OPTIMIZE FINAL 操作,因为它会触发资源密集型操作,可能影响集群性能。
OPTIMIZE FINAL 与 FINAL
OPTIMIZE FINAL 和 FINAL 并不相同。后者有时必须使用,
才能获得无重复结果,例如在使用 ReplacingMergeTree 时。一般来说,
如果查询过滤的列与主键中的列相同,使用 FINAL 通常没问题。为何要避免?
开销高昂
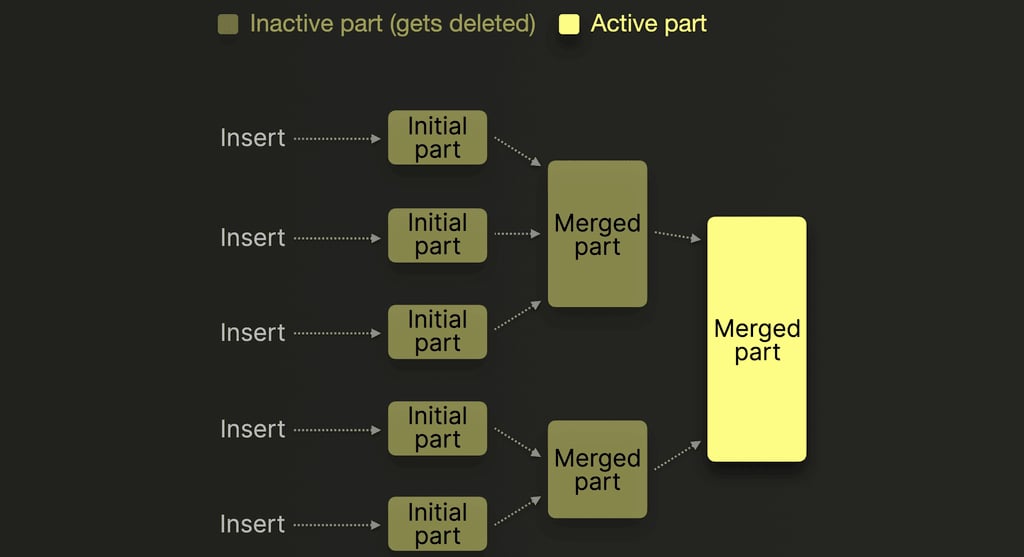
OPTIMIZE FINAL 会强制 ClickHouse 将所有活跃 parts 合并成一个 part,即使此前已经发生过大型合并也是如此。这个过程包括:
- 解压缩所有 parts
- 合并数据
- 重新压缩
- 将最终的 part 写入磁盘或对象存储
它会忽略安全限制
OPTIMIZE FINAL 会无视这一安全保护机制,这意味着:
- 它可能会尝试将多个 150 GB 的 parts合并成一个巨大的 part
- 这可能导致合并耗时很长、内存压力增大,甚至出现内存不足错误
- 这些大的 part 之后可能会变得难以继续合并,也就是说,出于上述原因,进一步合并它们的尝试可能会失败。在必须依赖合并才能保证查询时行为正确的情况下,这可能会带来不良后果,例如 ReplacingMergeTree 中的重复数据不断累积,从而导致查询时性能下降。