Партиции таблиц
Что такое партиции таблиц в ClickHouse?
Партиции объединяют части данных таблицы в семействе движков MergeTree в упорядоченные логические единицы — это способ организации данных, который имеет понятный смысл и привязан к конкретным критериям, таким как временные диапазоны, категории или другие ключевые атрибуты. Такие логические единицы упрощают управление данными, выполнение запросов и их оптимизацию.
PARTITION BY
Партиционирование можно включить при создании таблицы с помощью конструкции PARTITION BY. В ней может быть указано SQL-выражение по любым столбцам, результат которого определяет, к какой партиции относится строка.
Чтобы продемонстрировать это, мы расширим пример таблицы из раздела What are table parts, добавив конструкцию PARTITION BY toStartOfMonth(date), которая группирует части данных таблицы по месяцам продаж недвижимости:
Вы можете выполнить запрос к этой таблице в нашей песочнице ClickHouse SQL.
Структура на диске
Каждый раз, когда в таблицу вставляют набор строк, вместо создания (как минимум) одного единственного фрагмента данных, содержащего все вставленные строки (как описано здесь), ClickHouse создает новый фрагмент данных для каждого уникального значения ключа партиционирования среди вставленных строк:
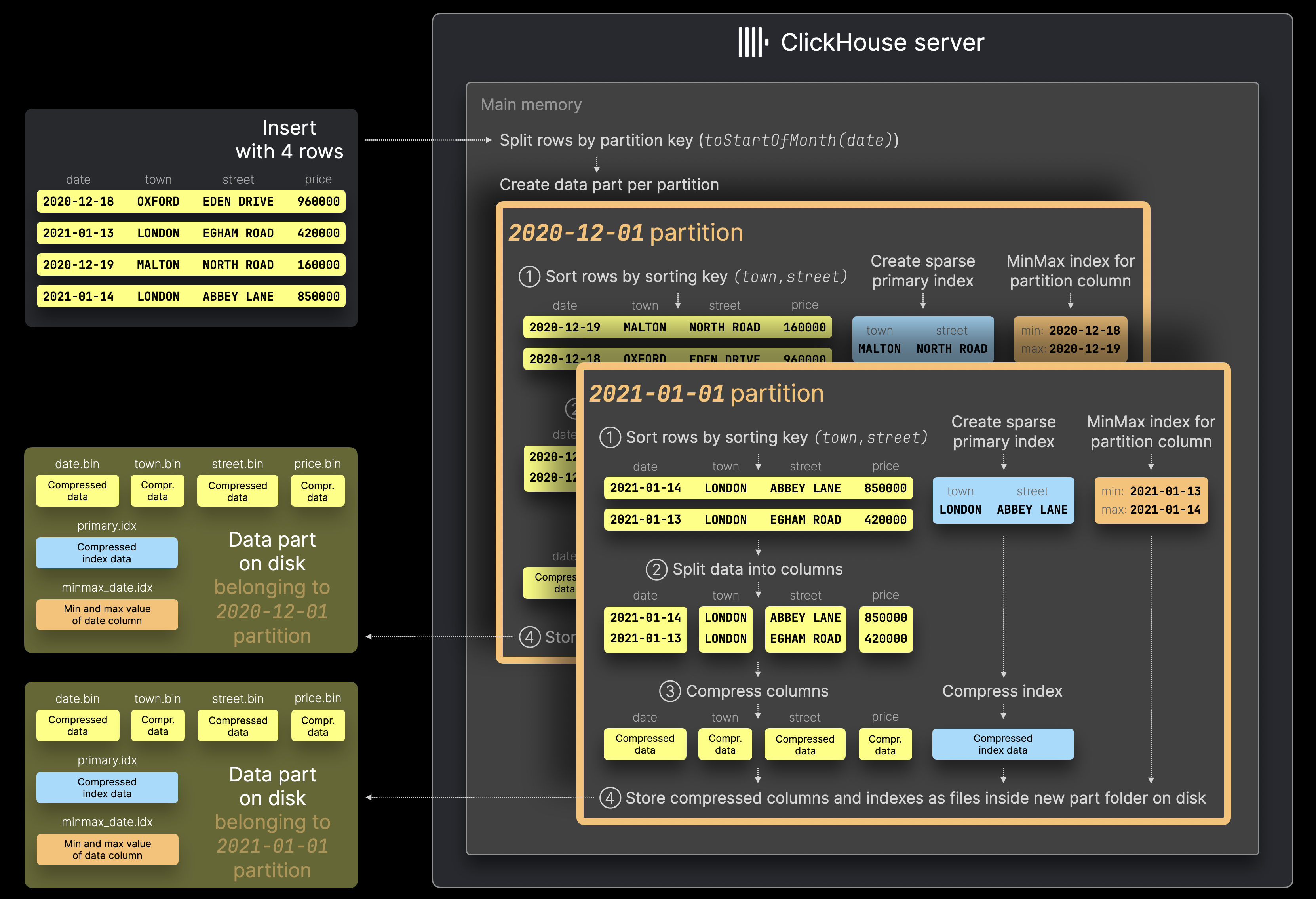
Сервер ClickHouse сначала разбивает строки из примерной операции INSERT с 4 строками, показанной на схеме выше, по значению ключа партиционирования toStartOfMonth(date).
