Проектирование вашей схемы
Хотя schema inference можно использовать для определения начальной схемы JSON-данных и выполнения запросов непосредственно к JSON-файлам, например в S3, вам следует стремиться к созданию оптимизированной версионируемой схемы для ваших данных. Ниже мы рассматриваем рекомендуемый подход к моделированию JSON-структур.
Статический и динамический JSON
Основная задача при определении схемы для JSON — подобрать подходящий тип для значения каждого ключа. Рекомендуется рекурсивно применять следующие правила к каждому ключу в иерархии JSON, чтобы определить соответствующий тип для каждого ключа.
- Примитивные типы — Если значение ключа является примитивным типом, независимо от того, является ли оно частью вложенного объекта или находится в корне, выбирайте его тип в соответствии с общими наилучшими практиками проектирования схемы и правилами оптимизации типов. Массивы примитивов, такие как
phone_numbers ниже, можно моделировать как Array(<type>), например Array(String).
- Статический vs динамический — Если значение ключа является сложным объектом, т.е. либо объектом, либо массивом объектов, определите, подвержено ли оно изменениям. Объекты, в которых новые ключи появляются редко и добавление нового ключа можно предсказать и обработать изменением схемы через
ALTER TABLE ADD COLUMN, можно считать статическими. Это включает объекты, в которых только подмножество ключей может присутствовать в некоторых JSON-документах. Объекты, в которых новые ключи добавляются часто и/или непредсказуемо, следует считать динамическими. Исключение — структуры с сотнями или тысячами вложенных ключей, которые для удобства можно считать динамическими.
Чтобы определить, является ли значение статическим или динамическим, см. соответствующие разделы Обработка статических объектов и Обработка динамических объектов ниже.
Важно: Приведённые выше правила следует применять рекурсивно. Если значение ключа определено как динамическое, дальнейшая оценка не требуется, и можно следовать рекомендациям из раздела Обработка динамических объектов. Если объект статический, продолжайте оценивать вложенные ключи до тех пор, пока значения ключей не будут примитивными или не будут обнаружены динамические ключи.
Чтобы проиллюстрировать эти правила, рассмотрим следующий пример JSON, представляющий человека:
{
"id": 1,
"name": "Clicky McCliickHouse",
"username": "Clicky",
"email": "clicky@clickhouse.com",
"address": [
{
"street": "Victor Plains",
"suite": "Suite 879",
"city": "Wisokyburgh",
"zipcode": "90566-7771",
"geo": {
"lat": -43.9509,
"lng": -34.4618
}
}
],
"phone_numbers": [
"010-692-6593",
"020-192-3333"
],
"website": "clickhouse.com",
"company": {
"name": "ClickHouse",
"catchPhrase": "The real-time data warehouse for analytics",
"labels": {
"type": "database systems",
"founded": "2021"
}
},
"dob": "2007-03-31",
"tags": {
"hobby": "Databases",
"holidays": [
{
"year": 2024,
"location": "Azores, Portugal"
}
],
"car": {
"model": "Tesla",
"year": 2023
}
}
}
Применяя эти правила:
- Корневые ключи
name, username, email, website могут быть представлены типом String. Столбец phone_numbers — это массив примитивов типа Array(String), при этом dob и id имеют типы Date и UInt32 соответственно.
- Новые ключи не будут добавляться в объект
address (только новые объекты адреса), и, таким образом, его можно считать статическим. Если пройтись по структуре рекурсивно, все подстолбцы можно считать примитивами (типа String), за исключением geo. Это также статическая структура с двумя столбцами типа Float32, lat и lon.
- Столбец
tags является динамическим. Мы предполагаем, что в этот объект можно добавлять новые произвольные теги любого типа и структуры.
- Объект
company является статическим и всегда будет содержать не более трёх указанных ключей. Вложенные ключи name и catchPhrase имеют тип String. Ключ labels является динамическим. Мы предполагаем, что в этот объект можно добавлять новые произвольные теги. Значения всегда будут парами «ключ — значение» типа String.
Примечание
Структуры с сотнями или тысячами статических ключей можно считать динамическими, поскольку практически нереалистично статически объявить для них столбцы. По возможности пропускайте пути, которые не нужны, чтобы сократить как затраты на хранение, так и накладные расходы на вывод схемы.
Обработка статических структур
Мы рекомендуем обрабатывать статические структуры с помощью именованных кортежей Tuple. Массивы объектов можно хранить в виде массивов кортежей, то есть Array(Tuple). В самих кортежах столбцы и их соответствующие типы должны определяться по тем же правилам. Это может приводить к использованию вложенных Tuple для представления вложенных объектов, как показано ниже.
Для иллюстрации мы используем приведённый ранее JSON‑пример с объектом person, опуская динамические объекты:
{
"id": 1,
"name": "Clicky McCliickHouse",
"username": "Clicky",
"email": "clicky@clickhouse.com",
"address": [
{
"street": "Victor Plains",
"suite": "Suite 879",
"city": "Wisokyburgh",
"zipcode": "90566-7771",
"geo": {
"lat": -43.9509,
"lng": -34.4618
}
}
],
"phone_numbers": [
"010-692-6593",
"020-192-3333"
],
"website": "clickhouse.com",
"company": {
"name": "ClickHouse",
"catchPhrase": "The real-time data warehouse for analytics"
},
"dob": "2007-03-31"
}
Схема этой таблицы приведена ниже:
CREATE TABLE people
(
`id` Int64,
`name` String,
`username` String,
`email` String,
`address` Array(Tuple(city String, geo Tuple(lat Float32, lng Float32), street String, suite String, zipcode String)),
`phone_numbers` Array(String),
`website` String,
`company` Tuple(catchPhrase String, name String),
`dob` Date
)
ENGINE = MergeTree
ORDER BY username
Обратите внимание, что столбец company определён как Tuple(catchPhrase String, name String). Ключ address использует Array(Tuple) с вложенным Tuple для представления столбца geo.
JSON можно вставлять в эту таблицу в её текущем виде:
INSERT INTO people FORMAT JSONEachRow
{"id":1,"name":"Clicky McCliickHouse","username":"Clicky","email":"clicky@clickhouse.com","address":[{"street":"Victor Plains","suite":"Suite 879","city":"Wisokyburgh","zipcode":"90566-7771","geo":{"lat":-43.9509,"lng":-34.4618}}],"phone_numbers":["010-692-6593","020-192-3333"],"website":"clickhouse.com","company":{"name":"ClickHouse","catchPhrase":"The real-time data warehouse for analytics"},"dob":"2007-03-31"}
В приведённом выше примере у нас минимальный объём данных, но, как показано ниже, мы можем выполнять запросы к столбцам кортежа по их именам, разделённым точками.
