尽量减少并优化 JOIN 操作
ClickHouse 支持多种 JOIN 类型和算法,并且在近期版本中 JOIN 性能有了显著提升。然而,相比从单个已反规范化的表进行查询,JOIN 从本质上来说开销更大。反规范化会将计算工作从查询时转移到写入或预处理阶段,这通常会在运行时显著降低延迟。对于实时或对延迟敏感的分析查询,强烈建议采用反规范化。
通常在以下情况下进行反规范化:
- 表变更不频繁,或者可以接受批量刷新。
- 关系不是多对多,或者基数不过高。
- 只会查询部分列,即可以将某些列排除在反规范化之外。
- 如果你具备在上游系统 (如 Flink) 中处理数据的能力,可以在那里完成实时富化或扁平化。
并非所有数据都需要反规范化——重点放在那些被频繁查询的属性上。此外,可以考虑使用物化视图来增量计算聚合,而不是复制整个子表。当模式更新很少且对延迟要求极高时,反规范化通常能提供最佳的性能折中方案。
关于在 ClickHouse 中对数据进行反规范化的完整指南,请参见此处。
何时需要使用 JOIN
在需要使用 JOIN 时,请确保使用至少 24.12 版本,且最好是最新版本,因为每个新版本都会持续改进 JOIN 性能。从 ClickHouse 24.12 开始,查询规划器会自动将较小的表放在 JOIN 的右侧以获得最佳性能——这一任务此前需要手动完成。后续还会有更多增强功能推出,包括更激进的过滤下推以及对多表 JOIN 的自动重排序。
遵循以下最佳实践来提升 JOIN 性能:
- 避免笛卡尔积:如果左侧的某个值与右侧的多个值匹配,则 JOIN 将返回多行结果——这就是所谓的笛卡尔积。如果你的用例不需要右侧的所有匹配,而是只需要任意一个匹配,可以使用
ANYJOIN(例如LEFT ANY JOIN)。它们比常规 JOIN 更快且占用更少内存。 - 减小参与 JOIN 的表大小:JOIN 的运行时间和内存消耗会随着左右表的大小成比例增长。要减少 JOIN 处理的数据量,可以在查询的
WHERE或JOIN ON子句中添加额外的过滤条件。ClickHouse 会在查询计划中尽可能深地下推过滤条件,通常会在 JOIN 之前。如果过滤条件没有(因任何原因而)被自动下推,可以将 JOIN 一侧改写为子查询以强制下推。 - 在适用时使用通过字典的直接 JOIN:ClickHouse 中的标准 JOIN 分两阶段执行:构建阶段遍历右侧以构建哈希表,然后探测阶段遍历左侧,通过哈希表查找匹配的 JOIN 伙伴。如果右侧是一个 dictionary 或者是另一个具备键值对特性的表引擎(例如 EmbeddedRocksDB 或 Join table engine),那么 ClickHouse 就可以使用“直接” JOIN 算法,从而实际上不需要构建哈希表,加速查询处理。这适用于
INNER和LEFT OUTERJOIN,并且是实时分析型工作负载的优选方案。 - 在 JOIN 中利用表排序:ClickHouse 中的每个表都按照该表的主键列排序。可以通过使用所谓的排序合并 JOIN 算法(如
full_sorting_merge和partial_merge)来利用表的排序。与基于哈希表的标准 JOIN 算法(见下文parallel_hash、hash、grace_hash)不同,排序合并 JOIN 算法会先对两个表排序,然后再进行合并。如果查询是按两个表各自的主键列进行 JOIN,那么排序合并会启用一种优化,省略排序步骤,从而节省处理时间和开销。 - 避免发生落盘的 JOIN:JOIN 的中间状态(例如哈希表)可能会变得非常大,以至于不再能放入内存。在这种情况下,ClickHouse 默认会返回内存不足错误。某些 JOIN 算法(见下文),例如
grace_hash、partial_merge和full_sorting_merge,可以将中间状态落盘并继续执行查询。不过仍应谨慎使用这些 JOIN 算法,因为磁盘访问会显著降低 JOIN 处理速度。我们更推荐通过其他方式优化 JOIN 查询,以减少中间状态的大小。 - 在外连接中使用默认值作为未匹配标记:左/右/全外连接会包含来自左表/右表/两个表的所有值。如果在另一张表中找不到某个值的 JOIN 伙伴,ClickHouse 会用一个特殊的标记替代该 JOIN 伙伴。SQL 标准要求数据库使用 NULL 作为这种标记。在 ClickHouse 中,这需要将结果列包装为 Nullable,从而带来额外的内存和性能开销。作为替代方案,可以将设置
join_use_nulls = 0,并使用结果列数据类型的默认值作为该标记。
在 ClickHouse 中将字典用于 JOIN 时,需要理解:字典在设计上不允许存在重复键。在数据加载过程中,任何重复键都会被静默去重——对于给定键,仅保留最后加载的那个值。此行为使得字典非常适合一对一或多对一的关系场景,此类场景只需要最新或权威值即可。然而,如果将字典用于一对多或多对多关系 (例如在关联演员与角色时,一个演员可以拥有多个角色) ,则会导致静默的数据丢失,因为除了一行匹配记录之外,其余匹配行都会被丢弃。因此,在需要保留所有匹配结果、完全还原关系结构的场景中,字典并不适用。有关字典适用与不适用场景的更多信息,请参阅字典最佳实践。
选择合适的 JOIN 算法
ClickHouse 支持多种在速度与内存之间进行权衡的 JOIN 算法:
- Parallel Hash JOIN(默认): 对可以放入内存的小到中等大小的右表速度快。
- Direct JOIN: 当使用字典(或其他具有键值特征的表引擎)并配合
INNER或LEFT ANY JOIN时非常理想——这是点查询最快的方法,因为它消除了构建哈希表的需求。 - Full Sorting Merge JOIN: 当两个表都在 JOIN 键上排序时效率较高。
- Partial Merge JOIN: 将内存占用降到最低但速度较慢——最适合在内存有限的情况下对大表进行 JOIN。
- Grace Hash JOIN: 灵活且可调节内存使用,适用于需要调优性能特征的大规模数据集。
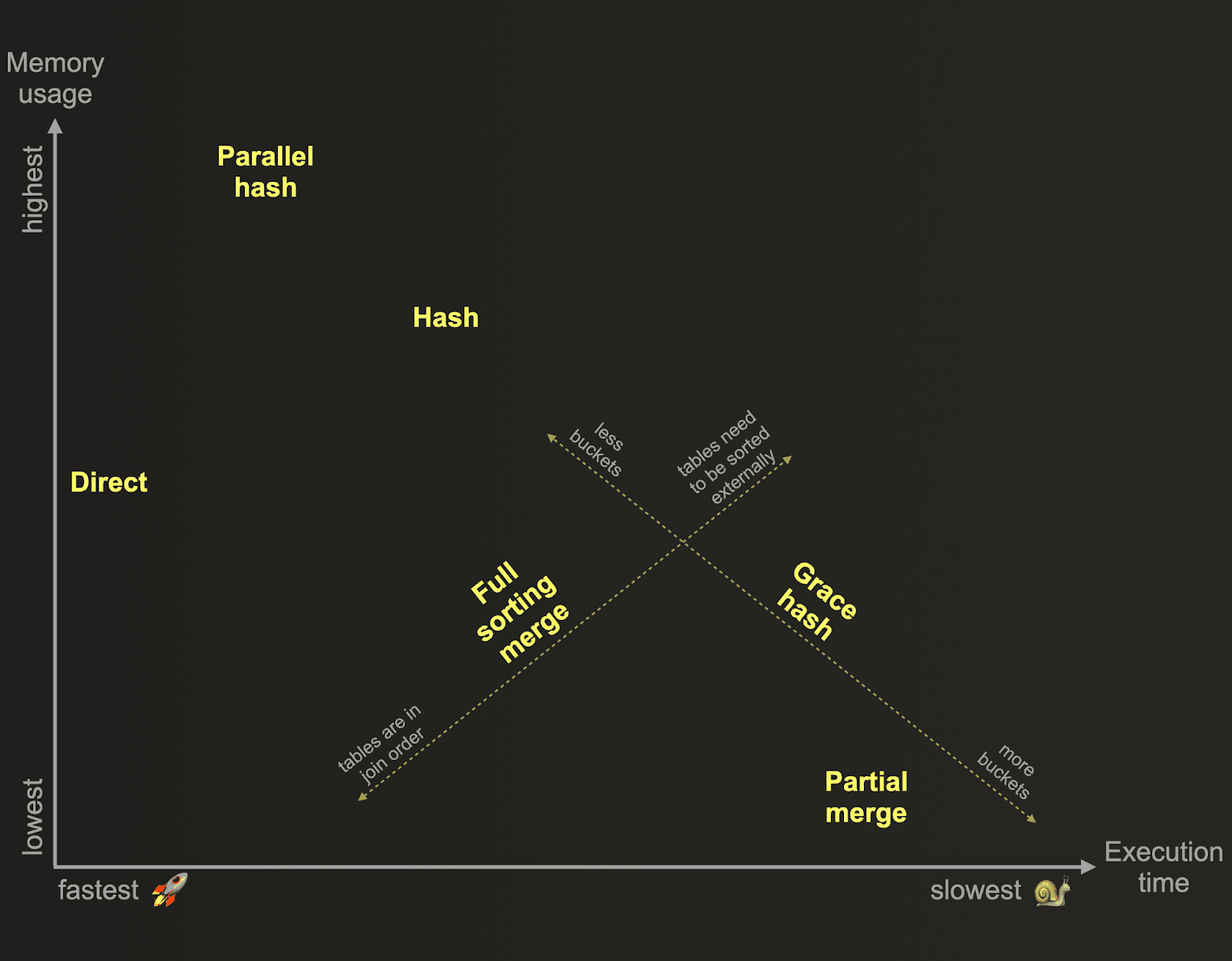
每种算法对不同 JOIN 类型的支持程度不同。各算法支持的 JOIN 类型完整列表可在此处找到。
你可以通过将 join_algorithm = 'auto'(默认值)让 ClickHouse 自动选择最佳算法,或根据你的工作负载进行显式控制。如果你需要选择 JOIN 算法来优化性能或内存开销,建议参考本指南。
为获得最佳性能:
- 在高性能工作负载中尽量减少 JOIN 的数量。
- 每个查询避免超过 3–4 个 JOIN。
- 在真实数据上对不同算法进行基准测试——性能会随 JOIN 键分布和数据规模而变化。
关于 JOIN 优化策略、JOIN 算法以及如何调优的更多信息,请参考ClickHouse 文档以及这篇博客系列。