Затем для каждой найденной партиции строки обрабатываются обычным образом, проходя несколько последовательных шагов (① Сортировка, ② Разделение на столбцы, ③ Сжатие, ④ Запись на диск).
Обратите внимание, что при включённом партиционировании ClickHouse автоматически создает индексы MinMax для каждого фрагмента данных. Это просто файлы для каждого столбца таблицы, используемого в выражении ключа партиционирования, содержащие минимальное и максимальное значения этого столбца внутри данного фрагмента данных.
Слияния по партициям
При включённом партиционировании ClickHouse сливает части данных только внутри партиций, но не между партициями. Ниже это показано на примере нашей таблицы выше:
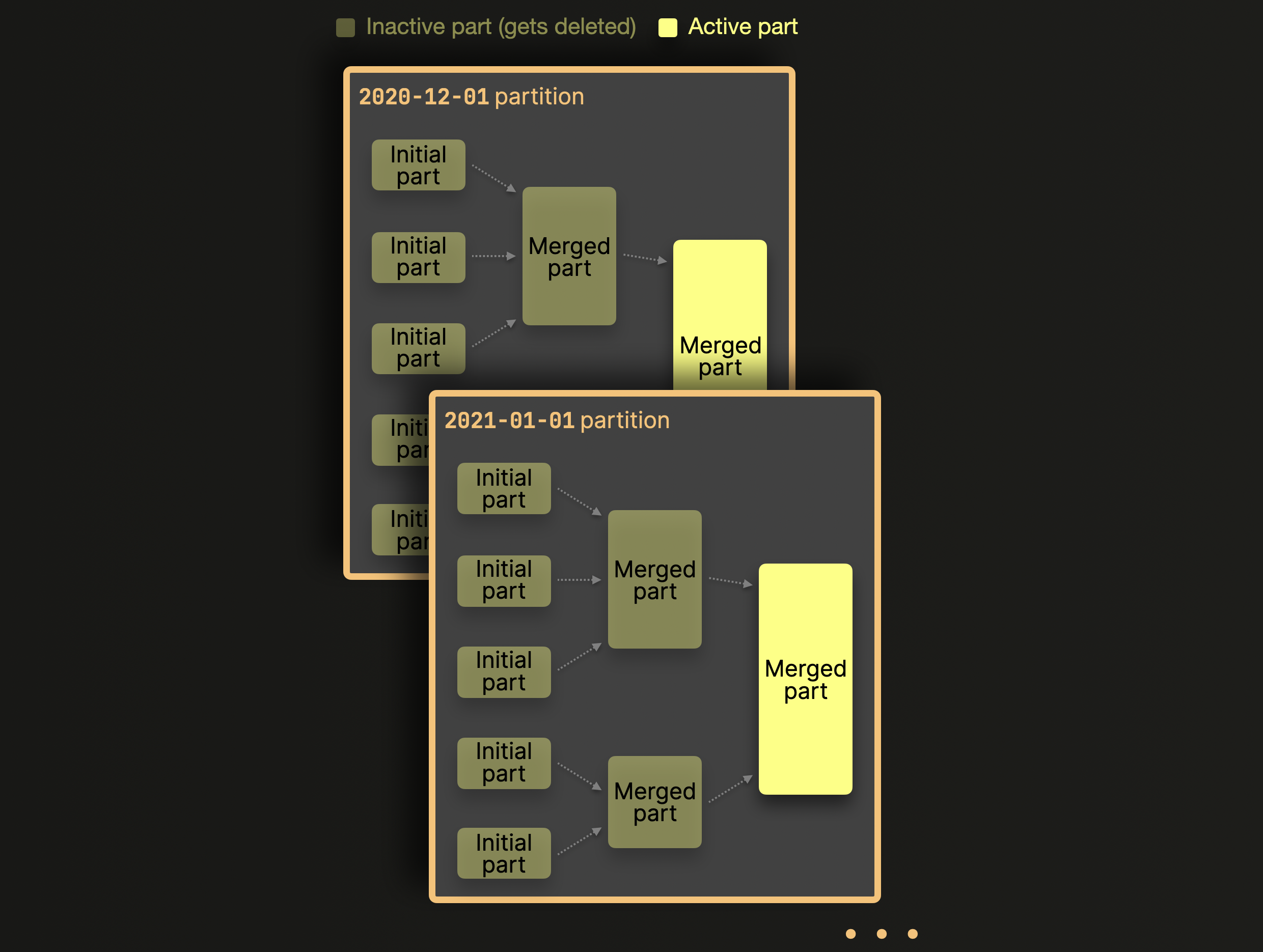
Как показано на схеме выше, части, относящиеся к разным партициям, никогда не сливаются. Если выбран ключ партиционирования с высокой кардинальностью, части, распределённые по тысячам партиций, никогда не станут кандидатами на слияние — будут превышены предварительно настроенные лимиты, что приведёт к печально известной ошибке Too many parts. Решение этой проблемы простое: выберите разумный ключ партиционирования с кардинальностью менее 1000..10000.
Мониторинг партиций
Вы можете получить список всех уникальных партиций таблицы из нашего примера, используя виртуальный столбец _partition_value:
Кроме того, ClickHouse отслеживает все парты и партиции всех таблиц в системной таблице system.parts, и следующий запрос возвращает для приведённой выше примерной таблицы список всех партиций, а также текущее количество активных партов и сумму строк в этих партах по каждой партиции:
Для чего используются разделы таблиц?
Управление данными
В ClickHouse партиционирование в первую очередь является механизмом управления данными. Логически организуя данные на основе выражения партиционирования, можно управлять каждой партицией независимо. Например, схема партиционирования в приведённой выше таблице позволяет реализовать сценарий, когда в основной таблице хранятся только данные за последние 12 месяцев, а более старые данные автоматически удаляются с помощью правила TTL (см. добавленную последнюю строку DDL-запроса):
Поскольку таблица партиционирована по toStartOfMonth(date), целые партиции (наборы частей таблицы), удовлетворяющие условию TTL, будут удалены, что делает операцию очистки более эффективной — без необходимости перезаписывать части.
Аналогично, вместо удаления старых данных их можно автоматически и эффективно перемещать на более экономичный уровень хранилища:
Оптимизация запросов
Разбиение данных на партиции может помочь с производительностью запросов, но это сильно зависит от характера доступа к данным. Если запросы обращаются только к нескольким партициям (в идеале к одной), производительность может улучшиться. Это обычно полезно только в том случае, если ключ партиционирования не входит в первичный ключ и вы фильтруете по нему, как показано в примере запроса ниже.
