Подходы к моделированию данных
Это Часть 3 руководства по миграции с PostgreSQL на ClickHouse. На практическом примере показано, как моделировать данные в ClickHouse при миграции с PostgreSQL.
Мы рекомендуем пользователям, мигрирующим с Postgres, прочитать руководство по моделированию данных в ClickHouse. В этом руководстве используется тот же набор данных Stack Overflow и рассматривается несколько подходов с использованием возможностей ClickHouse.
Первичные (упорядочивающие) ключи в ClickHouse
Пользователи, приходящие из OLTP-баз данных, часто ищут эквивалентную концепцию в ClickHouse. Замечая, что ClickHouse поддерживает синтаксис PRIMARY KEY, они могут быть склонны определять схему таблицы, используя те же ключи, что и в исходной OLTP-базе. Это некорректно.
Чем отличаются первичные ключи в ClickHouse?
Чтобы понять, почему использование OLTP-первичного ключа в ClickHouse не является корректным, необходимо разобраться в основах индексирования в ClickHouse. В качестве примера для сравнения мы используем Postgres, но эти общие концепции применимы и к другим OLTP-базам данных.
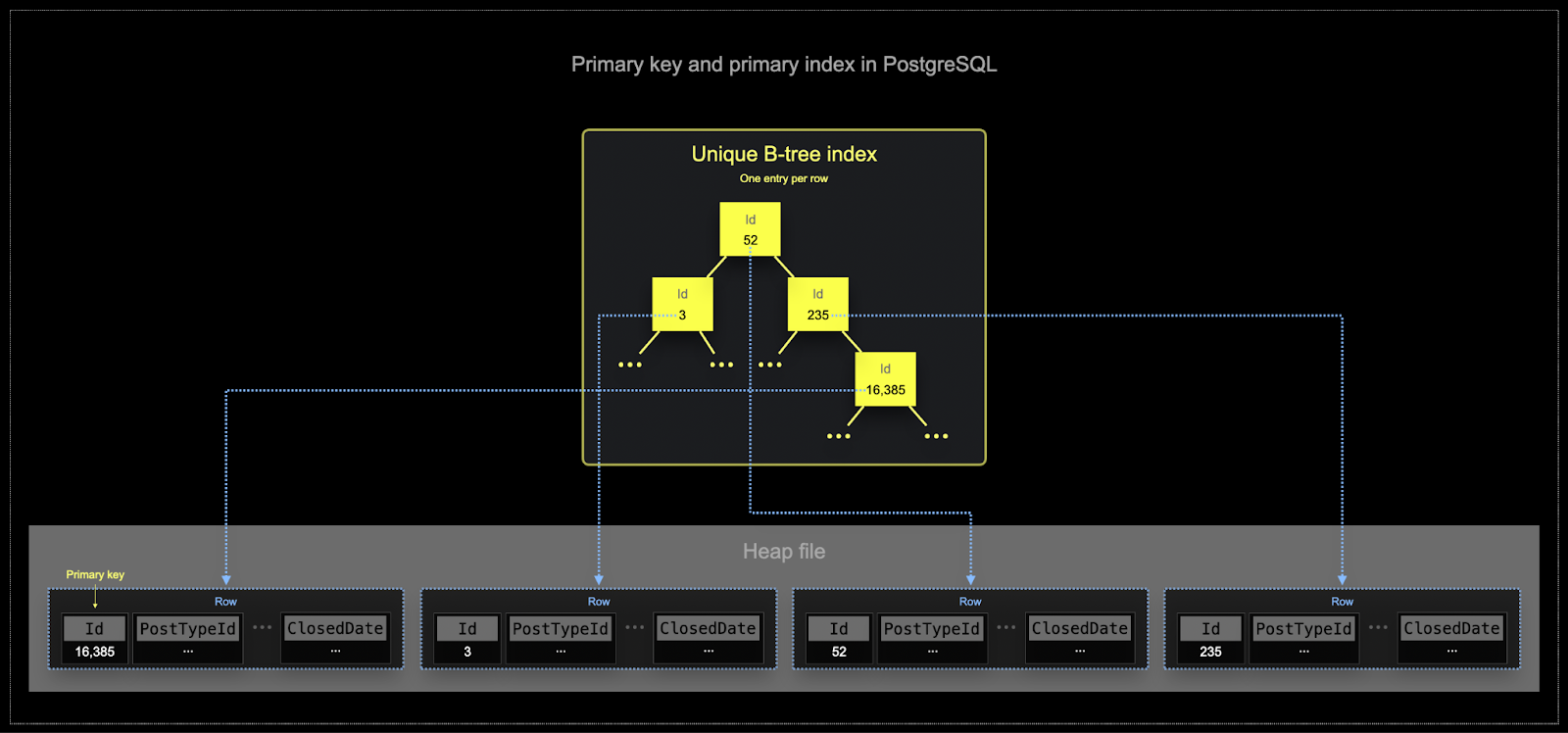
- Первичные ключи Postgres по определению уникальны для каждой строки. Использование B-деревьев позволяет эффективно находить отдельные строки по этому ключу. Хотя ClickHouse можно оптимизировать для поиска значения одной строки, аналитические нагрузки обычно требуют чтения нескольких столбцов, но для большого количества строк. Фильтры гораздо чаще должны определять подмножество строк, над которым будет выполняться агрегация.
- Эффективное использование памяти и диска критично для масштабов, на которых часто используется ClickHouse. Данные записываются в таблицы ClickHouse блоками, называемыми частями (parts), к которым в фоне применяются правила слияния. В ClickHouse каждая часть имеет свой собственный первичный индекс. При слиянии частей первичные индексы результирующей части также сливаются. В отличие от Postgres, эти индексы не строятся для каждой строки. Вместо этого первичный индекс для части содержит одну запись индекса на группу строк — такая техника называется разрежённым индексированием.
- Разрежённое индексирование возможно, потому что ClickHouse хранит строки части на диске в порядке, определённом заданным ключом. Вместо того чтобы напрямую находить отдельные строки (как индекс на основе B-дерева), разрежённый первичный индекс позволяет быстро (через двоичный поиск по записям индекса) определять группы строк, которые потенциально могут соответствовать запросу. Найденные группы потенциально подходящих строк затем параллельно потоково передаются в движок ClickHouse для поиска совпадений. Такая схема индекса позволяет сделать первичный индекс небольшим (он полностью помещается в оперативной памяти), при этом существенно ускоряя выполнение запросов, особенно диапазонных, которые типичны для аналитических сценариев.
За более подробной информацией обратитесь к этому подробному руководству.
