Шаблон Dataflow BigQuery to ClickHouse
Шаблон BigQuery to ClickHouse — это батч-конвейер, который выполняет приём данных из таблицы BigQuery в таблицу ClickHouse. Шаблон может считывать всю таблицу целиком или фильтровать отдельные записи с помощью указанного SQL-запроса.
Требования к конвейеру
- Исходная таблица BigQuery должна существовать.
- Целевая таблица ClickHouse должна существовать.
- Хост ClickHouse должен быть доступен с рабочих машин Dataflow.
Параметры шаблона
| Parameter Name | Parameter Description | Required | Notes |
|---|---|---|---|
jdbcUrl | JDBC-URL ClickHouse в формате jdbc:clickhouse://<host>:<port>/<schema>. | ✅ | Не добавляйте имя пользователя и пароль в виде JDBC-опций. Любую другую JDBC-опцию можно добавить в конец jdbcUrl. Для пользователей ClickHouse Cloud добавьте ssl=true&sslmode=NONE к jdbcUrl. |
clickHouseUsername | Имя пользователя ClickHouse для аутентификации. | ✅ | |
clickHousePassword | Пароль ClickHouse для аутентификации. | ✅ | |
clickHouseTable | Целевая таблица ClickHouse, в которую будут вставляться данные. | ✅ | |
maxInsertBlockSize | Максимальный размер блока для вставки, если мы управляем созданием блоков для вставки (опция ClickHouseIO). | Опция ClickHouseIO. | |
insertDistributedSync | Если настройка включена, запрос INSERT в распределённую таблицу ожидает, пока данные не будут отправлены на все узлы кластера (опция ClickHouseIO). | Опция ClickHouseIO. | |
insertQuorum | Для запросов INSERT в реплицируемую таблицу ожидает записи указанного числа реплик и линеаризует добавление данных. Значение 0 — отключено. | Опция ClickHouseIO. Эта настройка отключена в настройках сервера по умолчанию. | |
insertDeduplicate | Для запросов INSERT в реплицируемую таблицу указывает, что должна выполняться дедупликация вставляемых блоков. | Опция ClickHouseIO. | |
maxRetries | Максимальное количество повторных попыток для одной вставки. | Опция ClickHouseIO. | |
InputTableSpec | Таблица BigQuery, из которой будет выполняться чтение. Укажите либо inputTableSpec, либо query. Если заданы оба параметра, приоритет имеет параметр query. Пример: <BIGQUERY_PROJECT>:<DATASET_NAME>.<INPUT_TABLE>. | Считывает данные напрямую из хранилища BigQuery с использованием BigQuery Storage Read API. Обратите внимание на ограничения Storage Read API. | |
outputDeadletterTable | Таблица BigQuery для сообщений, которые не удалось записать в выходную таблицу. Если таблица не существует, она будет создана во время выполнения конвейера. Если параметр не указан, используется <outputTableSpec>_error_records. Например, <PROJECT_ID>:<DATASET_NAME>.<DEADLETTER_TABLE>. | ||
query | SQL-запрос, используемый для чтения данных из BigQuery. Если набор данных BigQuery находится в другом проекте, чем задание Dataflow, укажите полное имя набора данных в SQL-запросе, например: <PROJECT_ID>.<DATASET_NAME>.<TABLE_NAME>. По умолчанию используется GoogleSQL, если useLegacySql не имеет значения true. | Необходимо указать либо inputTableSpec, либо query. Если заданы оба параметра, шаблон использует параметр query. Пример: SELECT * FROM sampledb.sample_table. | |
useLegacySql | Установите значение true, чтобы использовать устаревший SQL. Этот параметр применяется только при использовании параметра query. По умолчанию имеет значение false. | ||
queryLocation | Требуется при чтении из авторизованного представления без прав на исходную таблицу. Например, US. | ||
queryTempDataset | Укажите существующий набор данных, в котором будет создана временная таблица для хранения результатов запроса. Например, temp_dataset. | ||
KMSEncryptionKey | При чтении из BigQuery с использованием источника-запроса используйте этот ключ Cloud KMS для шифрования всех создаваемых временных таблиц. Например, projects/your-project/locations/global/keyRings/your-keyring/cryptoKeys/your-key. |
Значения по умолчанию для всех параметров ClickHouseIO можно найти в ClickHouseIO Apache Beam Connector
Схема исходных и целевых таблиц
Чтобы эффективно загрузить набор данных BigQuery в ClickHouse, конвейер выполняет процесс вывода схемы столбцов, состоящий из следующих этапов:
- Шаблоны строят объект схемы на основе целевой таблицы ClickHouse.
- Шаблоны последовательно обходят набор данных BigQuery и пытаются сопоставить столбцы по их именам.
При этом ваш набор данных BigQuery (таблица или результат запроса) должен иметь точно такие же имена столбцов, как и целевая таблица ClickHouse.
Отображение типов данных
Типы BigQuery преобразуются на основе определения вашей таблицы ClickHouse. Поэтому в приведённой выше таблице перечислено рекомендуемое отображение, которое следует использовать в целевой таблице ClickHouse (для заданной таблицы/запроса BigQuery):
| Тип BigQuery | Тип ClickHouse | Примечания |
|---|---|---|
| Array Type | Array Type | Внутренний тип должен быть одним из поддерживаемых примитивных типов данных, перечисленных в этой таблице. |
| Boolean Type | Bool Type | |
| Date Type | Date Type | |
| Datetime Type | Datetime Type | Также работает с Enum8, Enum16 и FixedString. |
| String Type | String Type | В BigQuery все типы Int (INT, SMALLINT, INTEGER, BIGINT, TINYINT, BYTEINT) являются синонимами типа INT64. Рекомендуется задать в ClickHouse корректный размер целочисленного типа, так как шаблон будет преобразовывать столбец на основе заданного типа столбца (Int8, Int16, Int32, Int64). |
| Numeric - Integer Types | Integer Types | В BigQuery все типы Int (INT, SMALLINT, INTEGER, BIGINT, TINYINT, BYTEINT) являются синонимами типа INT64. Рекомендуется задать в ClickHouse корректный размер целочисленного типа, так как шаблон будет преобразовывать столбец на основе заданного типа столбца (Int8, Int16, Int32, Int64). Шаблон также будет преобразовывать беззнаковые целочисленные типы, если они используются в таблице ClickHouse (UInt8, UInt16, UInt32, UInt64). |
| Numeric - Float Types | Float Types | Поддерживаемые типы ClickHouse: Float32 и Float64. |
Запуск шаблона
Шаблон BigQuery to ClickHouse доступен для выполнения через Google Cloud CLI.
Обязательно изучите этот документ, особенно разделы выше, чтобы полностью понять требования к конфигурации и предварительные требования для использования шаблона.
- Google Cloud Console
- Google Cloud CLI
Войдите в Google Cloud Console и найдите службу Dataflow.
- Нажмите кнопку
CREATE JOB FROM TEMPLATE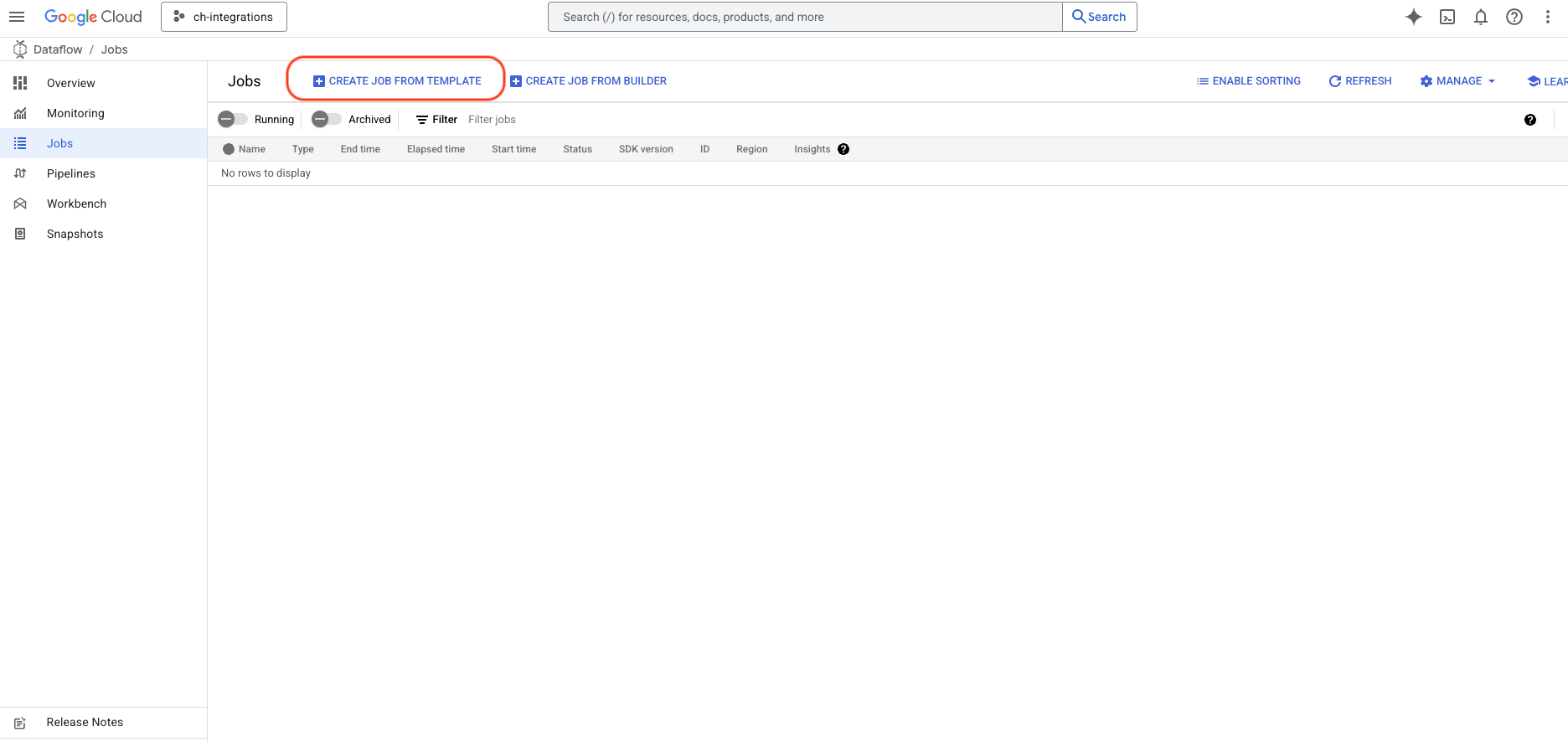
- После открытия формы шаблона введите имя задания и выберите нужный регион.
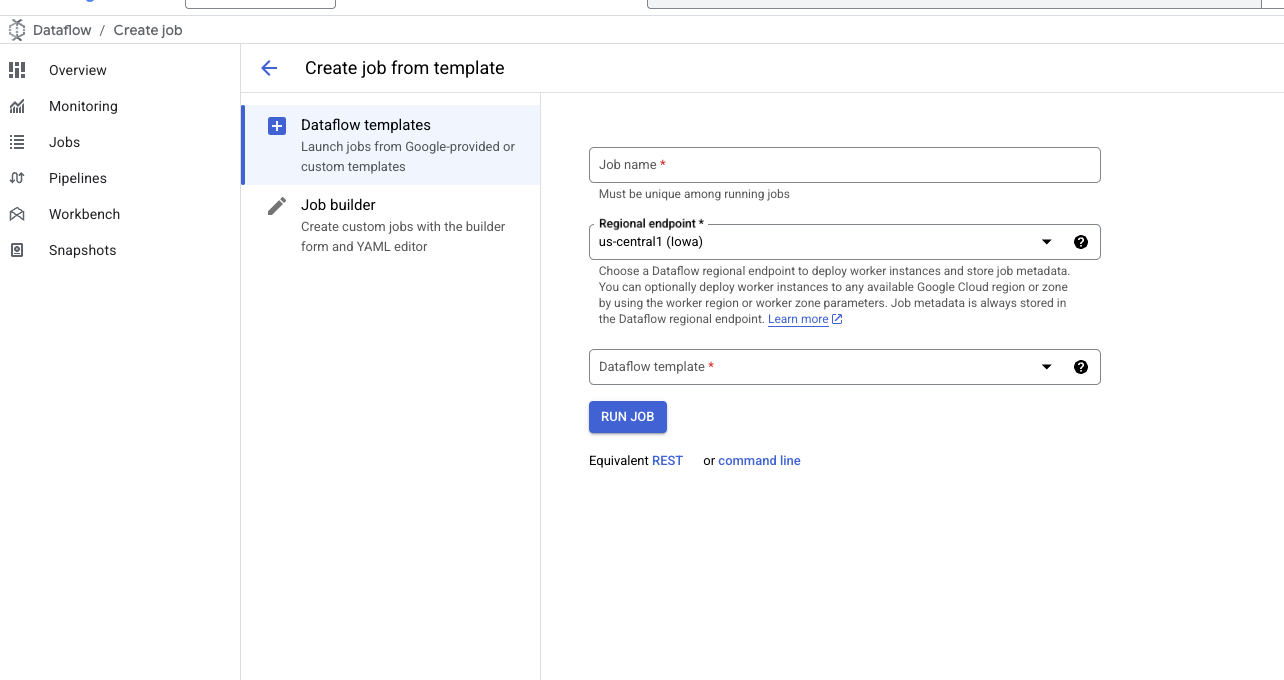
- В поле
DataFlow TemplateвведитеClickHouseилиBigQueryи выберите шаблонBigQuery to ClickHouse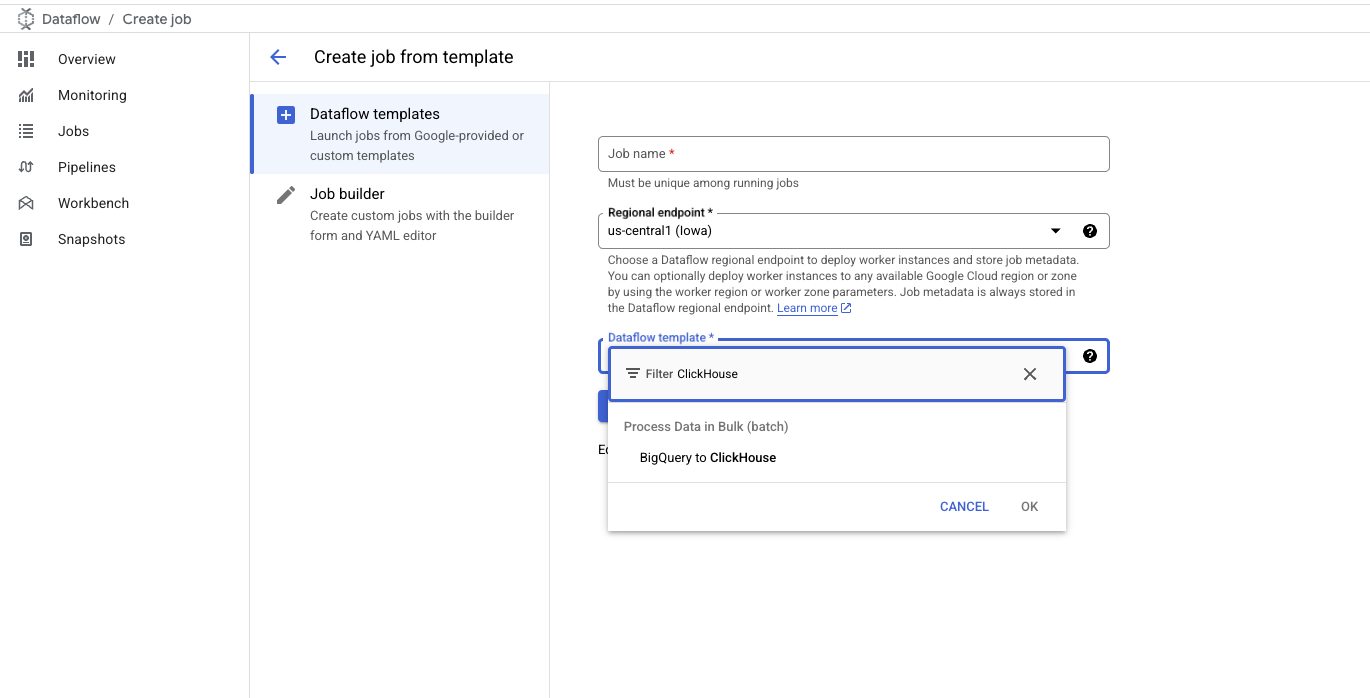
- После выбора форма будет расширена, чтобы вы могли указать дополнительные параметры:
- JDBC URL сервера ClickHouse в формате
jdbc:clickhouse://host:port/schema. - Имя пользователя ClickHouse.
- Имя целевой таблицы ClickHouse.
- JDBC URL сервера ClickHouse в формате
Параметр пароля ClickHouse помечен как необязательный — для случаев, когда пароль не настроен.
Чтобы добавить его, прокрутите вниз до параметра Password for ClickHouse Endpoint.
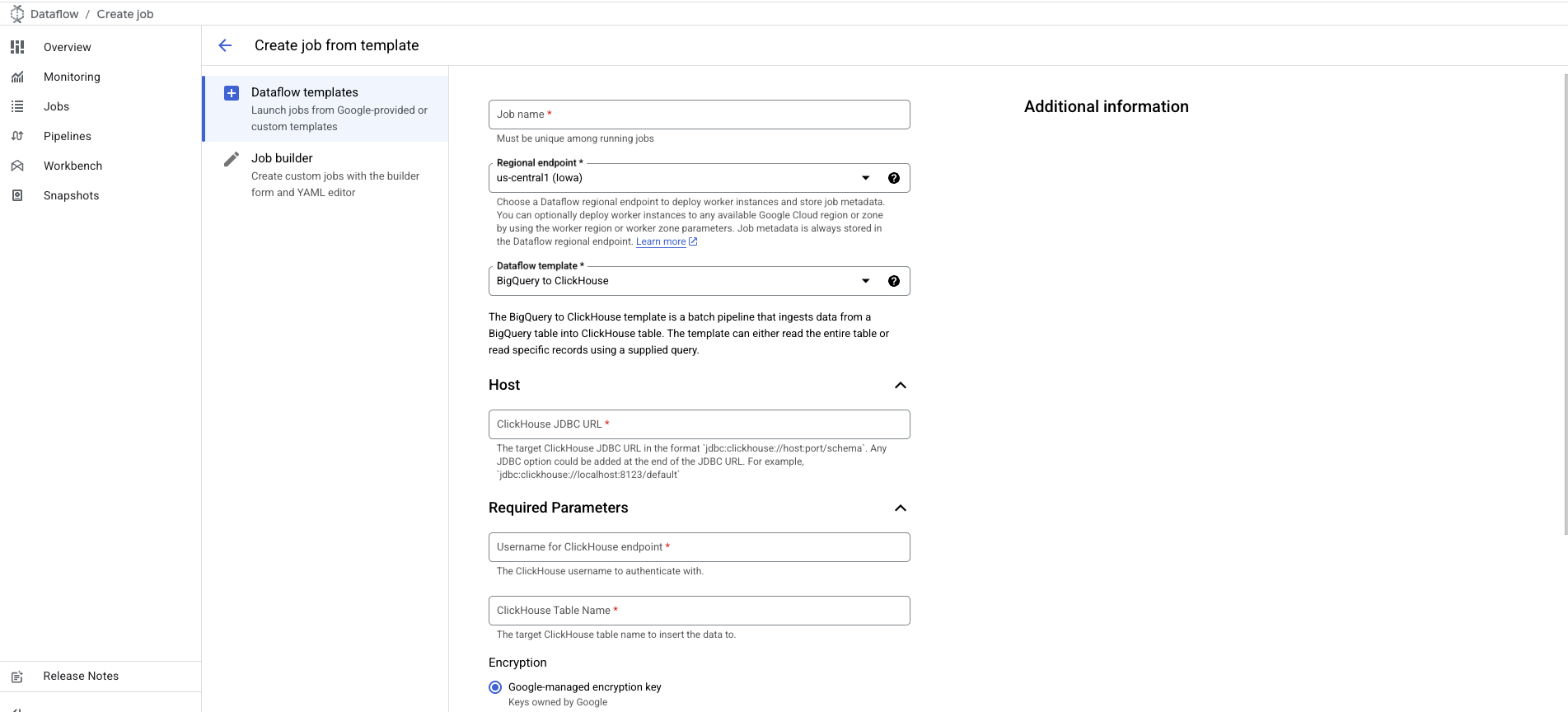
- Настройте и добавьте любые параметры, связанные с BigQuery/ClickHouseIO, как описано в разделе Template Parameters
Установка и настройка gcloud CLI
- Если
gcloudCLI еще не установлен, установите его, следуя этой инструкции. - Выполните шаги из раздела
Before you beginв данном руководстве, чтобы настроить необходимые конфигурации, параметры и разрешения для запуска шаблона Dataflow.
Запуск команды
Используйте команду gcloud dataflow flex-template run
для запуска задания Dataflow, использующего Flex Template.
Ниже приведен пример команды:
Разбор команды
- Job Name: Текст, идущий после ключевого слова
run, является уникальным именем задания. - Template File: JSON-файл, задаваемый параметром
--template-file-gcs-location, определяет структуру шаблона и сведения о допустимых параметрах. Указанный путь к файлу является общедоступным и готов к использованию. - Parameters: Параметры разделяются запятыми. Для строковых параметров заключайте значения в двойные кавычки.
Ожидаемый ответ
После выполнения команды вы должны увидеть ответ, аналогичный следующему:
Мониторинг задания
Перейдите на вкладку Dataflow Jobs в Google Cloud Console, чтобы отслеживать статус задания. Там вы найдете подробную информацию о задании, включая прогресс и возможные ошибки:

Устранение неполадок
Ошибка Memory limit (total) exceeded (code 241)
Эта ошибка возникает, когда ClickHouse исчерпывает доступную память при обработке крупных пакетов данных. Чтобы устранить проблему:
- Увеличьте ресурсы экземпляра: обновите сервер ClickHouse до более мощного экземпляра с большим объёмом памяти, чтобы справляться с нагрузкой на обработку данных.
- Уменьшите размер пакета: настройте размер пакета в конфигурации задания Dataflow так, чтобы отправлять меньшие порции данных в ClickHouse, снижая потребление памяти на пакет. Эти изменения помогают сбалансировать использование ресурсов во время ингестии данных.
Исходный код шаблона
Исходный код шаблона доступен в следующих репозиториях:
GoogleCloudPlatform/DataflowTemplates— основной репозиторий Google Cloud Platform.ClickHouse/DataflowTemplates— форк ClickHouse.
