Использование движка таблицы Kafka
Движок таблицы Kafka можно использовать для чтения данных из и записи данных в Apache Kafka и других брокеров, совместимых с Kafka API (например, Redpanda, Amazon MSK).
Kafka → ClickHouse
Если вы используете ClickHouse Cloud, мы рекомендуем вместо этого использовать ClickPipes. ClickPipes нативно поддерживает приватные сетевые подключения, независимое масштабирование ресурсов приёма и кластера, а также всесторонний мониторинг для потоковой передачи данных Kafka в ClickHouse.
Чтобы использовать движок таблиц Kafka, вам следует в общих чертах быть знакомыми с материализованными представлениями ClickHouse.
Обзор
Сначала мы сосредоточимся на самом распространённом варианте использования: применении движка таблиц Kafka для вставки данных в ClickHouse из Kafka.
Движок таблиц Kafka позволяет ClickHouse читать данные напрямую из топика Kafka. Хотя это удобно для просмотра сообщений в топике, по своему устройству движок допускает только однократное извлечение данных, то есть при выполнении запроса к таблице он потребляет данные из очереди и увеличивает смещение (offset) потребителя, прежде чем вернуть результаты вызывающей стороне. По сути, повторно прочитать данные нельзя без сброса этих смещений.
Чтобы сохранить эти данные, прочитанные через движок таблиц, нам нужен способ захвата данных и вставки их в другую таблицу. Материализованные представления на основе триггеров нативно предоставляют такую функциональность. Материализованное представление инициирует чтение из движка таблиц, получая батчи документов. Оператор TO определяет место назначения данных — обычно это таблица из семейства MergeTree. Эта схема показана ниже:
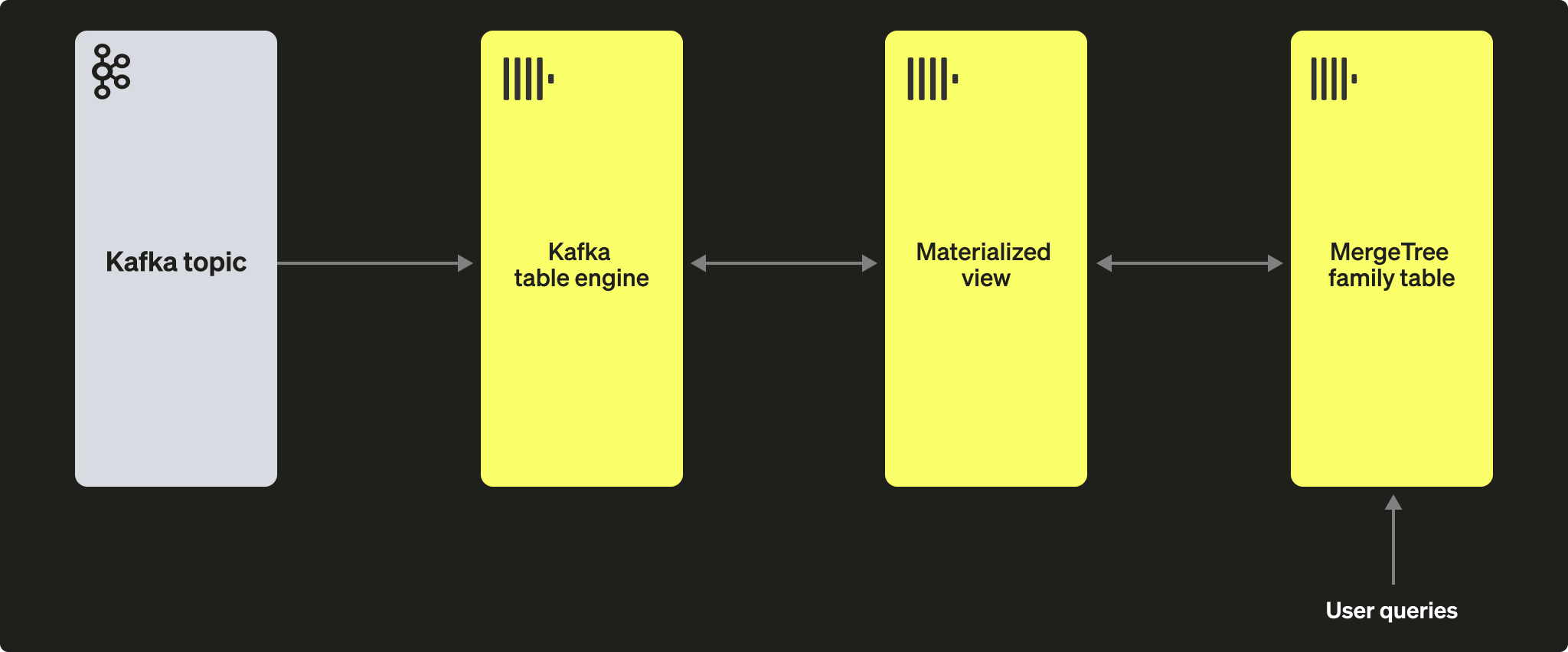
Шаги
1. Подготовка
Если у вас уже есть данные в целевом топике, вы можете адаптировать приведённое ниже под свой набор данных. В качестве альтернативы доступен пример набора данных GitHub здесь. Этот набор данных используется в примерах ниже и основан на урезанной схеме и подмножестве строк (в частности, мы ограничиваемся событиями GitHub, относящимися к репозиторию ClickHouse), по сравнению с полным набором данных, доступным здесь, для краткости. Этого по-прежнему достаточно, чтобы большинство запросов, опубликованных вместе с набором данных, работали.
2. Настройка ClickHouse
Этот шаг требуется, если вы подключаетесь к защищённому Kafka. Эти настройки нельзя передать через SQL DDL-команды, их необходимо задать в файле ClickHouse config.xml. Мы предполагаем, что вы подключаетесь к экземпляру, защищённому с помощью SASL. Это самый простой способ при работе с Confluent Cloud.
Либо поместите приведённый выше фрагмент в новый файл в каталоге conf.d/, либо объедините его с существующими файлами конфигурации. Настраиваемые параметры описаны здесь.
Мы также создадим базу данных под названием KafkaEngine, которую будем использовать в этом руководстве:
После создания базы данных переключитесь на неё:
3. Создание целевой таблицы
Подготовьте целевую таблицу. В приведённом ниже примере для краткости используется сокращённая схема GitHub. Обратите внимание, что хотя в примере используется таблица с движком MergeTree, этот пример можно легко адаптировать для любого представителя семейства MergeTree.
4. Создание и наполнение топика
Теперь создадим топик. Для этого можно использовать несколько инструментов. Если Kafka запущена локально на нашей машине или внутри Docker-контейнера, RPK отлично подходит. Мы можем создать топик с именем github и 5 партициями, выполнив следующую команду:
Если мы запускаем Kafka в Confluent Cloud, мы, вероятно, предпочтём использовать Confluent CLI:
Теперь нам нужно заполнить этот топик некоторыми данными, и для этого мы воспользуемся kcat. Если Kafka запущена локально с отключённой аутентификацией, можно выполнить следующую команду:
Или следующее, если в нашем кластере Kafka используется SASL для аутентификации:
Набор данных содержит 200 000 строк, поэтому его приём займёт всего несколько секунд. Если вы хотите работать с более крупным набором данных, ознакомьтесь с разделом о больших наборах данных репозитория GitHub ClickHouse/kafka-samples.
5. Создание таблицы с движком Kafka
Пример ниже создаёт таблицу с движком Kafka с той же схемой, что и у таблицы на движке MergeTree. Это не является строго обязательным, так как вы можете использовать алиасы или временные столбцы в целевой таблице. Однако настройки имеют важное значение — обратите внимание на использование JSONEachRow как типа данных для чтения JSON из топика Kafka. Значения github и clickhouse представляют собой имя топика и имя группы потребителей соответственно. На самом деле список топиков может содержать несколько значений.
Ниже мы рассмотрим настройки движка и оптимизацию производительности. На этом этапе простой запрос SELECT к таблице github_queue должен прочитать несколько строк. Обратите внимание, что это сдвинет вперёд смещения консьюмера, не позволяя прочитать эти строки повторно без сброса. Также обратите внимание на LIMIT и обязательный параметр stream_like_engine_allow_direct_select.
6. Создайте материализованное представление
Материализованное представление свяжет две ранее созданные таблицы, считывая данные из таблицы с движком Kafka и вставляя их в целевую таблицу MergeTree. Мы можем выполнять различные преобразования данных. В данном случае мы выполним простое чтение и вставку. Использование * предполагает, что имена столбцов идентичны (с учётом регистра).
В момент создания materialized view подключается к движку Kafka и начинает чтение — вставляет строки в целевую таблицу. Этот процесс будет продолжаться непрерывно, по мере того как новые сообщения вставляются в Kafka и потребляются. При необходимости вы можете повторно запустить скрипт вставки данных, чтобы добавить дополнительные сообщения в Kafka.
7. Проверьте, что строки были вставлены
Убедитесь, что данные присутствуют в целевой таблице:
Должно отобразиться 200 000 строк:
Общие операции
Остановка и перезапуск потребления сообщений
Чтобы остановить потребление сообщений, вы можете отсоединить таблицу с движком Kafka:
Это не повлияет на смещения группы потребителей. Чтобы возобновить чтение и продолжить с предыдущего смещения, снова подключите таблицу.
Добавление метаданных Kafka
Полезно сохранять метаданные исходных сообщений Kafka после их приёма в ClickHouse. Например, может потребоваться знать, какой объём данных из конкретного топика или партиции уже был потреблён. Для этого движок таблицы Kafka предоставляет несколько виртуальных столбцов. Эти столбцы можно сделать постоянными в целевой таблице, изменив схему и оператор SELECT в нашем материализованном представлении.
Сначала мы выполняем описанную выше операцию остановки, прежде чем добавлять столбцы в целевую таблицу.
Ниже мы добавляем дополнительные столбцы, чтобы идентифицировать исходный топик и партицию, из которой была прочитана строка.
Далее нам нужно убедиться, что виртуальные столбцы сопоставлены требуемым образом.
Виртуальные столбцы имеют префикс _.
Полный список виртуальных столбцов можно найти здесь.
Чтобы обновить нашу таблицу с виртуальными столбцами, нам нужно удалить материализованное представление, повторно прикрепить таблицу с движком Kafka и заново создать материализованное представление.
Вновь считываемые строки будут содержать эти метаданные.
Результат будет выглядеть так:
| actor_login | event_type | created_at | topic | partition |
|---|---|---|---|---|
| IgorMinar | CommitCommentEvent | 2011-02-12 02:22:00 | github | 0 |
| queeup | CommitCommentEvent | 2011-02-12 02:23:23 | github | 0 |
| IgorMinar | CommitCommentEvent | 2011-02-12 02:23:24 | github | 0 |
| IgorMinar | CommitCommentEvent | 2011-02-12 02:24:50 | github | 0 |
| IgorMinar | CommitCommentEvent | 2011-02-12 02:25:20 | github | 0 |
| dapi | CommitCommentEvent | 2011-02-12 06:18:36 | github | 0 |
| sourcerebels | CommitCommentEvent | 2011-02-12 06:34:10 | github | 0 |
| jamierumbelow | CommitCommentEvent | 2011-02-12 12:21:40 | github | 0 |
| jpn | CommitCommentEvent | 2011-02-12 12:24:31 | github | 0 |
| Oxonium | CommitCommentEvent | 2011-02-12 12:31:28 | github | 0 |
Изменение настроек движка Kafka
Рекомендуем удалить таблицу с движком Kafka и создать её заново с новыми настройками. Материализованное представление изменять не требуется — потребление сообщений возобновится после повторного создания таблицы с движком Kafka.
Диагностика проблем
Ошибки, такие как проблемы с аутентификацией, не возвращаются в ответах на DDL‑запросы движка Kafka. Для диагностики проблем рекомендуется использовать основной лог-файл ClickHouse clickhouse-server.err.log. Более детализированное трассирование для используемой клиентской библиотеки Kafka librdkafka можно включить в конфигурации.
Обработка некорректных сообщений
Kafka часто используется как «свалка» для данных. Это приводит к тому, что топики содержат смешанные форматы сообщений и несогласованные имена полей. Избегайте этого и используйте возможности Kafka, такие как Kafka Streams или ksqlDB, чтобы гарантировать, что сообщения имеют корректный формат и согласованы до вставки в Kafka. Если эти варианты недоступны, в ClickHouse есть несколько функций, которые могут помочь.
- Обрабатывайте поле сообщения как строку. В выражении материализованного представления можно использовать функции для очистки и приведения типов по мере необходимости. Это не должно рассматриваться как промышленное решение, но может помочь при разовой ингестии.
- Если вы читаете JSON из топика, используя формат JSONEachRow, используйте настройку
input_format_skip_unknown_fields. При записи данных по умолчанию ClickHouse генерирует исключение, если входные данные содержат столбцы, которых нет в целевой таблице. Однако если эта опция включена, эти лишние столбцы будут игнорироваться. Опять же, это не решение производственного уровня и может ввести других в заблуждение. - Рассмотрите настройку
kafka_skip_broken_messages. Она требует от пользователя указать допустимый порог на блок для некорректных сообщений — с учётомkafka_max_block_size. Если этот порог превышен (измеряется в абсолютном количестве сообщений), стандартное поведение с генерацией исключения будет восстановлено, а остальные сообщения будут пропущены.
Семантика доставки и проблемы с дубликатами
Движок таблиц Kafka предоставляет семантику как минимум однократной доставки (at-least-once). Дубликаты возможны в нескольких известных редких случаях. Например, сообщения могут быть прочитаны из Kafka и успешно вставлены в ClickHouse. До того как новый offset будет зафиксирован, соединение с Kafka теряется. В этой ситуации требуется повторная попытка вставки блока. Блок может быть дедуплицирован с использованием распределённой таблицы или ReplicatedMergeTree в качестве целевой таблицы. Хотя это снижает вероятность появления строк-дубликатов, оно полагается на идентичность блоков. События, такие как ребалансировка Kafka, могут нарушить это предположение, вызывая дубликаты в редких случаях.
Вставки на основе кворума
Вам могут потребоваться вставки на основе кворума для случаев, когда в ClickHouse требуются более строгие гарантии доставки. Это нельзя настроить на материализованном представлении или целевой таблице. Однако это можно задать для пользовательских профилей, например:
ClickHouse в Kafka
Хотя это менее распространённый сценарий, данные ClickHouse также могут сохраняться в Kafka. Например, мы вручную вставим строки в таблицу с движком Kafka. Эти данные будут прочитаны тем же движком Kafka, материализованное представление которого поместит данные в таблицу MergeTree. Наконец, мы продемонстрируем применение материализованных представлений при вставках в Kafka для чтения данных из уже существующих исходных таблиц.
