Табличные функции S3
s3 позволяет читать файлы из S3-совместимого хранилища и записывать их в него. Общий вид синтаксиса:
- path — URL бакета с путём к файлу. В режиме только для чтения поддерживаются следующие подстановочные шаблоны:
*,?,{abc,def}и{N..M}, гдеN,M— числа, а'abc','def'— строки. Дополнительные сведения см. в документации по использованию подстановочных шаблонов в path. - format — Формат файла.
- structure — Структура таблицы. Формат:
'column1_name column1_type, column2_name column2_type, ...'. - compression — Параметр необязателен. Поддерживаемые значения:
none,gzip/gz,brotli/br,xz/LZMA,zstd/zst. По умолчанию сжатие определяется автоматически по расширению файла.
Подготовка
DESCRIBE:
DESCRIBE TABLE должен показать, как ClickHouse автоматически определяет структуру этих данных в том виде, в каком они представлены в S3 бакете. Обратите внимание, что он также автоматически распознаёт и распаковывает данные, сжатые в формате gzip:
MergeTree в качестве пункта назначения. Приведённый ниже оператор создаёт таблицу с именем trips в базе данных по умолчанию. Обратите внимание, что мы решили изменить некоторые из этих типов данных, определённых выше, в частности не использовать модификатор типа данных Nullable(), так как это может привести к хранению некоторого лишнего объёма данных и дополнительным накладным расходам на производительность:
pickup_date. Обычно ключ партиционирования используют для управления данными, но позже мы будем использовать его для распараллеливания записи в S3.
Каждая запись в нашем наборе данных о такси соответствует одной поездке. Эти анонимизированные данные содержат 20 млн записей и хранятся в сжатом виде в S3 бакете https://datasets-documentation.s3.eu-west-3.amazonaws.com/ в папке nyc-taxi. Данные представлены в формате TSV, примерно по 1 млн строк в каждом файле.
Чтение данных из S3
TabSeparatedWithNames содержит имена столбцов в первой строке. Другие форматы, такие как CSV или TSV, для этого запроса вернут автоматически сгенерированные столбцы, например c1, c2, c3 и т. д.
Запросы также поддерживают виртуальные столбцы, такие как _path и _file, которые содержат информацию соответственно о пути к бакету и имени файла. Например:
MergeTree в ClickHouse.
Использование clickhouse-local
clickhouse-local позволяет быстро обрабатывать локальные файлы без развертывания и настройки сервера ClickHouse. С помощью этой утилиты можно выполнять любые запросы, использующие табличную функцию s3. Например:
Вставка данных из S3
s3 с простым оператором INSERT. Обратите внимание, что нам не нужно перечислять столбцы, поскольку нужную структуру задаёт целевая таблица. Для этого столбцы должны идти в порядке, указанном в DDL-операторе таблицы: столбцы сопоставляются в соответствии с их позицией в части SELECT. Вставка всех 10 млн строк может занять несколько минут в зависимости от экземпляра ClickHouse. Ниже мы вставим 1 млн строк, чтобы обеспечить быстрый отклик. При необходимости измените выражение LIMIT или набор выбираемых столбцов, чтобы импортировать нужные подмножества:
Удаленная вставка через ClickHouse Local
clickhouse-local. В примере ниже мы читаем данные из S3 бакета и вставляем их в ClickHouse с помощью функции remote:
Чтобы выполнить это по защищённому SSL-соединению, используйте функцию
remoteSecure.Экспорт данных
s3. Для этого потребуются соответствующие разрешения. Необходимые учетные данные мы передаем в запросе, но дополнительные варианты описаны на странице Управление учетными данными.
В простом примере ниже мы используем табличную функцию как пункт назначения, а не как источник. Здесь мы передаем 10 000 строк из таблицы trips в бакет, указывая сжатие lz4 и выходной формат CSV:
s3 — они будут выведены из SELECT.
Разбиение больших файлов
INSERT несколько раз, каждый раз выбирая подмножество данных. В ClickHouse есть возможность автоматически разбивать данные по файлам с помощью ключа PARTITION.
В примере ниже мы создаём десять файлов, используя остаток от деления значения функции rand(). Обратите внимание, что идентификатор получившейся партиции используется в имени файла. В результате получается десять файлов с числовым суффиксом, например trips_0.csv.lz4, trips_1.csv.lz4 и т. д.:
payment_type служит естественным ключом партиционирования с мощностью 5.
Использование кластеров
INSERT INTO SELECT можно частично снизить нагрузку на ресурсы, если выполнять вставку в distributed таблицу, данные по-прежнему читает, парсит и обрабатывает один узел. Чтобы решить эту проблему и обеспечить горизонтальное масштабирование чтения, предусмотрена функция s3Cluster.
Узел, получающий запрос, называется инициатором и создает соединение с каждым узлом в кластере. Glob-шаблон, определяющий, какие файлы нужно прочитать, разворачивается в набор файлов. Инициатор распределяет файлы между узлами кластера, которые выступают в роли воркеров. Эти воркеры, в свою очередь, по мере завершения чтения запрашивают новые файлы для обработки. Этот механизм позволяет масштабировать чтение по горизонтали.
Функция s3Cluster использует тот же формат, что и варианты для одного узла, но дополнительно требует указать целевой кластер, чтобы определить узлы-воркеры:
cluster_name— Имя кластера, которое используется для построения набора адресов и параметров подключения к удалённым и локальным серверам.source— URL файла или набора файлов. Поддерживает следующие подстановочные шаблоны в режиме только для чтения:*,?,{'abc','def'}и{N..M}, где N, M — числа, abc, def — строки. Подробнее см. в разделе Подстановочные шаблоны в пути.access_key_idиsecret_access_key— Ключи, задающие учётные данные для использования с указанной конечной точкой. Необязательны.format— Формат файла.structure— Структура таблицы. Формат: ‘column1_name column1_type, column2_name column2_type, …’.
s3, учётные данные необязательны, если бакет не защищён или доступ настраивается через окружение, например с помощью ролей IAM. Однако, в отличие от функции s3, начиная с версии 22.3.1 структуру необходимо указывать в запросе, то есть схема не определяется автоматически.
Эта функция в большинстве случаев будет использоваться как часть INSERT INTO SELECT. В этом случае часто выполняется вставка в distributed таблицу. Ниже приведён простой пример, где trips_all — это distributed таблица. Хотя эта таблица использует кластер events, не требуется, чтобы для чтения и записи использовались согласованные узлы:
s3cluster.
Движки таблиц S3
s3 позволяют выполнять разовые запросы к данным, хранящимся в S3, их синтаксис довольно многословен. Чтобы не указывать URL бакета и учетные данные снова и снова, ClickHouse предоставляет движок таблицы S3.
path— URL бакета с путем к файлу. В режиме только для чтения поддерживаются следующие подстановочные шаблоны:*,?,{abc,def}и{N..M}, где N, M — числа, ‘abc’, ‘def’ — строки. Дополнительную информацию см. здесь.format— формат файла.aws_access_key_id,aws_secret_access_key- Долгосрочные учетные данные пользователя учетной записи AWS. Их можно использовать для аутентификации запросов. Параметр необязателен. Если учетные данные не указаны, используются значения из файла конфигурации. Дополнительную информацию см. в разделе Управление учетными данными.compression— Тип сжатия. Поддерживаемые значения: none, gzip/gz, brotli/br, xz/LZMA, zstd/zst. Параметр необязателен. По умолчанию тип сжатия определяется автоматически по расширению файла.
Чтение данных
trips_raw, используя первые десять файлов в формате TSV из бакета https://datasets-documentation.s3.eu-west-3.amazonaws.com/nyc-taxi/. Каждый из них содержит по 1 млн строк:
{0..9}, чтобы ограничиться первыми десятью файлами. После создания мы можем выполнять запросы к этой таблице, как к любой другой таблице:
Вставка данных
S3 поддерживает параллельное чтение. Запись поддерживается только в том случае, если определение таблицы не содержит glob-шаблонов. Поэтому в приведённую выше таблицу нельзя выполнять запись.
Чтобы продемонстрировать запись, создайте таблицу, указывающую на доступный для записи S3 бакет:
- Указать настройку
s3_create_new_file_on_insert=1. Это приведет к созданию нового файла при каждой вставке. В конец имени каждого файла будет добавляться числовой суффикс, который будет монотонно увеличиваться с каждой операцией вставки. Для приведенного выше примера следующая вставка приведет к созданию файла trips_1.bin. - Указать настройку
s3_truncate_on_insert=1. Это приведет к усечению файла, то есть после завершения он будет содержать только вновь вставленные строки.
s3_truncate_on_insert.
Несколько замечаний о движке таблицы S3:
- В отличие от традиционной таблицы семейства
MergeTree, удаление таблицыS3не удаляет лежащие в основе данные. - Полный список настроек для этого типа таблиц можно найти здесь.
- Учитывайте следующие ограничения при использовании этого движка:
- Запросы ALTER не поддерживаются
- Операции SAMPLE не поддерживаются
- Индексы, включая первичные и skip-индексы, не поддерживаются.
Управление учетными данными
s3 или в определении таблицы S3. Хотя это может быть приемлемо при эпизодическом использовании, в рабочей среде требуются менее явные механизмы аутентификации. Для этого в ClickHouse предусмотрено несколько вариантов:
-
Укажите сведения о подключении в config.xml или эквивалентном файле конфигурации в каталоге conf.d. Ниже показано содержимое примерного файла для установки из пакета Debian.
Эти учетные данные будут использоваться для любых запросов, в которых указанная выше конечная точка является точным префиксом запрошенного URL. Также обратите внимание, что в этом примере можно указать заголовок авторизации как альтернативу ключу доступа и секретному ключу. Полный список поддерживаемых настроек можно найти здесь.
-
В примере выше показан параметр конфигурации
use_environment_credentials. Его также можно задать глобально на уровнеs3:Этот параметр включает попытку получать учетные данные S3 из окружения, что позволяет использовать доступ через роль IAM. В частности, используется следующий порядок получения:- Поиск переменных окружения
AWS_ACCESS_KEY_ID,AWS_SECRET_ACCESS_KEYиAWS_SESSION_TOKEN - Проверка в $HOME/.aws
- Временные учетные данные, полученные через AWS Security Token Service — то есть через API
AssumeRole - Проверка наличия учетных данных в переменных окружения ECS
AWS_CONTAINER_CREDENTIALS_RELATIVE_URIилиAWS_CONTAINER_CREDENTIALS_FULL_URIиAWS_ECS_CONTAINER_AUTHORIZATION_TOKEN. - Получение учетных данных через метаданные экземпляра Amazon EC2, если AWS_EC2_METADATA_DISABLED не установлена в
true. - Эти же настройки можно задать и для конкретной конечной точки, используя то же правило сопоставления по префиксу.
- Поиск переменных окружения
Оптимизация производительности
Настройка хранилища S3
Wide and Compact. Хотя в текущей реализации используется стандартное поведение ClickHouse (которое задаётся настройками min_bytes_for_wide_part и min_rows_for_wide_part), мы ожидаем, что в будущих выпусках поведение для S3 изменится — например, более высокое значение min_bytes_for_wide_part по умолчанию будет способствовать более активному использованию формата Compact и, соответственно, уменьшению числа файлов. Если вы используете только хранилище S3, возможно, вам уже сейчас стоит настроить эти параметры.
MergeTree с хранением в S3
s3 и связанный с ними движок таблицы позволяют запрашивать данные в S3, используя привычный синтаксис ClickHouse. Однако с точки зрения возможностей управления данными и производительности они ограничены. Поддержка primary indexes отсутствует, no-cache не поддерживается, а вставкой файлов должен управлять пользователь.
ClickHouse рассматривает S3 как привлекательное решение для хранения данных, особенно в случаях, когда производительность запросов к более «холодным» данным менее критична и пользователи стремятся разделить хранение и вычислительные ресурсы. Для этого предусмотрена поддержка использования S3 в качестве хранилища для движка MergeTree. Это позволит вам воспользоваться преимуществами S3 в плане масштабируемости и стоимости, сохранив при этом высокую производительность вставки и запросов движка MergeTree.
Уровни хранения
Создание диска
config.xml, либо, что предпочтительнее, создать новый файл в conf.d. Ниже приведён пример объявления S3-диска:
Создание политики хранения
Создание таблицы
Изменение таблицы
<path>. Обратите внимание, что имена наших томов и дисков не меняются. Новые данные, вставляемые в нашу таблицу, будут размещаться на диске по умолчанию, пока не будет достигнуто значение move_factor * disk_size, после чего данные будут перемещены в S3.
Репликация
ReplicatedMergeTree. Подробнее см. в руководстве Репликация одного сегмента между двумя регионами AWS с использованием объектного хранилища S3.
Чтение и запись
- По умолчанию максимальное число потоков обработки запроса, используемых на любом этапе конвейера обработки запроса, равно числу ядер. Некоторые этапы лучше поддаются распараллеливанию, чем другие, поэтому это значение задает верхнюю границу. Несколько этапов запроса могут выполняться одновременно, поскольку данные поступают с диска в потоковом режиме. Поэтому фактическое число потоков, используемых для запроса, может превышать это значение. Изменяется с помощью настройки max_threads.
- Чтение из S3 по умолчанию асинхронное. Это поведение определяется настройкой
remote_filesystem_read_method, для которой по умолчанию установлено значениеthreadpool. При обработке запроса ClickHouse читает гранулы страйпами. Каждый такой страйп потенциально может содержать много столбцов. Поток читает столбцы для своих гранул один за другим. Вместо того чтобы делать это синхронно, для всех столбцов заранее выполняется предзагрузка, и только затем происходит ожидание данных. Это дает значительный прирост производительности по сравнению с синхронным ожиданием для каждого столбца. В большинстве случаев менять эту настройку не потребуется — см. оптимизацию производительности. - Запись выполняется параллельно, максимум в 100 одновременно работающих потоков записи файлов.
max_insert_delayed_streams_for_parallel_write, который по умолчанию имеет значение 1000, управляет количеством объектов S3, записываемых параллельно. Поскольку для каждого записываемого файла требуется буфер (~1MB), это фактически ограничивает потребление памяти для INSERT. В условиях ограниченной памяти сервера может быть целесообразно уменьшить это значение.
Используйте объектное хранилище S3 как диск ClickHouse
Настройте ClickHouse для использования S3 бакета в качестве диска
- Создайте новый файл в каталоге ClickHouse
config.dдля хранения конфигурации хранилища.
- Добавьте следующую конфигурацию хранилища, подставив путь к бакету, ключ доступа и секретные ключи из предыдущих шагов
Теги
s3_disk и s3_cache внутри тега <disks> — это произвольные метки. Их можно задать иначе, но для ссылки на диск в теге <disk> внутри тега <policies> нужно использовать ту же метку.
Тег <S3_main> также является произвольным и представляет собой имя политики, которое будет использоваться как идентификатор целевого хранилища при создании ресурсов в ClickHouse.Показанная выше конфигурация предназначена для ClickHouse версии 22.8 и выше. Если вы используете более раннюю версию, см. документацию хранение данных.Дополнительные сведения об использовании S3 см. здесь:
Руководство по интеграции: S3 Backed MergeTree- Измените владельца файла на пользователя и группу
clickhouse
- Перезапустите экземпляр ClickHouse, чтобы изменения вступили в силу.
Тестирование
- Войдите в клиент ClickHouse, например так:
- Создайте таблицу, указав новую политику хранения для хранилища S3
- Убедитесь, что table была создана с правильной политикой
- Вставьте тестовые строки в таблицу
- Просмотрите строки
- В консоли AWS перейдите в раздел бакетов, затем выберите новый бакет и папку. Вы должны увидеть примерно следующее:
Репликация одного сегмента в двух регионах AWS с использованием объектного хранилища S3
Спланируйте развертывание
Установка ПО
Узлы сервер ClickHouse
Развертывание ClickHouse
chnode1 и chnode2.
Разместите chnode1 в одном регионе AWS, а chnode2 — в другом.
Развертывание ClickHouse Keeper
keepernode1, keepernode2 и keepernode3. keepernode1 можно развернуть в том же регионе, что и chnode1, keepernode2 — вместе с chnode2, а keepernode3 — в любом из регионов, но в другой зоне доступности, чем узел ClickHouse в этом регионе.
При выполнении шагов развертывания на узлах ClickHouse Keeper см. инструкции по установке.
Создайте S3 бакеты
chnode1 и chnode2.
Если вам нужны пошаговые инструкции по созданию бакетов и роли IAM, разверните Создание S3 бакетов и роли IAM и следуйте им:
Создайте S3 бакеты и IAM-пользователя
Создайте S3 бакеты и IAM-пользователя
В этой статье описываются основы настройки пользователя AWS IAM, создания S3 бакета и настройки ClickHouse для использования бакета в качестве S3-диска.
Рекомендуется согласовать с командой безопасности необходимые разрешения, рассматривая приведённые настройки как отправную точку.



Создание пользователя AWS IAM
В следующих шагах вы создадите пользователя сервисного аккаунта (не пользователя для авторизации).- Войдите в консоль управления AWS IAM.
-
В меню
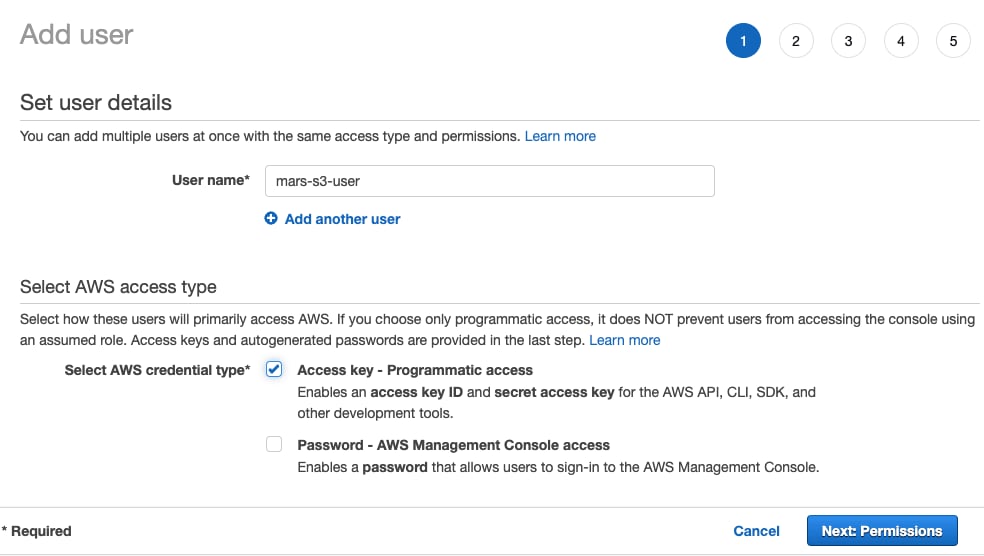
UsersвыберитеCreate user
- Введите имя пользователя, выберите тип учетных данных
Access key - Programmatic accessи нажмитеNext: Permissions
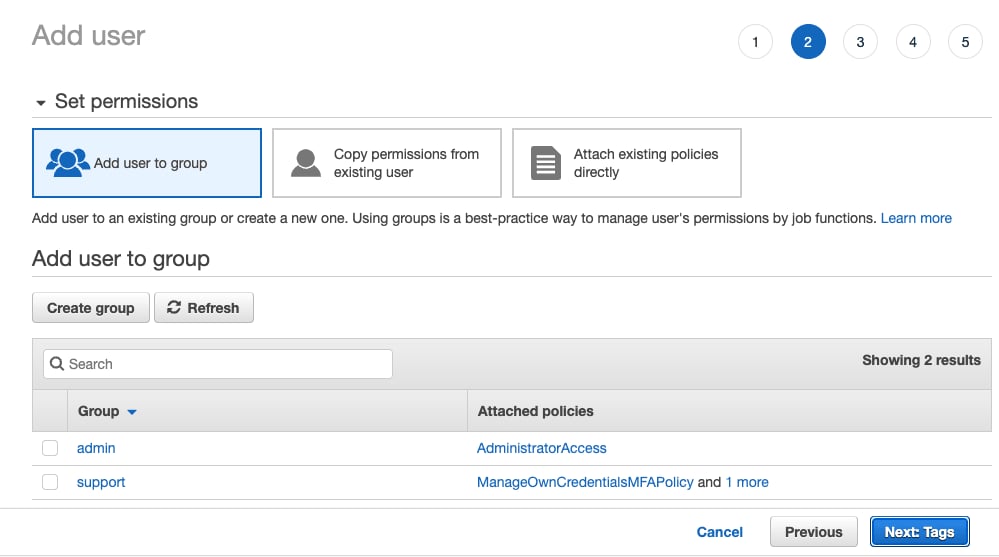
- Не добавляйте пользователя ни в одну группу; нажмите
Next: Tags
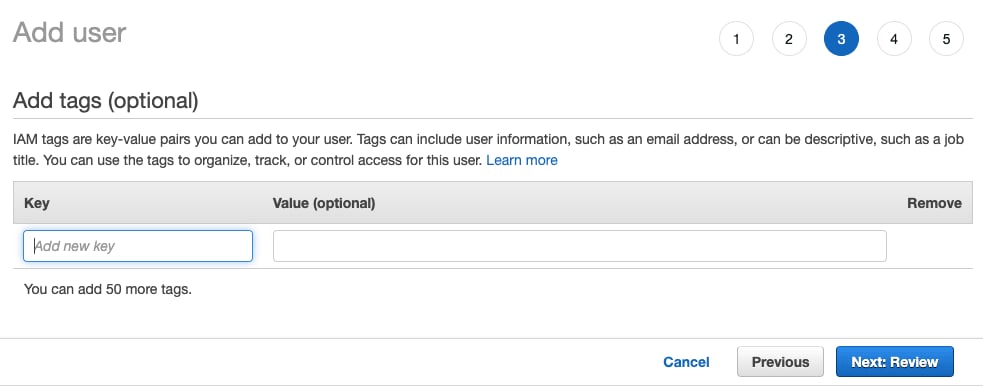
- Если вам не нужно добавлять теги, выберите
Next: Review
- Выберите
Create User
Предупреждение о том, что у пользователя нет разрешений, можно проигнорировать; в следующем разделе пользователю будут выданы разрешения на бакет
- Пользователь создан; нажмите
showи скопируйте ключ доступа и секретный ключ.
Сохраните ключи в другом месте; секретный ключ доступа можно будет увидеть только сейчас.
- Нажмите Close, затем найдите пользователя на странице пользователей.
- Скопируйте ARN (Amazon Resource Name) и сохраните его — он понадобится при настройке политики доступа к бакету.
Создайте S3 бакет
- В разделе S3 бакета выберите
Create bucket
- Введите имя бакета, остальные параметры оставьте по умолчанию
Имя бакета должно быть уникальным во всём AWS, а не только в пределах организации, иначе возникнет ошибка.
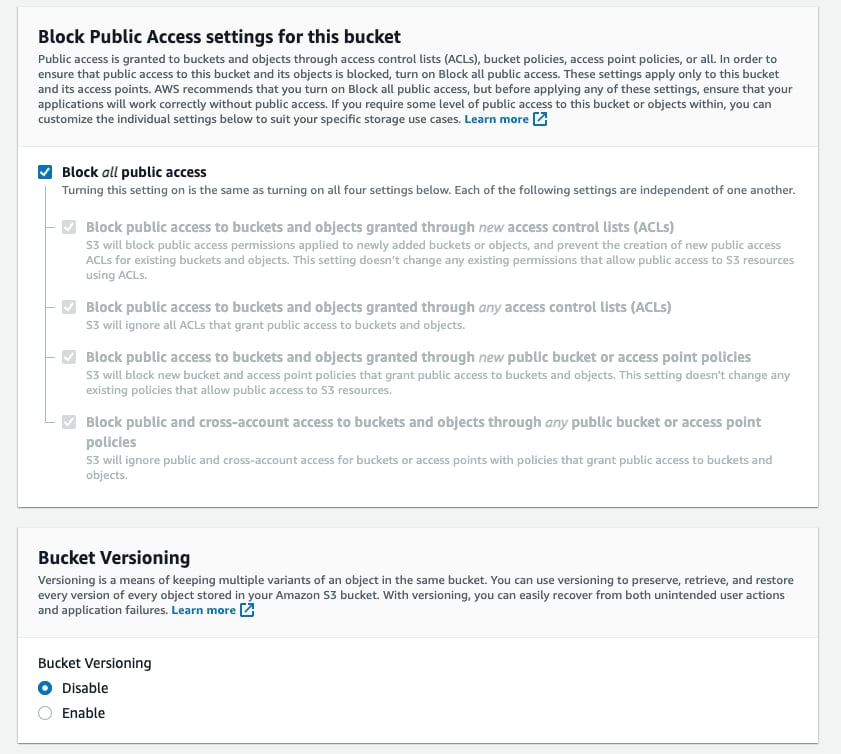
- Оставьте
Block all Public Accessвключенным; публичный доступ не нужен.
- Выберите
Create Bucketв нижней части страницы
- Выберите ссылку, скопируйте ARN и сохраните его, чтобы использовать при настройке политики доступа к бакету.
- После создания бакета найдите новый S3 бакет в списке S3 бакетов и выберите ссылку
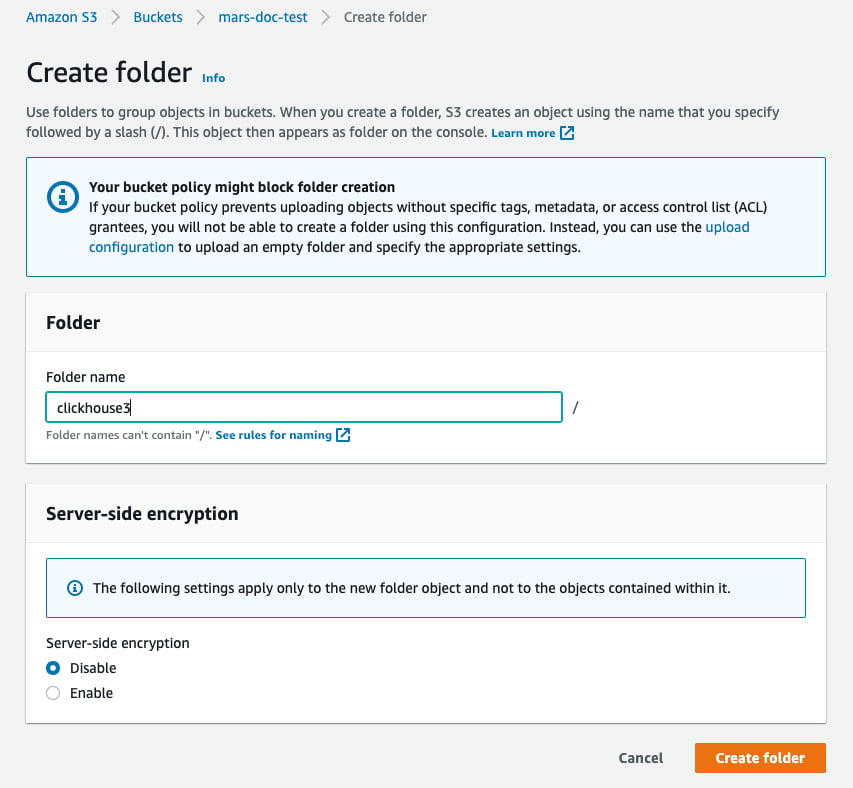
- Выберите
Create folder
- Введите имя папки, которая будет использоваться как целевая для S3-диска ClickHouse, и выберите
Create folder
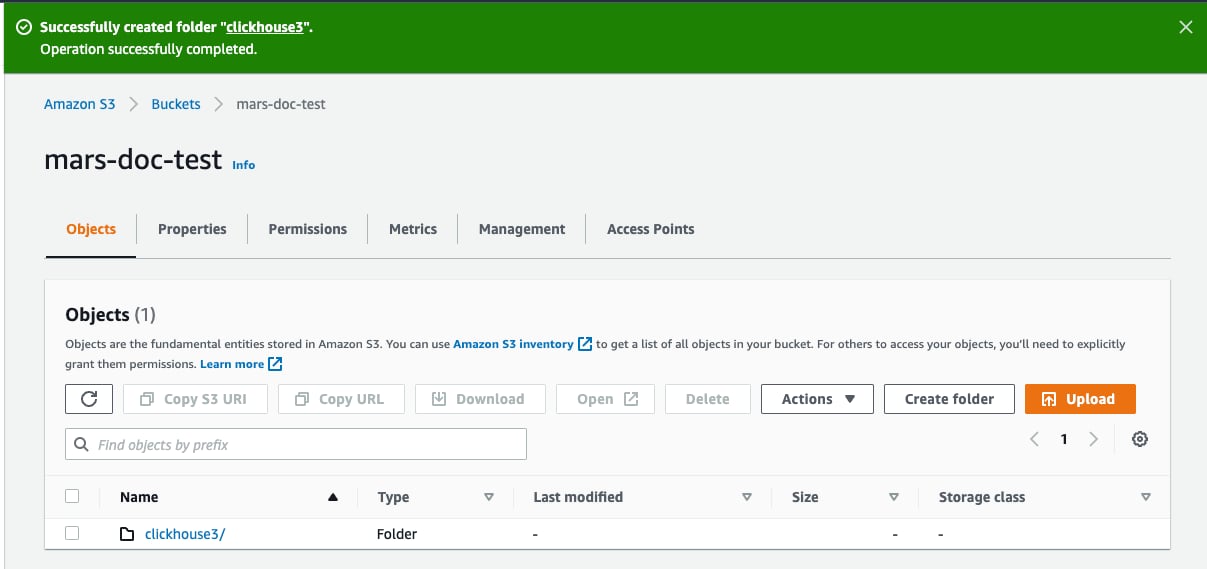
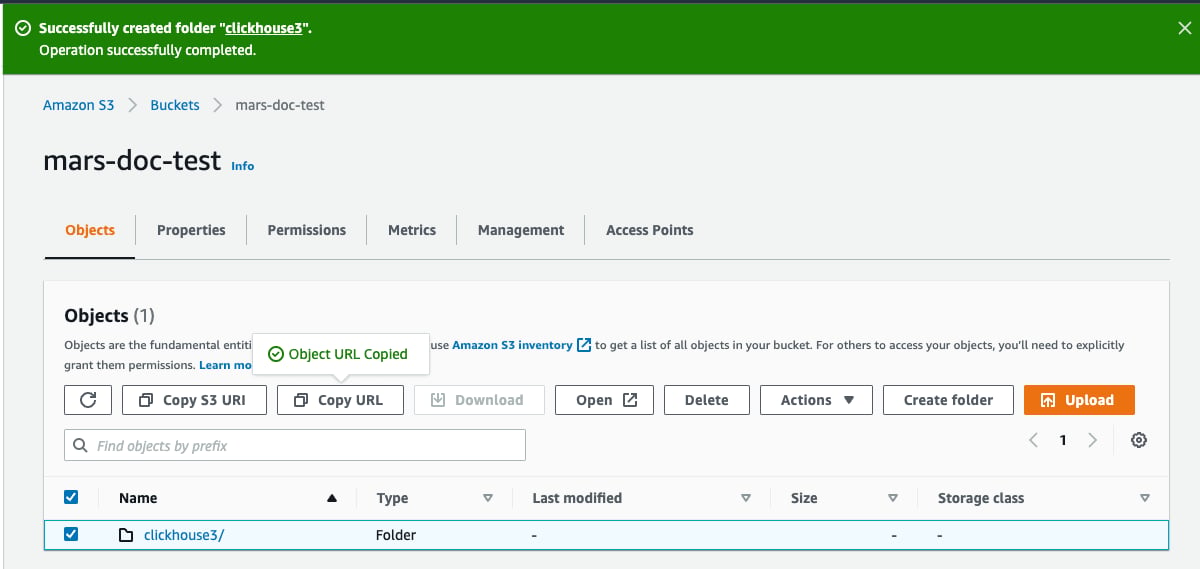
- Теперь папка должна отображаться в списке бакетов
- Установите флажок рядом с новой папкой и нажмите