Запрос выполняется над приведённой выше примерной таблицей и вычисляет наивысшую цену среди всех проданных объектов недвижимости в Лондоне в декабре 2020 года, фильтруя по столбцу (date), используемому в ключе партиционирования таблицы, и по столбцу (town), используемому в первичном ключе таблицы (при этом date не является частью первичного ключа).
ClickHouse обрабатывает этот запрос, последовательно применяя методы отсечения данных, чтобы избежать обработки нерелевантных данных:
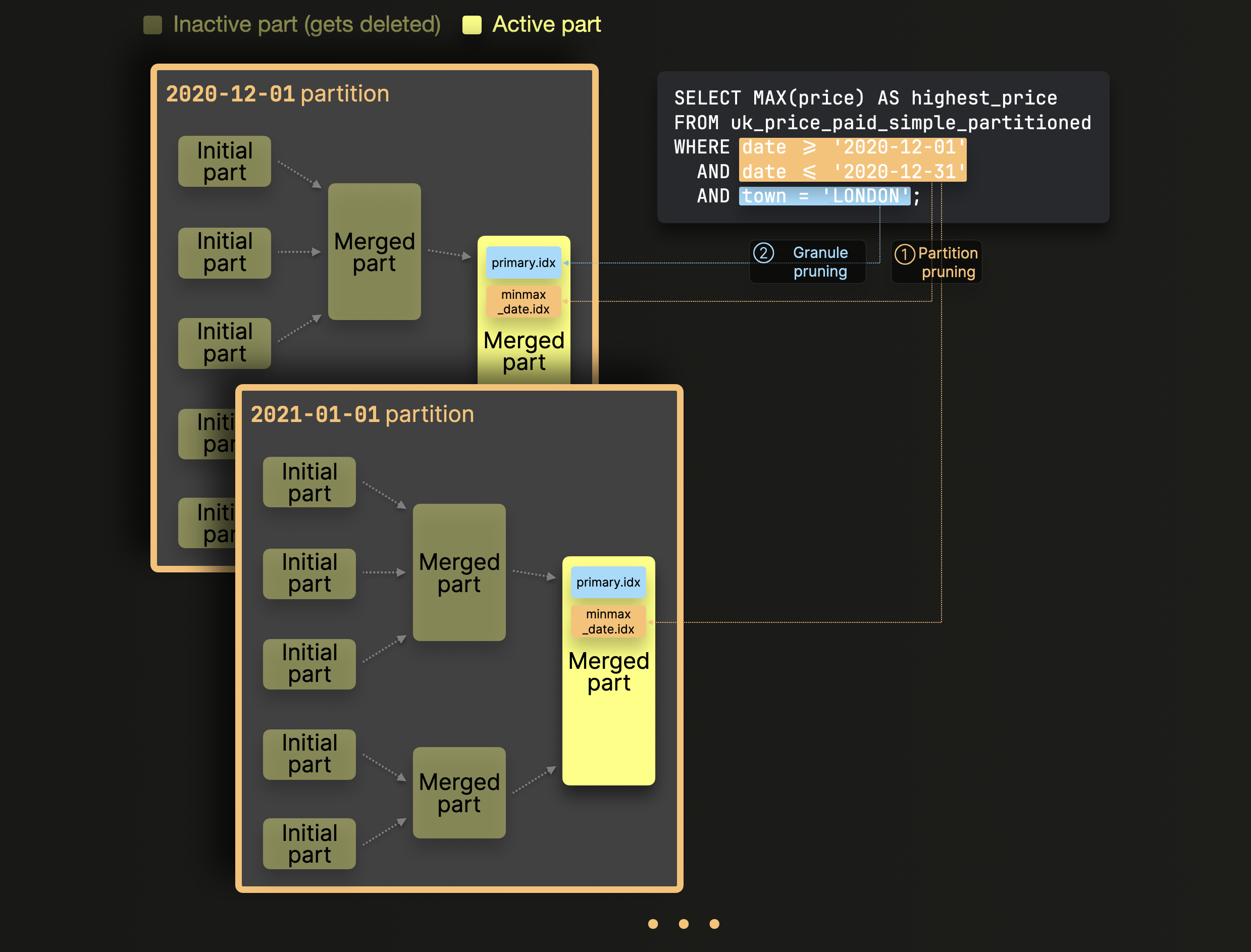
① Отсечение партиций (partition pruning): MinMax-индексы используются для игнорирования целых партиций (наборов частей), которые логически не могут удовлетворять фильтру запроса по столбцам, используемым в ключе партиционирования таблицы.