SELECT
address.street,
company.name
FROM people
┌─address.street────┬─company.name─┐
│ ['Victor Plains'] │ ClickHouse │
└───────────────────┴──────────────┘
Обратите внимание, что столбец address.street возвращается как Array. Чтобы сделать запрос к конкретному элементу массива по позиции, укажите смещение массива сразу после имени столбца. Например, чтобы получить значение улицы из первого адреса:
SELECT address.street[1] AS street
FROM people
┌─street────────┐
│ Victor Plains │
└───────────────┘
1 row in set. Elapsed: 0.001 sec.
Подстолбцы также можно использовать в ключах сортировки, начиная с версии 24.12:
CREATE TABLE people
(
`id` Int64,
`name` String,
`username` String,
`email` String,
`address` Array(Tuple(city String, geo Tuple(lat Float32, lng Float32), street String, suite String, zipcode String)),
`phone_numbers` Array(String),
`website` String,
`company` Tuple(catchPhrase String, name String),
`dob` Date
)
ENGINE = MergeTree
ORDER BY company.name
Обработка значений по умолчанию
Даже если объекты JSON имеют фиксированную структуру, они часто разрежённые и содержат лишь подмножество известных ключей. К счастью, тип Tuple не требует, чтобы в JSON‑нагрузке присутствовали все столбцы. Если какие‑то из них не указаны, будут использованы значения по умолчанию.
Рассмотрим нашу таблицу people из предыдущего примера и следующий разрежённый JSON, в котором отсутствуют ключи suite, geo, phone_numbers и catchPhrase.
{
"id": 1,
"name": "Clicky McCliickHouse",
"username": "Clicky",
"email": "clicky@clickhouse.com",
"address": [
{
"street": "Victor Plains",
"city": "Wisokyburgh",
"zipcode": "90566-7771"
}
],
"website": "clickhouse.com",
"company": {
"name": "ClickHouse"
},
"dob": "2007-03-31"
}
Ниже показано, что эту строку можно успешно вставить:
INSERT INTO people FORMAT JSONEachRow
{"id":1,"name":"Clicky McCliickHouse","username":"Clicky","email":"clicky@clickhouse.com","address":[{"street":"Victor Plains","city":"Wisokyburgh","zipcode":"90566-7771"}],"website":"clickhouse.com","company":{"name":"ClickHouse"},"dob":"2007-03-31"}
Ok.
1 row in set. Elapsed: 0.002 sec.
Выполнив запрос для этой единственной строки, можно увидеть, что для пропущенных столбцов (включая вложенные объекты) используются значения по умолчанию:
SELECT *
FROM people
FORMAT PrettyJSONEachRow
{
"id": "1",
"name": "Clicky McCliickHouse",
"username": "Clicky",
"email": "clicky@clickhouse.com",
"address": [
{
"city": "Wisokyburgh",
"geo": {
"lat": 0,
"lng": 0
},
"street": "Victor Plains",
"suite": "",
"zipcode": "90566-7771"
}
],
"phone_numbers": [],
"website": "clickhouse.com",
"company": {
"catchPhrase": "",
"name": "ClickHouse"
},
"dob": "2007-03-31"
}
1 row in set. Elapsed: 0.001 sec.
Различие между пустым значением и null
Если вам нужно различать ситуацию, когда значение является пустым, и когда оно вовсе не задано, можно использовать тип Nullable. Однако следует избегать его использования, если только это не абсолютно необходимо, поскольку это отрицательно влияет на хранение данных и производительность запросов по этим столбцам.
Обработка новых столбцов
Хотя структурированный подход проще всего применять, когда ключи JSON статичны, его можно использовать и в том случае, если изменения схемы можно заранее спланировать, то есть новые ключи известны предварительно и схему можно соответствующим образом изменить.
Обратите внимание, что ClickHouse по умолчанию игнорирует ключи JSON, которые переданы в полезной нагрузке, но отсутствуют в схеме. Рассмотрим следующую модифицированную JSON-полезную нагрузку с добавлением ключа nickname:
{
"id": 1,
"name": "Clicky McCliickHouse",
"nickname": "Clicky",
"username": "Clicky",
"email": "clicky@clickhouse.com",
"address": [
{
"street": "Victor Plains",
"suite": "Suite 879",
"city": "Wisokyburgh",
"zipcode": "90566-7771",
"geo": {
"lat": -43.9509,
"lng": -34.4618
}
}
],
"phone_numbers": [
"010-692-6593",
"020-192-3333"
],
"website": "clickhouse.com",
"company": {
"name": "ClickHouse",
"catchPhrase": "The real-time data warehouse for analytics"
},
"dob": "2007-03-31"
}
Этот JSON можно успешно вставить, при этом ключ nickname будет игнорироваться:
INSERT INTO people FORMAT JSONEachRow
{"id":1,"name":"Clicky McCliickHouse","nickname":"Clicky","username":"Clicky","email":"clicky@clickhouse.com","address":[{"street":"Victor Plains","suite":"Suite 879","city":"Wisokyburgh","zipcode":"90566-7771","geo":{"lat":-43.9509,"lng":-34.4618}}],"phone_numbers":["010-692-6593","020-192-3333"],"website":"clickhouse.com","company":{"name":"ClickHouse","catchPhrase":"The real-time data warehouse for analytics"},"dob":"2007-03-31"}
Ok.
1 row in set. Elapsed: 0.002 sec.
Столбцы можно добавлять в схему с помощью команды ALTER TABLE ADD COLUMN. Значение по умолчанию можно задать через предложение DEFAULT, которое будет использоваться, если оно не указано при последующих вставках данных. Для строк, в которых это значение отсутствует (так как они были вставлены до его появления), также будет возвращаться это значение по умолчанию. Если значение DEFAULT не указано, будет использовано значение по умолчанию для данного типа.
Например:
-- insert initial row (nickname will be ignored)
INSERT INTO people FORMAT JSONEachRow
{"id":1,"name":"Clicky McCliickHouse","nickname":"Clicky","username":"Clicky","email":"clicky@clickhouse.com","address":[{"street":"Victor Plains","suite":"Suite 879","city":"Wisokyburgh","zipcode":"90566-7771","geo":{"lat":-43.9509,"lng":-34.4618}}],"phone_numbers":["010-692-6593","020-192-3333"],"website":"clickhouse.com","company":{"name":"ClickHouse","catchPhrase":"The real-time data warehouse for analytics"},"dob":"2007-03-31"}
-- add column
ALTER TABLE people
(ADD COLUMN `nickname` String DEFAULT 'no_nickname')
-- insert new row (same data different id)
INSERT INTO people FORMAT JSONEachRow
{"id":2,"name":"Clicky McCliickHouse","nickname":"Clicky","username":"Clicky","email":"clicky@clickhouse.com","address":[{"street":"Victor Plains","suite":"Suite 879","city":"Wisokyburgh","zipcode":"90566-7771","geo":{"lat":-43.9509,"lng":-34.4618}}],"phone_numbers":["010-692-6593","020-192-3333"],"website":"clickhouse.com","company":{"name":"ClickHouse","catchPhrase":"The real-time data warehouse for analytics"},"dob":"2007-03-31"}
-- select 2 rows
SELECT id, nickname FROM people
┌─id─┬─nickname────┐
│ 2 │ Clicky │
│ 1 │ no_nickname │
└────┴─────────────┘
2 rows in set. Elapsed: 0.001 sec.
Обработка полуструктурированных/динамических структур
Если данные JSON являются полуструктурированными, в которых ключи могут динамически добавляться и/или иметь несколько типов, рекомендуется использовать тип JSON.
Конкретнее, используйте тип JSON, когда ваши данные:
- Имеют непредсказуемые ключи, которые могут со временем меняться.
- Содержат значения разных типов (например, в одном и том же пути иногда находится строка, а иногда число).
- Требуют гибкой схемы данных, при которой строгая типизация нецелесообразна.
- Имеют сотни или даже тысячи путей, которые статичны, но их просто нереалистично объявлять явно. Это обычно редкий случай.
Рассмотрим наш предыдущий пример JSON для person, где объект company.labels был признан динамическим.
Предположим, что company.labels содержит произвольные ключи. Кроме того, тип значения по любому ключу в этой структуре может отличаться в разных строках. Например:
{
"id": 1,
"name": "Clicky McCliickHouse",
"username": "Clicky",
"email": "clicky@clickhouse.com",
"address": [
{
"street": "Victor Plains",
"suite": "Suite 879",
"city": "Wisokyburgh",
"zipcode": "90566-7771",
"geo": {
"lat": -43.9509,
"lng": -34.4618
}
}
],
"phone_numbers": [
"010-692-6593",
"020-192-3333"
],
"website": "clickhouse.com",
"company": {
"name": "ClickHouse",
"catchPhrase": "The real-time data warehouse for analytics",
"labels": {
"type": "database systems",
"founded": "2021",
"employees": 250
}
},
"dob": "2007-03-31",
"tags": {
"hobby": "Databases",
"holidays": [
{
"year": 2024,
"location": "Azores, Portugal"
}
],
"car": {
"model": "Tesla",
"year": 2023
}
}
}
{
"id": 2,
"name": "Analytica Rowe",
"username": "Analytica",
"address": [
{
"street": "Maple Avenue",
"suite": "Apt. 402",
"city": "Dataford",
"zipcode": "11223-4567",
"geo": {
"lat": 40.7128,
"lng": -74.006
}
}
],
"phone_numbers": [
"123-456-7890",
"555-867-5309"
],
"website": "fastdata.io",
"company": {
"name": "FastData Inc.",
"catchPhrase": "Streamlined analytics at scale",
"labels": {
"type": [
"real-time processing"
],
"founded": 2019,
"dissolved": 2023,
"employees": 10
}
},
"dob": "1992-07-15",
"tags": {
"hobby": "Running simulations",
"holidays": [
{
"year": 2023,
"location": "Kyoto, Japan"
}
],
"car": {
"model": "Audi e-tron",
"year": 2022
}
}
}
Учитывая динамический характер столбца company.labels от объекта к объекту, с точки зрения ключей и типов, у нас есть несколько вариантов моделирования этих данных:
- Один JSON-столбец — представляет всю схему в виде одного столбца
JSON, позволяя всем структурам внутри него быть динамическими.
- Целевой JSON-столбец — использовать тип
JSON только для столбца company.labels, сохраняя структурированную схему, использованную выше, для всех остальных столбцов.
Хотя первый подход не согласуется с ранее описанной методологией, использование одного JSON-столбца полезно для прототипирования и задач по инженерии данных.
Для промышленных развертываний ClickHouse в больших масштабах мы рекомендуем максимально четко задавать структуру и использовать тип JSON для выборочных динамических подструктур, где это возможно.
Строгая схема имеет ряд преимуществ:
- Проверка данных – соблюдение строгой схемы позволяет избежать риска взрыва числа столбцов, за пределами отдельных специализированных структур.
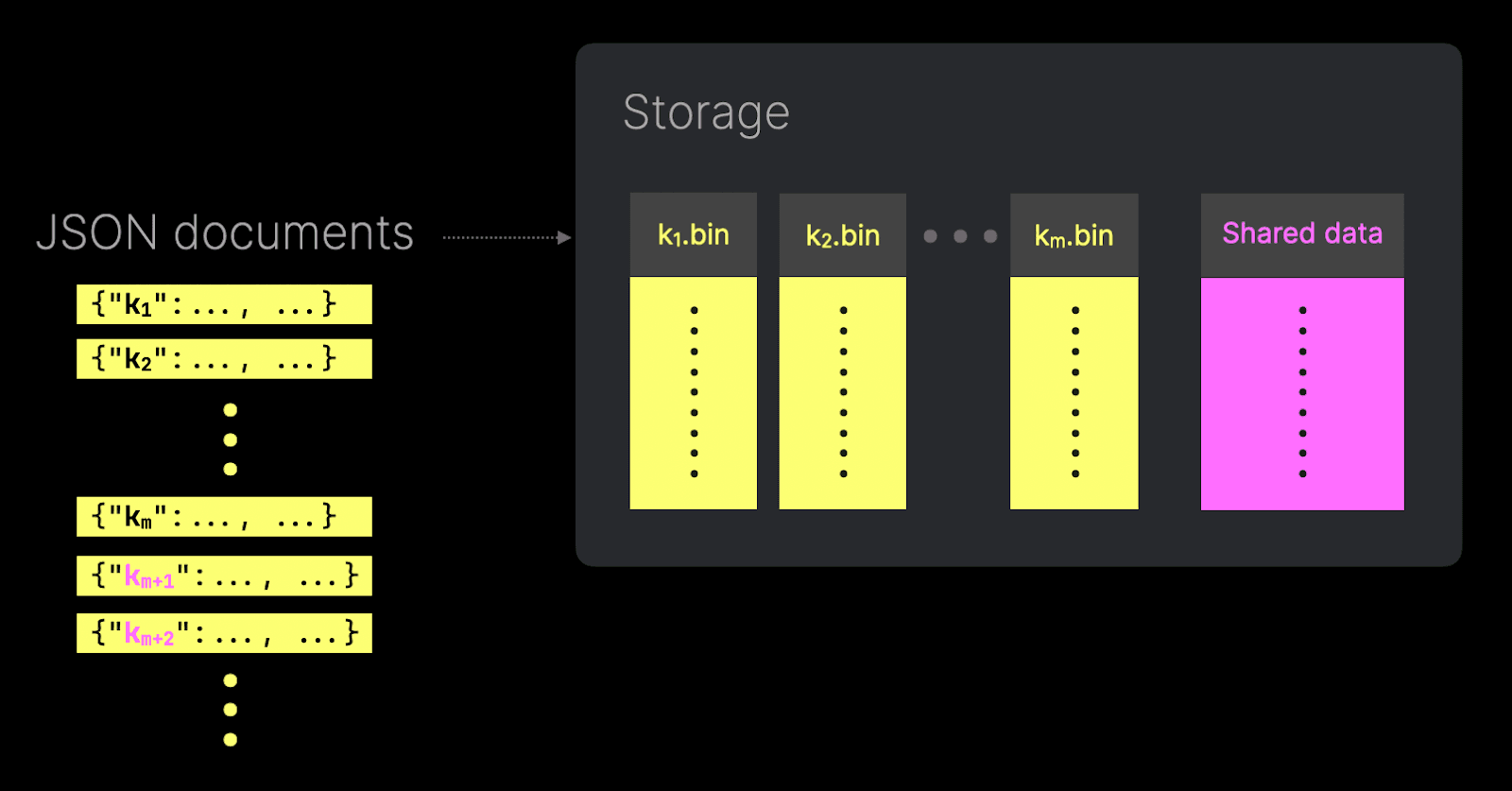
- Снижение риска взрыва числа столбцов – хотя тип JSON масштабируется до потенциально тысяч столбцов, где подстолбцы хранятся как отдельные столбцы, это может привести к «взрыву» файлов столбцов, когда создаётся чрезмерное количество файлов столбцов, что негативно сказывается на производительности. Чтобы снизить этот риск, базовый тип Dynamic, используемый JSON, предоставляет параметр
max_dynamic_paths, который ограничивает количество уникальных путей, сохраняемых как отдельные файлы столбцов. После достижения порога дополнительные пути сохраняются в общем файле столбца с использованием компактного кодированного формата, сохраняя производительность и эффективность хранения при одновременной поддержке гибкой ингестии данных. Доступ к этому общему файлу столбца, однако, уступает по производительности. Отметим также, что столбец JSON может использоваться с подсказками типов. Столбцы с подсказанным типом ("hinted") обеспечат ту же производительность, что и выделенные столбцы.
- Более простой анализ путей и типов – хотя тип JSON поддерживает функции интроспекции для определения типов и путей, которые были выведены по данным, статические структуры могут быть проще для исследования, например с помощью
DESCRIBE.
Один JSON-столбец
Этот подход полезен для прототипирования и задач инженерии данных. В продакшене старайтесь использовать JSON только для динамических подструктур, где это действительно необходимо.
Особенности производительности
Один JSON-столбец можно оптимизировать, пропуская (не сохраняя) JSON-пути, которые не требуются, и используя подсказки типов. Подсказки типов позволяют пользователю явно определить тип для подстолбца, тем самым исключая необходимость вывода типа и дополнительной обработки во время выполнения запроса. Это позволяет достичь такой же производительности, как при использовании явной схемы. Подробности см. в разделе "Using type hints and skipping paths".
Схема одного JSON-столбца в этом случае проста:
SET enable_json_type = 1;
CREATE TABLE people
(
`json` JSON(username String)
)
ENGINE = MergeTree
ORDER BY json.username;
Примечание
Мы указываем подсказку типа для столбца username в определении JSON, так как используем его в сортировке/первичном ключе. Это помогает ClickHouse понять, что этот столбец не может быть NULL, и гарантирует, что будет использован нужный подстолбец username (для каждого типа их может быть несколько, поэтому без этого возникает неоднозначность).
Вставку строк в указанную выше таблицу можно выполнять с помощью формата JSONAsObject:
INSERT INTO people FORMAT JSONAsObject
{"id":1,"name":"Clicky McCliickHouse","username":"Clicky","email":"clicky@clickhouse.com","address":[{"street":"Victor Plains","suite":"Suite 879","city":"Wisokyburgh","zipcode":"90566-7771","geo":{"lat":-43.9509,"lng":-34.4618}}],"phone_numbers":["010-692-6593","020-192-3333"],"website":"clickhouse.com","company":{"name":"ClickHouse","catchPhrase":"The real-time data warehouse for analytics","labels":{"type":"database systems","founded":"2021","employees":250}},"dob":"2007-03-31","tags":{"hobby":"Databases","holidays":[{"year":2024,"location":"Azores, Portugal"}],"car":{"model":"Tesla","year":2023}}}
1 row in set. Elapsed: 0.028 sec.
INSERT INTO people FORMAT JSONAsObject
{"id":2,"name":"Analytica Rowe","username":"Analytica","address":[{"street":"Maple Avenue","suite":"Apt. 402","city":"Dataford","zipcode":"11223-4567","geo":{"lat":40.7128,"lng":-74.006}}],"phone_numbers":["123-456-7890","555-867-5309"],"website":"fastdata.io","company":{"name":"FastData Inc.","catchPhrase":"Streamlined analytics at scale","labels":{"type":["real-time processing"],"founded":2019,"dissolved":2023,"employees":10}},"dob":"1992-07-15","tags":{"hobby":"Running simulations","holidays":[{"year":2023,"location":"Kyoto, Japan"}],"car":{"model":"Audi e-tron","year":2022}}}
1 row in set. Elapsed: 0.004 sec.
SELECT *
FROM people
FORMAT Vertical
Row 1:
──────
json: {"address":[{"city":"Dataford","geo":{"lat":40.7128,"lng":-74.006},"street":"Maple Avenue","suite":"Apt. 402","zipcode":"11223-4567"}],"company":{"catchPhrase":"Streamlined analytics at scale","labels":{"dissolved":"2023","employees":"10","founded":"2019","type":["real-time processing"]},"name":"FastData Inc."},"dob":"1992-07-15","id":"2","name":"Analytica Rowe","phone_numbers":["123-456-7890","555-867-5309"],"tags":{"car":{"model":"Audi e-tron","year":"2022"},"hobby":"Running simulations","holidays":[{"location":"Kyoto, Japan","year":"2023"}]},"username":"Analytica","website":"fastdata.io"}
Row 2:
──────
json: {"address":[{"city":"Wisokyburgh","geo":{"lat":-43.9509,"lng":-34.4618},"street":"Victor Plains","suite":"Suite 879","zipcode":"90566-7771"}],"company":{"catchPhrase":"The real-time data warehouse for analytics","labels":{"employees":"250","founded":"2021","type":"database systems"},"name":"ClickHouse"},"dob":"2007-03-31","email":"clicky@clickhouse.com","id":"1","name":"Clicky McCliickHouse","phone_numbers":["010-692-6593","020-192-3333"],"tags":{"car":{"model":"Tesla","year":"2023"},"hobby":"Databases","holidays":[{"location":"Azores, Portugal","year":"2024"}]},"username":"Clicky","website":"clickhouse.com"}
2 rows in set. Elapsed: 0.005 sec.
Мы можем определить выведенные подстолбцы и их типы с помощью функций интроспекции. Например:
SELECT JSONDynamicPathsWithTypes(json) AS paths
FROM people
FORMAT PrettyJsonEachRow
{
"paths": {
"address": "Array(JSON(max_dynamic_types=16, max_dynamic_paths=256))",
"company.catchPhrase": "String",
"company.labels.employees": "Int64",
"company.labels.founded": "String",
"company.labels.type": "String",
"company.name": "String",
"dob": "Date",
"email": "String",
"id": "Int64",
"name": "String",
"phone_numbers": "Array(Nullable(String))",
"tags.car.model": "String",
"tags.car.year": "Int64",
"tags.hobby": "String",
"tags.holidays": "Array(JSON(max_dynamic_types=16, max_dynamic_paths=256))",
"website": "String"
}
}
{
"paths": {
"address": "Array(JSON(max_dynamic_types=16, max_dynamic_paths=256))",
"company.catchPhrase": "String",
"company.labels.dissolved": "Int64",
"company.labels.employees": "Int64",
"company.labels.founded": "Int64",
"company.labels.type": "Array(Nullable(String))",
"company.name": "String",
"dob": "Date",
"id": "Int64",
"name": "String",
"phone_numbers": "Array(Nullable(String))",
"tags.car.model": "String",
"tags.car.year": "Int64",
"tags.hobby": "String",
"tags.holidays": "Array(JSON(max_dynamic_types=16, max_dynamic_paths=256))",
"website": "String"
}
}
2 rows in set. Elapsed: 0.009 sec.
Полный список функций для интроспекции см. в разделе «Introspection functions»
К вложенным путям можно обращаться с использованием точечной нотации . , например:
SELECT json.name, json.email FROM people
┌─json.name────────────┬─json.email────────────┐
│ Analytica Rowe │ ᴺᵁᴸᴸ │
│ Clicky McCliickHouse │ clicky@clickhouse.com │
└──────────────────────┴───────────────────────┘
2 rows in set. Elapsed: 0.006 sec.
Обратите внимание, что отсутствующие в строках столбцы возвращаются как NULL.
Кроме того, для путей одного и того же типа создаётся отдельный подстолбец. Например, для company.labels.type есть подстолбец типа String и подстолбец типа Array(Nullable(String)). При возможности будут возвращены оба, но мы можем обращаться к конкретным подстолбцам с помощью синтаксиса .::
SELECT json.company.labels.type
FROM people
┌─json.company.labels.type─┐
│ database systems │
│ ['real-time processing'] │
└──────────────────────────┘
2 rows in set. Elapsed: 0.007 sec.
SELECT json.company.labels.type.:String
FROM people
┌─json.company⋯e.:`String`─┐
│ ᴺᵁᴸᴸ │
│ database systems │
└──────────────────────────┘
2 rows in set. Elapsed: 0.009 sec.
Чтобы вернуть вложенные подобъекты, требуется использовать ^. Это сделано намеренно, чтобы избежать чтения большого числа столбцов, если явно не запрошено иное. Объекты, к которым выполняется доступ без ^, вернут NULL, как показано ниже:
-- sub objects will not be returned by default
SELECT json.company.labels
FROM people
┌─json.company.labels─┐
│ ᴺᵁᴸᴸ │
│ ᴺᵁᴸᴸ │
└─────────────────────┘
2 rows in set. Elapsed: 0.002 sec.
-- return sub objects using ^ notation
SELECT json.^company.labels
FROM people
┌─json.^`company`.labels─────────────────────────────────────────────────────────────────┐
│ {"employees":"250","founded":"2021","type":"database systems"} │
│ {"dissolved":"2023","employees":"10","founded":"2019","type":["real-time processing"]} │
└────────────────────────────────────────────────────────────────────────────────────────┘
2 rows in set. Elapsed: 0.004 sec.
Выделенный JSON-столбец
Хотя такой подход полезен для прототипирования и решения задач инженерии данных, в продуктивной среде по возможности рекомендуется использовать явную схему.
Наш предыдущий пример можно смоделировать с помощью одного столбца типа JSON для company.labels.
CREATE TABLE people
(
`id` Int64,
`name` String,
`username` String,
`email` String,
`address` Array(Tuple(city String, geo Tuple(lat Float32, lng Float32), street String, suite String, zipcode String)),
`phone_numbers` Array(String),
`website` String,
`company` Tuple(catchPhrase String, name String, labels JSON),
`dob` Date,
`tags` String
)
ENGINE = MergeTree
ORDER BY username
Мы можем записывать данные в эту таблицу в формате JSONEachRow:
INSERT INTO people FORMAT JSONEachRow
{"id":1,"name":"Clicky McCliickHouse","username":"Clicky","email":"clicky@clickhouse.com","address":[{"street":"Victor Plains","suite":"Suite 879","city":"Wisokyburgh","zipcode":"90566-7771","geo":{"lat":-43.9509,"lng":-34.4618}}],"phone_numbers":["010-692-6593","020-192-3333"],"website":"clickhouse.com","company":{"name":"ClickHouse","catchPhrase":"The real-time data warehouse for analytics","labels":{"type":"database systems","founded":"2021","employees":250}},"dob":"2007-03-31","tags":{"hobby":"Databases","holidays":[{"year":2024,"location":"Azores, Portugal"}],"car":{"model":"Tesla","year":2023}}}
1 row in set. Elapsed: 0.450 sec.