Шаги
Нашу изначальную задачу лучше всего иллюстрирует следующая схема:
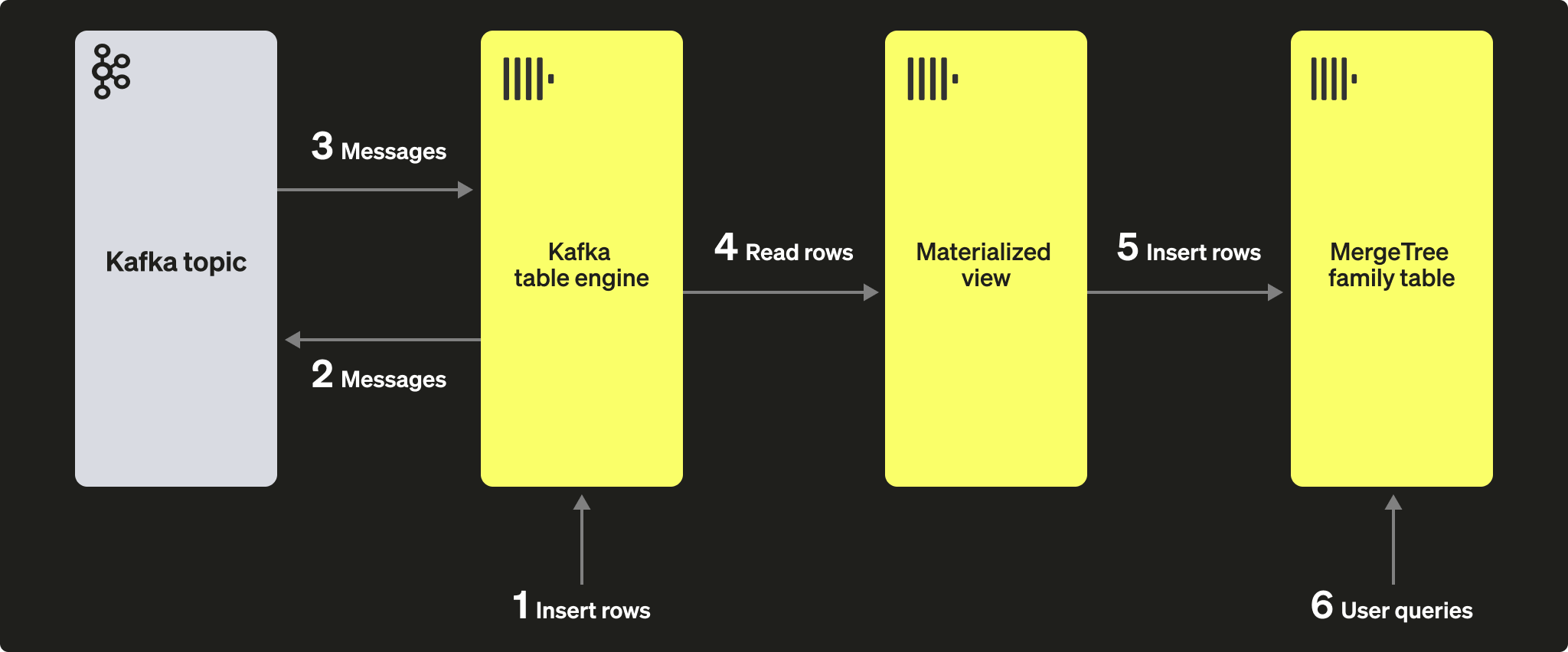
Мы предполагаем, что вы уже создали таблицы и представления на шагах для Kafka to ClickHouse и что топик был полностью обработан.
1. Прямая вставка строк
Сначала проверьте количество строк в целевой таблице.
У вас должно быть 200 000 строк:
Теперь вставьте строки из целевой таблицы GitHub обратно в таблицу движка Kafka github_queue. Обратите внимание, что мы используем формат JSONEachRow и ограничиваем запрос SELECT до 100 строк с помощью LIMIT.
Пересчитайте количество строк в GitHub, чтобы убедиться, что оно увеличилось на 100. Как показано на диаграмме выше, строки были записаны в Kafka с помощью движка таблицы Kafka, затем снова прочитаны этим же движком и вставлены в целевую таблицу GitHub нашим материализованным представлением!
Вы должны увидеть ещё 100 строк:
2. Использование материализованных представлений
Мы можем использовать материализованные представления, чтобы отправлять сообщения в движок Kafka (и в топик) при вставке документов в таблицу. Когда строки вставляются в таблицу GitHub, срабатывает материализованное представление, в результате чего эти строки снова вставляются в движок Kafka и в новый топик. Это, опять же, лучше всего иллюстрируется так:
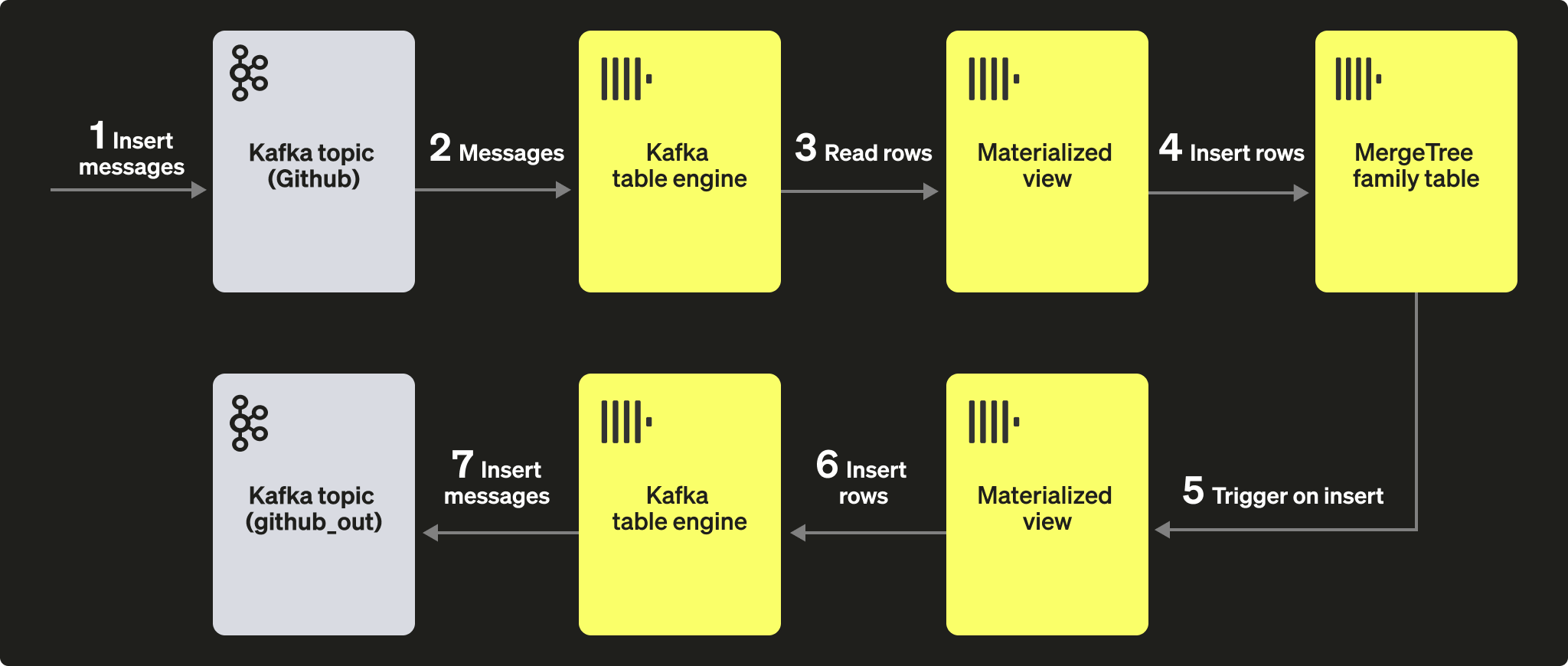
Создайте новый топик Kafka github_out или аналогичный. Убедитесь, что движок таблицы Kafka github_out_queue указывает на этот топик.
Теперь создайте новое материализованное представление github_out_mv, ссылающееся на таблицу GitHub и при срабатывании вставляющее строки в указанный выше движок. В результате новые записи в таблице GitHub будут отправляться в наш новый топик Kafka.
Если вы будете вставлять данные в исходный топик GitHub, созданный как часть раздела Kafka to ClickHouse, сообщения «магическим образом» появятся в топике "github_clickhouse". Подтвердите это с помощью штатных средств Kafka. Например, далее мы вставляем 100 строк в топик GitHub с помощью kcat для топика, размещённого в Confluent Cloud:
Чтение сообщений из топика github_out должно подтвердить их доставку.
Хотя это и сложный пример, он иллюстрирует мощь материализованных представлений при использовании вместе с табличным движком Kafka.
Кластеры и производительность
Работа с кластерами ClickHouse
Через группы потребителей Kafka несколько экземпляров ClickHouse потенциально могут читать из одного и того же топика. Каждому потребителю будет назначен раздел топика в соответствии со схемой 1:1. При масштабировании чтения ClickHouse с использованием табличного движка Kafka учитывайте, что общее количество потребителей в кластере не может превышать количество разделов в топике. Поэтому заранее убедитесь, что разбиение на разделы корректно настроено для топика.
Несколько экземпляров ClickHouse могут быть сконфигурированы для чтения из топика, используя один и тот же идентификатор группы потребителей, задаваемый при создании таблицы с движком Kafka. Таким образом, каждый экземпляр будет читать из одного или нескольких разделов, вставляя сегменты в свою локальную целевую таблицу. Целевые таблицы, в свою очередь, могут быть сконфигурированы на использование ReplicatedMergeTree для обработки дублирования данных. Такой подход позволяет масштабировать чтение из Kafka вместе с кластером ClickHouse при условии, что в Kafka достаточно разделов.
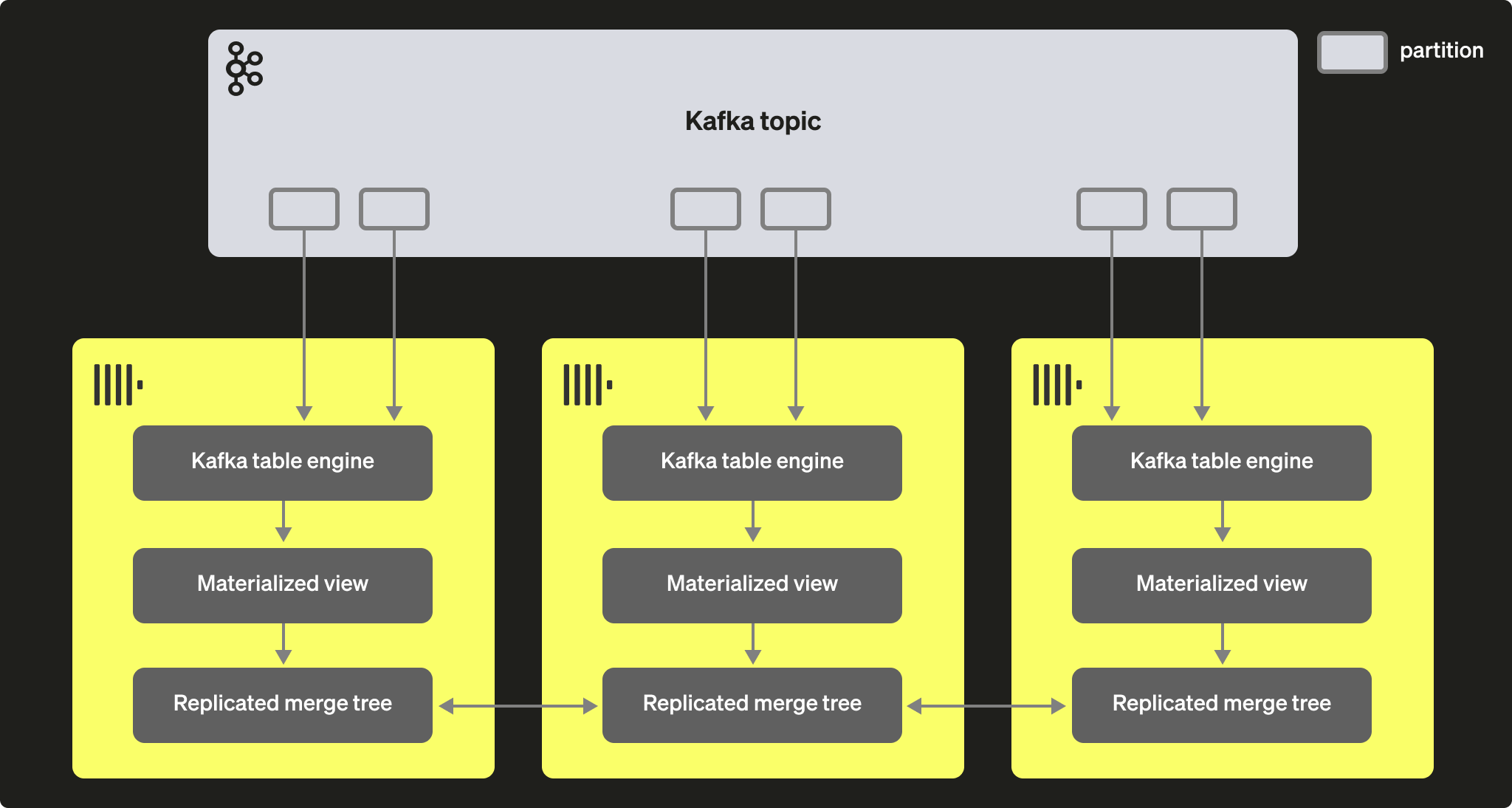
Настройка производительности
Учитывайте следующее при попытках увеличить пропускную способность таблицы с движком Kafka:
- Производительность будет варьироваться в зависимости от размера сообщений, их формата и типов целевых таблиц. Значение 100 тыс. строк/с для одного табличного движка можно считать достижимым. По умолчанию сообщения читаются блоками, что контролируется параметром kafka_max_block_size. По умолчанию он установлен в значение max_insert_block_size, равное 1 048 576. Если только сообщения не являются крайне крупными, этот параметр почти всегда следует увеличивать. Значения между 500 тыс. и 1 млн встречаются довольно часто. Тестируйте и оценивайте влияние на пропускную способность.
- Количество потребителей для табличного движка можно увеличить с помощью kafka_num_consumers. Однако по умолчанию вставки будут линеаризованы в одном потоке, если только kafka_thread_per_consumer не изменён со значения по умолчанию 1. Установите его в значение 1, чтобы гарантировать, что сбросы выполняются параллельно. Обратите внимание, что создание таблицы с движком Kafka с N потребителями (и kafka_thread_per_consumer=1) логически эквивалентно созданию N таблиц с движком Kafka, каждая с материализованным представлением и kafka_thread_per_consumer=0.
- Увеличение числа потребителей не является «бесплатной» операцией. Каждый потребитель поддерживает собственные буферы и потоки, увеличивая накладные расходы на сервер. Учитывайте эти накладные расходы и по возможности сначала масштабируйтесь линейно по кластеру.
- Если пропускная способность сообщений Kafka изменчива и задержки приемлемы, подумайте о повышении значения stream_flush_interval_ms, чтобы обеспечить сброс более крупных блоков.
- background_message_broker_schedule_pool_size задаёт количество потоков, выполняющих фоновые задачи. Эти потоки используются для стриминга из Kafka. Этот параметр применяется при запуске сервера ClickHouse и не может быть изменён в пользовательской сессии; по умолчанию он равен 16. Если вы видите тайм-ауты в логах, возможно, стоит увеличить его.
- Для взаимодействия с Kafka используется библиотека librdkafka, которая сама создаёт потоки. Большое количество таблиц Kafka или потребителей может, таким образом, приводить к большому числу переключений контекста. Либо распределите эту нагрузку по кластеру, по возможности реплицируя только целевые таблицы, либо рассмотрите использование одного табличного движка для чтения из нескольких топиков — поддерживается список значений. Несколько материализованных представлений могут читать из одной таблицы, каждое фильтруя данные для конкретного топика.
Любые изменения настроек необходимо тестировать. Мы рекомендуем мониторить лаги потребителей Kafka, чтобы убедиться, что масштабирование выполнено корректно.
Дополнительные настройки
Помимо настроек, обсуждённых выше, могут быть полезны следующие:
- Kafka_max_wait_ms — время ожидания в миллисекундах при чтении сообщений из Kafka перед повторной попыткой. Задаётся на уровне профиля пользователя; по умолчанию — 5000.
Все настройки из базовой библиотеки librdkafka также могут быть заданы в конфигурационных файлах ClickHouse внутри элемента kafka — имена настроек должны задаваться в виде XML-элементов, при этом точки в названиях заменяются символами подчёркивания, например:
Это экспертные настройки, и мы рекомендуем обратиться к документации Kafka за подробным объяснением.