Copy URL. Сохраните скопированный URL, чтобы использовать его в конфигурации хранилища ClickHouse в следующем разделе.
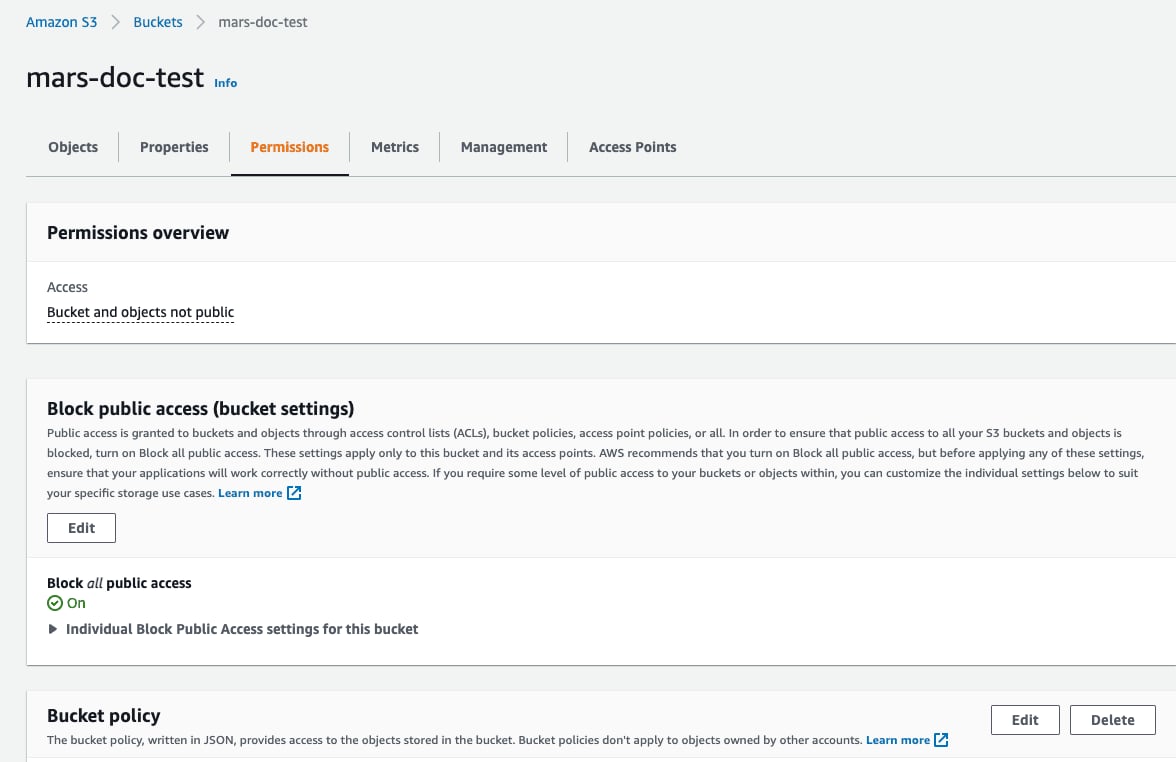
- Выберите вкладку
Permissionsи нажмите кнопкуEditв разделеBucket Policy
- Добавьте политику для бакета, пример ниже:
Вместе с вашей командой по безопасности определите, какие разрешения следует использовать; приведённые ниже можно рассматривать как отправную точку.
Дополнительную информацию о политиках и настройках см. в документации AWS:
https://docs.aws.amazon.com/AmazonS3/latest/userguide/access-policy-language-overview.html
- Сохраните настройки политики.
/etc/clickhouse-server/config.d/. Вот пример файла конфигурации для одного бакета; для другого он будет аналогичным, за исключением трех выделенных строк:
/etc/clickhouse-server/config.d/storage_config.xml
На многих этапах этого руководства вам будет предложено поместить файл конфигурации в
/etc/clickhouse-server/config.d/. Это стандартное расположение в системах Linux для файлов переопределения конфигурации. Когда вы поместите эти файлы в этот каталог, ClickHouse будет использовать их содержимое для переопределения конфигурации по умолчанию. Размещая эти файлы в каталоге переопределения, вы избежите потери своей конфигурации при обновлении.Настройка ClickHouse Keeper
/etc/clickhouse-keeper/keeper_config.xml. Все три сервера Keeper используют одну и ту же конфигурацию, за исключением одного параметра — <server_id>.
server_id указывает идентификатор, назначаемый хосту, на котором используется файл конфигурации. В примере ниже значение server_id равно 3, и, если вы посмотрите ниже по файлу, в разделе <raft_configuration>, то увидите, что у сервера 3 имя хоста keepernode3. Именно так процесс ClickHouse Keeper определяет, к каким другим серверам нужно подключаться при выборе лидера и выполнении всех остальных операций.
/etc/clickhouse-keeper/keeper_config.xml
<server_id>):
Настройка сервера ClickHouse
Определение кластера
<remote_servers>. В этом примере задан один кластер — cluster_1S_2R; он состоит из одного сегмента с двумя репликами. Реплики размещены на хостах chnode1 и chnode2.
/etc/clickhouse-server/config.d/remote-servers.xml
shard и replica. При создании таблицы вы можете увидеть, как используются макросы shard и replica, выполнив запрос к system.tables.
/etc/clickhouse-server/config.d/macros.xml
Указанные выше макросы предназначены для
chnode1; для chnode2 задайте replica как replica_2.Отключите репликацию zero-copy
allow_remote_fs_zero_copy_replication по умолчанию равно true для дисков S3 и HDFS. Для этого сценария аварийного восстановления эту настройку следует установить в false, а в версии 22.8 и выше её значение по умолчанию уже равно false.
Эта настройка должна иметь значение false по двум причинам: 1) эта возможность ещё не готова к промышленной эксплуатации; 2) в сценарии аварийного восстановления и данные, и метаданные должны храниться в нескольких регионах. Установите allow_remote_fs_zero_copy_replication в false.
/etc/clickhouse-server/config.d/remote-servers.xml
/etc/clickhouse-server/config.d/use_keeper.xml
Настройте сетевое взаимодействие
/etc/clickhouse-server/config.d/. Ниже приведен пример конфигурации, в котором ClickHouse и ClickHouse Keeper настроены на прослушивание на всех интерфейсах IPv4. Подробнее см. в документации или в файле конфигурации по умолчанию /etc/clickhouse/config.xml.
/etc/clickhouse-server/config.d/networking.xml
Запустите серверы
Запустите ClickHouse Keeper
Проверьте состояние ClickHouse Keeper
netcat. Например, mntr возвращает состояние кластера ClickHouse Keeper. Если выполнить эту команду на каждом из узлов Keeper, вы увидите, что один из них — leader, а два других — followers:
Запустите сервер ClickHouse
Проверьте сервер ClickHouse
-
Убедитесь, что кластер существует:
-
Создайте таблицу в кластере, используя движок таблицы
ReplicatedMergeTree: -
Разберитесь, как используются определённые ранее макросы
Макросы
shardиreplicaбыли определены ранее, и в выделенной строке ниже показано, где эти значения подставляются на каждом узле ClickHouse. Кроме того, используется значениеuuid;uuidне определён в макросах, так как генерируется системой.
Вы можете настроить путь ZooKeeper
'clickhouse/tables/{uuid}/{shard}, показанный выше, задав default_replica_path и default_replica_name. Документация находится здесь.Тестирование
-
Добавьте данные из датасета такси Нью-Йорка:
-
Убедитесь, что данные хранятся в S3.
Этот запрос показывает размер данных на диске и политику хранения, которая определяет, какой диск используется.
Проверьте размер данных на локальном диске. Как показано выше, размер хранимых миллионов строк на диске составляет 36.42 MiB. Эти данные должны находиться в S3, а не на локальном диске. Приведённый выше запрос также показывает, где на локальном диске хранятся данные и метаданные. Проверьте локальные данные:Проверьте данные в каждом S3 бакете (итоговые значения не показаны, но после вставки в обоих бакетах хранится примерно по 36 MiB):
S3Express
S3Express хранит данные в пределах одной AZ. Это означает, что в случае сбоя в AZ данные будут недоступны.
Диск S3
- Создайте бакет типа
Directory - Задайте подходящую политику бакета, чтобы предоставить пользователю S3 все необходимые разрешения (например,
"Action": "s3express:*"для полного неограниченного доступа) - При настройке политики хранения укажите параметр
region
Хранилище S3
Object URL. Пример: