Разделение хранилища и вычислений
Обзор
В этом руководстве рассматривается, как использовать ClickHouse и S3 для реализации архитектуры с раздельными хранением и вычислительными ресурсами.
Разделение хранилища и вычислительных ресурсов означает, что вычислительные ресурсы и ресурсы хранения управляются независимо друг от друга. В ClickHouse это обеспечивает лучшую масштабируемость, экономическую эффективность и гибкость. Вы можете независимо масштабировать хранилище и вычислительные ресурсы по мере необходимости, оптимизируя производительность и затраты.
Использование ClickHouse с хранилищем в S3 особенно полезно для сценариев, где производительность запросов по «холодным» данным менее критична. ClickHouse поддерживает использование S3 в качестве хранилища для движка MergeTree с помощью S3BackedMergeTree. Этот табличный движок позволяет воспользоваться масштабируемостью и экономичностью S3, сохраняя при этом производительность вставки и выполнения запросов движка MergeTree.
Обратите внимание, что реализация и эксплуатация архитектуры с разделением хранилища и вычислительных ресурсов сложнее по сравнению со стандартными развертываниями ClickHouse. Хотя самостоятельно управляемый ClickHouse позволяет разделять хранилище и вычислительные ресурсы, как описано в этом руководстве, мы рекомендуем использовать ClickHouse Cloud, который позволяет использовать ClickHouse в этой архитектуре без дополнительной конфигурации, с использованием табличного движка SharedMergeTree.
В этом руководстве предполагается, что вы используете ClickHouse версии 22.8 или выше.
Не настраивайте какие-либо политики жизненного цикла AWS/GCS. Это не поддерживается и может привести к повреждению таблиц.
1. Использование S3 в качестве диска для ClickHouse
Создание диска
Создайте новый файл в каталоге config.d ClickHouse для хранения конфигурации хранилища:
Скопируйте следующий XML в только что созданный файл, заменив BUCKET, ACCESS_KEY_ID, SECRET_ACCESS_KEY на параметры бакета AWS, в который вы хотите сохранять данные:
Если вам необходимо более точно настроить диск S3, например указать region или отправить пользовательский HTTP header, вы можете найти список соответствующих настроек здесь.
Вы также можете заменить access_key_id и secret_access_key на следующие значения, которые попытаются получить учетные данные из переменных среды и метаданных Amazon EC2:
После того как вы создали файл конфигурации, необходимо изменить владельца файла на пользователя и группу clickhouse:
Теперь вы можете перезапустить сервер ClickHouse, чтобы изменения вступили в силу:
2. Создайте таблицу с использованием S3
Чтобы проверить, что диск S3 настроен правильно, можно попробовать создать таблицу и выполнить к ней запрос.
Создайте таблицу, указав новую политику хранения S3:
Обратите внимание, что нам не нужно было указывать движок таблицы как S3BackedMergeTree. ClickHouse автоматически преобразует тип движка, если обнаруживает, что таблица использует S3 в качестве хранилища.
Проверьте, что таблица была создана с правильной политикой хранения:
Вы должны увидеть следующий результат:
Теперь вставим несколько строк в нашу новую таблицу:
Убедимся, что наши записи были вставлены:
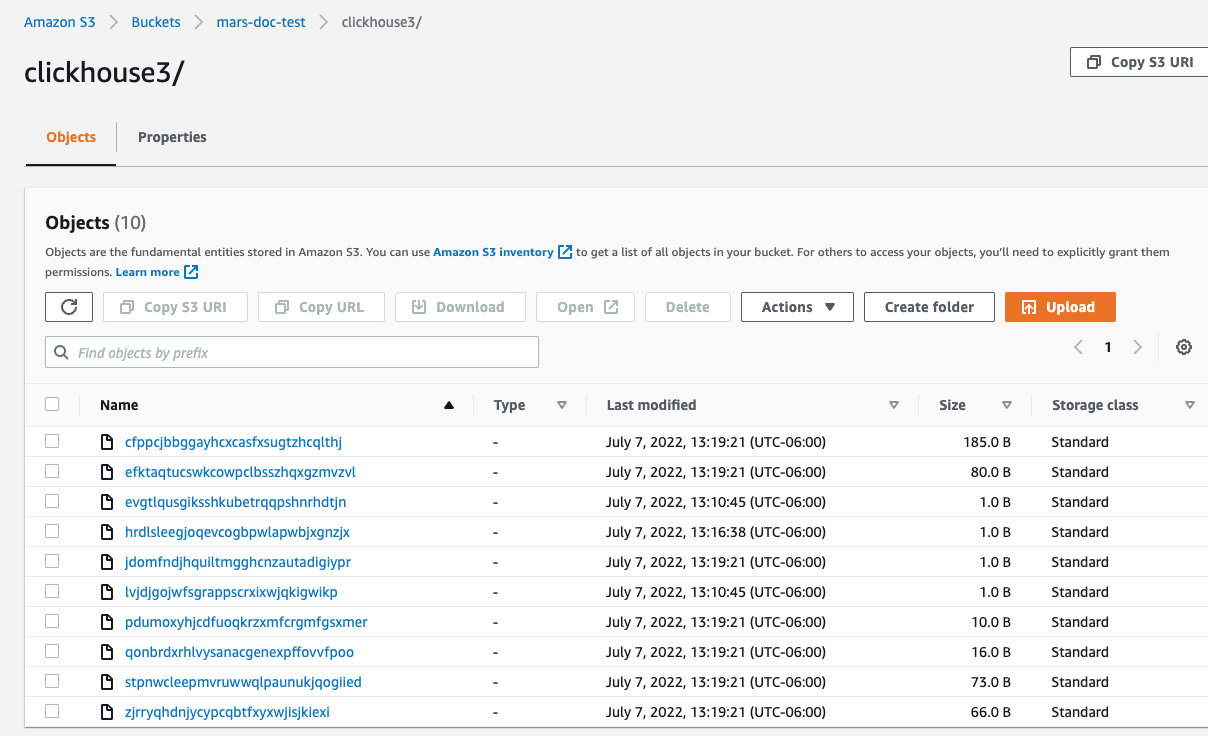
В консоли AWS, если ваши данные были успешно записаны в S3, вы увидите, что ClickHouse создал новые файлы в указанном вами S3-бакете.
Если всё прошло успешно, вы теперь используете ClickHouse с раздельными хранилищем и вычислительными ресурсами!
3. Реализация репликации для отказоустойчивости (необязательно)
Не настраивайте политики жизненного цикла AWS/GCS. Это не поддерживается и может привести к некорректной работе таблиц.
Для обеспечения отказоустойчивости вы можете использовать несколько серверных узлов ClickHouse, распределённых по нескольким регионам AWS, с отдельным бакетом S3 для каждого узла.
Репликация с дисками S3 может быть реализована с помощью движка таблиц ReplicatedMergeTree. Подробности см. в следующем руководстве:
