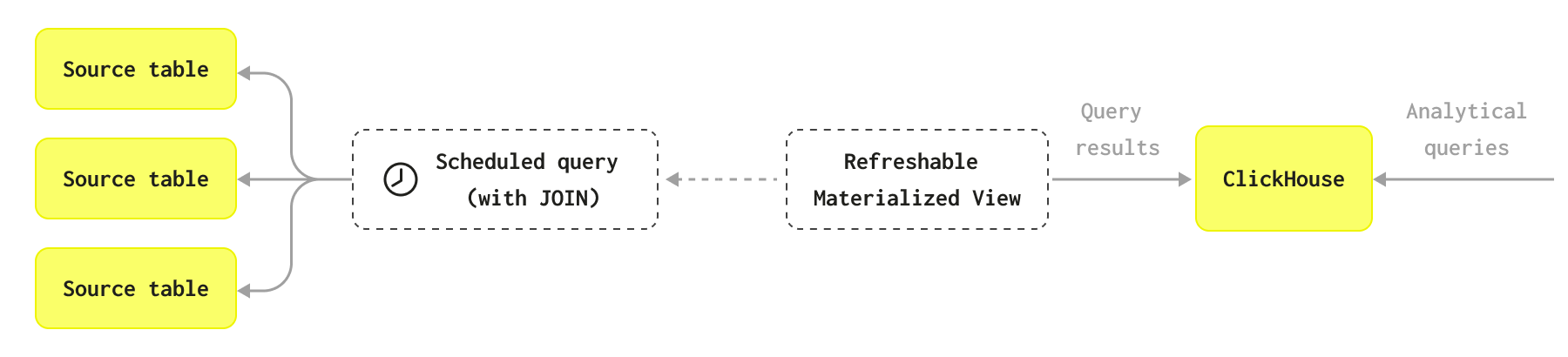
Обновляемые материализованные представления концептуально похожи на материализованные представления в традиционных OLTP-базах данных: они хранят результат заданного запроса для быстрого доступа и уменьшают необходимость многократно выполнять ресурсоемкие запросы. В отличие от инкрементных материализованных представлений ClickHouse, здесь требуется периодическое выполнение запроса по всему набору данных, результаты которого сохраняются в целевой таблице, из которой затем выполняются запросы. Теоретически этот результирующий набор данных должен быть меньше исходного набора, что позволяет выполнять последующие запросы быстрее.
На диаграмме показано, как работают обновляемые материализованные представления:
Также вы можете просмотреть следующее видео:
Когда следует использовать обновляемые материализованные представления?
Инкрементные материализованные представления в ClickHouse чрезвычайно мощны и, как правило, масштабируются значительно лучше, чем подход, используемый обновляемыми материализованными представлениями, особенно в случаях, когда необходимо выполнить агрегирование по одной таблице. Поскольку агрегирование вычисляется только для каждого блока данных в момент вставки, а инкрементные состояния сливаются в итоговую таблицу, запрос всегда выполняется только над подмножеством данных. Этот метод масштабируется вплоть до петабайт данных и обычно является предпочтительным.
Однако существуют сценарии, когда этот инкрементный процесс не требуется или неприменим. Некоторые задачи либо несовместимы с инкрементным подходом, либо не требуют обновлений в режиме реального времени, и более уместной является периодическая перестройка. Например, может потребоваться регулярно выполнять полный пересчёт представления над всем набором данных, поскольку оно использует сложное соединение, которое несовместимо с инкрементным подходом.
Обновляемые материализованные представления могут запускать пакетные процессы, выполняющие такие задачи, как денормализация. Между обновляемыми материализованными представлениями можно создавать зависимости таким образом, что одно представление зависит от результатов другого и выполняется только после его завершения. Это может заменить планировщик рабочих процессов или простые DAG, такие как задание dbt. Чтобы узнать больше о том, как задавать зависимости между обновляемыми материализованными представлениями, перейдите к разделу Dependencies на странице CREATE VIEW.
Как происходит обновление refreshable materialized view?
Refreshable materialized view автоматически обновляются с интервалом, который задаётся при их создании.
Например, следующее материализованное представление обновляется каждую минуту:
CREATE MATERIALIZED VIEW table_name_mv
REFRESH EVERY 1 MINUTE TO table_name AS
...
Если вы хотите принудительно обновить материализованное представление, можно использовать оператор SYSTEM REFRESH VIEW:
Когда обновляемое материализованное представление обновлялось в последний раз?
Чтобы узнать время последнего обновления обновляемого материализованного представления, вы можете выполнить запрос к системной таблице system.view_refreshes, как показано ниже:
Функция APPEND позволяет добавлять новые строки в конец таблицы вместо замены всего представления.
Одно из применений этой возможности — создание снимков значений в определённый момент времени. Например, представим, что у нас есть таблица events, которую заполняет поток сообщений из Kafka, Redpanda или другой платформы потоковой передачи данных.
В этом наборе данных в столбце uuid содержится 4096 значений. Мы можем написать следующий запрос, чтобы найти те из них, у которых наибольшее суммарное количество:
SELECT
uuid,
sum(count) AS count
FROM events
GROUP BY ALL
ORDER BY count DESC
LIMIT 10
┌─uuid─┬───count─┐
│ c6f │ 5676468 │
│ 951 │ 5669731 │
│ 6a6 │ 5664552 │
│ b06 │ 5662036 │
│ 0ca │ 5658580 │
│ 2cd │ 5657182 │
│ 32a │ 5656475 │
│ ffe │ 5653952 │
│ f33 │ 5653783 │
│ c5b │ 5649936 │
└──────┴─────────┘
Предположим, мы хотим каждые 10 секунд получать количество записей для каждого uuid и сохранять его в новой таблице events_snapshot. Схема таблицы events_snapshot будет выглядеть следующим образом:
CREATE TABLE events_snapshot (
ts DateTime32,
uuid String,
count UInt64
)
ENGINE = MergeTree
ORDER BY uuid;
Затем мы можем создать обновляемое материализованное представление, которое будет заполнять эту таблицу:
CREATE MATERIALIZED VIEW events_snapshot_mv
REFRESH EVERY 10 SECOND APPEND TO events_snapshot
AS SELECT
now() AS ts,
uuid,
sum(count) AS count
FROM events
GROUP BY ALL;
Затем мы можем выполнить запрос к events_snapshot, чтобы получить временной ряд количества для конкретного uuid:
В руководстве по денормализации данных показаны различные методы денормализации данных с использованием набора данных Stack Overflow. Мы заполняем данными следующие таблицы: votes, users, badges, posts и postlinks.
В этом руководстве мы показали, как денормализовать набор данных postlinks в таблицу posts с помощью следующего запроса:
SELECT
posts.*,
arrayMap(p -> (p.1, p.2), arrayFilter(p -> p.3 = 'Linked' AND p.2 != 0, Related)) AS LinkedPosts,
arrayMap(p -> (p.1, p.2), arrayFilter(p -> p.3 = 'Duplicate' AND p.2 != 0, Related)) AS DuplicatePosts
FROM posts
LEFT JOIN (
SELECT
PostId,
groupArray((CreationDate, RelatedPostId, LinkTypeId)) AS Related
FROM postlinks
GROUP BY PostId
) AS postlinks ON posts_types_codecs_ordered.Id = postlinks.PostId;
Затем мы показали, как выполнить разовую вставку этих данных в таблицу posts_with_links, но в производственной среде нам нужно запускать эту операцию периодически.
Обе таблицы — posts и postlinks — потенциально могут изменяться. Поэтому, вместо того чтобы пытаться реализовать это соединение с использованием инкрементных материализованных представлений, часто бывает достаточно просто запланировать выполнение этого запроса с фиксированным интервалом, например раз в час, сохраняя результаты в таблице post_with_links.
В таком случае помогает обновляемое материализованное представление, и мы можем создать его с помощью следующего запроса:
CREATE MATERIALIZED VIEW posts_with_links_mv
REFRESH EVERY 1 HOUR TO posts_with_links AS
SELECT
posts.*,
arrayMap(p -> (p.1, p.2), arrayFilter(p -> p.3 = 'Linked' AND p.2 != 0, Related)) AS LinkedPosts,
arrayMap(p -> (p.1, p.2), arrayFilter(p -> p.3 = 'Duplicate' AND p.2 != 0, Related)) AS DuplicatePosts
FROM posts
LEFT JOIN (
SELECT
PostId,
groupArray((CreationDate, RelatedPostId, LinkTypeId)) AS Related
FROM postlinks
GROUP BY PostId
) AS postlinks ON posts_types_codecs_ordered.Id = postlinks.PostId;
Представление будет выполнено немедленно, а затем каждый час, согласно настройкам, чтобы гарантировать, что обновления в исходной таблице отражаются в нём. Важно, что при повторном выполнении запроса результирующий набор данных обновляется атомарно и прозрачно.
Примечание
Синтаксис здесь идентичен инкрементальному материализованному представлению, за исключением того, что мы добавляем оператор REFRESH:
В руководстве по интеграции dbt и ClickHouse мы заполнили набор данных IMDb следующими таблицами: actors, directors, genres, movie_directors, movies и roles.
Затем можно использовать следующий запрос для вычисления сводной информации по каждому актёру, упорядоченной по количеству появлений в фильмах.
SELECT
id, any(actor_name) AS name, uniqExact(movie_id) AS movies,
round(avg(rank), 2) AS avg_rank, uniqExact(genre) AS genres,
uniqExact(director_name) AS directors, max(created_at) AS updated_at
FROM (
SELECT
imdb.actors.id AS id,
concat(imdb.actors.first_name, ' ', imdb.actors.last_name) AS actor_name,
imdb.movies.id AS movie_id, imdb.movies.rank AS rank, genre,
concat(imdb.directors.first_name, ' ', imdb.directors.last_name) AS director_name,
created_at
FROM imdb.actors
INNER JOIN imdb.roles ON imdb.roles.actor_id = imdb.actors.id
LEFT JOIN imdb.movies ON imdb.movies.id = imdb.roles.movie_id
LEFT JOIN imdb.genres ON imdb.genres.movie_id = imdb.movies.id
LEFT JOIN imdb.movie_directors ON imdb.movie_directors.movie_id = imdb.movies.id
LEFT JOIN imdb.directors ON imdb.directors.id = imdb.movie_directors.director_id
)
GROUP BY id
ORDER BY movies DESC
LIMIT 5;
Получение результата занимает не так уж много времени, но предположим, что мы хотим сделать это ещё быстрее и менее ресурсоёмко.
Допустим, этот набор данных также постоянно обновляется — фильмы постоянно выходят, а новые актёры и режиссёры продолжают появляться.
Пришло время для обновляемого материализованного представления, поэтому сначала создадим целевую таблицу для результатов:
CREATE MATERIALIZED VIEW imdb.actor_summary_mv
REFRESH EVERY 1 MINUTE TO imdb.actor_summary AS
SELECT
id,
any(actor_name) AS name,
uniqExact(movie_id) AS num_movies,
avg(rank) AS avg_rank,
uniqExact(genre) AS unique_genres,
uniqExact(director_name) AS uniq_directors,
max(created_at) AS updated_at
FROM
(
SELECT
imdb.actors.id AS id,
concat(imdb.actors.first_name, ' ', imdb.actors.last_name) AS actor_name,
imdb.movies.id AS movie_id,
imdb.movies.rank AS rank,
genre,
concat(imdb.directors.first_name, ' ', imdb.directors.last_name) AS director_name,
created_at
FROM imdb.actors
INNER JOIN imdb.roles ON imdb.roles.actor_id = imdb.actors.id
LEFT JOIN imdb.movies ON imdb.movies.id = imdb.roles.movie_id
LEFT JOIN imdb.genres ON imdb.genres.movie_id = imdb.movies.id
LEFT JOIN imdb.movie_directors ON imdb.movie_directors.movie_id = imdb.movies.id
LEFT JOIN imdb.directors ON imdb.directors.id = imdb.movie_directors.director_id
)
GROUP BY id
ORDER BY num_movies DESC;
Представление будет выполнено сразу, а затем — каждую минуту, как задано в конфигурации, чтобы изменения в исходной таблице сразу отражались в нём. Наш прежний запрос, получавший сводную информацию об актёрах, стал синтаксически проще и значительно быстрее!
SELECT *
FROM imdb.actor_summary
ORDER BY num_movies DESC
LIMIT 5
Предположим, мы добавим нового актёра по имени «Clicky McClickHouse» в наши исходные данные, который снялся во множестве фильмов!
INSERT INTO imdb.actors VALUES (845466, 'Clicky', 'McClickHouse', 'M');
INSERT INTO imdb.roles SELECT
845466 AS actor_id,
id AS movie_id,
'Himself' AS role,
now() AS created_at
FROM imdb.movies
LIMIT 10000, 910;
Не проходит и 60 секунд, как наша целевая таблица обновляется и отражает, насколько плодовито Clicky снимается в кино:
SELECT *
FROM imdb.actor_summary
ORDER BY num_movies DESC
LIMIT 5;