Работа с движком ReplacingMergeTree
Транзакционные базы данных оптимизированы для рабочих нагрузок с частыми транзакционными операциями обновления и удаления, тогда как OLAP-базы данных предоставляют ослабленные гарантии для таких операций. Вместо этого они оптимизированы под работу с неизменяемыми данными, вставляемыми пакетами, что обеспечивает значительно более высокую скорость аналитических запросов. Хотя ClickHouse предоставляет операции обновления через мутации, а также облегчённый механизм удаления строк, его колоночная структура означает, что эти операции следует планировать с осторожностью, как было описано выше. Эти операции обрабатываются асинхронно, выполняются в одном потоке и требуют (в случае обновлений) перезаписи данных на диске. Поэтому их не следует использовать для большого количества небольших изменений. Чтобы обрабатывать поток операций обновления и удаления строк, избегая описанных выше сценариев использования, мы можем использовать табличный движок ClickHouse ReplacingMergeTree.
Автоматические upsert-операции для вставленных строк
Движок таблицы ReplacingMergeTree позволяет применять операции обновления к строкам без необходимости использовать неэффективные операторы ALTER или DELETE. Это достигается за счёт того, что пользователи могут вставлять несколько копий одной и той же строки и помечать одну из них как последнюю версию. Фоновый процесс, в свою очередь, асинхронно удаляет более старые версии той же строки, эффективно имитируя операцию обновления за счёт использования неизменяемых вставок.
Это основано на способности движка таблицы определять дубликаты строк. Это реализуется с помощью предложения ORDER BY, используемого для определения уникальности, т. е. если две строки имеют одинаковые значения для столбцов, указанных в ORDER BY, они считаются дубликатами. Столбец version, задаваемый при определении таблицы, позволяет сохранить последнюю версию строки, когда две строки определены как дубликаты, то есть сохраняется строка с наибольшим значением версии.
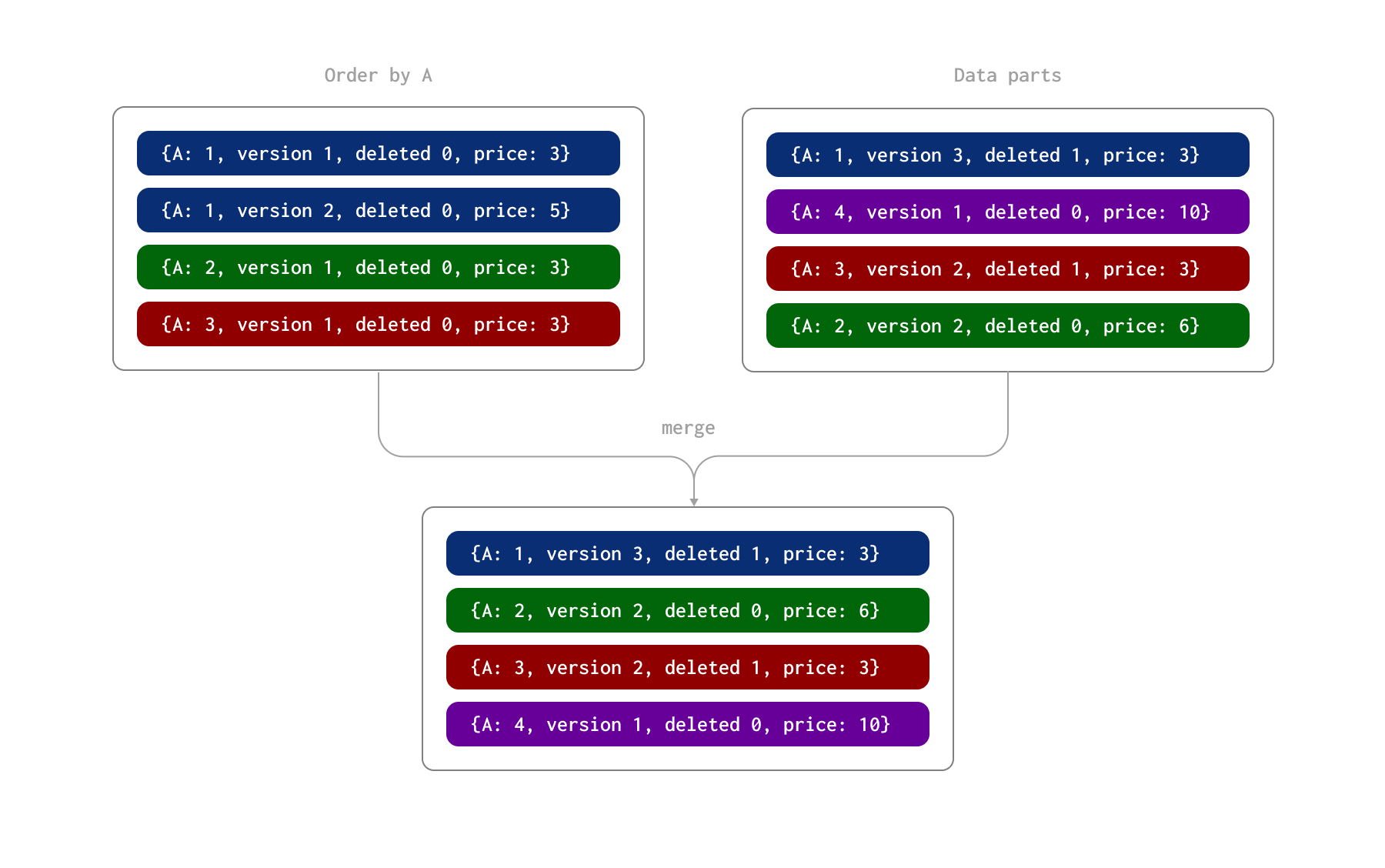
Мы иллюстрируем этот процесс на примере ниже. Здесь строки однозначно идентифицируются столбцом A (ORDER BY для таблицы). Мы предполагаем, что эти строки были вставлены двумя партиями, в результате чего на диске образовались две части данных. Позже, в ходе асинхронного фонового процесса, эти части объединяются.
ReplacingMergeTree дополнительно позволяет указать столбец deleted. Он может содержать 0 или 1, где значение 1 указывает, что строка (и её дубликаты) была удалена, а ноль используется в противном случае. Примечание: удалённые строки не будут удалены во время слияния.
Во время этого процесса при слиянии частей происходит следующее:
- Строка, идентифицируемая значением 1 для столбца A, имеет и строку обновления с версией 2, и строку удаления с версией 3 (и значением столбца
deleted, равным 1). Поэтому сохраняется последняя строка, помеченная как удалённая. - Строка, идентифицируемая значением 2 для столбца A, имеет две строки обновления. Сохраняется последняя строка со значением 6 в столбце
price. - Строка, идентифицируемая значением 3 для столбца A, имеет строку с версией 1 и строку удаления с версией 2. Сохраняется эта строка удаления.
В результате этого процесса слияния у нас есть четыре строки, представляющие конечное состояние:
Обратите внимание, что удалённые строки никогда не удаляются. Их можно принудительно удалить с помощью OPTIMIZE table FINAL CLEANUP. Для этого требуется экспериментальная настройка allow_experimental_replacing_merge_with_cleanup=1. Эту операцию следует выполнять только при соблюдении следующих условий:
- Вы уверены, что строки со старыми версиями (для тех, которые удаляются при очистке) не будут вставлены после выполнения операции. Если они всё же будут вставлены, они будут ошибочно сохранены, так как удалённые строки больше не будут присутствовать.
- Убедитесь, что все реплики синхронизированы перед выполнением очистки. Этого можно добиться с помощью команды:
Мы рекомендуем приостановить вставки после того, как выполнение условия (1) гарантировано, и до завершения этой команды и последующей очистки.
Обработка удалений с использованием ReplacingMergeTree рекомендуется только для таблиц с небольшим или умеренным числом удалений (менее 10%), за исключением случаев, когда можно планировать периоды очистки при соблюдении вышеуказанных условий.
Совет: вы также можете выполнить
OPTIMIZE FINAL CLEANUPдля выборочных партиций, которые больше не подвержены изменениям.
Выбор первичного/дедупликационного ключа
Выше мы выделили важное дополнительное ограничение, которое также должно соблюдаться в случае ReplacingMergeTree: значения столбцов, указанных в ORDER BY, должны однозначно идентифицировать строку при любых изменениях. Если выполняется миграция из транзакционной базы данных, такой как Postgres, исходный первичный ключ Postgres, таким образом, должен быть включён в предложение ORDER BY в ClickHouse.
Пользователи ClickHouse знакомы с выбором столбцов в предложении ORDER BY своих таблиц для оптимизации производительности запросов. Как правило, эти столбцы следует выбирать на основе часто выполняемых запросов и перечислять в порядке возрастания кардинальности. Важно, что ReplacingMergeTree накладывает дополнительное ограничение — эти столбцы должны быть неизменяемыми, т.е. при репликации из Postgres добавляйте столбцы в это предложение только в том случае, если они не изменяются в исходных данных Postgres. Хотя другие столбцы могут меняться, именно эти столбцы должны оставаться постоянными для уникальной идентификации строк.
Для аналитических нагрузок первичный ключ Postgres, как правило, мало полезен, поскольку вы редко будете выполнять точечный поиск отдельных строк. Учитывая, что мы рекомендуем упорядочивать столбцы в порядке возрастания кардинальности, а также тот факт, что сравнения по столбцам, идущим раньше в ORDER BY, обычно выполняются быстрее, первичный ключ Postgres следует добавлять в конец ORDER BY (если только он не имеет аналитической ценности). Если в Postgres первичный ключ составной (несколько столбцов), их также следует добавить в ORDER BY, учитывая кардинальность и ожидаемую полезность для запросов. Вы также можете сгенерировать уникальный первичный ключ с помощью конкатенации значений в столбце MATERIALIZED.
Рассмотрим таблицу posts из набора данных Stack Overflow.
Мы используем ключ ORDER BY вида (PostTypeId, toDate(CreationDate), CreationDate, Id). Столбец Id, уникальный для каждого поста, обеспечивает возможность дедупликации строк. В схему добавляются столбцы Version и Deleted в соответствии с требованиями.
Выполнение запросов к ReplacingMergeTree
При слиянии данных движок ReplacingMergeTree определяет дублирующиеся строки, используя значения столбцов ORDER BY как уникальный идентификатор, и либо сохраняет только строку с наибольшей версией, либо удаляет все дубликаты, если последняя версия помечает строку как удалённую. Однако это даёт лишь корректность «со временем» — нет гарантии, что строки действительно будут дедуплицированы, и на это не следует полагаться. В результате запросы могут возвращать некорректные ответы, поскольку строки с обновлениями и удалениями продолжают участвовать в выборках.
Чтобы получать корректные ответы, вам необходимо дополнять фоновые слияния дедупликацией и удалением на этапе выполнения запроса. Это можно сделать с помощью оператора FINAL.
Рассмотрим приведённую выше таблицу posts. Мы можем воспользоваться обычным методом загрузки этого набора данных, но указать столбцы deleted и version, задав для них значение 0. В качестве примера мы загружаем только 10000 строк.
Проверим количество строк:
Теперь обновим нашу статистику по публикациям и ответам. Вместо того чтобы изменять существующие значения, мы вставляем новые копии 5000 строк и увеличиваем их номер версии на единицу (это означает, что в таблице будет существовать 150 строк). Это можно смоделировать с помощью простого INSERT INTO SELECT:
Кроме того, мы удаляем 1000 случайных постов, повторно вставляя строки, но уже со значением столбца deleted, равным 1. Это также можно смоделировать с помощью простого INSERT INTO SELECT.
Результатом вышеописанных операций будет 16 000 строк, т.е. 10 000 + 5 000 + 1 000. На самом деле правильный итог должен быть другим: у нас должно быть всего на 1 000 строк меньше исходного количества, т.е. 10 000 − 1 000 = 9 000.
Ваши результаты могут отличаться в зависимости от того, какие слияния уже произошли. Мы видим, что итоговое количество отличается, так как у нас есть дублирующиеся строки. Применение FINAL к таблице даёт корректный результат.
Производительность с FINAL
Оператор FINAL действительно оказывает небольшое влияние на производительность запросов.
Это будет наиболее заметно, когда запросы не фильтруют по столбцам первичного ключа,
что приводит к чтению большего объёма данных и увеличивает накладные расходы на дедупликацию. Если вы
фильтруете по столбцам ключа с помощью условия WHERE, объём данных, загружаемых и передаваемых
для дедупликации, будет уменьшен.
Если условие WHERE не использует столбец ключа, ClickHouse в текущей реализации не использует оптимизацию PREWHERE при использовании FINAL. Эта оптимизация направлена на сокращение количества строк, читаемых для столбцов, по которым не происходит фильтрация. Примеры эмуляции такого поведения PREWHERE и, соответственно, потенциального улучшения производительности можно найти здесь.
Эффективное использование партиций с ReplacingMergeTree
Слияние данных в ClickHouse происходит на уровне партиций. При использовании ReplacingMergeTree мы рекомендуем разбивать таблицу на партиции в соответствии с лучшими практиками при условии, что ключ партиционирования для строки не изменяется. Это гарантирует, что обновления, относящиеся к одной и той же строке, будут попадать в одну и ту же партицию ClickHouse. Вы можете использовать тот же ключ партиционирования, что и в Postgres, при условии соблюдения лучших практик, описанных здесь.
Если это выполняется, вы можете использовать настройку do_not_merge_across_partitions_select_final=1 для повышения производительности запросов с FINAL. Эта настройка приводит к тому, что партиции сливаются и обрабатываются независимо друг от друга при использовании FINAL.
Рассмотрите следующую таблицу posts, в которой мы не используем партиционирование:
Чтобы гарантировать, что FINAL вынужден выполнять некоторую работу, мы обновляем 1 млн строк: увеличиваем их значение AnswerCount, вставляя дублирующиеся строки.
Подсчёт суммы ответов по годам с использованием FINAL:
Повторите те же шаги для таблицы, разбитой на партиции по годам, и затем выполните тот же запрос с do_not_merge_across_partitions_select_final=1.
Как видно, секционирование в данном случае значительно улучшило производительность запроса за счёт того, что процесс дедупликации выполняется параллельно на уровне партиций.
Особенности поведения слияний
Механизм выбора слияний в ClickHouse выходит за рамки простого объединения частей. Ниже мы рассматриваем это поведение в контексте ReplacingMergeTree, включая параметры конфигурации для более агрессивного слияния старых данных и аспекты, касающиеся крупных частей.
Логика выбора слияний
Хотя цель слияния — минимизировать количество частей, при этом также учитывается стоимость эффекта write amplification. В результате некоторые диапазоны частей исключаются из слияния, если оно, согласно внутренним вычислениям, приведёт к чрезмерному write amplification. Такое поведение помогает избежать ненужного расхода ресурсов и продлевает срок службы компонентов хранилища.
Поведение слияний для крупных частей
Движок ReplacingMergeTree в ClickHouse оптимизирован для управления дублирующимися строками путём слияния частей данных, сохраняя только последнюю версию каждой строки на основе заданного уникального ключа. Однако когда объединённая часть достигает порога max_bytes_to_merge_at_max_space_in_pool, она больше не будет выбираться для дальнейшего слияния, даже если установлен min_age_to_force_merge_seconds. В результате на автоматические слияния больше нельзя полагаться для удаления дублей, которые могут накапливаться при непрерывной вставке данных.
Для решения этой проблемы вы можете вызывать OPTIMIZE FINAL для ручного слияния частей и удаления дублей. В отличие от автоматических слияний, OPTIMIZE FINAL игнорирует порог max_bytes_to_merge_at_max_space_in_pool и выполняет слияние частей, основываясь только на доступных ресурсах, в первую очередь дисковом пространстве, до тех пор, пока в каждом разделе не останется одна часть. Однако такой подход может потреблять много памяти на больших таблицах и может требовать повторного выполнения по мере добавления новых данных.
Более практичным и производительным решением является разбиение таблицы на разделы (partitioning). Это помогает предотвратить достижение частью максимального размера для слияния и снижает потребность в постоянных ручных оптимизациях.
Разбиение на разделы и слияние между разделами
Как обсуждается в разделе Exploiting Partitions with ReplacingMergeTree, мы рекомендуем разбиение таблиц на разделы как наилучшую практику. Разбиение изолирует данные для более эффективных слияний и предотвращает слияния между разделами, особенно во время выполнения запросов. Начиная с версий 23.12 это поведение улучшено: если ключ раздела является префиксом ключа сортировки, слияния между разделами не выполняются на этапе выполнения запроса, что приводит к более высокой производительности запросов.
Настройка слияний для улучшения производительности запросов
По умолчанию параметры min_age_to_force_merge_seconds и min_age_to_force_merge_on_partition_only установлены в 0 и false соответственно, что отключает эти функции. В такой конфигурации ClickHouse применяет стандартное поведение слияний без принудительного слияния на основе возраста раздела.
Если указано значение для min_age_to_force_merge_seconds, ClickHouse будет игнорировать обычные эвристики слияния для частей, возраст которых превышает заданный период. Хотя это, как правило, эффективно только в том случае, если цель — минимизировать общее количество частей, в ReplacingMergeTree это может улучшить производительность запросов за счёт уменьшения количества частей, которые нужно сливать во время выполнения запроса.
Это поведение можно дополнительно настроить, установив min_age_to_force_merge_on_partition_only=true, что требует, чтобы все части в разделе были старше min_age_to_force_merge_seconds для агрессивного слияния. Такая конфигурация позволяет старым разделам со временем сливаться до одной части, что консолидирует данные и поддерживает производительность запросов.
Рекомендуемые настройки
Настройка поведения слияний — это продвинутая операция. Мы рекомендуем проконсультироваться со службой поддержки ClickHouse перед включением этих настроек в продакшн-средах.
В большинстве случаев предпочтительно устанавливать min_age_to_force_merge_seconds в небольшое значение — значительно меньше периода раздела. Это минимизирует количество частей и предотвращает ненужные слияния во время выполнения запроса с оператором FINAL.
Например, рассмотрим ежемесячный раздел, который уже был слит в одну часть. Если небольшая, разовая вставка создаёт новую часть в этом разделе, производительность запросов может ухудшиться, поскольку ClickHouse должен читать несколько частей до завершения слияния. Установка min_age_to_force_merge_seconds может обеспечить агрессивное слияние этих частей, предотвращая деградацию производительности запросов.
