Хранилища данных
Современное хранилище данных больше не предполагает жёсткой связки хранения и вычислений. Вместо этого отдельные, но взаимосвязанные слои хранения, управления и обработки запросов дают вам гибкость в выборе подходящих инструментов для ваших рабочих процессов.
Добавив открытые табличные форматы и высокопроизводительный движок запросов, такой как ClickHouse, к облачному объектному хранилищу, вы получаете возможности уровня баз данных — ACID-транзакции, контроль схемы и быстрые аналитические запросы — не жертвуя при этом открытостью ваших озер данных. Такое сочетание объединяет производительность с совместимым и экономичным хранением для традиционной аналитики и современных AI/ML-нагрузок.
Что даёт эта архитектура
Объединяя открытое объектное хранилище и табличные форматы с ClickHouse в качестве движка запросов, вы получаете:
| Преимущество | Описание |
|---|---|
| Согласованные обновления таблиц | Атомарные фиксации состояния таблицы означают, что параллельные записи не приводят к повреждению данных или появлению частично записанных данных. Это решает одну из самых серьёзных проблем сырых озер данных. |
| Управление схемой | Принудительная валидация и отслеживаемая эволюция схемы предотвращают проблему «болота данных», когда данные становятся непригодными к использованию из-за несогласованности схем. |
| Производительность запросов | Индексирование, статистика и оптимизация размещения данных, такие как пропуск данных и кластеризация, позволяют SQL-запросам выполняться со скоростью, сопоставимой со специализированным хранилищем данных. В сочетании со столбцовым движком ClickHouse это справедливо даже для данных, хранящихся в объектном хранилище. |
| Управление доступом и соответствием | Каталоги и табличные форматы обеспечивают детализированное управление доступом и аудит на уровне строк и столбцов, устраняя ограничения базовых озер данных в части механизмов безопасности. |
| Разделение хранения и вычислений | Хранение и вычисления масштабируются независимо на базе стандартного объектного хранилища, которое значительно дешевле, чем проприетарное хранилище для хранилищ данных. Хотя такое разделение является стандартом в современных облачных хранилищах данных, открытые форматы позволяют выбирать, какой вычислительный движок будет масштабироваться вместе с вашими данными. |
Как ClickHouse обеспечивает работу вашего хранилища данных
Данные поступают из потоковых платформ и существующих хранилищ через Объектное хранилище в ClickHouse, где они преобразуются, оптимизируются и становятся доступными для ваших BI/AI-инструментов.
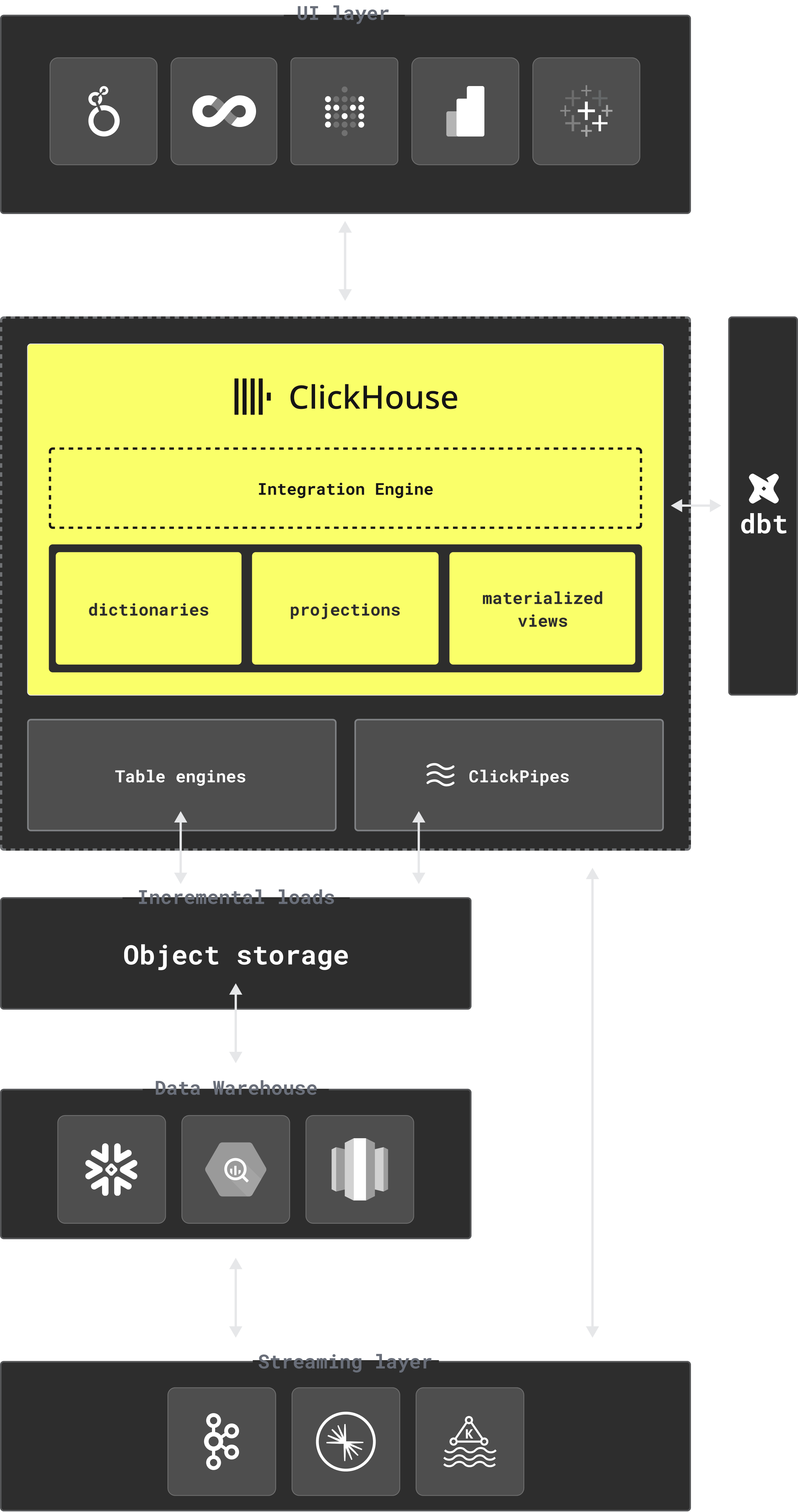
ClickHouse охватывает четыре ключевых этапа работы хранилища данных: загрузку данных, выполнение запросов, преобразование данных и подключение к инструментам, которые уже использует ваша команда.
Ингестия данных
Для массовой загрузки данных обычно используют Объектное хранилище, например S3 или GCS, в качестве промежуточного слоя. Высокая производительность чтения Parquet в ClickHouse позволяет загружать данные со скоростью в сотни миллионов строк в секунду с помощью табличного движка S3. Для потоковой передачи в реальном времени ClickPipes подключается напрямую к таким платформам, как Kafka и Confluent.
Вы также можете мигрировать из существующих хранилищ данных, таких как Snowflake, BigQuery и Databricks, экспортируя данные в Объектное хранилище и загружая их в ClickHouse через Движки таблиц.
Выполнение запросов
Вы можете выполнять запросы к данным напрямую в Объектном хранилище, таком как S3 и GCS, или в озерах данных с открытыми табличными форматами, такими как Iceberg, Delta Lake и Hudi. Подключаться к этим форматам можно напрямую или через каталоги данных, такие как AWS Glue Catalog, Unity Catalog и Iceberg REST.
Запросы к materialized views выполняются быстро, поскольку их агрегированные результаты автоматически сохраняются в отдельных таблицах, что ускоряет последующие запросы независимо от объема анализируемых данных. Тогда как другие поставщики баз данных скрывают возможности ускорения за более дорогими тарифами или дополнительной платой, ClickHouse Cloud предоставляет кэш запросов, разреженные индексы и проекции из коробки для повторяющихся запросов и запросов, чувствительных к задержкам.
ClickHouse поддерживает более 70 форматов файлов и SQL-функции для работы с датами, массивами, JSON, геоданными и приближенными агрегациями в большом масштабе.
Преобразование данных
Преобразование данных — один из ключевых элементов рабочих процессов business intelligence и аналитики. Materialized views в ClickHouse автоматизируют эти процессы: эти представления на основе SQL срабатывают при вставке новых данных в исходные таблицы, поэтому вы можете извлекать, агрегировать и изменять данные по мере их поступления без создания и сопровождения специализированных конвейеров преобразования.
Для более сложных сценариев моделирования интеграция dbt в ClickHouse позволяет определять преобразования как SQL-модели с контролем версий и переносить существующие задачи dbt для выполнения непосредственно в ClickHouse.
Интеграции
ClickHouse имеет нативные коннекторы для BI-инструментов, таких как Tableau и Looker. Инструменты без нативного коннектора могут подключаться через протокол MySQL без дополнительной настройки. Для рабочих процессов с семантическим слоем ClickHouse интегрируется с Cube, позволяя вашей команде один раз определить метрики и затем запрашивать их из любого нижележащего инструмента. Компании в сфере финансовых услуг, игр, e-commerce и других отраслях используют эти интеграции, чтобы извлекать пользу из данных сразу после их поступления, обеспечивая работу панелей мониторинга в реальном времени и процессов business intelligence.
ClickHouse также поддерживает REST-интерфейс, поэтому вы можете создавать легковесные приложения без сложных бинарных протоколов. MCP-сервер подключает ClickHouse к LLM для диалоговой аналитики через такие инструменты, как LibreChat или Claude. Гибкие средства управления RBAC и квотами позволяют публично открывать таблицы только для чтения для выборки данных на стороне клиента.
Гибридная архитектура: лучшее из двух миров
Помимо выполнения запросов к вашим озерам данных, вы можете загружать критичные к производительности данные в нативное хранилище MergeTree ClickHouse для сценариев использования, требующих сверхнизкой задержки, — таких как панели мониторинга в реальном времени, операционная аналитика или интерактивные приложения.
Это даёт вам многоуровневую стратегию работы с данными. Горячие, часто используемые данные хранятся в оптимизированном хранилище ClickHouse, обеспечивая выполнение запросов за доли секунды, тогда как полная история данных остаётся в озере и по-прежнему доступна для запросов. Вы также можете использовать materialized view в ClickHouse, чтобы непрерывно преобразовывать и агрегировать данные из озера в оптимизированные таблицы, автоматически связывая два уровня.
Вы сами выбираете, где хранятся данные, исходя из требований к производительности, а не технических ограничений.
Пройдите бесплатный курс Data Warehousing with ClickHouse, чтобы узнать больше. :::”}]}
