Используйте индексы пропуска данных там, где это уместно
Индексы пропуска данных следует рассматривать после того, как соблюдены предыдущие рекомендации по лучшим практикам, то есть оптимизированы типы, выбран хороший первичный ключ и задействованы материализованные представления. Если вы впервые сталкиваетесь с индексами пропуска, это руководство — хорошая отправная точка.
Эти типы индексов могут использоваться для ускорения выполнения запросов, если применять их осторожно и с пониманием того, как они работают.
ClickHouse предоставляет мощный механизм под названием индексы пропуска данных, который может значительно сократить объем данных, сканируемых при выполнении запроса — особенно когда первичный ключ не помогает для конкретного условия фильтрации. В отличие от традиционных баз данных, полагающихся на строковые вторичные индексы (например, B-деревья), ClickHouse является колоночным хранилищем и не хранит расположения строк в формате, подходящем для таких структур. Вместо этого он использует индексы пропуска, которые помогают избегать чтения блоков данных, заведомо не соответствующих условиям фильтрации запроса.
Индексы пропуска работают за счет хранения метаданных о блоках данных — таких как минимальные/максимальные значения, множества значений или представления в виде фильтра Блума — и использования этих метаданных при выполнении запроса для определения того, какие блоки данных можно полностью пропустить. Они применимы только к семейству движков таблиц MergeTree и определяются при помощи выражения, типа индекса, имени и гранулярности, задающей размер каждого индексируемого блока. Эти индексы хранятся вместе с данными таблицы и используются, когда фильтр запроса соответствует выражению индекса.
Существует несколько типов индексов пропуска данных, каждый из которых подходит для разных типов запросов и распределений данных:
- minmax: Отслеживает минимальное и максимальное значение выражения на блок. Идеально подходит для диапазонных запросов по слабо отсортированным данным.
- set(N): Отслеживает множество значений размером до N для каждого блока. Эффективен для столбцов с низкой кардинальностью внутри блоков.
- text: Создает инвертированный индекс по токенизированным строковым данным, обеспечивая эффективный и детерминированный полнотекстовый поиск. Рекомендуется для столбцов с естественным языком или большим свободным текстом, когда вместо приближенных подходов на основе фильтра Блума требуются точный поиск по токенам и масштабируемый многотерминный поиск.
- bloom_filter: Вероятностно определяет, существует ли значение в блоке, обеспечивая быстрое приближенное фильтрование по принадлежности к множеству. Эффективен для оптимизации запросов, которые ищут «иглу в стоге сена», где требуется положительное совпадение.
- tokenbf_v1 / ngrambf_v1: (Устарело) Специализированные варианты фильтра Блума, предназначенные для поиска токенов или последовательностей символов в строках — особенно полезны для логов или сценариев полнотекстового поиска. Устарели в версиях ClickHouse >= 26.2 в пользу текстовых индексов.
Несмотря на мощь, индексы пропуска нужно использовать осторожно. Они приносят пользу только тогда, когда позволяют исключить значимое количество блоков данных, и могут, наоборот, вносить дополнительный оверхед, если структура запроса или данных не соответствует их модели. Если в блоке существует хотя бы одно подходящее значение, весь этот блок все равно должен быть прочитан.
Эффективное использование индексов пропуска часто зависит от сильной корреляции между индексируемым столбцом и первичным ключом таблицы либо от вставки данных таким образом, чтобы схожие значения группировались вместе.
В целом, индексы пропуска данных лучше всего применять после того, как вы убедились в корректном проектировании первичного ключа и оптимизации типов. Они особенно полезны для:
- Столбцов с высокой общей кардинальностью, но низкой кардинальностью внутри блока.
- Редких значений, критичных для поиска (например, коды ошибок, конкретные идентификаторы).
- Случаев, когда фильтрация выполняется по непервичным столбцам с локализованным распределением.
Всегда:
- Тестируйте индексы пропуска на реальных данных с реалистичными запросами. Пробуйте разные типы индексов и значения гранулярности.
- Оценивайте их влияние с помощью инструментов, таких как send_logs_level='trace' и
EXPLAIN indexes=1, чтобы увидеть эффективность индекса. - Всегда оценивайте размер индекса и то, как на него влияет гранулярность. Уменьшение размера гранулярности часто улучшает производительность до определенного момента, поскольку больше гранул может быть отфильтровано и не потребует сканирования. Однако по мере роста размера индекса при меньшей гранулярности производительность также может снижаться. Измеряйте производительность и размер индекса для различных значений гранулярности. Это особенно актуально для индексов с фильтром Блума.
При корректном использовании индексы пропуска могут обеспечить существенный прирост производительности — при бездумном применении они могут добавить ненужные затраты.
Более подробное руководство по индексам пропуска данных смотрите здесь.
Пример
Рассмотрим следующую оптимизированную таблицу. Она содержит данные Stack Overflow, по одной строке на каждую публикацию.
Эта таблица оптимизирована для запросов, которые фильтруют и агрегируют данные по типу поста и дате. Предположим, что мы хотим посчитать количество постов с числом просмотров более 10 000 000, опубликованных после 2009 года.
Этот запрос может исключить часть строк (и гранул), используя первичный индекс. Однако основную часть строк всё равно необходимо прочитать, как видно из приведённого выше вывода и следующего результата команды EXPLAIN indexes = 1:
Простой анализ показывает, что ViewCount коррелирует с CreationDate (первичным ключом), как и следовало ожидать — чем дольше существует пост, тем больше времени его могут просматривать.
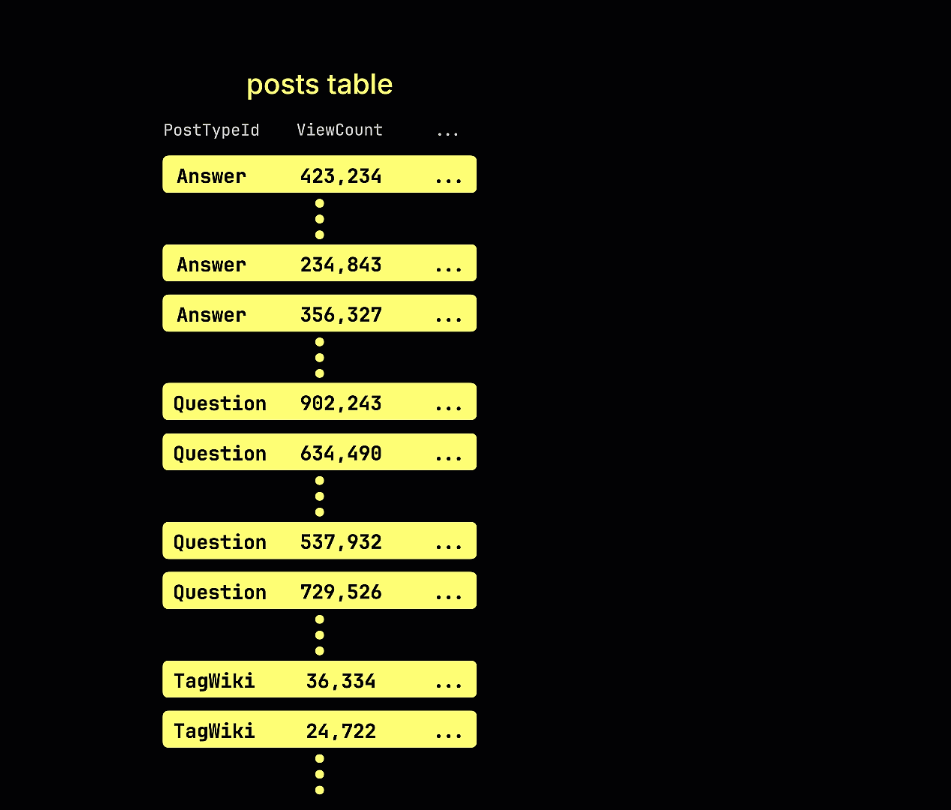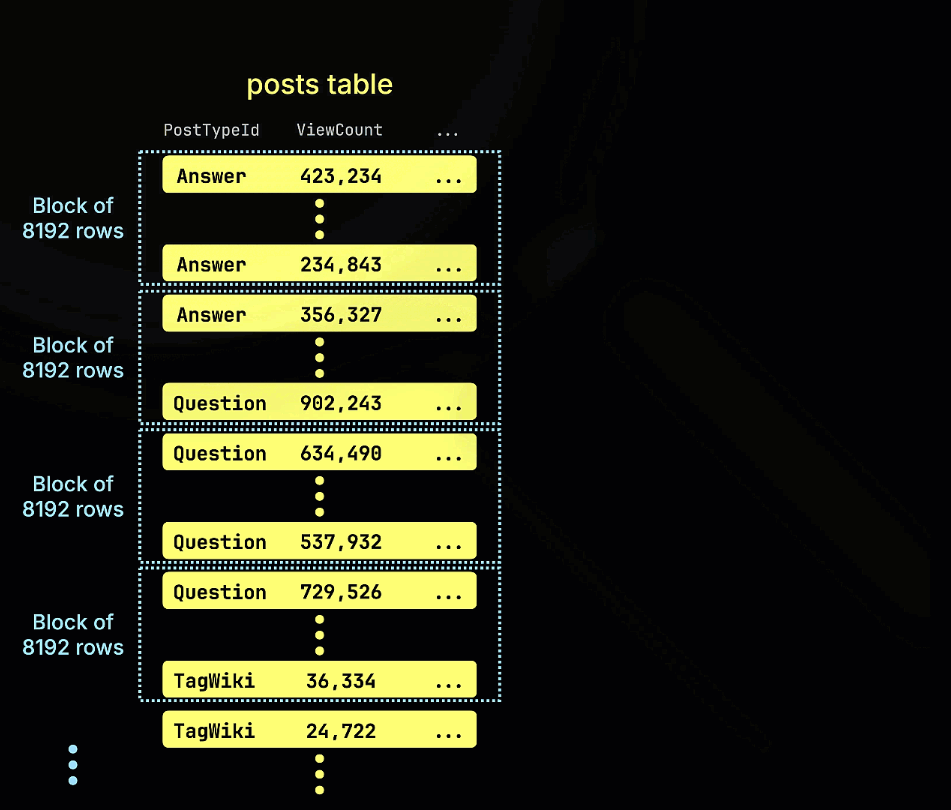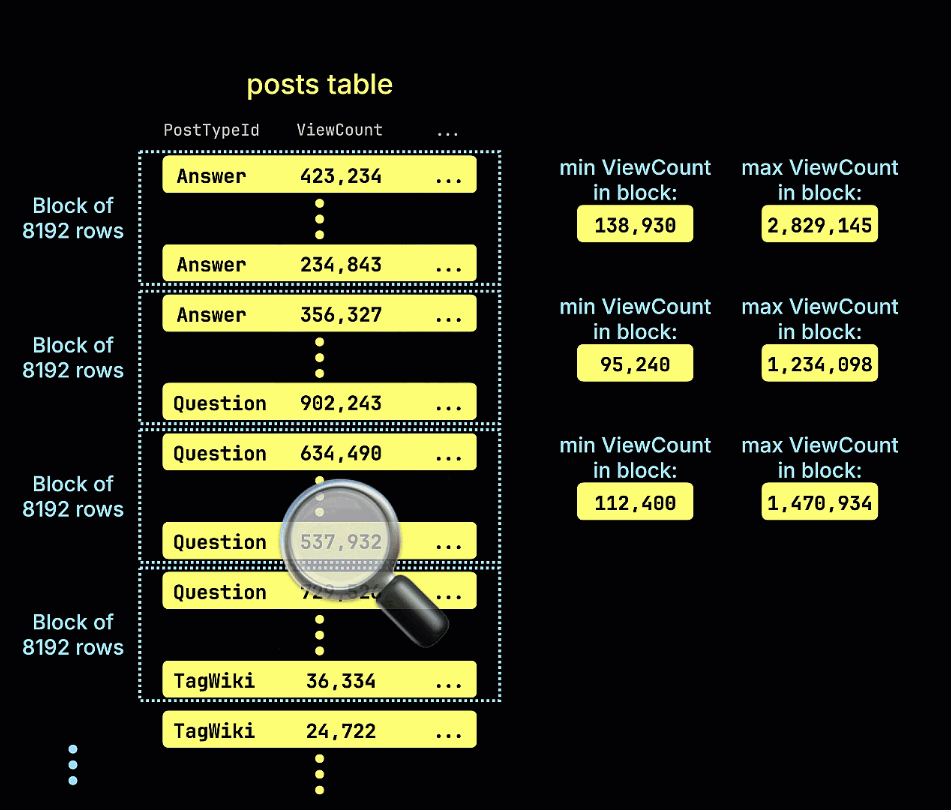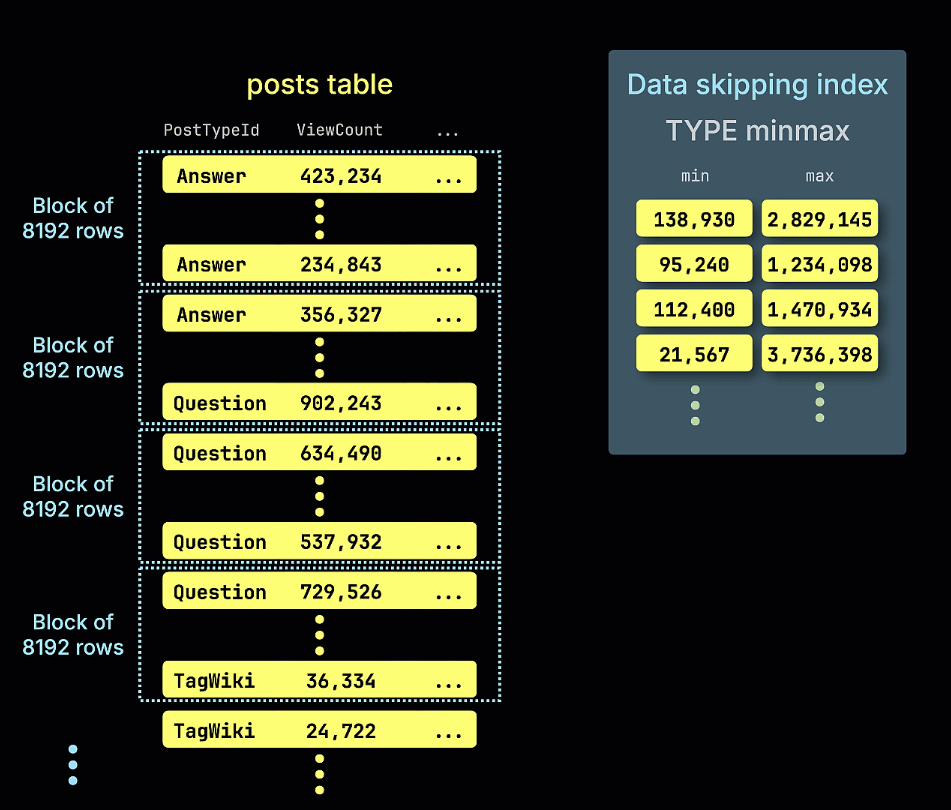
Поэтому это является логичным выбором для индекса пропуска данных. Учитывая числовой тип, имеет смысл использовать индекс minmax. Мы добавляем индекс с помощью следующих команд ALTER TABLE: сначала создаём его, затем «материализуем».
