 'WikiPlaceholder' = 7, 'PrivilegeWiki' = 8),
`AcceptedAnswerId` UInt32,
`CreationDate` DateTime64(3, 'UTC'),
`Score` Int32,
`ViewCount` UInt32 CODEC(Delta(4), ZSTD(1)),
`Body` String,
`OwnerUserId` Int32,
`OwnerDisplayName` String,
`LastEditorUserId` Int32,
`LastEditorDisplayName` String,
`LastEditDate` DateTime64(3, 'UTC') CODEC(Delta(8), ZSTD(1)),
`LastActivityDate` DateTime64(3, 'UTC'),
`Title` String,
`Tags` String,
`AnswerCount` UInt16 CODEC(Delta(2), ZSTD(1)),
`CommentCount` UInt8,
`FavoriteCount` UInt8,
`ContentLicense` LowCardinality(String),
`ParentId` String,
`CommunityOwnedDate` DateTime64(3, 'UTC'),
`ClosedDate` DateTime64(3, 'UTC')
)
ENGINE = MergeTree
PARTITION BY toYear(CreationDate)
ORDER BY (PostTypeId, toDate(CreationDate))
此表针对按帖子类型和日期进行过滤和聚合的查询进行了优化。假设我们希望统计 2009 年之后发布、且浏览量超过 10,000,000 次的帖子数量。
SELECT count()
FROM stackoverflow.posts
WHERE (CreationDate > '2009-01-01') AND (ViewCount > 10000000)
┌─count()─┐
│ 5 │
└─────────┘
1 row in set. Elapsed: 0.720 sec. Processed 59.55 million rows, 230.23 MB (82.66 million rows/s., 319.56 MB/s.)
此查询可以利用主索引排除部分行(和粒度)。然而,如上方响应以及下面的 EXPLAIN indexes = 1 所示,仍然需要读取大部分行:
EXPLAIN indexes = 1
SELECT count()
FROM stackoverflow.posts
WHERE (CreationDate > '2009-01-01') AND (ViewCount > 10000000)
LIMIT 1
┌─explain──────────────────────────────────────────────────────────┐
│ Expression ((Project names + Projection)) │
│ Limit (preliminary LIMIT (without OFFSET)) │
│ Aggregating │
│ Expression (Before GROUP BY) │
│ Expression │
│ ReadFromMergeTree (stackoverflow.posts) │
│ Indexes: │
│ MinMax │
│ Keys: │
│ CreationDate │
│ Condition: (CreationDate in ('1230768000', +Inf)) │
│ Parts: 123/128 │
│ Granules: 8513/8545 │
│ Partition │
│ Keys: │
│ toYear(CreationDate) │
│ Condition: (toYear(CreationDate) in [2009, +Inf)) │
│ Parts: 123/123 │
│ Granules: 8513/8513 │
│ PrimaryKey │
│ Keys: │
│ toDate(CreationDate) │
│ Condition: (toDate(CreationDate) in [14245, +Inf)) │
│ Parts: 123/123 │
│ Granules: 8513/8513 │
└──────────────────────────────────────────────────────────────────┘
25 rows in set. Elapsed: 0.070 sec.
一个简单的分析表明,ViewCount 与 CreationDate(主键)存在相关性,正如人们所预期的那样——帖子存在的时间越长,被查看的次数就越多。
SELECT toDate(CreationDate) AS day, avg(ViewCount) AS view_count FROM stackoverflow.posts WHERE day > '2009-01-01' GROUP BY day
因此,这使其成为数据跳过索引的合理选择。鉴于其数值类型,使用 minmax 索引是合适的。我们使用以下 ALTER TABLE 命令添加索引——先添加它,然后对其进行物化。
ALTER TABLE stackoverflow.posts
(ADD INDEX view_count_idx ViewCount TYPE minmax GRANULARITY 1);
ALTER TABLE stackoverflow.posts MATERIALIZE INDEX view_count_idx;
在初始创建表时也可以同时添加该索引。将 minmax 索引作为 DDL 一部分定义的表结构如下:
CREATE TABLE stackoverflow.posts
(
`Id` Int32 CODEC(Delta(4), ZSTD(1)),
`PostTypeId` Enum8('Question' = 1, 'Answer' = 2, 'Wiki' = 3, 'TagWikiExcerpt' = 4, 'TagWiki' = 5, 'ModeratorNomination' = 6, 'WikiPlaceholder' = 7, 'PrivilegeWiki' = 8),
`AcceptedAnswerId` UInt32,
`CreationDate` DateTime64(3, 'UTC'),
`Score` Int32,
`ViewCount` UInt32 CODEC(Delta(4), ZSTD(1)),
`Body` String,
`OwnerUserId` Int32,
`OwnerDisplayName` String,
`LastEditorUserId` Int32,
`LastEditorDisplayName` String,
`LastEditDate` DateTime64(3, 'UTC') CODEC(Delta(8), ZSTD(1)),
`LastActivityDate` DateTime64(3, 'UTC'),
`Title` String,
`Tags` String,
`AnswerCount` UInt16 CODEC(Delta(2), ZSTD(1)),
`CommentCount` UInt8,
`FavoriteCount` UInt8,
`ContentLicense` LowCardinality(String),
`ParentId` String,
`CommunityOwnedDate` DateTime64(3, 'UTC'),
`ClosedDate` DateTime64(3, 'UTC'),
INDEX view_count_idx ViewCount TYPE minmax GRANULARITY 1 --index here
)
ENGINE = MergeTree
PARTITION BY toYear(CreationDate)
ORDER BY (PostTypeId, toDate(CreationDate))
下面的动画展示了在示例表中是如何构建 minmax 跳过索引的,它会跟踪表中每个行块(granule)的 ViewCount 最小值和最大值:
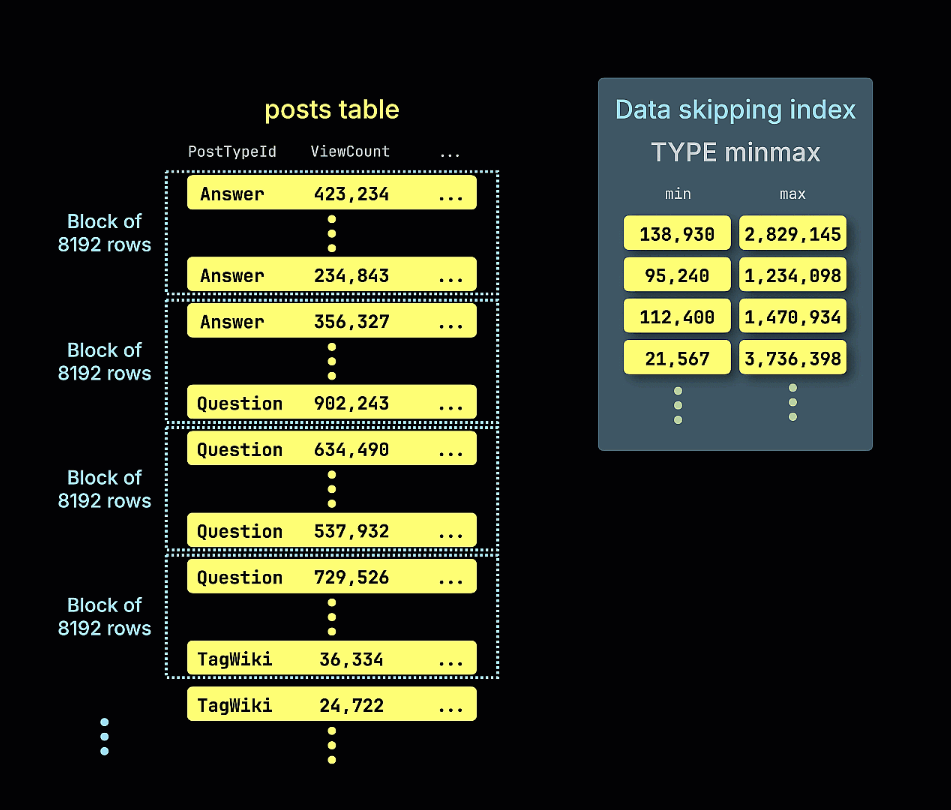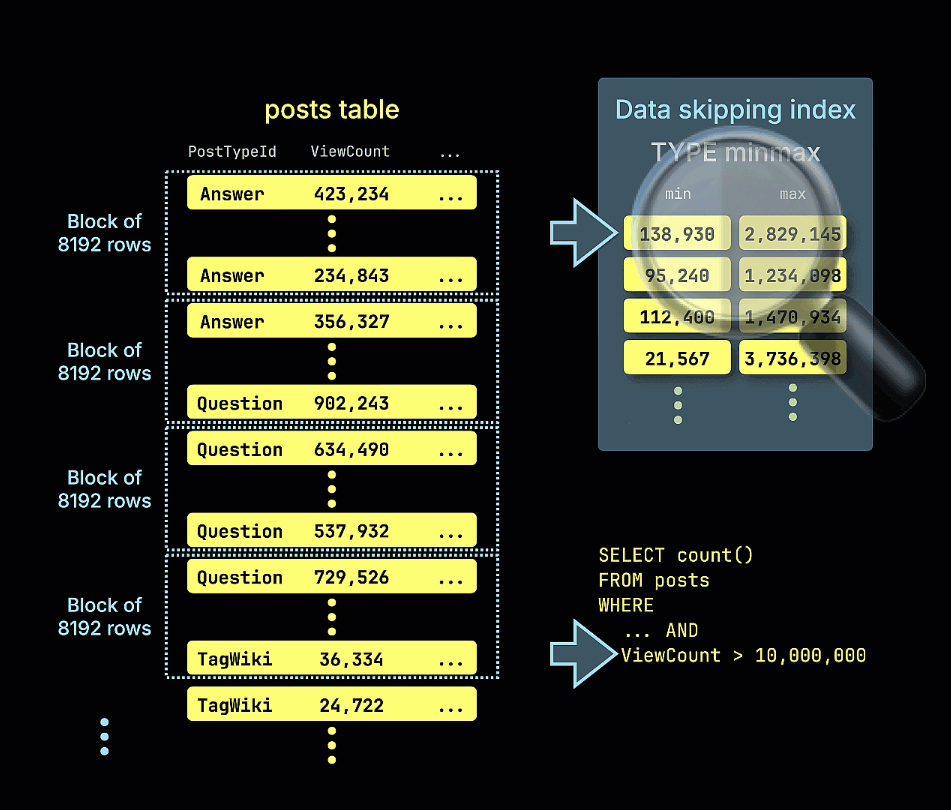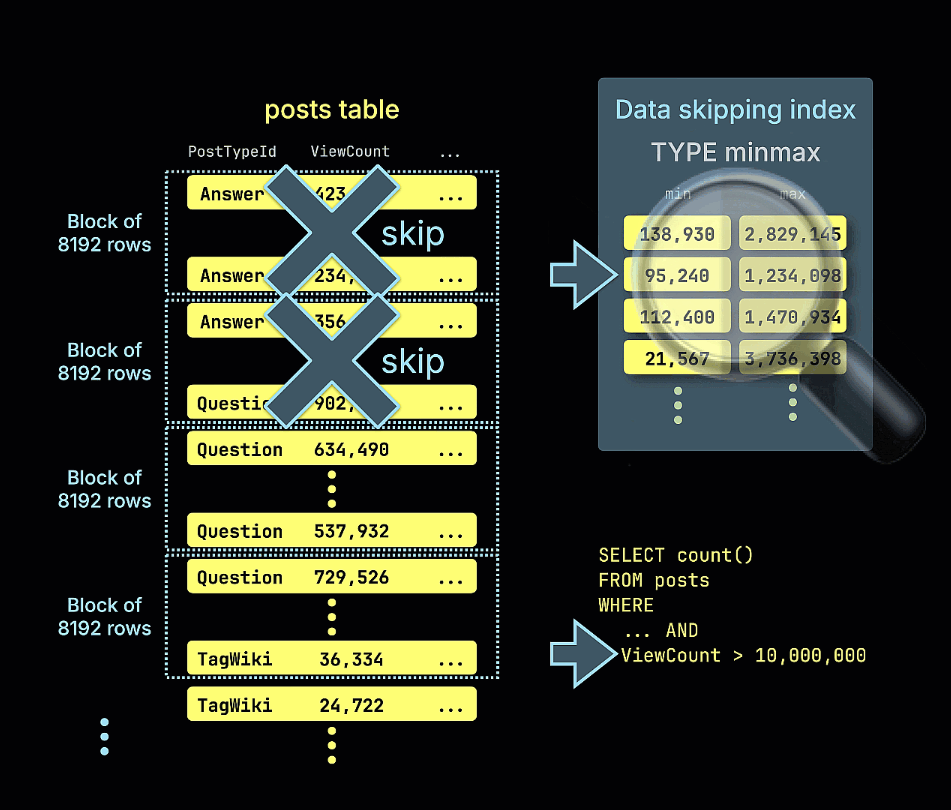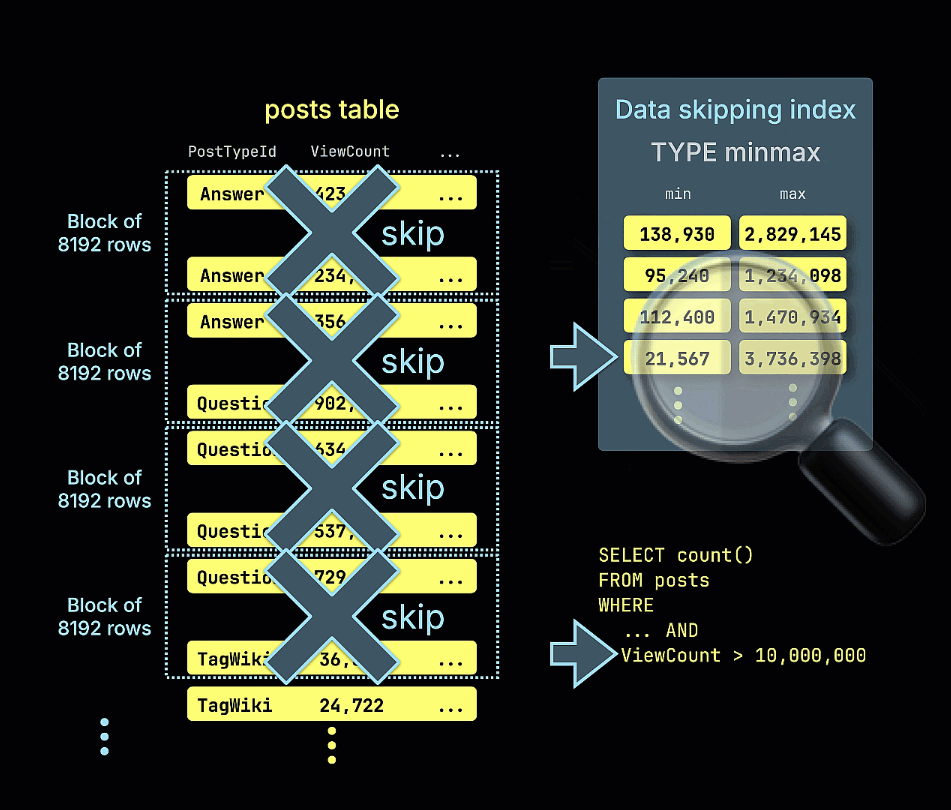
再次运行之前的查询可以看到明显的性能提升。请注意被扫描的行数已经减少:
SELECT count()
FROM stackoverflow.posts
WHERE (CreationDate > '2009-01-01') AND (ViewCount > 10000000)
┌─count()─┐
│ 5 │
└─────────┘
1 row in set. Elapsed: 0.012 sec. Processed 39.11 thousand rows, 321.39 KB (3.40 million rows/s., 27.93 MB/s.)
运行 EXPLAIN indexes = 1 可以确认索引已被使用。
EXPLAIN indexes = 1
SELECT count()
FROM stackoverflow.posts
WHERE (CreationDate > '2009-01-01') AND (ViewCount > 10000000)
┌─explain────────────────────────────────────────────────────────────┐
│ Expression ((Project names + Projection)) │
│ Aggregating │
│ Expression (Before GROUP BY) │
│ Expression │
│ ReadFromMergeTree (stackoverflow.posts) │
│ Indexes: │
│ MinMax │
│ Keys: │
│ CreationDate │
│ Condition: (CreationDate in ('1230768000', +Inf)) │
│ Parts: 123/128 │
│ Granules: 8513/8545 │
│ Partition │
│ Keys: │
│ toYear(CreationDate) │
│ Condition: (toYear(CreationDate) in [2009, +Inf)) │
│ Parts: 123/123 │
│ Granules: 8513/8513 │
│ PrimaryKey │
│ Keys: │
│ toDate(CreationDate) │
│ Condition: (toDate(CreationDate) in [14245, +Inf)) │
│ Parts: 123/123 │
│ Granules: 8513/8513 │
│ Skip │
│ Name: view_count_idx │
│ Description: minmax GRANULARITY 1 │
│ Parts: 5/123 │
│ Granules: 23/8513 │
└────────────────────────────────────────────────────────────────────┘
29 rows in set. Elapsed: 0.211 sec.
我们还通过动画演示了 minmax 跳数索引如何剪枝所有不可能包含示例查询中 ViewCount > 10,000,000 谓词匹配项的行块: