Использование Vector с Kafka и ClickHouse
Использование Vector с Kafka и ClickHouse
Vector — это независимый от поставщиков конвейер обработки данных, который может читать из Kafka и отправлять события в ClickHouse.
Руководство по началу работы с Vector и ClickHouse сфокусировано на сценарии с логами и чтении событий из файла. Мы используем пример набора данных GitHub с событиями, размещёнными в топике Kafka.
Vector использует sources для получения данных по push- или pull-модели. Sinks, в свою очередь, являются приёмниками событий. Поэтому мы используем источник Kafka и приёмник ClickHouse. Обратите внимание, что хотя Kafka поддерживается как Sink, источник ClickHouse недоступен. В результате Vector не подходит пользователям, желающим передавать данные из ClickHouse в Kafka.
Vector также поддерживает transformation данных. Это выходит за рамки данного руководства. При необходимости применения трансформаций к своему набору данных пользователю следует обратиться к документации Vector.
Обратите внимание, что текущая реализация приёмника ClickHouse использует HTTP-интерфейс. Приёмник ClickHouse в данный момент не поддерживает использование JSON-схемы. Данные должны публиковаться в Kafka либо в виде обычного JSON-формата, либо в виде строк (Strings).
Лицензия
Vector распространяется по лицензии MPL-2.0
Сбор параметров подключения
Чтобы подключиться к ClickHouse по HTTP(S) вам потребуется следующая информация:
| Параметр(ы) | Описание |
|---|---|
HOST and PORT | Typically, the port is 8443 when using TLS or 8123 when not using TLS. |
DATABASE NAME | Out of the box, there is a database named default, use the name of the database that you want to connect to. |
USERNAME and PASSWORD | Out of the box, the username is default. Use the username appropriate for your use case. |
The details for your ClickHouse Cloud service are available in the ClickHouse Cloud console. Select a service and click Connect:
Choose HTTPS. Connection details are displayed in an example curl command.
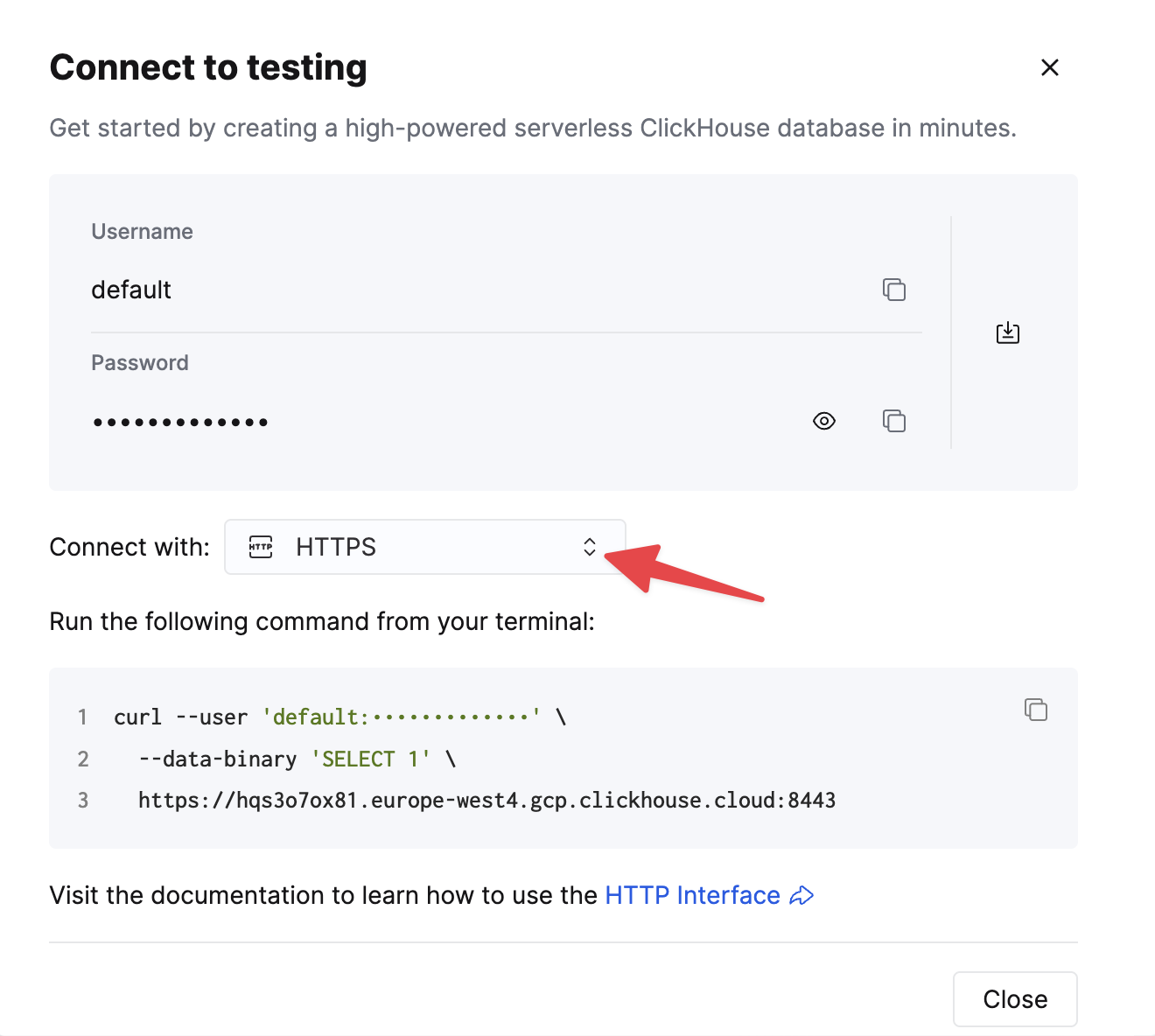
If you're using self-managed ClickHouse, the connection details are set by your ClickHouse administrator.
Шаги
- Создайте топик Kafka
githubи загрузите в него набор данных GitHub.
Этот набор данных состоит из 200 000 строк, относящихся к репозиторию ClickHouse/ClickHouse.
- Убедитесь, что целевая таблица создана. Ниже мы используем базу данных по умолчанию.
- Скачайте и установите Vector. Создайте конфигурационный файл
kafka.tomlи измените значения для экземпляров Kafka и ClickHouse.
Несколько важных замечаний относительно этой конфигурации и поведения Vector:
- Этот пример был протестирован с Confluent Cloud. Поэтому параметры безопасности
sasl.*иssl.enabledмогут быть неприменимы в сценариях с самостоятельным управлением кластером. - Префикс протокола не требуется для параметра конфигурации
bootstrap_servers, например:pkc-2396y.us-east-1.aws.confluent.cloud:9092. - Параметр источника
decoding.codec = "json"гарантирует, что сообщение передается в ClickHouse sink как один JSON-объект. При обработке сообщений как строк (String) и использовании значения по умолчаниюbytesсодержимое сообщения будет добавлено в полеmessage. В большинстве случаев это потребует обработки в ClickHouse, как описано в руководстве Vector getting started. - Vector добавляет ряд полей к сообщениям. В нашем примере мы игнорируем эти поля в ClickHouse sink с помощью параметра конфигурации
skip_unknown_fields = true. Это приводит к игнорированию полей, которые не являются частью схемы целевой таблицы. При необходимости скорректируйте схему, чтобы такие мета-поля, какoffset, также добавлялись. - Обратите внимание, как sink ссылается на источник событий через параметр
inputs. - Обратите внимание на поведение ClickHouse sink, описанное здесь. Для оптимальной пропускной способности вы можете настроить параметры
buffer.max_events,batch.timeout_secsиbatch.max_bytes. Согласно рекомендациям ClickHouse, значение 1000 следует рассматривать как минимальное количество событий в одном пакете. Для сценариев с равномерно высокой пропускной способностью вы можете увеличить параметрbuffer.max_events. При более переменной нагрузке могут потребоваться изменения параметраbatch.timeout_secs. - Параметр
auto_offset_reset = "smallest"заставляет источник Kafka начинать чтение с начала топика, гарантируя, что мы потребляем сообщения, опубликованные на шаге (1). Вам может потребоваться иное поведение. См. подробности здесь.
- Запустите Vector
По умолчанию перед началом вставки данных в ClickHouse требуется проверка работоспособности. Это гарантирует, что можно установить соединение и прочитать схему. Добавьте перед командой VECTOR_LOG=debug, чтобы получить более подробные логи, которые могут быть полезны при возникновении проблем.
- Подтвердите вставку данных.
| Количество |
|---|
| 200000 |