Этот индекс можно было также добавить при первоначальном создании таблицы. Схема с индексом minmax, определённым как часть DDL:
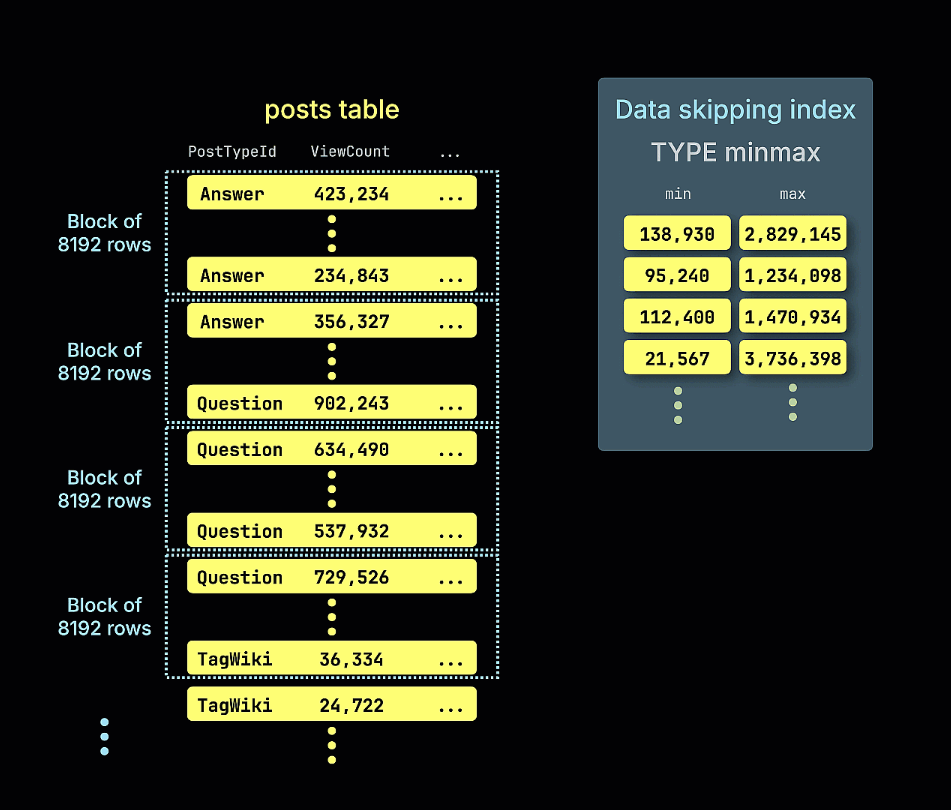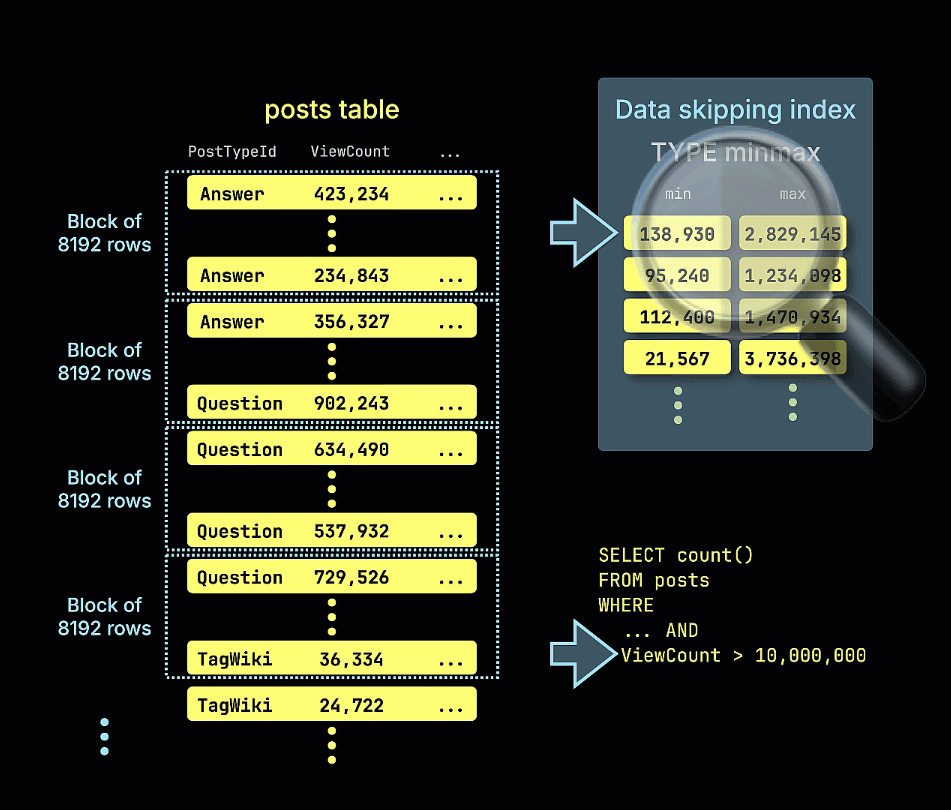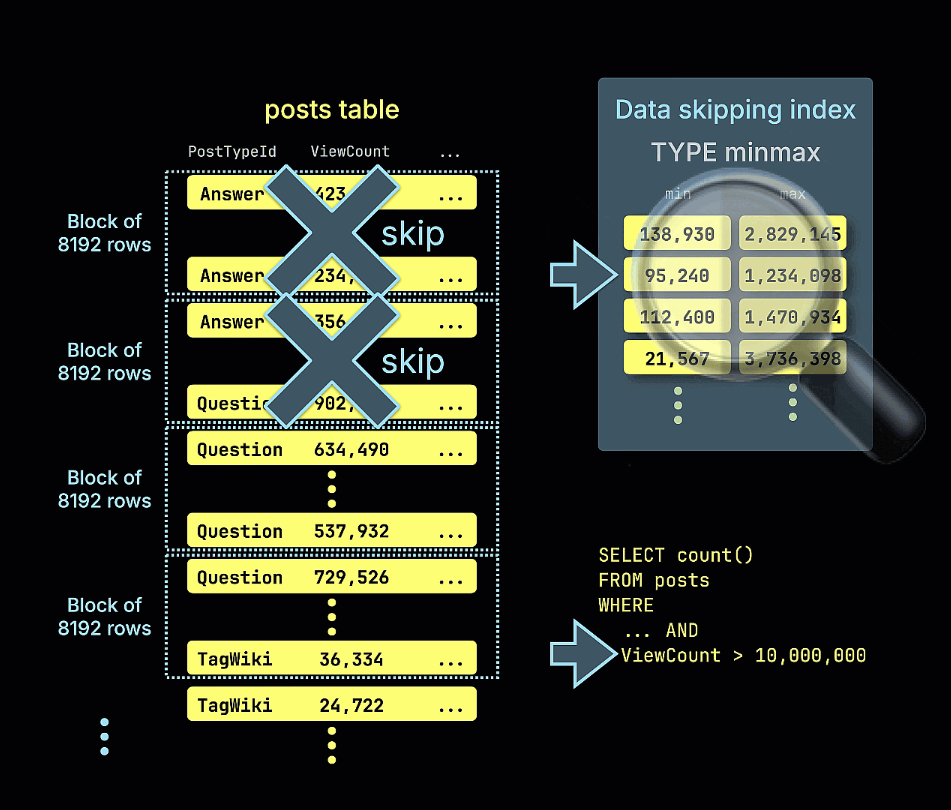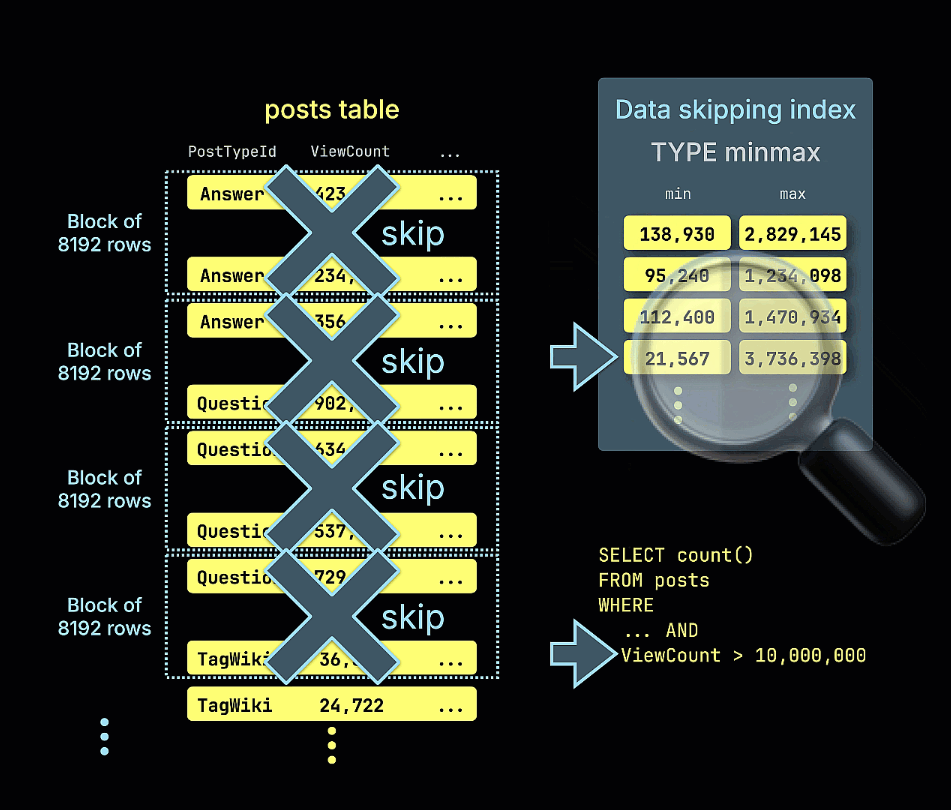
Следующая анимация иллюстрирует, как строится наш индекс пропуска minmax для таблицы из примера: при этом отслеживаются минимальные и максимальные значения ViewCount для каждого блока строк (гранулы) в таблице:
Повторив наш предыдущий запрос, мы увидим значительный прирост производительности. Обратите внимание на уменьшившееся количество сканируемых строк:
Запрос EXPLAIN indexes = 1 подтверждает, что используется индекс.
Также показана анимация того, как индекс пропуска minmax отсекает все блоки строк, которые заведомо не могут содержать совпадения для предиката ViewCount > 10,000,000 в нашем примере запроса: