Инкрементное Материализованное Представление
Обзор
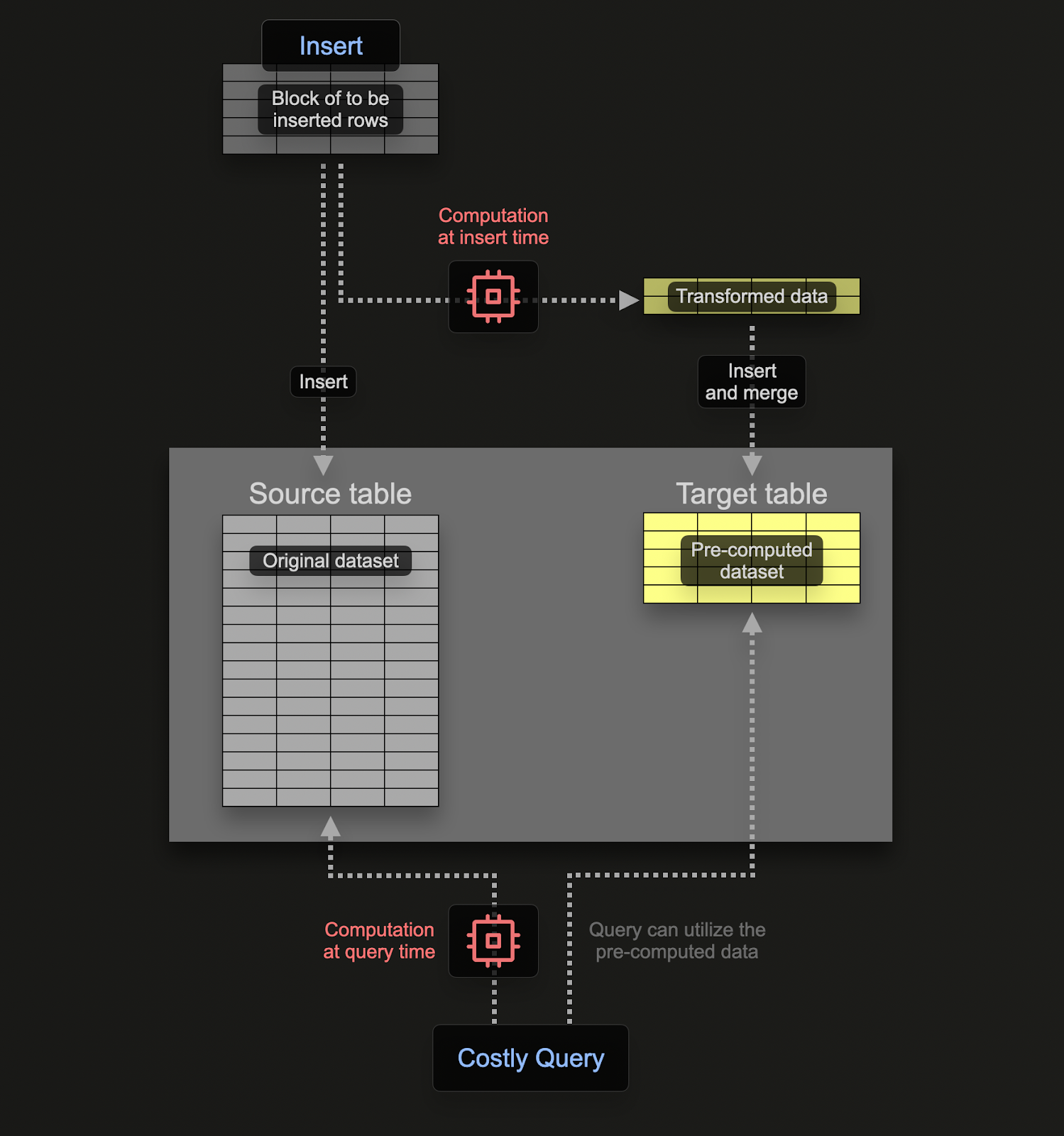
Инкрементные Материализованные Представления (Материализованные Представления) позволяют пользователям перенести стоимость вычислений с времени выполнения запроса на время вставки, что приводит к более быстрым SELECT запросам.
В отличие от транзакционных баз данных, таких как Postgres, Материализованное Представление ClickHouse — это всего лишь триггер, который выполняет запрос над блоками данных по мере их вставки в таблицу. Результат этого запроса вставляется во вторую "целевую" таблицу. При вставке дополнительных строк результаты снова будут отправлены в целевую таблицу, где промежуточные результаты будут обновлены и объединены. Этот объединённый результат эквивалентен выполнению запроса над всеми исходными данными.
Основная мотивация использования Материализованных Представлений заключается в том, что результаты, вставленные в целевую таблицу, представляют собой результаты агрегации, фильтрации или преобразования строк. Эти результаты часто являются меньшей репрезентацией исходных данных (частичным чертежом в случае агрегации). Это, наряду с тем, что запрос для чтения результатов из целевой таблицы является простым, гарантирует, что время выполнения запросов будет быстрее, чем если бы те же вычисления выполнялись над исходными данными, перенос вычислений (а значит, и задержку запроса) с времени запроса на время вставки.
Материализованные представления в ClickHouse обновляются в реальном времени, по мере поступления данных в таблицу, на основе которой они созданы, функционируя скорее как постоянно обновляемые индексы. Это в контрасте с другими базами данных, где Материализованные Представления обычно представляют собой статические снимки запроса, которые необходимо обновлять (аналогично Обновляемым Материализованным Представлениям в ClickHouse).
Пример
Для примера мы воспользуемся набором данных Stack Overflow, описанным в "Дизайн схемы".
Предположим, мы хотим получить количество голосов вверх и вниз за день по посту.
Это достаточно простой запрос в ClickHouse благодаря функции toStartOfDay:
Этот запрос уже быстр благодаря ClickHouse, но можем ли мы сделать лучше?
Если мы хотим вычислять это во время вставки с помощью Материализованного Представления, нам нужна таблица для получения результатов. Эта таблица должна хранить только 1 строку на день. Если обновление поступает для существующего дня, другие столбцы должны быть объединены в строку соответствующего дня. Для того чтобы это объединение инкрементальных состояний произошло, частичные состояния должны храниться для остальных столбцов.
Это требует специального типа движка в ClickHouse: SummingMergeTree. Он заменяет все строки с одинаковым ключом сортировки одной строкой, которая содержит суммы для числовых столбцов. Следующая таблица будет объединять любые строки с одинаковой датой, суммируя все числовые столбцы:
Чтобы продемонстрировать наше Материализованное Представление, предположим, что наша таблица votes пуста и ещё не получила никаких данных. Наше Материализованное Представление выполняет вышеприведённый SELECT на данные, вставляемые в votes, с результатами, отправляемыми в up_down_votes_per_day:
Клаузула TO здесь является ключевой, указывая, куда будут отправляться результаты, т.е. up_down_votes_per_day.
Мы можем повторно заполнить нашу таблицу votes, используя ранее сделанную вставку:
По завершении мы можем подтвердить размер нашей таблицы up_down_votes_per_day — у нас должно быть 1 строка на день:
Мы эффективно снизили количество строк здесь с 238 миллионов (в votes) до 5000, сохранив результат нашего запроса. Однако ключевым моментом здесь является то, что если новые голоса будут вставлены в таблицу votes, новые значения будут отправлены в up_down_votes_per_day для их соответствующего дня, где они будут автоматически объединены асинхронно в фоновом режиме — сохраняя только одну строку на день. Таким образом, up_down_votes_per_day всегда будет и небольшой, и актуальной.
Поскольку объединение строк происходит асинхронно, может быть более одного голоса за день, когда пользователь запрашивает. Чтобы гарантировать, что все ожидающие строки объединены на момент выполнения запроса, у нас есть два варианта:
- Использовать модификатор
FINALв названии таблицы. Мы сделали это для запроса подсчета выше. - Аггрегировать по ключу сортировки, использованному в нашей конечной таблице, т.е.
CreationDateи суммировать метрики. Обычно это более эффективно и гибко (таблицу можно использовать для других вещей), но первый вариант может быть проще для некоторых запросов. Мы показываем оба ниже:
Это ускорило наш запрос с 0.133с до 0.004с — улучшение более чем в 25 раз!
ORDER BY = GROUP BYВ большинстве случаев столбцы, используемые в клаузе GROUP BY трансформации Материализованных Представлений, должны соответствовать столбцам, используемым в клаузе ORDER BY целевой таблицы, если используются движки таблиц SummingMergeTree или AggregatingMergeTree. Эти движки полагаются на столбцы ORDER BY для объединения строк с одинаковыми значениями во время фоновых операций объединения. Несоответствие между столбцами GROUP BY и ORDER BY может привести к неэффективной производительности запросов, неоптимальным объединениям или даже к несоответствиям данных.
Более сложный пример
Предыдущий пример использует Материализованные Представления для вычисления и поддержания двух сумм за день. Суммы представляют собой простейшую форму агрегации для сохранения частичных состояний — мы можем просто добавлять новые значения к существующим значениям по мере их поступления. Однако Материализованные Представления ClickHouse могут использоваться для любого типа агрегации.
Предположим, мы хотим вычислить некоторые статистические данные для постов за каждый день: 99.9-й процентиль для Score и среднее значение CommentCount. Запрос для вычисления этого может выглядеть так:
Как и прежде, мы можем создать Материализованное Представление, которое выполняет вышеупомянутый запрос, как только новые посты будут вставлены в нашу таблицу posts.
Для целей примера и чтобы избежать загрузки данных постов из S3, мы создадим дубликат таблицы posts_null с такой же схемой, как и posts. Однако эта таблица не будет хранить никаких данных и будет использоваться Материализованным Представлением при вставке строк. Чтобы предотвратить хранение данных, мы можем использовать тип движка Null.
Движок таблицы Null является мощной оптимизацией — думайте об этом как о /dev/null. Наше Материализованное Представление будет вычислять и хранить наши сводные статистики, когда таблица posts_null получает строки во время вставки — это всего лишь триггер. Однако сырые данные не будут храниться. Хотя в нашем случае, мы, вероятно, все же хотим хранить оригинальные посты, этот подход может быть использован для вычисления агрегатов, избегая затрат на хранение сырых данных.
Таким образом, Материализованное Представление становится:
Обратите внимание, как мы добавляем суффикс State в конец наших агрегатных функций. Это гарантирует, что агрегатное состояние функции возвращается вместо окончательного результата. Это будет содержать дополнительную информацию, чтобы позволить этому частичному состоянию объединиться с другими состояниями. Например, в случае средней величины это будет включать количество и сумму столбца.
Частичные состояния агрегации необходимы для вычисления корректных результатов. Например, для вычисления средней величины, простое усреднение средних значений поддиапазонов дает неправильные результаты.
Теперь мы создадим целевую таблицу для этого представления post_stats_per_day, которая будет хранить эти частичные агрегатные состояния:
Хотя ранее SummingMergeTree был достаточен для хранения количеств, мы требуем более продвинутый тип движка для других функций: AggregatingMergeTree.
Чтобы убедиться, что ClickHouse знает, что агрегатные состояния будут храниться, мы определяем Score_quantiles и AvgCommentCount как тип AggregateFunction, указывая источник функции частичных состояний и тип их исходных столбцов. Как и в случае SummingMergeTree, строки с тем же значением ключа ORDER BY будут объединяться (Day в приведенном выше примере).
Чтобы заполнить нашу post_stats_per_day через наше Материализованное Представление, мы можем просто вставить все строки из posts в posts_null:
В производственной среде, вы, вероятно, прикрепите Материализованное Представление к таблице
posts. Мы использовалиposts_nullздесь, чтобы продемонстрировать таблицу null.
Наш окончательный запрос должен использовать суффикс Merge для наших функций (поскольку столбцы хранят частичные состояния агрегации):
Обратите внимание, что мы используем GROUP BY здесь вместо использования FINAL.
Другие приложения
Вышеописанное сосредоточено в основном на использовании Материализованных Представлений для инкрементного обновления частичных агрегатов данных, тем самым перемещая вычисления с времени запроса на время вставки. За пределами этого общего сценария Материализованные Представления имеют ряд других применений.
Фильтрация и преобразование
В некоторых ситуациях мы можем захотеть вставить только подсет строк и столбцов при вставке. В этом случае наша таблица posts_null могла бы получать вставки с запросом SELECT, фильтрующим строки перед вставкой в таблицу posts. Например, предположим, что мы хотели бы преобразовать столбец Tags в нашей таблице posts. Он содержит список имен тегов, разделенных символом " | ". Преобразуя их в массив, мы можем легче агрегировать по отдельным значениям тегов.
Мы могли бы выполнить это преобразование при выполнении
INSERT INTO SELECT. Материализованное Представление позволяет нам инкапсулировать эту логику в DDL ClickHouse и сохранять нашиINSERTпростыми, с преобразованием, применяемым к любым новым строкам.
Наше Материализованное Представление для этого преобразования показано ниже:
Таблица справочников
Пользователи должны учитывать свои шаблоны доступа при выборе ключа сортировки ClickHouse. Столбцы, которые часто используются в фильтрах и агрегационных клаузах, должны использоваться. Это может быть ограничивающим для сценариев, где пользователи имеют более разнообразные шаблоны доступа, которые не могут быть инкапсулированы в одном наборе столбцов. Например, рассмотрим следующую таблицу comments:
Ключ сортировки здесь оптимизирует таблицу для запросов, которые фильтруют по PostId.
Предположим, что пользователь желает фильтровать по конкретному UserId и вычислить среднее значение Score:
Хотя это быстро (данные невелики для ClickHouse), мы можем видеть, что это требует полной проверки таблицы из-за количества обработанных строк — 90.38 миллиона. Для более крупных наборов данных мы можем использовать Материализованное Представление для поиска значений ключей сортировки PostId для фильтрации по столбцу UserId. Эти значения впоследствии могут быть использованы для выполнения эффективного поиска.
В этом примере наше Материализованное Представление может быть очень простым, выбирая только PostId и UserId из comments при вставке. Эти результаты затем отправляются в таблицу comments_posts_users, которая отсортирована по UserId. Мы создаем нулевую версию таблицы Comments ниже и используем это для заполнения нашего представления и таблицы comments_posts_users:
Теперь мы можем использовать это представление в подзапросе для ускорения нашего предыдущего запроса:
Цепочки
Материализованные представления могут быть связаны, что позволяет устанавливать сложные рабочие процессы. Для практического примера мы рекомендуем прочитать этот блог-пост.
Материализованные Представления и JOINs
Следующее применимо только к Инкрементным Материализованным Представлениям. Обновляемые Материализованные Представления периодически выполняют свой запрос по всей целевой выборке данных и полностью поддерживают JOINs. Рассматривайте их использование для сложных JOINs, если снижение свежести результата можно будет допустить.
Инкрементные Материализованные Представления в ClickHouse полностью поддерживают операции JOIN, но с одним важным ограничением: Материализованное Представление срабатывает только при вставках в исходную таблицу (самую левую таблицу в запросе). Таблицы правой стороны в JOIN не вызывают обновления, даже если их данные меняются. Это поведение особенно важно при создании Инкрементных Материализованных Представлений, где данные агрегируются или преобразуются во время вставки.
Когда Инкрементное Материализованное Представление определяется с использованием JOIN, самая левая таблица в запросе SELECT выступает в качестве источника. Когда в эту таблицу вставляются новые строки, ClickHouse выполняет запрос Материализованного Представления только с недавно вставленных строк. Таблицы правой стороны в JOIN считываются полностью во время этого выполнения, но изменения в них сами по себе не вызывают обновление представления.
Такое поведение делает JOINs в Материализованных Представлениях похожими на снимок соединения с статичными данными измерений.
Это хорошо работает для обогащения данных с помощью справочных или измерительных таблиц. Однако любые обновления таблиц правой стороны (например, метаданные пользователей) не будут ретроактивно обновляться в Материализованном Представлении. Чтобы увидеть обновленные данные, новые вставки должны поступить из исходной таблицы.
Пример
Давайте пройдёмся по конкретному примеру с использованием набора данных Stack Overflow. Мы будем использовать Материализованное Представление, чтобы вычислить ежедневные медали для пользователей, включая отображаемое имя пользователя из таблицы users.
В качестве напоминания, наши схемы таблиц таковы:
Мы предполагаем, что таблица users предварительно заполнена:
Материализованное Представление и связанная с ним целевая таблица определены как:
Клаузула GROUP BY в Материализованном Представлении должна включать DisplayName, UserId и Day, чтобы соответствовать ORDER BY в целевой таблице SummingMergeTree. Это гарантирует правильную агрегацию и объединение строк. Пропуск любого из этих может привести к неправильным результатам или неэффективным объединениям.
Теперь, если мы заполним медали, представление будет активировано — заполнив нашу таблицу daily_badges_by_user.
Предположим, что мы хотим увидеть медали, полученные конкретным пользователем, мы можем написать следующий запрос:
Теперь, если этот пользователь получает новую медаль и вставляется строка, наше представление будет обновлено:
Обратите внимание на задержку вставки здесь. Вставленная строка пользователя соединяется с полной таблицей users, что значительно влияет на производительность вставки. Мы предлагаем подходы для решения этой проблемы ниже в разделе "Использование исходной таблицы в фильтрах и соединениях".
С другой стороны, если мы вставляем медаль для нового пользователя, а затем строку для пользователя, наше Материализованное Представление не сможет зафиксировать метрики пользователей.
В этом случае представление выполняется только для вставки медали до того, как строка пользователя существует. Если мы вставим другую медаль для этого пользователя, строка вставляется, как и ожидалось:
Обратите внимание, однако, что этот результат неверен.
Лучшие практики для JOINs в Материализованных Представлениях
-
Используйте самую левую таблицу как триггер. Только таблица с левой стороны оператора
SELECTвызывает Материализованное Представление. Изменения в таблицах правой стороны не вызовут обновления. -
Предварительно вставьте соединенные данные. Убедитесь, что данные в объединенных таблицах существуют перед вставкой строк в исходную таблицу. JOIN вычисляется во время вставки, поэтому недостающие данные приведут к несоответствующим строкам или нулям.
-
Ограничьте столбцы, извлекаемые из соединений. Выбирайте только необходимые столбцы из объединенных таблиц, чтобы минимизировать использование памяти и уменьшить задержку при вставке (см. ниже).
-
Оцените производительность вставки. JOINs увеличивают стоимость вставок, особенно с большими таблицами правой стороны. Проведите тестирование скорости вставок, используя репрезентативные производственные данные.
-
Предпочитайте словари для простых запросов. Используйте Словари для поиска по ключу-значению (например, ID пользователя к имени), чтобы избежать дорогостоящих JOIN операций.
-
Согласуйте
GROUP BYиORDER BYдля эффективности объединений. При использованииSummingMergeTreeилиAggregatingMergeTreeубедитесь, чтоGROUP BYсовпадает с клаузойORDER BYв целевой таблице, чтобы обеспечить эффективное объединение строк. -
Используйте явные имена столбцов. Когда таблицы имеют перекрывающиеся имена столбцов, используйте псевдонимы, чтобы предотвратить двусмысленность и обеспечить правильные результаты в целевой таблице.
-
Учитывайте объем и частоту вставок. JOINs хорошо работают при умеренной нагрузке вставки. Для интенсивного потока ввода данных рассмотрите возможность использования промежуточных таблиц, предварительных соединений или других подходов, таких как Словари и Обновляемые Материализованные Представления.
Использование исходной таблицы в фильтрах и соединениях
При работе с Материализованными Представлениями в ClickHouse важно понимать, как исходная таблица обрабатывается во время выполнения запроса Материализованного Представления. В частности, исходная таблица в запросе Материализованного Представления заменяется вставленным блоком данных. Это поведение может привести к некоторым неожиданным результатам, если его не понимать должным образом.
Пример сценария
Рассмотрим следующую настройку:
Объяснение
В приведенном выше примере у нас есть два Материализованных Представления mvw1 и mvw2, которые выполняют похожие операции, но с небольшим различием в том, как они ссылаются на исходную таблицу t0.
В mvw1 таблица t0 напрямую ссылается внутри подзапроса (SELECT * FROM t0) с правой стороны JOIN. Когда данные вставляются в t0, запрос Материализованного Представления выполняется с вставленным блоком данных, заменяющим t0. Это означает, что операция JOIN выполняется только над вновь вставленными строками, а не над всей таблицей.
Во втором случае, когда присоединяется vt0, представление считывает все данные из t0. Это гарантирует, что операция JOIN учитывает все строки в t0, а не только вновь вставленный блок.
Ключевое различие заключается в том, как ClickHouse обрабатывает исходную таблицу в запросе Материализованного Представления. Когда Материализованное Представление вызывается вставкой, исходная таблица (t0 в данном случае) заменяется вставленным блоком данных. Это поведение можно использовать для оптимизации запросов, но оно также требует тщательного рассмотрения, чтобы избежать неожиданного результата.
Сценарии использования и предостережения
На практике вы можете использовать это поведение для оптимизации материализованных представлений, которые необходимо обрабатывать только для подмножества данных исходной таблицы. Например, вы можете использовать подзапрос для фильтрации исходной таблицы перед объединением ее с другими таблицами. Это может помочь сократить объем обрабатываемых данных и улучшить производительность.
В этом примере множество, построенное из подзапроса IN (SELECT id FROM t0), содержит только новые вставленные строки, что может помочь отфильтровать t1.
Пример со Stack Overflow
Рассмотрим наш предыдущий пример материализованного представления для вычисления ежедневных значков на пользователя, включая отображаемое имя пользователя из таблицы users.
Это представление значительно повлияло на задержку вставки в таблицу badges, например:
Используя вышеуказанный подход, мы можем оптимизировать это представление. Мы добавим фильтр к таблице users, используя идентификаторы пользователей в вставленных строках значков:
Это не только ускоряет первую вставку значков:
Но также делает будущие вставки значков эффективными:
В вышеуказанной операции только одна строка извлекается из таблицы users для идентификатора пользователя 2936484. Этот поиск также оптимизируется с учетом ключа сортировки Id.
Материализованные представления и объединения
UNION ALL запросы часто используются для объединения данных из нескольких исходных таблиц в один результирующий набор.
Хотя UNION ALL не поддерживается напрямую в инкрементных материализованных представлениях, вы можете добиться того же результата, создав отдельное материализованное представление для каждого SELECT узла и записывая их результаты в общую целевую таблицу.
Для нашего примера мы будем использовать набор данных Stack Overflow. Рассмотрим таблицы badges и comments ниже, которые представляют собой знаки, заработанные пользователем, и комментарии, которые они оставляют к постам:
Эти таблицы можно заполнить следующими командами INSERT INTO:
Предположим, что мы хотим создать объединенное представление активности пользователя, показывающее последнюю активность каждого пользователя, объединив эти две таблицы:
Предположим, что у нас есть целевая таблица, чтобы получить результаты этого запроса. Обратите внимание на использование AggregatingMergeTree движка таблицы и AggregateFunction, чтобы гарантировать правильное объединение результатов:
Хотя мы хотим, чтобы эта таблица обновлялась при вставке новых строк как в badges, так и в comments, наивный подход к этой проблеме может заключаться в попытке создать материализованное представление с предыдущим запросом объединения:
Хотя это валидно с синтаксической точки зрения, это приведет к нежелательным результатам - представление будет вызывать вставки только в таблицу comments. Например:
Вставки в таблицу badges не вызовут обновления представления, что приводит к тому, что user_activity не получает обновления:
Чтобы решить эту проблему, мы просто создаем материализованное представление для каждого оператора SELECT:
Теперь вставка в любую из таблиц приводит к получению правильных результатов. Например, если мы вставим в таблицу comments:
Аналогично, вставки в таблицу badges отражаются в таблице user_activity:
Параллельная обработка против последовательной обработки
Как показано в предыдущем примере, таблица может выступать в качестве источника для нескольких материализованных представлений. Порядок их выполнения зависит от настройки parallel_view_processing.
По умолчанию эта настройка равна 0 (false), что означает, что материализованные представления выполняются последовательно в порядке uuid.
Например, рассмотрим следующую таблицу source и 3 материализованных представления, каждое из которых отправляет строки в таблицу target:
Обратите внимание, что каждое из представлений приостанавливается на 1 секунду перед вставкой своих строк в таблицу target, а также включает свое имя и время вставки.
Вставка строки в таблицу source занимает ~3 секунды, при этом каждое представление выполняется последовательно:
Мы можем подтвердить приход строк из каждого представления с помощью SELECT:
Это соответствует uuid представлений:
Напротив, рассмотрим, что произойдет, если мы вставим строку с включенной настройкой parallel_view_processing=1. С включенной этой настройкой представления выполняются параллельно, не давая гарантий порядка, в котором строки попадают в таблицу target:
Хотя порядок поступления строк из каждого представления остается тем же, это не гарантируется, как показывает схожесть времени вставки каждой строки. Также стоит отметить улучшенную производительность вставки.
Когда использовать параллельную обработку
Включение parallel_view_processing=1 может значительно улучшить throughput вставки, как показано выше, особенно когда несколько материализованных представлений подключены к одной таблице. Тем не менее, важно понимать компромиссы:
- Увеличенное давление на вставки: Все материализованные представления выполняются одновременно, увеличивая использование CPU и памяти. Если каждое представление выполняет тяжелые вычисления или JOIN, это может перегрузить систему.
- Необходимость строгого порядка выполнения: В редких рабочих процессах, где порядок выполнения представлений имеет значение (например, связанные зависимости), параллельное выполнение может привести к несогласованному состоянию или условиям гонки. Хотя это возможно обойти, такие настройки хрупки и могут сломаться с будущими версиями.
Последовательное выполнение долгое время было значением по умолчанию, отчасти из-за сложности обработки ошибок. Исторически сбой в одном материализованном представлении мог предотвратить выполнение других. Новые версии улучшили это, изолируя сбои по блокам, но последовательное выполнение все еще предоставляет более четкие семантики ошибок.
В общем, включайте parallel_view_processing=1, когда:
- У вас есть несколько независимых материализованных представлений
- Вы хотите максимизировать производительность вставки
- Вы осведомлены о способности системы обрабатывать параллельное выполнение представлений
Оставляйте его выключенным, когда:
- Материализованные представления зависят друг от друга
- Вам требуется предсказуемое, упорядоченное выполнение
- Вы отлаживаете или проверяете поведение вставки и хотите детерминированное воспроизведение
Материализованные представления и общие табличные выражения (CTEs)
Некоррекционные общие табличные выражения (CTEs) поддерживаются в материализованных представлениях.
ClickHouse не материализует CTE; вместо этого он напрямую вставляет определение CTE в запрос, что может привести к нескольким evaluations одного и того же выражения (если CTE используется более одного раза).
Рассмотрим следующий пример, который вычисляет ежедневную активность для каждого типа поста.
Хотя CTE здесь строго не необходим, для примера представление будет работать, как и ожидалось:
В ClickHouse CTE встраиваются, что означает, что они фактически копируются в запрос во время оптимизации и не материализуются. Это означает, что:
- Если ваш CTE ссылается на другую таблицу, отличную от исходной таблицы (то есть той, к которой прикреплено материализованное представление), и используется в условии
JOINилиIN, он будет вести себя как подзапрос или соединение, а не как триггер. - Материализованное представление все еще будет вызывать вставки только в основную исходную таблицу, но CTE будет повторно выполняться на каждой вставке, что может вызвать ненужные затраты, особенно если запрашиваемая таблица велика.
Например,
В этом случае CTE пользователей повторно оценивается при каждой вставке в посты, а материализованное представление не будет обновляться при вставке новых пользователей - только при вставке постов.
В общем, используйте CTE для логики, которая работает с той же исходной таблицей, к которой прикреплено материализованное представление, или убедитесь, что запрашиваемые таблицы малы и вряд ли вызовут узкие места производительности. В качестве альтернативы рассмотрите те же оптимизации, что и для JOIN с материализованными представлениями.