INSERT INTO people FORMAT JSONEachRow
{"id":2,"name":"Analytica Rowe","username":"Analytica","address":[{"street":"Maple Avenue","suite":"Apt. 402","city":"Dataford","zipcode":"11223-4567","geo":{"lat":40.7128,"lng":-74.006}}],"phone_numbers":["123-456-7890","555-867-5309"],"website":"fastdata.io","company":{"name":"FastData Inc.","catchPhrase":"Streamlined analytics at scale","labels":{"type":["real-time processing"],"founded":2019,"dissolved":2023,"employees":10}},"dob":"1992-07-15","tags":{"hobby":"Running simulations","holidays":[{"year":2023,"location":"Kyoto, Japan"}],"car":{"model":"Audi e-tron","year":2022}}}
1 row in set. Elapsed: 0.440 sec.
SELECT *
FROM people
FORMAT Vertical
Row 1:
──────
id: 2
name: Analytica Rowe
username: Analytica
email:
address: [('Dataford',(40.7128,-74.006),'Maple Avenue','Apt. 402','11223-4567')]
phone_numbers: ['123-456-7890','555-867-5309']
website: fastdata.io
company: ('Streamlined analytics at scale','FastData Inc.','{"dissolved":"2023","employees":"10","founded":"2019","type":["real-time processing"]}')
dob: 1992-07-15
tags: {"hobby":"Running simulations","holidays":[{"year":2023,"location":"Kyoto, Japan"}],"car":{"model":"Audi e-tron","year":2022}}
Row 2:
──────
id: 1
name: Clicky McCliickHouse
username: Clicky
email: clicky@clickhouse.com
address: [('Wisokyburgh',(-43.9509,-34.4618),'Victor Plains','Suite 879','90566-7771')]
phone_numbers: ['010-692-6593','020-192-3333']
website: clickhouse.com
company: ('The real-time data warehouse for analytics','ClickHouse','{"employees":"250","founded":"2021","type":"database systems"}')
dob: 2007-03-31
tags: {"hobby":"Databases","holidays":[{"year":2024,"location":"Azores, Portugal"}],"car":{"model":"Tesla","year":2023}}
2 rows in set. Elapsed: 0.005 sec.
Функции интроспекции можно использовать для определения выведенных путей и типов для столбца company.labels.
SELECT JSONDynamicPathsWithTypes(company.labels) AS paths
FROM people
FORMAT PrettyJsonEachRow
{
"paths": {
"dissolved": "Int64",
"employees": "Int64",
"founded": "Int64",
"type": "Array(Nullable(String))"
}
}
{
"paths": {
"employees": "Int64",
"founded": "String",
"type": "String"
}
}
2 rows in set. Elapsed: 0.003 sec.
Использование подсказок типов и пропуска путей
Подсказки типов позволяют указать тип для пути и его вложенного столбца, предотвращая ненужный вывод типов. Рассмотрим следующий пример, где мы задаём типы для JSON-ключей dissolved, employees и founded внутри JSON-столбца company.labels
CREATE TABLE people
(
`id` Int64,
`name` String,
`username` String,
`email` String,
`address` Array(Tuple(
city String,
geo Tuple(
lat Float32,
lng Float32),
street String,
suite String,
zipcode String)),
`phone_numbers` Array(String),
`website` String,
`company` Tuple(
catchPhrase String,
name String,
labels JSON(dissolved UInt16, employees UInt16, founded UInt16)),
`dob` Date,
`tags` String
)
ENGINE = MergeTree
ORDER BY username
INSERT INTO people FORMAT JSONEachRow
{"id":1,"name":"Clicky McCliickHouse","username":"Clicky","email":"clicky@clickhouse.com","address":[{"street":"Victor Plains","suite":"Suite 879","city":"Wisokyburgh","zipcode":"90566-7771","geo":{"lat":-43.9509,"lng":-34.4618}}],"phone_numbers":["010-692-6593","020-192-3333"],"website":"clickhouse.com","company":{"name":"ClickHouse","catchPhrase":"The real-time data warehouse for analytics","labels":{"type":"database systems","founded":"2021","employees":250}},"dob":"2007-03-31","tags":{"hobby":"Databases","holidays":[{"year":2024,"location":"Azores, Portugal"}],"car":{"model":"Tesla","year":2023}}}
1 row in set. Elapsed: 0.450 sec.
INSERT INTO people FORMAT JSONEachRow
{"id":2,"name":"Analytica Rowe","username":"Analytica","address":[{"street":"Maple Avenue","suite":"Apt. 402","city":"Dataford","zipcode":"11223-4567","geo":{"lat":40.7128,"lng":-74.006}}],"phone_numbers":["123-456-7890","555-867-5309"],"website":"fastdata.io","company":{"name":"FastData Inc.","catchPhrase":"Streamlined analytics at scale","labels":{"type":["real-time processing"],"founded":2019,"dissolved":2023,"employees":10}},"dob":"1992-07-15","tags":{"hobby":"Running simulations","holidays":[{"year":2023,"location":"Kyoto, Japan"}],"car":{"model":"Audi e-tron","year":2022}}}
1 row in set. Elapsed: 0.440 sec.
Обратите внимание, что у этих столбцов теперь явно заданные типы:
SELECT JSONAllPathsWithTypes(company.labels) AS paths
FROM people
FORMAT PrettyJsonEachRow
{
"paths": {
"dissolved": "UInt16",
"employees": "UInt16",
"founded": "UInt16",
"type": "String"
}
}
{
"paths": {
"dissolved": "UInt16",
"employees": "UInt16",
"founded": "UInt16",
"type": "Array(Nullable(String))"
}
}
2 rows in set. Elapsed: 0.003 sec.
Кроме того, мы можем пропускать пути внутри JSON, которые не хотим сохранять, с помощью параметров SKIP и SKIP REGEXP, чтобы минимизировать объем хранения и избежать ненужного вывода типов для ненужных путей. Например, предположим, что мы используем один JSON-столбец для приведенных выше данных. Мы можем пропустить пути address и company:
CREATE TABLE people
(
`json` JSON(username String, SKIP address, SKIP company)
)
ENGINE = MergeTree
ORDER BY json.username
INSERT INTO people FORMAT JSONAsObject
{"id":1,"name":"Clicky McCliickHouse","username":"Clicky","email":"clicky@clickhouse.com","address":[{"street":"Victor Plains","suite":"Suite 879","city":"Wisokyburgh","zipcode":"90566-7771","geo":{"lat":-43.9509,"lng":-34.4618}}],"phone_numbers":["010-692-6593","020-192-3333"],"website":"clickhouse.com","company":{"name":"ClickHouse","catchPhrase":"The real-time data warehouse for analytics","labels":{"type":"database systems","founded":"2021","employees":250}},"dob":"2007-03-31","tags":{"hobby":"Databases","holidays":[{"year":2024,"location":"Azores, Portugal"}],"car":{"model":"Tesla","year":2023}}}
1 row in set. Elapsed: 0.450 sec.
INSERT INTO people FORMAT JSONAsObject
{"id":2,"name":"Analytica Rowe","username":"Analytica","address":[{"street":"Maple Avenue","suite":"Apt. 402","city":"Dataford","zipcode":"11223-4567","geo":{"lat":40.7128,"lng":-74.006}}],"phone_numbers":["123-456-7890","555-867-5309"],"website":"fastdata.io","company":{"name":"FastData Inc.","catchPhrase":"Streamlined analytics at scale","labels":{"type":["real-time processing"],"founded":2019,"dissolved":2023,"employees":10}},"dob":"1992-07-15","tags":{"hobby":"Running simulations","holidays":[{"year":2023,"location":"Kyoto, Japan"}],"car":{"model":"Audi e-tron","year":2022}}}
1 row in set. Elapsed: 0.440 sec.
Обратите внимание, что эти столбцы были исключены из наших данных:
SELECT *
FROM people
FORMAT PrettyJSONEachRow
{
"json": {
"dob" : "1992-07-15",
"id" : "2",
"name" : "Analytica Rowe",
"phone_numbers" : [
"123-456-7890",
"555-867-5309"
],
"tags" : {
"car" : {
"model" : "Audi e-tron",
"year" : "2022"
},
"hobby" : "Running simulations",
"holidays" : [
{
"location" : "Kyoto, Japan",
"year" : "2023"
}
]
},
"username" : "Analytica",
"website" : "fastdata.io"
}
}
{
"json": {
"dob" : "2007-03-31",
"email" : "clicky@clickhouse.com",
"id" : "1",
"name" : "Clicky McCliickHouse",
"phone_numbers" : [
"010-692-6593",
"020-192-3333"
],
"tags" : {
"car" : {
"model" : "Tesla",
"year" : "2023"
},
"hobby" : "Databases",
"holidays" : [
{
"location" : "Azores, Portugal",
"year" : "2024"
}
]
},
"username" : "Clicky",
"website" : "clickhouse.com"
}
}
2 rows in set. Elapsed: 0.004 sec.
Подсказки типов делают больше, чем просто избавляют от ненужного вывода типов — они полностью устраняют дополнительный уровень косвенности при хранении и обработке, а также позволяют указать оптимальные примитивные типы. JSON-пути с подсказками типов всегда хранятся так же, как обычные столбцы, избавляя от необходимости в столбцах-дискриминаторах или динамического разрешения во время выполнения запроса.
Это означает, что при чётко определённых подсказках типов вложенные JSON-ключи достигают той же производительности и эффективности, как если бы они изначально были смоделированы как столбцы верхнего уровня.
В результате для наборов данных, которые в основном однородны, но при этом выигрывают от гибкости JSON, подсказки типов предоставляют удобный способ сохранить производительность без необходимости переработки схемы или конвейера приёма данных.
Настройка динамических путей
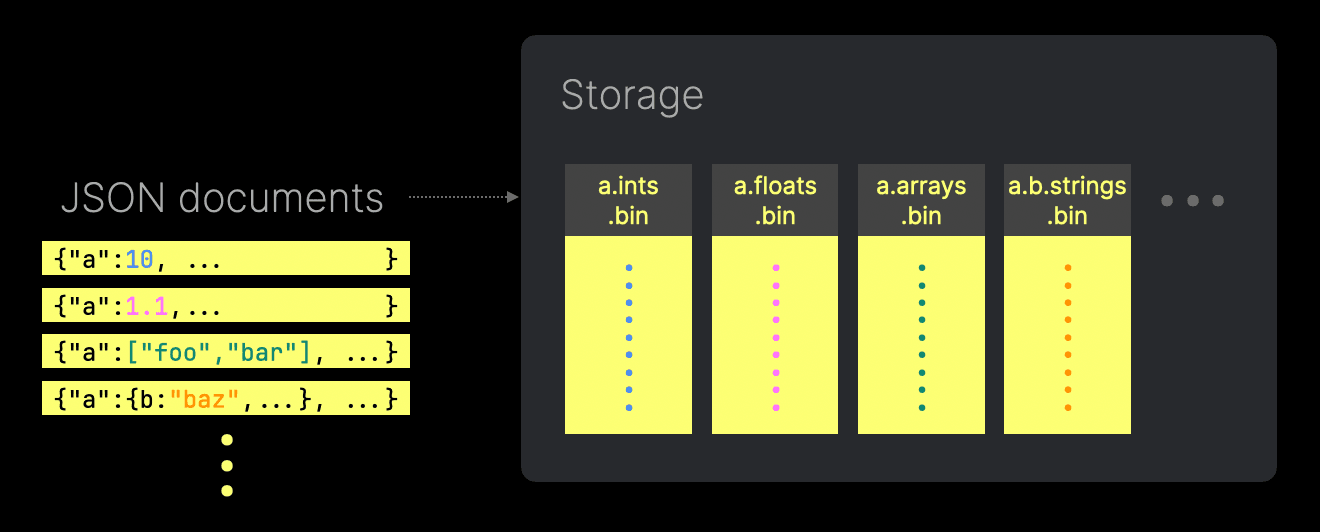
ClickHouse хранит каждый JSON‑путь как подстолбец в истинном столбцовом формате хранения, обеспечивая те же преимущества по производительности, что и для традиционных столбцов — такие как сжатие, SIMD‑ускоренная обработка и минимальный дисковый I/O. Каждая уникальная комбинация пути и типа в ваших JSON‑данных может стать отдельным файлом столбца на диске.
Например, когда два JSON‑пути вставляются с различающимися типами, ClickHouse хранит значения каждого конкретного типа в отдельных подстолбцах. К этим подстолбцам можно обращаться независимо, минимизируя лишний I/O. Обратите внимание, что при выполнении запроса к столбцу с несколькими типами его значения всё равно возвращаются как единый столбцовый результат.
Кроме того, за счёт использования смещений ClickHouse гарантирует, что эти подстолбцы остаются плотными, без хранения значений по умолчанию для отсутствующих JSON‑путей. Такой подход максимизирует сжатие и дополнительно снижает I/O.
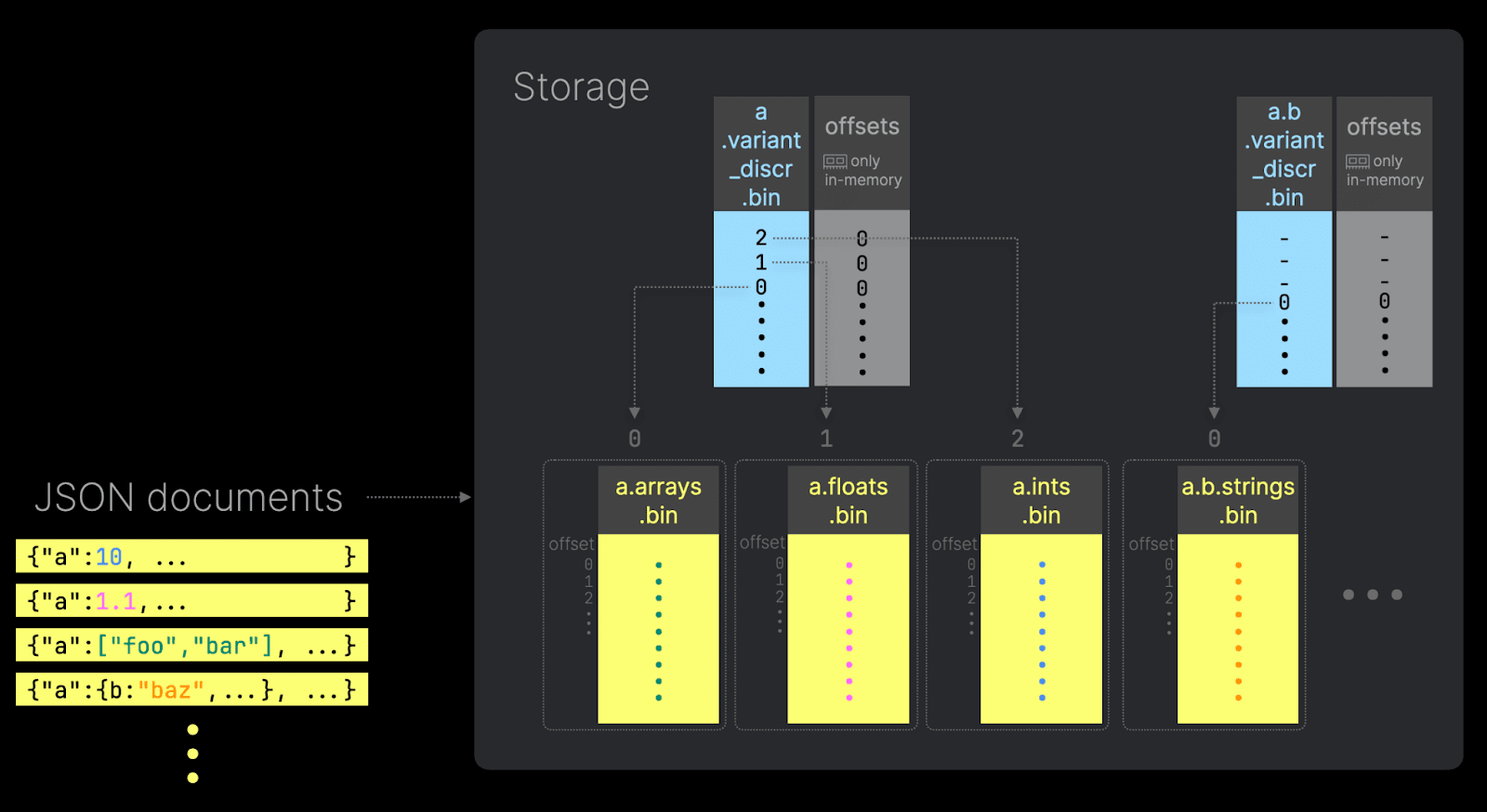
Однако в сценариях с высокой кардинальностью или сильно изменяющимися JSON‑структурами — таких как конвейеры телеметрии, логи или хранилища признаков для машинного обучения — такое поведение может привести к взрывному росту количества файлов столбцов. Каждый новый уникальный JSON‑путь приводит к новому файловому столбцу, а каждый вариант типа под этим путём создаёт дополнительный файловый столбец. Хотя это оптимально для производительности чтения, это создаёт операционные сложности: исчерпание дескрипторов файлов, рост потребления памяти и более медленные операции слияния из‑за большого числа мелких файлов.
Чтобы смягчить это, ClickHouse вводит концепцию подстолбца overflow: после того как количество различных JSON‑путей превышает порог, дополнительные пути сохраняются в одном общем файле с использованием компактного кодированного формата. Этот файл по‑прежнему доступен для запросов, но не обладает теми же характеристиками производительности, что и выделенные подстолбцы.
Этот порог контролируется параметром max_dynamic_paths в объявлении типа JSON.
CREATE TABLE logs
(
payload JSON(max_dynamic_paths = 500)
)
ENGINE = MergeTree
ORDER BY tuple();
Избегайте слишком высоких значений этого параметра — большие значения увеличивают потребление ресурсов и снижают эффективность. В качестве практического ориентира держите его ниже 10 000. Для рабочих нагрузок с сильно изменяющимися структурами используйте подсказки типов и параметры SKIP, чтобы ограничить сохраняемые данные.
Пользователям, которым интересно, как реализован этот новый тип столбца, мы рекомендуем прочитать наш подробный пост в блоге "A New Powerful JSON Data Type for ClickHouse".