在本页中,我们会交替使用术语 "排序键" 来指代 "主键"。严格来说,在 ClickHouse 中二者是有区别的,但在本文档中,读者可以将这两个术语视为等同使用,其中 排序键 指的是表中 ORDER BY 子句所指定的列。
请注意,对于熟悉 OLTP 数据库 (例如 Postgres) 中类似术语的读者而言,ClickHouse 中主键 的工作方式有很大不同。
在 ClickHouse 中选择一个有效的 主键 对查询性能和存储效率至关重要。ClickHouse 将数据组织为多个 part,每个 part 都包含自己的稀疏 primary index。该索引通过减少扫描的数据量显著加快查询速度。此外,由于 主键 决定了磁盘上数据的物理排序,它会直接影响压缩效率。数据排序越合理,压缩效果越好,从而通过减少 I/O 进一步提升性能。
- 在选择 排序键 时,应优先考虑在查询过滤条件 (即
WHERE 子句) 中经常使用的列,尤其是那些能排除大量行的列。
- 与表中其他数据高度相关的列也很有价值,因为连续存储可在执行
GROUP BY 和 ORDER BY 操作时改善压缩比和内存效率。
可以应用一些简单规则来帮助选择 排序键。以下规则有时可能会互相冲突,因此请按顺序考虑它们。用户可以通过该过程确定若干个 键,通常 4-5 个就已足够:
Important
排序键 必须在建表时定义,之后无法添加。可以通过名为 projections 的特性在数据插入之后 (或之前) 为表添加额外的排序。注意,这会导致数据重复。更多细节参见此处。
请看下面的 posts_unordered 表。该表中每一行对应一个 Stack Overflow 帖子。
此表没有主键 —— 这可以从 ORDER BY tuple() 看出。
CREATE TABLE posts_unordered
(
`Id` Int32,
`PostTypeId` Enum('Question' = 1, 'Answer' = 2, 'Wiki' = 3, 'TagWikiExcerpt' = 4,
'TagWiki' = 5, 'ModeratorNomination' = 6, 'WikiPlaceholder' = 7, 'PrivilegeWiki' = 8),
`AcceptedAnswerId` UInt32,
`CreationDate` DateTime,
`Score` Int32,
`ViewCount` UInt32,
`Body` String,
`OwnerUserId` Int32,
`OwnerDisplayName` String,
`LastEditorUserId` Int32,
`LastEditorDisplayName` String,
`LastEditDate` DateTime,
`LastActivityDate` DateTime,
`Title` String,
`Tags` String,
`AnswerCount` UInt16,
`CommentCount` UInt8,
`FavoriteCount` UInt8,
`ContentLicense`LowCardinality(String),
`ParentId` String,
`CommunityOwnedDate` DateTime,
`ClosedDate` DateTime
)
ENGINE = MergeTree
ORDER BY tuple()
假设某位用户希望计算在 2024 年之后提交的问题数量,而这代表了其最常见的访问模式。
SELECT count()
FROM stackoverflow.posts_unordered
WHERE (CreationDate >= '2024-01-01') AND (PostTypeId = 'Question')
┌─count()─┐
│ 192611 │
└─────────┘
--highlight-next-line
1 row in set. Elapsed: 0.055 sec. Processed 59.82 million rows, 361.34 MB (1.09 billion rows/s., 6.61 GB/s.)
注意观察此查询读取的行数和字节数。在没有主键的情况下,查询必须扫描整个数据集。
使用 EXPLAIN indexes=1 可以确认,由于缺少索引,执行的是全表扫描。
EXPLAIN indexes = 1
SELECT count()
FROM stackoverflow.posts_unordered
WHERE (CreationDate >= '2024-01-01') AND (PostTypeId = 'Question')
┌─explain───────────────────────────────────────────────────┐
│ Expression ((Project names + Projection)) │
│ Aggregating │
│ Expression (Before GROUP BY) │
│ Expression │
│ ReadFromMergeTree (stackoverflow.posts_unordered) │
└───────────────────────────────────────────────────────────┘
5 rows in set. Elapsed: 0.003 sec.
假设有一个名为 posts_ordered 的表,包含相同的数据,其定义中的 ORDER BY 为 (PostTypeId, toDate(CreationDate)),即:
CREATE TABLE posts_ordered
(
`Id` Int32,
`PostTypeId` Enum('Question' = 1, 'Answer' = 2, 'Wiki' = 3, 'TagWikiExcerpt' = 4, 'TagWiki' = 5, 'ModeratorNomination' = 6,
'WikiPlaceholder' = 7, 'PrivilegeWiki' = 8),
...
)
ENGINE = MergeTree
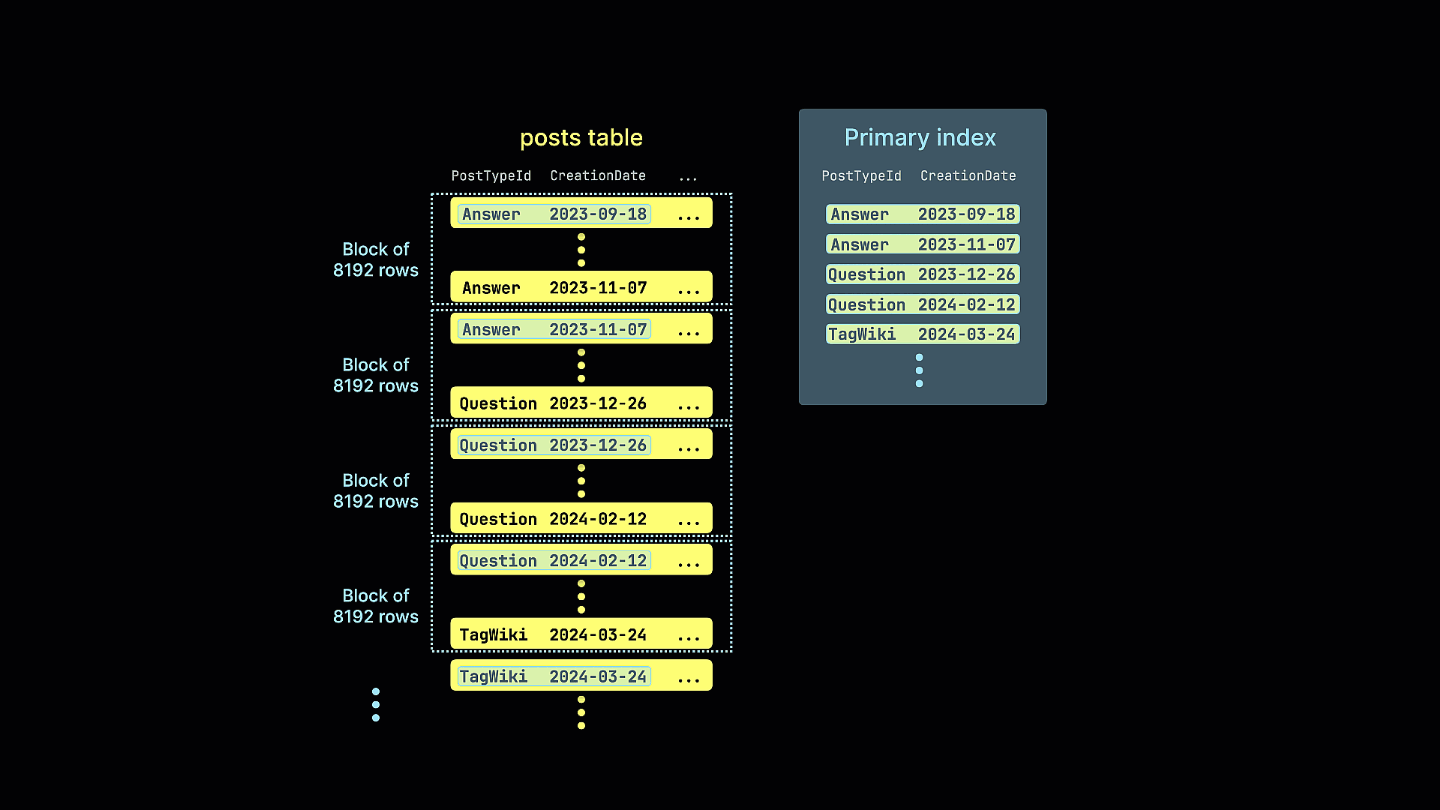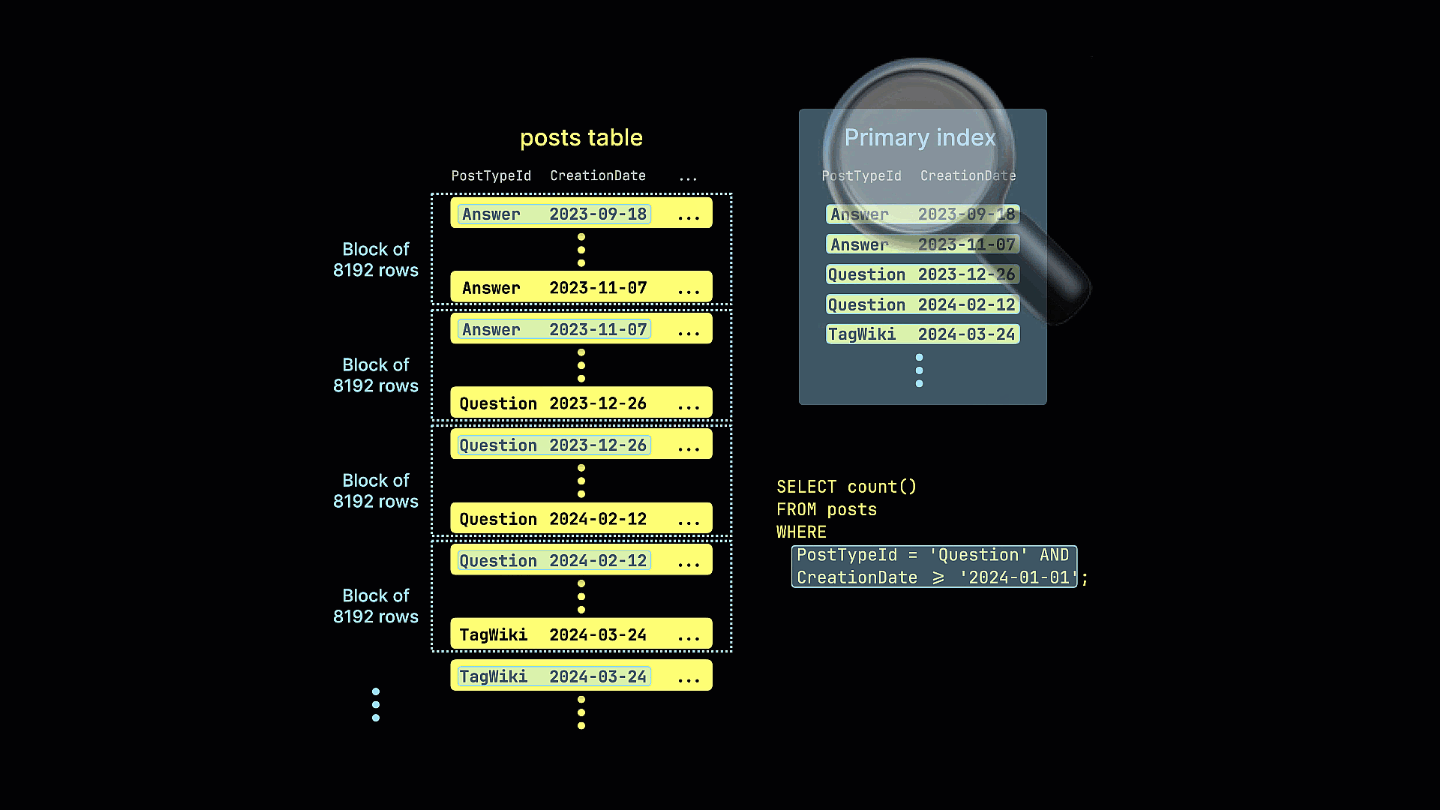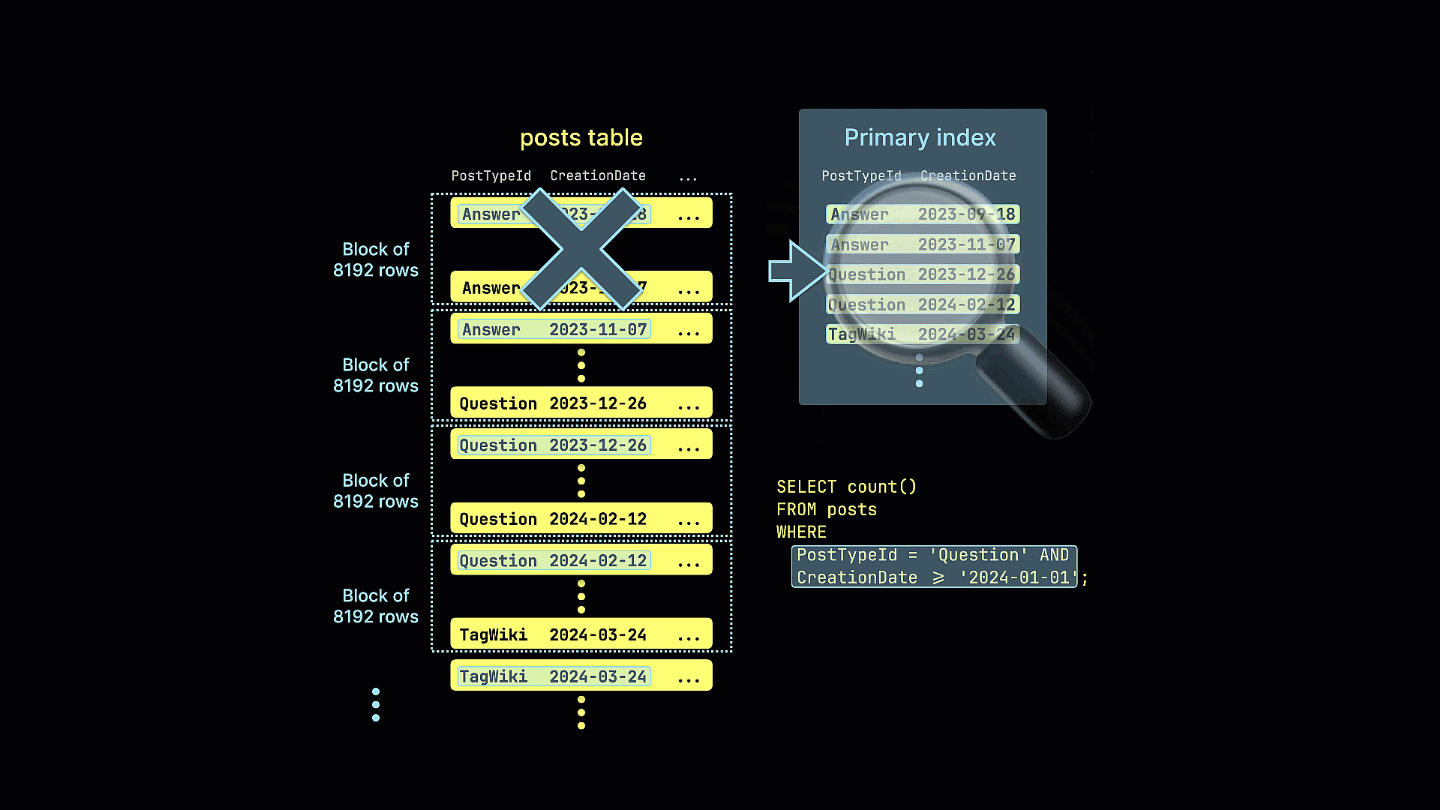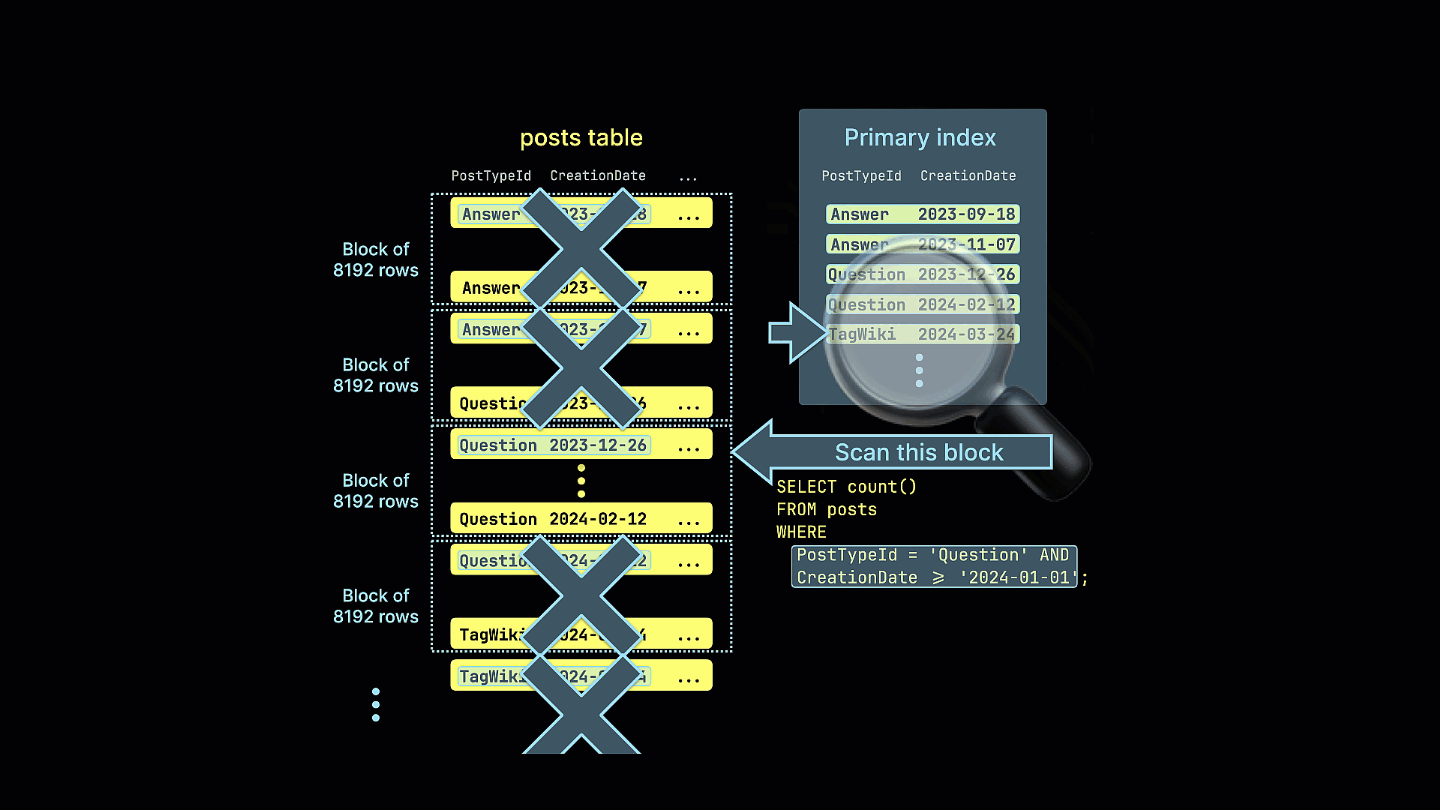
ORDER BY (PostTypeId, toDate(CreationDate))
PostTypeId 的基数为 8,是我们排序键中第一个条目的逻辑首选。考虑到按日期粒度进行过滤通常已经足够(同时仍然可以从 datetime 过滤中受益),因此我们使用 toDate(CreationDate) 作为排序键的第二个组成部分。这样还会生成更小的索引,因为日期可以用 16 位来表示,从而加快过滤速度。
下列动画展示了如何为 Stack Overflow 的 posts 表创建一个经过优化的稀疏主索引。索引针对的是数据块,而不是单独的行:
如果在具有此排序键的表上重复执行相同的查询:
SELECT count()
FROM stackoverflow.posts_ordered
WHERE (CreationDate >= '2024-01-01') AND (PostTypeId = 'Question')
┌─count()─┐
│ 192611 │
└─────────┘
--highlight-next-line
1 row in set. Elapsed: 0.013 sec. Processed 196.53 thousand rows, 1.77 MB (14.64 million rows/s., 131.78 MB/s.)
此查询现在利用稀疏索引,显著减少了读取的数据量,并将执行时间提升了 4 倍——请注意读取的行数和字节数的减少。
可以通过执行 EXPLAIN indexes=1 来确认是否使用了该索引。
EXPLAIN indexes = 1
SELECT count()
FROM stackoverflow.posts_ordered
WHERE (CreationDate >= '2024-01-01') AND (PostTypeId = 'Question')
┌─explain─────────────────────────────────────────────────────────────────────────────────────┐
│ Expression ((Project names + Projection)) │
│ Aggregating │
│ Expression (Before GROUP BY) │
│ Expression │
│ ReadFromMergeTree (stackoverflow.posts_ordered) │
│ Indexes: │
│ PrimaryKey │
│ Keys: │
│ PostTypeId │
│ toDate(CreationDate) │
│ Condition: and((PostTypeId in [1, 1]), (toDate(CreationDate) in [19723, +Inf))) │
│ Parts: 14/14 │
│ Granules: 39/7578 │
└─────────────────────────────────────────────────────────────────────────────────────────────┘
13 rows in set. Elapsed: 0.004 sec.
此外,我们还通过可视化展示了稀疏索引如何裁剪掉所有不可能包含示例查询匹配结果的行块:
注意
表中的所有列都会根据指定排序键的值进行排序,而不论这些列是否包含在该键中。例如,如果使用 CreationDate 作为键,则所有其他列中的值顺序都会与 CreationDate 列中的值顺序相对应。可以指定多个排序键——其排序语义与在 SELECT 查询中使用 ORDER BY 子句相同。
关于如何选择主键的完整进阶指南,请参见这里。
如果想更深入了解排序键如何提升压缩效果并进一步优化存储,请查阅官方指南:Compression in ClickHouse 和 Column Compression Codecs。