Эффективная ингестия данных — основа высокопроизводительных развертываний ClickHouse. Выбор подходящей стратегии вставки может существенно повлиять на пропускную способность, стоимость и надёжность. В этом разделе рассматриваются лучшие практики, компромиссы и параметры конфигурации, которые помогут вам выбрать оптимальный вариант для вашей рабочей нагрузки.
Синхронные вставки по умолчанию
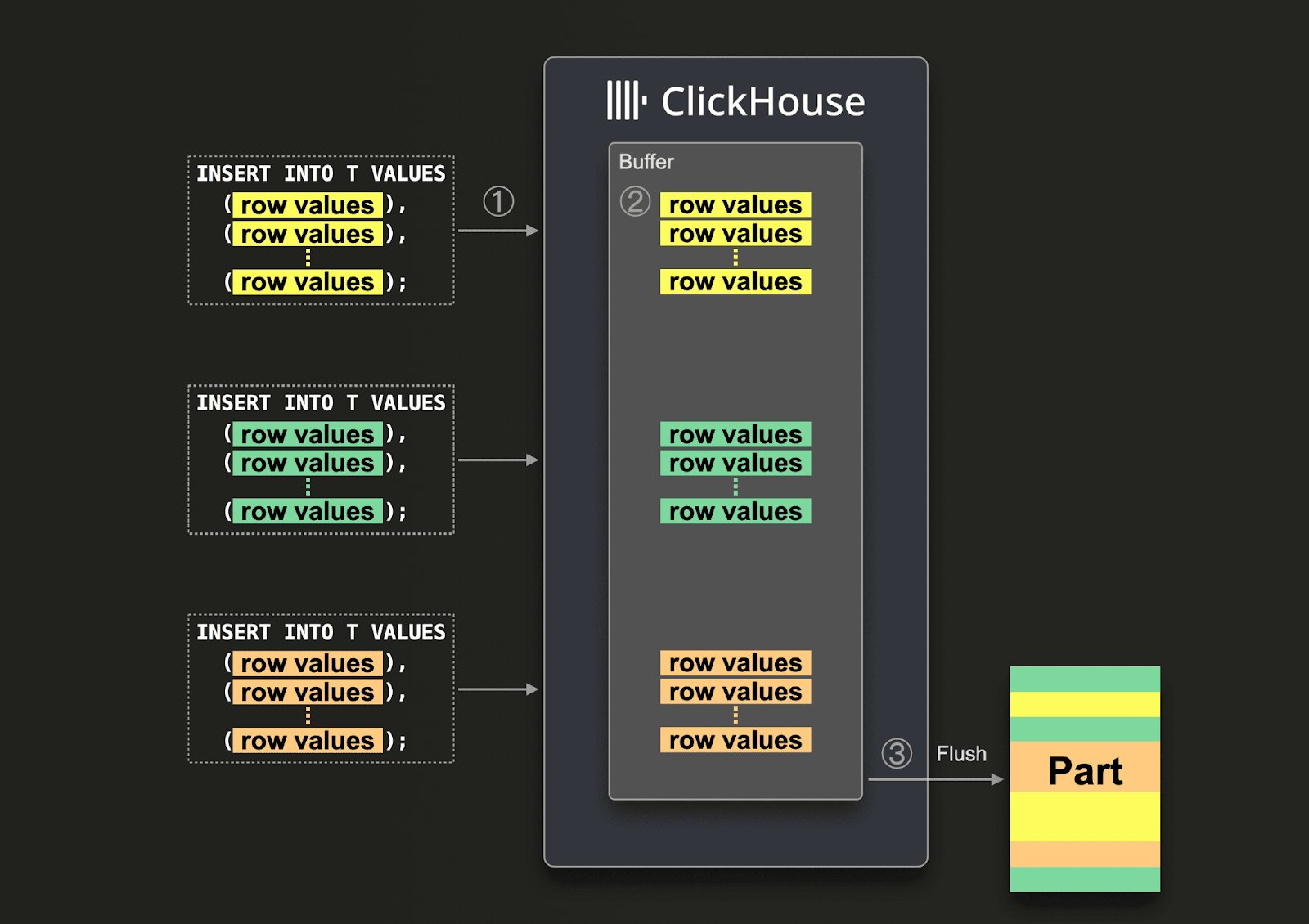
Используйте синхронные вставки, если можете батчировать данные на стороне клиентаЕсли нет, см. раздел Асинхронные вставки ниже. Батч-вставки при синхронной вставке
Независимо от размера вставок, мы рекомендуем поддерживать частоту запросов на вставку на уровне примерно одного запроса в секунду. Это связано с тем, что созданные части в фоновом режиме сливаются в более крупные (чтобы оптимизировать данные для запросов на чтение), и если отправлять слишком много запросов на вставку в секунду, фоновое слияние может не успевать за появлением новых частей. Однако при использовании асинхронных вставок можно работать с более высокой частотой запросов на вставку в секунду (см. Asynchronous inserts). Обеспечьте идемпотентность повторных попыток
- Вставка прошла успешно, но клиент не получил подтверждение из-за сбоя сети.
- Вставка завершилась ошибкой на стороне сервера и привела к тайм-ауту.
В обоих случаях повторить вставку безопасно — при условии, что содержимое батча и его порядок остаются неизменными. Поэтому крайне важно, чтобы клиенты выполняли повторные попытки последовательно, не изменяя и не переупорядочивая данные.
Выберите подходящую цель для вставки
- Выполнять вставку напрямую в таблицу MergeTree или ReplicatedMergeTree. Это самый эффективный вариант, если клиент может балансировать нагрузку между сегментами. При
internal_replication = true ClickHouse прозрачно управляет репликацией.
- Выполнять вставку в distributed таблицу. Это позволяет клиентам отправлять данные на любой узел, а ClickHouse сам перенаправит их в нужный сегмент. Это проще, но немного менее производительно из-за дополнительного шага перенаправления.
internal_replication = true по-прежнему рекомендуется.
В ClickHouse Cloud все узлы читают и записывают данные в один и тот же сегмент. Операции вставки автоматически балансируются между узлами. Вы можете просто отправлять их на доступную конечную точку.
Выбор подходящего входного формата крайне важен для эффективной ингестии данных в ClickHouse. При наличии более 70 поддерживаемых форматов выбор наиболее производительного варианта может существенно повлиять на скорость вставки, нагрузку на CPU и память, а также на общую эффективность системы.
Хотя гибкость полезна для инженерии данных и импорта из файлов, приложениям следует отдавать приоритет форматам, ориентированным на производительность:
- формат Native (рекомендуется): Наиболее эффективный вариант. Столбцовый формат, требует минимального разбора на стороне сервера. По умолчанию используется в Go- и Python-клиентах.
- RowBinary: Эффективный построчный формат, оптимален, если преобразование в столбцовый вид сложно выполнить на стороне клиента. Используется в Java-клиенте.
- JSONEachRow: Прост в использовании, но требует больших затрат на разбор. Подходит для сценариев с небольшими объёмами данных или быстрых интеграций.
Сжатие играет важную роль в снижении сетевых накладных расходов, ускорении вставки и сокращении затрат на хранение в ClickHouse. При правильном использовании оно повышает производительность ингестии, не требуя изменений формата данных или схемы.
Сжатие данных при вставке уменьшает размер полезной нагрузки, передаваемой по сети, снижая потребление пропускной способности и ускоряя передачу.
Для вставки сжатие особенно эффективно при использовании формата Native, который уже соответствует внутренней столбцовой модели хранения ClickHouse. В такой конфигурации сервер может эффективно распаковывать и напрямую сохранять данные с минимальными преобразованиями.
Используйте LZ4 для скорости, а ZSTD — для более высокого коэффициента сжатия
- LZ4: Быстрый и лёгкий. Значительно уменьшает объём данных при минимальной нагрузке на CPU, поэтому отлично подходит для вставки с высокой пропускной способностью и используется по умолчанию в большинстве клиентов ClickHouse.
- ZSTD: Обеспечивает более высокий коэффициент сжатия, но сильнее нагружает CPU. Полезен, когда передача данных по сети обходится дорого — например, между регионами или у облачных провайдеров, — хотя при этом немного возрастают вычислительная нагрузка на клиенте и время распаковки на сервере.
Рекомендуемая практика: используйте LZ4, если только у вас не ограничена пропускная способность канала или нет затрат на исходящий трафик данных — в этом случае стоит рассмотреть ZSTD.
В тестах из бенчмарка FastFormats вставки Native со сжатием LZ4 уменьшили объём данных более чем на 50%, сократив время ингестии со 150 до 131 с для набора данных объёмом 5,6 GiB. При переходе на ZSTD тот же набор данных сжался до 1,69 GiB, но время обработки на стороне сервера немного увеличилось. Сжатие снижает потребление ресурсов
Предварительная сортировка, если это не требует больших затрат
Отправлять много небольших батчей в синхронном режиме не рекомендуется, так как это приводит к созданию множества частей. Это ухудшает производительность запросов и вызывает ошибки “too many part”. async_insert.
Асинхронные вставки поддерживаются как через HTTP, так и через native TCP interface.
Когда они включены (async_insert = 1), вставки буферизуются и записываются на диск только после выполнения одного из условий сброса:
Сброс выполняется при достижении первого из этих порогов.
Этот процесс пакетирования прозрачен для клиентов и помогает ClickHouse эффективно объединять трафик вставки из нескольких источников. Однако до сброса данные недоступны для запросов. Важно, что для каждой комбинации формы вставки и настроек существует несколько буферов, а в кластерах буферы поддерживаются отдельно на каждом узле, что позволяет гибко управлять ими в многопользовательских средах. Во всем остальном механика вставки идентична описанной для синхронных вставок.
Поведение асинхронных вставок дополнительно настраивается с помощью параметра wait_for_async_insert.
Если установлено значение 1 (по умолчанию), ClickHouse подтверждает вставку только после того, как данные успешно сбрасываются на диск. Это обеспечивает строгие гарантии сохранности данных и упрощает обработку ошибок: если во время сброса что-то пойдет не так, ошибка будет возвращена клиенту. Этот режим рекомендуется для большинства production-сценариев, особенно если отказы вставки нужно надежно отслеживать.
Бенчмарки показывают, что этот режим хорошо масштабируется при параллелизме — как с 200, так и с 500 клиентами — благодаря адаптивным вставкам и стабильному созданию частей.
Параметр wait_for_async_insert = 0 включает режим “fire-and-forget”. В этом случае сервер подтверждает вставку сразу после буферизации данных, не дожидаясь их записи в хранилище.
Это обеспечивает сверхнизкую latency вставок и максимальный throughput, что идеально подходит для высокоскоростных, но некритичных данных. Однако здесь есть компромиссы: нет гарантии, что данные будут сохранены, ошибки проявляются только во время сброса, а dead-letter queue для неудачных вставок отсутствует — для трассировки сбоев приходится постфактум проверять серверные журналы и системные таблицы. Используйте этот режим только в том случае, если ваша рабочая нагрузка допускает потерю данных.
Бенчмарки также показывают существенное сокращение количества частей и снижение загрузки CPU, когда буфер сбрасывается нечасто (например, каждые 30 секунд), однако риск незаметного сбоя сохраняется.
Мы настоятельно рекомендуем использовать async_insert=1,wait_for_async_insert=1, если вы используете асинхронные вставки. Использование wait_for_async_insert=0 очень рискованно, потому что ваш INSERT-клиент может не узнать о наличии ошибок, а также это может привести к перегрузке, если клиент продолжит быстро записывать данные в ситуации, когда серверу ClickHouse нужно замедлить запись и создать обратное давление, чтобы обеспечить надежность сервиса.
Адаптивные асинхронные вставки
async_insert_use_adaptive_busy_timeout). Вместо фиксированного интервала сброса тайм-аут динамически подстраивается между минимальным значением (async_insert_busy_timeout_min_ms, по умолчанию 50 мс) и максимальным (async_insert_busy_timeout_max_ms, по умолчанию 200 мс или 1000 мс в Cloud) в зависимости от скорости поступления данных.
Когда данные поступают часто, тайм-аут остается ближе к минимальному значению, чтобы сброс происходил раньше и уменьшалась сквозная задержка. Когда данные поступают редко, он увеличивается в сторону максимального значения, чтобы накапливать более крупные батчи. Это особенно полезно в режиме по умолчанию (wait_for_async_insert=1), где фиксированный большой тайм-аут заставлял бы клиентов ждать весь интервал, даже если данные уже готовы к сбросу.
Проверка схемы и разбор данных происходят при сбросе буфера, а не в момент получения вставки. Если в какой-либо строке запроса на вставку есть ошибка разбора данных или несоответствие типа, никакие данные из этого запроса не сбрасываются на диск — отклоняется вся полезная нагрузка запроса. В режиме по умолчанию (wait_for_async_insert=1) ошибка возвращается клиенту. В режиме fire-and-forget ошибки записываются в серверный журнал и в таблицу system.asynchronous_inserts.
Каждый сброс создает как минимум одну часть для каждого отдельного значения ключа партиционирования в буфере. Даже для таблиц без ключа партиционирования один сброс может создать несколько частей, если объем буферизованных данных превышает max_insert_block_size (по умолчанию ~1 миллион строк).
Несмотря на использование асинхронных вставок, вы все равно можете столкнуться с ошибками “too many parts”, если ключ партиционирования имеет высокую мощность. Дедупликация и надежность
Включение асинхронных вставок
-
Включение асинхронных вставок на уровне пользователя. В этом примере используется пользователь
default; если вы создадите другого пользователя, подставьте его имя:
-
Вы можете указать настройки асинхронной вставки с помощью секции SETTINGS в запросах вставки:
-
Вы также можете указать настройки асинхронной вставки как параметры подключения при использовании клиентской библиотеки ClickHouse для языка программирования.
Например, вот как это можно сделать в строке подключения JDBC, если вы используете драйвер ClickHouse Java JDBC для подключения к ClickHouse Cloud:
Асинхронные вставки не применяются к запросам INSERT INTO ... SELECT. Если вставка содержит секцию SELECT, запрос всегда выполняется синхронно, независимо от настройки async_insert.
Сброс буферов при завершении работы
Сравнение с буферными таблицами
- Изменения DDL не требуются. Асинхронные вставки прозрачны — достаточно включить настройку, а не создавать дополнительные таблицы.
- Буферизация по форме запроса. Асинхронные вставки поддерживают отдельные буферы для каждой уникальной формы запроса и комбинации настроек, что позволяет применять более гибкие политики сброса. Буферные таблицы используют один буфер на целевую таблицу.
- Надёжность. В режиме по умолчанию (
wait_for_async_insert=1) данные записываются на диск до того, как клиент получит подтверждение. Буферные таблицы работают по принципу fire-and-forget — при сбое буферизованные данные теряются.
- Поведение в кластере. В кластерах буферы асинхронных вставок поддерживаются на каждом узле. Для буферных таблиц их нужно явно создавать на каждом узле.
Выберите интерфейс — HTTP или нативный
Content-Encoding: lz4), сжатие применяется ко всей полезной нагрузке, а не к отдельным блокам данных. Этот интерфейс часто выбирают в средах, где простота протокола, балансировка нагрузки или широкая совместимость форматов важнее, чем максимальная производительность.
Более подробное описание этих интерфейсов см. здесь. Последнее изменение 23 июля 2026 г.