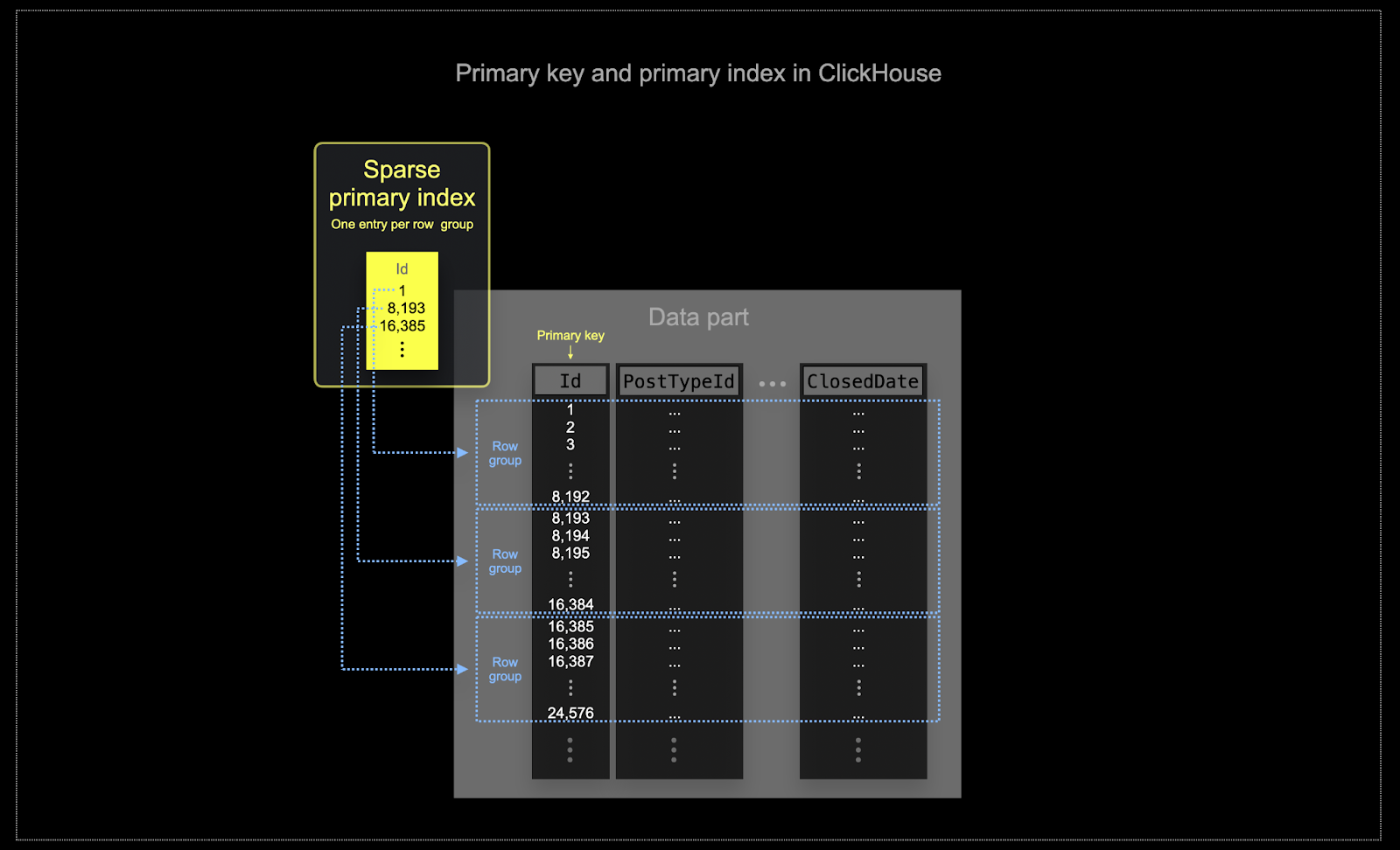
Выбранный ключ в ClickHouse определяет не только индекс, но и порядок, в котором данные записываются на диск. Из-за этого он может существенно влиять на уровень сжатия, что, в свою очередь, отражается на производительности запросов. Упорядочивающий ключ, при котором значения большинства столбцов записываются в непрерывном (смежном) порядке, позволит выбранному алгоритму сжатия (и кодекам) более эффективно сжимать данные.
Все столбцы в таблице будут отсортированы на основе значения указанного упорядочивающего ключа, независимо от того, включены ли они в сам ключ. Например, если в качестве ключа используется
CreationDate, порядок значений во всех остальных столбцах будет соответствовать порядку значений в столбцеCreationDate. Можно указать несколько упорядочивающих ключей — в этом случае порядок будет таким же, как при использовании предложенияORDER BYв запросеSELECT.
Выбор упорядочивающего ключа
Рассуждения и шаги по выбору упорядочивающего ключа, на примере таблицы posts, приведены здесь.
При использовании репликации в реальном времени с CDC (фиксацией изменений данных) существуют дополнительные ограничения, которые необходимо учитывать; обратитесь к этой документации за описанием техник настройки упорядочивающих ключей при работе с CDC.
Партиции
Пользователям Postgres знакома концепция партиционирования таблиц, которая используется для повышения производительности и управляемости крупных баз данных за счёт разделения таблиц на более мелкие, удобные в обслуживании части, называемые партициями. Такое партиционирование может выполняться по диапазону значений для указанного столбца (например, по датам), по заданным спискам или по хешу ключа. Это позволяет администраторам организовывать данные на основе конкретных критериев, таких как диапазоны дат или географические регионы. Партиционирование помогает улучшить производительность запросов за счёт более быстрого доступа к данным через отсечение партиций (partition pruning) и более эффективного индексирования. Оно также упрощает задачи обслуживания, такие как резервное копирование и очистка данных, позволяя выполнять операции над отдельными партициями, а не над всей таблицей целиком. Кроме того, партиционирование может существенно повысить масштабируемость баз данных PostgreSQL за счёт распределения нагрузки по нескольким партициям.
В ClickHouse партиционирование задаётся для таблицы при её первоначальном определении с помощью конструкции PARTITION BY. Она может содержать SQL-выражение над любыми столбцами, результат которого определяет, в какую партицию будет отправлена строка.
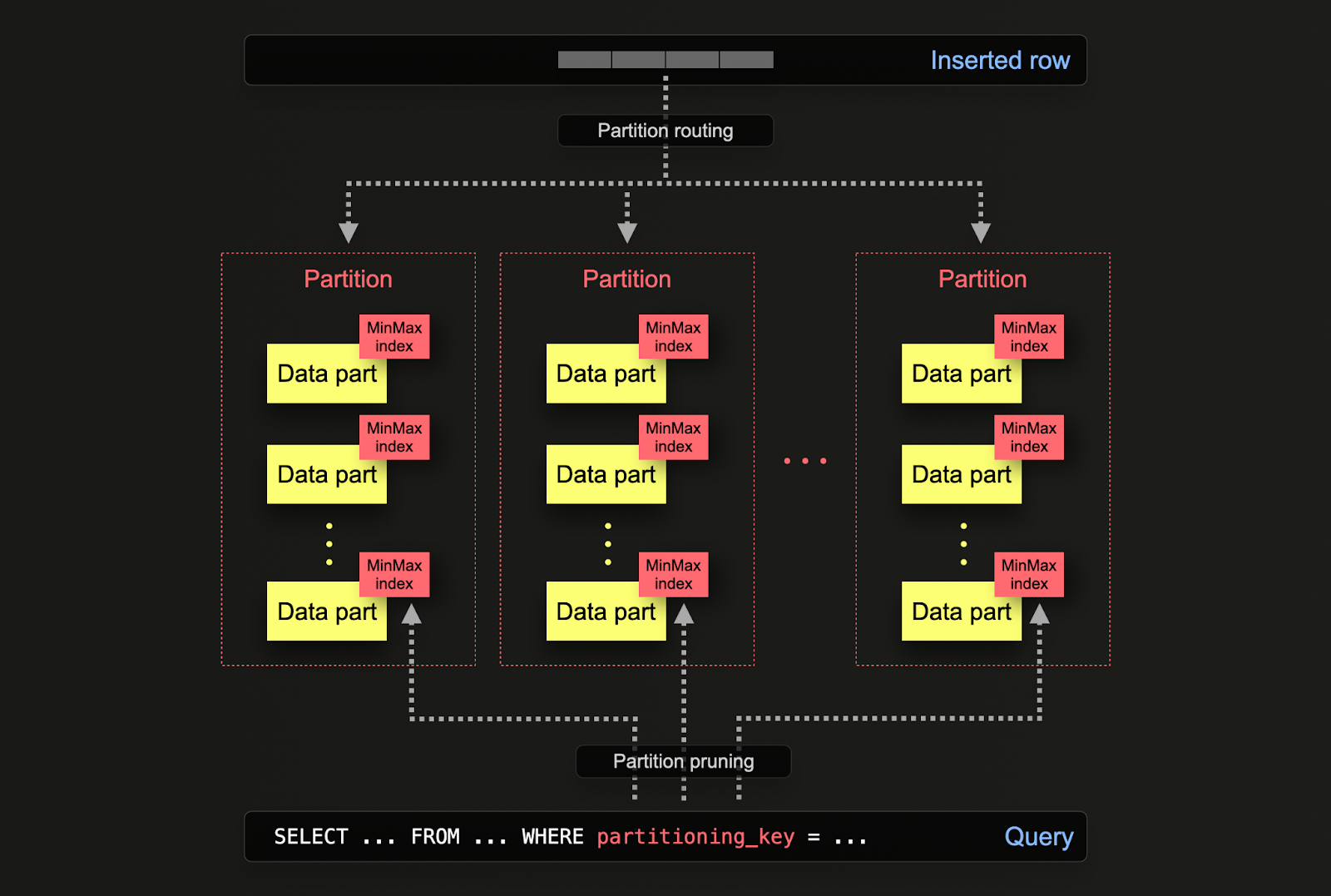
Части данных логически связаны с каждой партицией на диске и могут запрашиваться изолированно. В примере ниже мы партиционируем таблицу posts по году с использованием выражения toYear(CreationDate). По мере вставки строк в ClickHouse это выражение вычисляется для каждой строки, и строка направляется в соответствующую партицию, если она уже существует (если строка является первой для данного года, партиция будет создана).
Для полного описания партиционирования см. раздел «Партиции таблиц».
Области применения партиций
Партиционирование в ClickHouse имеет схожие области применения с Postgres, но с некоторыми тонкими отличиями. В частности:
- Управление данными — В ClickHouse партиционирование в первую очередь следует рассматривать как механизм управления данными, а не как технику оптимизации запросов. Логически разделяя данные по ключу, можно независимо работать с каждой партицией, например, удалять её. Это позволяет эффективно перемещать партиции, а значит и соответствующие подмножества данных, между уровнями хранилища в зависимости от времени или удалять устаревшие данные/эффективно удалять их из кластера. В примере ниже мы удаляем записи за 2008 год.
- Оптимизация запросов - Хотя партиционирование может улучшить производительность запросов, это сильно зависит от паттернов доступа. Если запросы затрагивают только несколько партиций (в идеале одну), производительность потенциально может повыситься. Это обычно полезно только в том случае, если ключ партиционирования не входит в первичный ключ и вы фильтруете по нему. Однако запросы, которым необходимо охватить много партиций, могут работать хуже, чем без партиционирования (так как в результате партиционирования может появиться больше частей данных). Преимущество работы с одной партицией будет ещё менее заметным, вплоть до отсутствия, если ключ партиционирования уже является одним из первых столбцов в первичном ключе. Партиционирование также может использоваться для оптимизации запросов с GROUP BY, если значения в каждой партиции уникальны. Однако в целом пользователям следует в первую очередь оптимизировать первичный ключ и рассматривать партиционирование как технику оптимизации запросов только в исключительных случаях, когда паттерны доступа обращаются к определённому предсказуемому подмножеству в пределах суток, например, при партиционировании по дням, если большинство запросов обращается к данным за последний день.
Рекомендации по партициям
Пользователям следует рассматривать партиционирование как технику управления данными. Оно особенно подходит, когда данные необходимо удалять из кластера при работе с временными рядами, например, самую старую партицию можно просто удалить.
Важно: Убедитесь, что выражение для ключа партиционирования не приводит к множеству с высокой кардинальностью, то есть следует избегать создания более чем 100 партиций. Например, не делите данные на партиции по столбцам с высокой кардинальностью, таким как идентификаторы клиентов или имена. Вместо этого сделайте идентификатор клиента или имя первым столбцом в выражении ORDER BY.