② Отсечение гранул (granule pruning): для оставшихся после шага ① частей данных их первичный индекс используется для игнорирования всех гранул (блоков строк), которые логически не могут удовлетворять фильтру запроса по столбцам, используемым в первичном ключе таблицы.
Мы можем наблюдать эти шаги отсечения данных, изучая физический план выполнения запроса для нашего примерного запроса выше с помощью оператора EXPLAIN:
Вывод выше показывает:
① Отсечение партиций (partition pruning): строки с 7 по 18 вывода EXPLAIN, показанного выше, показывают, что ClickHouse сначала использует MinMax-индекс поля date, чтобы найти 11 из 3257 существующих гранул (блоков строк), которые хранятся в 1 из 436 существующих активных частей данных (data parts) и содержат строки, удовлетворяющие date‑фильтру запроса.
② Отсечение гранул (granule pruning): строки с 19 по 24 вывода EXPLAIN, показанного выше, указывают, что ClickHouse затем использует первичный индекс (созданный по полю town) части данных, определённой на шаге ①, чтобы далее сократить число гранул (которые содержат строки, потенциально также удовлетворяющие town‑фильтру запроса) с 11 до 1. Это также отражено в выводе ClickHouse-client, который мы привели выше для выполненного запроса:
Это означает, что ClickHouse просканировал и обработал одну гранулу (блок из 8192 строк) за 6 миллисекунд при вычислении результата запроса.
Партиционирование — в первую очередь механизм управления данными
Имейте в виду, что выполнение запроса по всем партициям обычно медленнее, чем выполнение того же запроса по непартиционированной таблице.
При партиционировании данные, как правило, распределяются по большему числу партиций и частей данных, что часто приводит к тому, что ClickHouse сканирует и обрабатывает больший объём данных.
Мы можем продемонстрировать это, запустив один и тот же запрос как для примерной таблицы из раздела What are table parts (без включённого партиционирования), так и для нашей текущей примерной таблицы выше (с включённым партиционированием). Обе таблицы содержат одни и те же данные и одинаковое количество строк:
Однако таблица с включёнными партициями имеет больше активных частей данных, потому что, как уже упоминалось выше, ClickHouse сливает части данных только внутри одной партиции, но не между партициями:
Как показано выше, секционированная таблица uk_price_paid_simple_partitioned имеет более 600 секций, то есть 600 306 активных частей данных. Тогда как для нашей несекционированной таблицы uk_price_paid_simple все исходные части данных могли быть объединены фоновыми слияниями в одну активную часть.
Если мы проверим физический план выполнения запроса с предложением EXPLAIN для нашего приведённого выше примера запроса без фильтра по секции, выполняемого над секционированной таблицей, мы видим в строках 19 и 20 приведённого ниже вывода, что ClickHouse определил 671 из 3257 существующих гранул (блоков строк), распределённых по 431 из 436 существующих активных частей данных, которые потенциально содержат строки, удовлетворяющие фильтру запроса, и, следовательно, будут просканированы и обработаны движком запросов:
Физический план выполнения запроса для того же примерного запроса, выполняемого по таблице без секционирования, показывает в строках 11 и 12 приведённого ниже вывода, что ClickHouse определил 241 из 3083 существующих блоков строк в единственной активной части данных таблицы, которые потенциально содержат строки, удовлетворяющие фильтру запроса:
При выполнении запроса для секционированной версии таблицы ClickHouse сканирует и обрабатывает 671 блок строк (~ 5,5 миллиона строк) за 90 миллисекунд:
А при выполнении запроса по таблице без партиционирования ClickHouse сканирует и обрабатывает 241 блок (~ 2 миллиона строк) за 12 миллисекунд:
