Минимизация и оптимизация операций JOIN
ClickHouse поддерживает широкий спектр типов и алгоритмов JOIN, и производительность JOIN заметно улучшилась в последних релизах. Однако запросы с JOIN по своей природе более затратны, чем запросы к одной денормализованной таблице. Денормализация переносит вычислительную нагрузку с момента выполнения запроса на момент вставки или предварительной обработки данных, что часто приводит к существенно меньшей задержке при выполнении запросов. Для аналитических запросов в реальном времени или с жёсткими требованиями к задержке денормализация настоятельно рекомендуется.
Как правило, имеет смысл денормализовать, когда:
- Таблицы изменяются нечасто или допустимы их пакетные обновления.
- Связи не являются «многие-ко-многим» или не обладают чрезмерно высокой кардинальностью.
- Запрашивается только ограниченное подмножество столбцов, т.е. некоторые столбцы можно исключить из денормализации.
- У вас есть возможность вынести обработку из ClickHouse во внешние системы, такие как Flink, где можно управлять обогащением данных в реальном времени или их уплощением (flattening).
Не все данные нужно денормализовать — сосредоточьтесь на атрибутах, которые запрашиваются чаще всего. Также рассмотрите использование материализованных представлений для инкрементального вычисления агрегатов вместо дублирования целых подтаблиц. Когда изменения схемы редки, а задержка критична, денормализация обеспечивает наилучший компромисс по производительности.
Полное руководство по денормализации данных в ClickHouse см. здесь.
Когда требуются JOIN
Когда требуются JOIN, убедитесь, что вы используете как минимум версию 24.12 и по возможности самую свежую, поскольку производительность JOIN продолжает улучшаться с каждым релизом. Начиная с ClickHouse 24.12, планировщик запросов автоматически помещает меньшую таблицу в правую часть JOIN для оптимальной производительности — задачу, которую ранее приходилось выполнять вручную. В ближайших релизах ожидается ещё больше улучшений, включая более агрессивное проталкивание условий фильтрации (filter pushdown) и автоматическое переупорядочивание нескольких JOIN.
Следуйте этим рекомендациям, чтобы улучшить производительность JOIN:
- Избегайте декартовых произведений: Если значение в левой части совпадает с несколькими значениями в правой части, JOIN вернёт несколько строк — так называемое декартово произведение. Если вашему сценарию использования не нужны все совпадения из правой части, а достаточно любого одного совпадения, вы можете использовать
ANYJOIN (например,LEFT ANY JOIN). Они работают быстрее и потребляют меньше памяти, чем обычные JOIN. - Уменьшайте размеры соединяемых таблиц: Время выполнения и потребление памяти для JOIN растут пропорционально размерам левой и правой таблиц. Чтобы уменьшить объём данных, обрабатываемых JOIN, добавьте дополнительные условия фильтрации в предложения
WHEREилиJOIN ONзапроса. ClickHouse проталкивает условия фильтрации как можно глубже в план запроса, обычно до выполнения JOIN. Если по какой-либо причине фильтры не проталкиваются автоматически, перепишите одну из сторон JOIN как подзапрос, чтобы принудительно выполнить pushdown. - Используйте прямые JOIN через словари, если это уместно: Стандартные JOIN в ClickHouse выполняются в два этапа: этап построения, на котором правая часть обходится для построения хеш-таблицы, затем этап поиска (probe), на котором левая часть обходится для нахождения подходящих партнёров по JOIN через поиск в хеш-таблице. Если правая часть — это dictionary или другой движок таблиц с характеристиками key-value (например, EmbeddedRocksDB или табличный движок Join), то ClickHouse может использовать алгоритм «direct join», который по сути устраняет необходимость строить хеш-таблицу, ускоряя обработку запроса. Это работает для
INNERиLEFT OUTERJOIN и предпочтительно для аналитических нагрузок в режиме реального времени. - Используйте сортировку таблиц для JOIN: Каждая таблица в ClickHouse отсортирована по столбцам первичного ключа таблицы. Можно использовать сортировку таблицы, применяя так называемые алгоритмы сортирующего слияния (sort-merge) для JOIN, такие как
full_sorting_mergeиpartial_merge. В отличие от стандартных алгоритмов JOIN, основанных на хеш-таблицах (см. ниже,parallel_hash,hash,grace_hash), алгоритмы sort-merge JOIN сначала сортируют, а затем объединяют обе таблицы. Если запрос соединяет обе таблицы по их соответствующим столбцам первичного ключа, то у sort-merge есть оптимизация, которая опускает шаг сортировки, экономя время и накладные расходы на обработку. - Избегайте JOIN с выгрузкой на диск (disk-spilling): Промежуточные состояния JOIN (например, хеш-таблицы) могут стать настолько большими, что больше не помещаются в оперативной памяти. В этой ситуации ClickHouse по умолчанию вернёт ошибку нехватки памяти (out-of-memory). Некоторые алгоритмы JOIN (см. ниже), например
grace_hash,partial_mergeиfull_sorting_merge, могут выгружать промежуточные состояния на диск и продолжать выполнение запроса. Тем не менее эти алгоритмы JOIN следует использовать с осторожностью, так как доступ к диску может существенно замедлить обработку JOIN. Вместо этого мы рекомендуем оптимизировать запрос с JOIN другими способами, чтобы уменьшить размер промежуточных состояний. - Значения по умолчанию как маркеры отсутствия совпадений во внешних JOIN: Левые/правые/полные внешние JOIN включают все значения из левой/правой/обеих таблиц. Если для какого-то значения не найден партнёр по JOIN в другой таблице, ClickHouse заменяет партнёра по JOIN специальным маркером. Стандарт SQL требует, чтобы базы данных использовали NULL в качестве такого маркера. В ClickHouse для этого требуется оборачивать результирующий столбец в Nullable, что создаёт дополнительную нагрузку на память и производительность. В качестве альтернативы вы можете настроить параметр
join_use_nulls = 0и использовать значение по умолчанию типа данных результирующего столбца в качестве маркера.
При использовании словарей для операций JOIN в ClickHouse важно понимать, что словари по своей природе не допускают дублирующихся ключей. Во время загрузки данных любые повторяющиеся ключи автоматически объединяются — для каждого ключа сохраняется только последнее загруженное значение. Такое поведение делает словари идеальными для связей «один-к-одному» или «многие-к-одному», когда требуется только самое актуальное или эталонное значение. Однако использование словаря для связей «один-ко-многим» или «многие-ко-многим» (например, при связывании ролей с актёрами, где у одного актёра может быть несколько ролей) приведёт к незаметной потере данных, поскольку все соответствующие строки, кроме одной, будут отброшены. В результате словари не подходят для сценариев, где требуется сохранение полной реляционной семантики при множественных соответствиях. Подробнее о том, в каких случаях словари полезны (а в каких нет), см. Лучшие практики для словарей.
Выбор подходящего алгоритма JOIN
ClickHouse поддерживает несколько алгоритмов JOIN, которые по-разному балансируют между скоростью и потреблением памяти:
- Parallel Hash JOIN (по умолчанию): Быстрый для малых и средних правых таблиц, которые помещаются в память.
- Direct JOIN: Идеален при использовании словарей (или других движков таблиц с характеристиками ключ-значение) с
INNERилиLEFT ANY JOIN— самый быстрый метод для точечных выборок, так как устраняет необходимость строить хеш-таблицу. - Full Sorting Merge JOIN: Эффективен, когда обе таблицы отсортированы по ключу соединения.
- Partial Merge JOIN: Минимизирует использование памяти, но работает медленнее — лучше всего подходит для соединения больших таблиц при ограниченной памяти.
- Grace Hash JOIN: Гибкий и настраиваемый по использованию памяти, хорошо подходит для больших наборов данных с настраиваемыми характеристиками производительности.
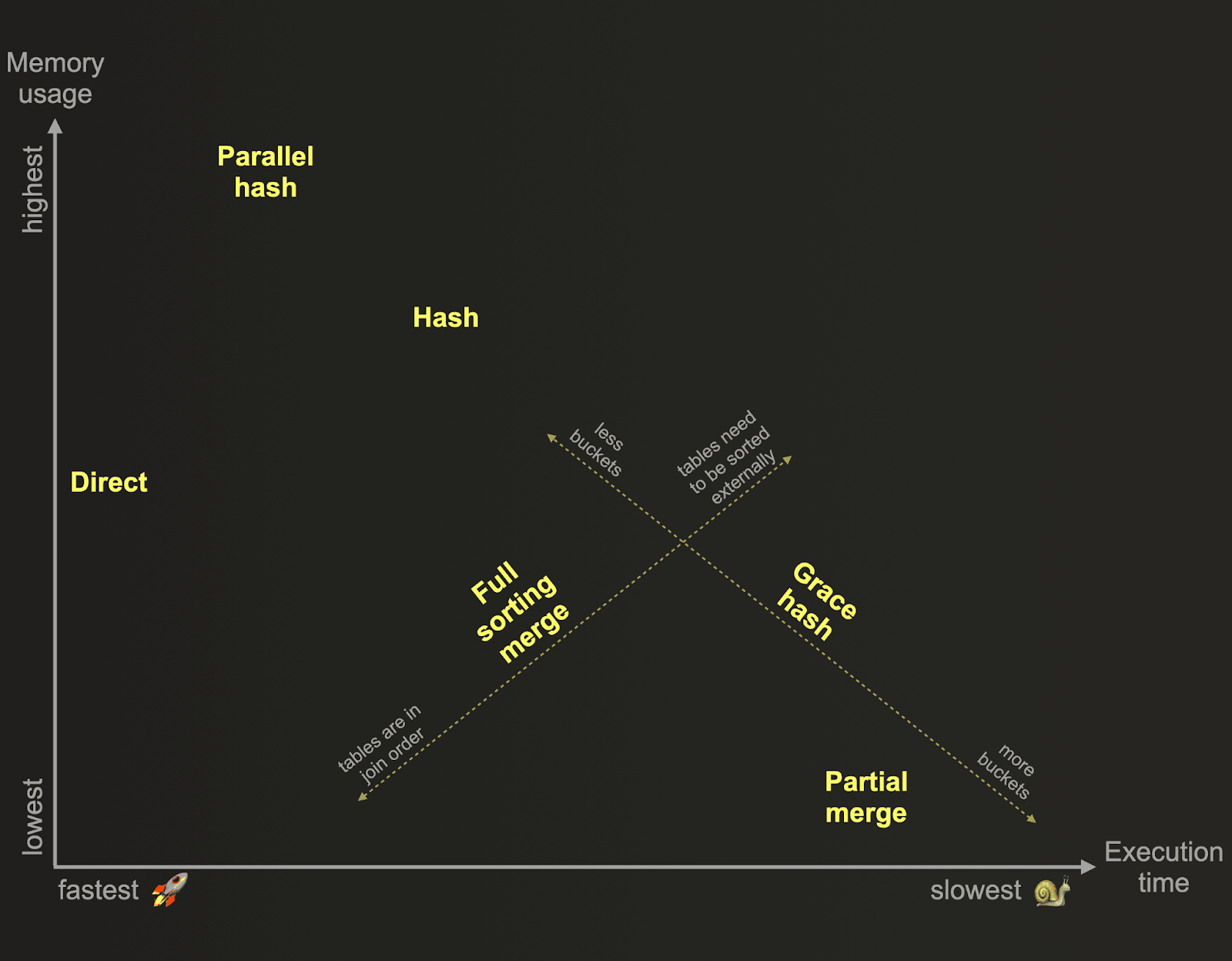
Каждый алгоритм по-разному поддерживает типы JOIN. Полный список поддерживаемых типов JOIN для каждого алгоритма можно найти здесь.
Вы можете позволить ClickHouse выбрать лучший алгоритм, установив join_algorithm = 'auto' (значение по умолчанию), или явно управлять им в зависимости от вашей нагрузки. Если вам нужно выбрать алгоритм JOIN для оптимизации производительности или накладных расходов по памяти, мы рекомендуем это руководство.
Для оптимальной производительности:
- Минимизируйте количество JOIN в высокопроизводительных рабочих нагрузках.
- Избегайте более чем 3–4 JOIN в одном запросе.
- Тестируйте разные алгоритмы на реальных данных — производительность зависит от распределения ключей JOIN и объёма данных.
Подробнее о стратегиях оптимизации JOIN, алгоритмах JOIN и их настройке см. в документации ClickHouse и в этой серии статей в блоге.