Внутри ClickHouse создаются части для вставляемых данных. По мере вставки новых данных количество частей увеличивается. Чтобы предотвратить чрезмерно большое количество частей, что ухудшит производительность запросов (больше файлов для чтения), части объединяются в фоновом асинхронном процессе. Если количество частей превышает предварительно настроенный предел, ClickHouse выбросит исключение при вставке — ошибку «too many parts». Этого не должно происходить при нормальной эксплуатации и такое возможно только в случае неправильной конфигурации ClickHouse или его некорректного использования, например, при большом количестве мелких вставок.
Поскольку части создаются независимо для каждой партиции, увеличение числа партиций приводит к росту количества частей, то есть оно является кратным числу партиций. Ключи партиционирования с высокой кардинальностью, таким образом, могут вызывать эту ошибку и их следует избегать.
Материализованные представления и проекции
Postgres позволяет создавать несколько индексов для одной таблицы, что позволяет оптимизировать ее под различные паттерны доступа. Эта гибкость позволяет администраторам и разработчикам настраивать производительность базы данных под конкретные запросы и операционные потребности. Концепция проекций в ClickHouse, хотя и не является полной аналогией этого, позволяет задавать несколько выражений ORDER BY для таблицы.
В документации по моделированию данных ClickHouse мы рассматриваем, как материализованные представления могут использоваться в ClickHouse для предварительного вычисления агрегаций, трансформации строк и оптимизации запросов под разные паттерны доступа.
Для последней из этих задач мы привели пример, где материализованное представление отправляет строки в целевую таблицу с иным ключом сортировки, чем у исходной таблицы, в которую вставляются данные.
Например, рассмотрим следующий запрос:
Этот запрос требует сканирования всех 90 млн строк (хотя и довольно быстро), так как UserId не является ключом упорядочения.
Ранее мы решали это с помощью материализованного представления, выступающего в роли словаря для PostId. Ту же задачу можно решить
с помощью projection. Команда ниже добавляет
проекцию с ORDER BY user_id.
Обратите внимание, что сначала необходимо создать проекцию, а затем материализовать её. Вторая команда приводит к тому, что данные дважды сохраняются на диск в двух разных порядках сортировки. Проекцию также можно определить при создании данных, как показано ниже, и далее она будет автоматически поддерживаться по мере вставки данных.
Если проекция создаётся с помощью ALTER, её создание происходит асинхронно при выполнении команды MATERIALIZE PROJECTION. Пользователи могут отслеживать ход этой операции с помощью следующего запроса, ожидая, пока is_done не станет равным 1.
Если мы повторим приведённый выше запрос, то увидим, что производительность значительно улучшилась, но за счёт дополнительного расхода дискового пространства.
С помощью команды EXPLAIN мы также подтверждаем, что при выполнении этого запроса была использована проекция:
Когда использовать проекции
Проекции — привлекательная функция для новых пользователей, поскольку они автоматически обновляются при вставке данных. Кроме того, запросы можно отправлять в одну таблицу, где проекции используются по возможности для ускорения времени отклика.
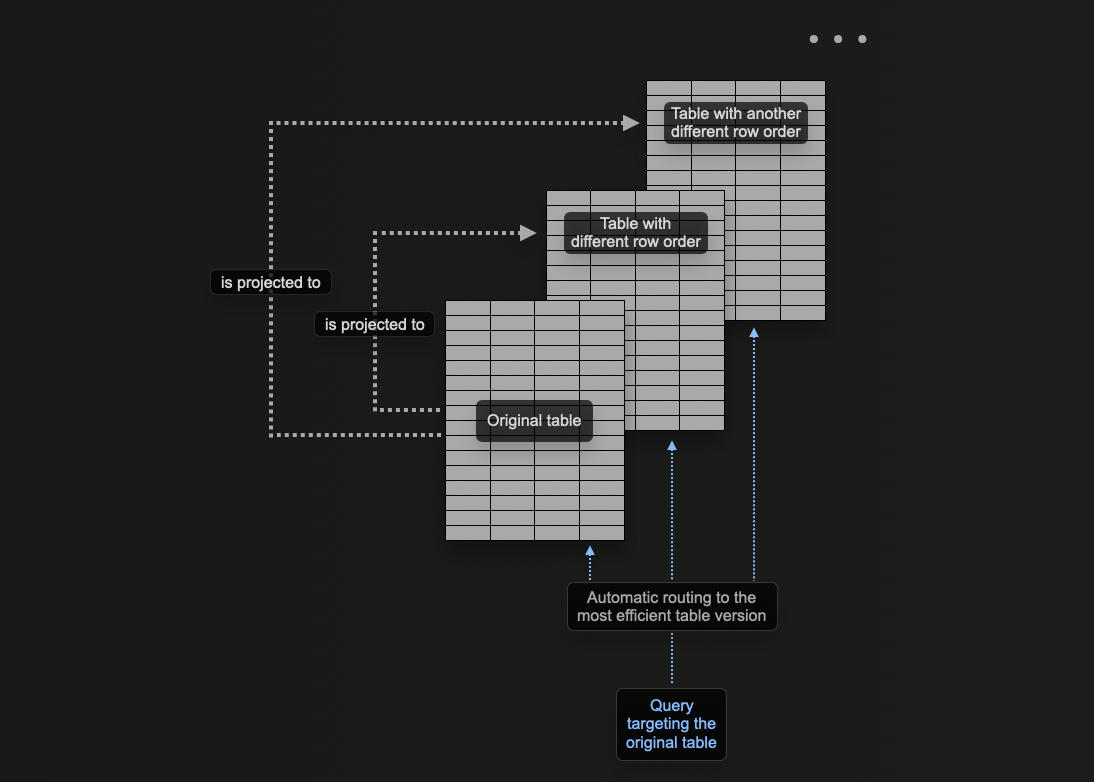
Это отличается от материализованных представлений, где пользователь должен выбрать соответствующую оптимизированную целевую таблицу или переписать запрос в зависимости от фильтров. Это повышает требования к пользовательским приложениям и увеличивает сложность на стороне клиента.
Несмотря на эти преимущества, проекции имеют некоторые присущие им ограничения, о которых вам следует знать, поэтому их следует применять с осторожностью.
Мы рекомендуем использовать проекции в следующих случаях:
- Требуется полная переупорядочка данных. Хотя выражение в
проекции теоретически может использовать
GROUP BY, материализованные представления более эффективны для поддержания агрегатов. Оптимизатор запросов также с большей вероятностью использует проекции с простой переупорядочкой, т. е.SELECT * ORDER BY x. Вы можете выбрать подмножество столбцов в этом выражении для уменьшения объёма хранилища. - Пользователи готовы к связанному с этим увеличению объёма хранилища и накладным расходам на двойную запись данных. Протестируйте влияние на скорость вставки и оцените накладные расходы на хранение.
Начиная с версии 25.5, ClickHouse поддерживает виртуальный столбец _part_offset в
проекциях. Это открывает более эффективный с точки зрения использования пространства способ хранения проекций.
Подробнее см. «Проекции»
Денормализация
Поскольку Postgres — реляционная база данных, его модель данных сильно нормализована и часто состоит из сотен таблиц. В ClickHouse денормализация иногда может быть полезна для оптимизации производительности JOIN.
Вы можете ознакомиться с этим руководством, в котором показаны преимущества денормализации набора данных Stack Overflow в ClickHouse.
На этом завершается наше базовое руководство по миграции с Postgres на ClickHouse. Рекомендуем прочитать руководство по моделированию данных в ClickHouse, чтобы узнать больше о продвинутых возможностях ClickHouse.
