АННОТАЦИЯ
1 ВВЕДЕНИЕ
- Огромные наборы данных с высокой скоростью ингестии. Многие приложения, опирающиеся на данные, в таких отраслях, как web analytics, финансы и электронная коммерция, характеризуются огромными и непрерывно растущими объёмами данных. Для работы с такими наборами аналитические базы данных должны не только обеспечивать эффективные стратегии индексирования и сжатия, но и поддерживать распределение данных по нескольким узлам (горизонтальное масштабирование), поскольку отдельные серверы ограничены несколькими десятками терабайт хранилища. Кроме того, свежие данные часто важнее для аналитики в реальном времени, чем исторические. В результате аналитические базы данных должны обеспечивать приём новых данных на стабильно высокой скорости или всплесками, а также непрерывно «снижать приоритет» исторических данных (например, агрегировать или архивировать их), не замедляя параллельно выполняемые отчётные запросы.
- Множество одновременных запросов при ожидании низкой задержки. Запросы в целом можно разделить на ad-hoc (например, исследовательский анализ данных) и повторяющиеся (например, периодические запросы панели мониторинга). Чем более интерактивен сценарий использования, тем ниже ожидаемая задержка запросов, что создаёт сложности для оптимизации и выполнения запросов. Повторяющиеся запросы также позволяют адаптировать физическую структуру базы данных к рабочей нагрузке. В результате базы данных должны предлагать методы отсечения, позволяющие оптимизировать часто выполняемые запросы. В зависимости от приоритета запроса базы данных также должны обеспечивать равный или приоритетный доступ к общим системным ресурсам, таким как CPU, память, диск и сетевой I/O, даже если одновременно выполняется большое количество запросов.
- Разнообразный ландшафт хранилищ данных, мест хранения и форматов. Чтобы интегрироваться с существующими архитектурами данных, современные аналитические базы данных должны быть в высокой степени открыты для чтения и записи внешних данных — независимо от системы, местоположения или формата.
- Удобный язык запросов с поддержкой анализа производительности. Практическое использование OLAP-баз данных предъявляет и дополнительные «мягкие» требования. Например, вместо нишевого языка программирования пользователи часто предпочитают работать с базами данных через выразительный диалект SQL с вложенными типами данных и широким набором обычных, агрегатных и оконных функций. Аналитические базы данных также должны предоставлять развитые средства для анализа производительности системы в целом или отдельных запросов.
- Надёжность промышленного уровня и гибкость развертывания. Поскольку стандартное оборудование ненадёжно, базы данных должны обеспечивать репликацию данных для устойчивости к отказам узлов. Кроме того, базы данных должны работать на любом оборудовании — от старых ноутбуков до мощных серверов. Наконец, чтобы избежать накладных расходов на сборку мусора в программах на основе JVM и обеспечить производительность на физическом оборудовании (например, за счёт SIMD), базы данных в идеале должны развертываться как нативные бинарные файлы для целевой платформы.

Рисунок 1: временная шкала ClickHouse.
2 АРХИТЕКТУРА
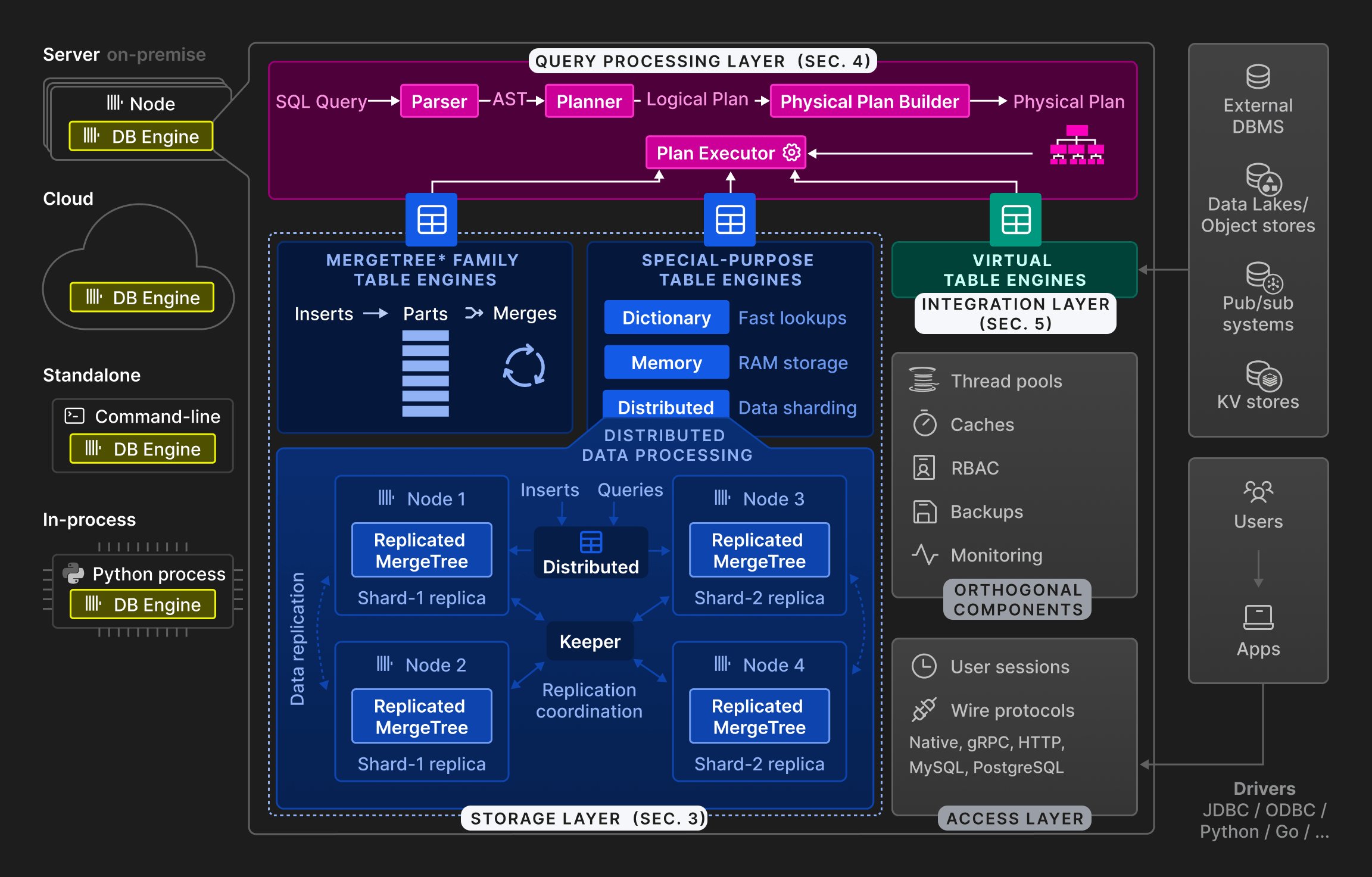
Рисунок 2: Общая архитектура движка базы данных ClickHouse.
3 УРОВЕНЬ ХРАНЕНИЯ
В этом разделе рассматриваются движки таблиц MergeTree* как нативный формат хранения ClickHouse. Мы описываем их структуру хранения на диске и рассматриваем три метода отсечения данных в ClickHouse. Затем мы представляем стратегии слияния, которые непрерывно преобразуют данные, не влияя на параллельные вставки. Наконец, мы объясняем, как реализованы обновления и удаления, а также дедупликация данных, репликация данных и соответствие принципам ACID.3.1 Формат хранения на диске
Каждая таблица с движком таблицы MergeTree* организована как набор неизменяемых частей таблицы. Часть создается каждый раз, когда в таблицу вставляется набор строк. Части самодостаточны в том смысле, что содержат все метаданные, необходимые для интерпретации их содержимого без дополнительных обращений к центральному каталогу. Чтобы число частей в таблице оставалось небольшим, фоновая задача слияния периодически объединяет несколько меньших частей в более крупную, пока не будет достигнут настраиваемый размер части (по умолчанию 150 ГБ). Поскольку части сортируются по столбцам первичного ключа таблицы (см. раздел 3.2), для слияния используется эффективная k-путевая сортировка слиянием [40]. Исходные части помечаются как неактивные и в конечном итоге удаляются, как только счетчик ссылок на них падает до нуля, то есть когда их больше не читают никакие запросы. Строки можно вставлять в двух режимах: в синхронном режиме вставки каждый оператор INSERT создает новую часть и добавляет ее в таблицу. Чтобы минимизировать накладные расходы на слияние, клиентам базы данных рекомендуется вставлять кортежи крупными батчами, например по 20 000 строк за раз. Однако задержки, вызванные пакетированием на стороне клиента, часто неприемлемы, если данные нужно анализировать в реальном времени. Например, сценарии использования обсервабилити часто включают тысячи агентов мониторинга, которые непрерывно отправляют небольшие объемы данных о событиях и метриках. В таких сценариях можно использовать асинхронный режим вставки, при котором ClickHouse буферизует строки из нескольких входящих операторов INSERT в одну и ту же таблицу и создает новую часть только после того, как размер буфера превысит настраиваемый порог или истечет тайм-аут.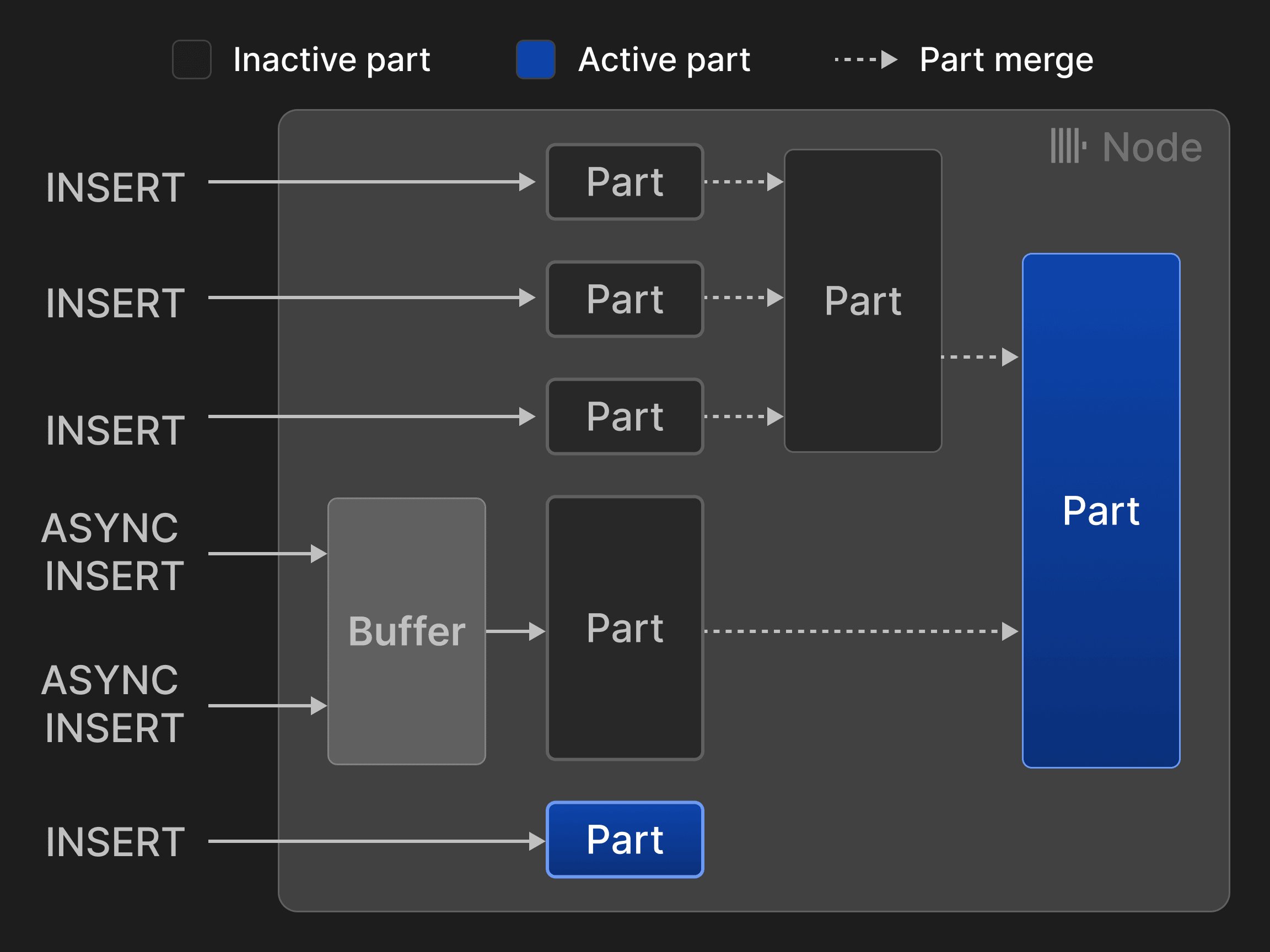
Рисунок 3: Вставки и слияния для таблиц с движком MergeTree*.
3.2 Отсечение данных
В большинстве случаев сканирование PB данных ради ответа на один запрос слишком медленно и дорого. ClickHouse поддерживает три метода отсечения данных, которые позволяют пропускать большую часть строк при поиске и тем самым значительно ускорять запросы. Во-первых, пользователи могут определить для таблицы индекс первичного ключа. Столбцы первичного ключа задают порядок сортировки строк внутри каждой части, то есть индекс локально кластеризован. Кроме того, ClickHouse хранит для каждой части отображение значений столбца первичного ключа из первой строки каждой гранулы в идентификатор гранулы, то есть индекс является разреженным [31]. Получающаяся структура данных обычно достаточно мала, чтобы целиком помещаться в памяти; например, для индексации 8,1 миллиона строк требуется всего 1000 записей. Основное назначение первичного ключа — вычислять предикаты равенства и диапазона для часто фильтруемых столбцов с помощью двоичного поиска вместо последовательного сканирования (раздел 4.4). Локальную сортировку также можно использовать для слияния частей и оптимизации запросов, например для агрегации на основе сортировки или для удаления операторов сортировки из физического плана выполнения, когда столбцы первичного ключа образуют префикс столбцов сортировки. На рисунке 4 показан индекс первичного ключа по столбцу EventTime для таблицы со статистикой просмотров страниц. Гранулы, соответствующие диапазонному предикату в запросе, можно найти с помощью двоичного поиска по индексу первичного ключа вместо последовательного сканирования EventTime.
Рисунок 4: Вычисление фильтров с помощью индекса первичного ключа.
3.3 Преобразование данных при слиянии
Сценарии бизнес-аналитики и обсервабилити часто требуют обрабатывать данные, которые генерируются либо постоянно с высокой скоростью, либо всплесками. Кроме того, недавно сгенерированные данные обычно важнее для получения значимых инсайтов в реальном времени, чем исторические данные. Такие сценарии требуют, чтобы базы данных поддерживали высокую скорость ингестии данных и при этом непрерывно сокращали объём исторических данных с помощью таких методов, как агрегация или старение данных. ClickHouse позволяет непрерывно и инкрементально преобразовывать существующие данные с использованием различных стратегий слияния. Преобразование данных при слиянии не снижает производительность операторов INSERT, но не может гарантировать, что таблицы никогда не будут содержать нежелательные значения (например, устаревшие или неагрегированные). При необходимости все преобразования при слиянии можно применить на этапе выполнения запроса, указав ключевое слово FINAL в операторах SELECT. Замещающие слияния сохраняют только самую позднюю вставленную версию кортежа на основе временной метки создания содержащей его части, а более старые версии удаляются. Кортежи считаются эквивалентными, если у них совпадают значения столбцов первичного ключа. Чтобы явно управлять тем, какой кортеж сохраняется, можно также указать специальный столбец версии для сравнения. Замещающие слияния обычно используются как механизм обновления при слиянии (как правило, в сценариях с частыми обновлениями) или как альтернатива дедупликации данных во время вставки (раздел 3.5). Агрегирующие слияния сворачивают строки с одинаковыми значениями столбцов первичного ключа в одну агрегированную строку. Столбцы, не входящие в первичный ключ, должны иметь тип промежуточного состояния агрегации, содержащего итоговые значения. Два промежуточных состояния агрегации, например сумма и количество для avg(), объединяются в новое промежуточное состояние агрегации. Агрегирующие слияния обычно используются в materialized view вместо обычных таблиц. Materialized view заполняются на основе запроса преобразования к исходной таблице. В отличие от других баз данных, ClickHouse не обновляет materialized view периодически всем содержимым исходной таблицы. Вместо этого materialized view инкрементально обновляются результатом запроса преобразования, когда в исходную таблицу вставляется новая часть. На рисунке 5 показана materialized view, определённая для таблицы со статистикой показов страниц. Для новых частей, вставляемых в исходную таблицу, запрос преобразования вычисляет максимальную и среднюю задержку, сгруппированную по регионам, и вставляет результат в materialized view. Агрегатные функции avg() и max() с расширением -State возвращают промежуточные состояния агрегации вместо фактических результатов. Агрегирующее слияние, определённое для materialized view, непрерывно объединяет промежуточные состояния агрегации в разных частях. Чтобы получить итоговый результат, пользователи объединяют промежуточные состояния агрегации в materialized view с помощью avg() и max()) с расширением -Merge.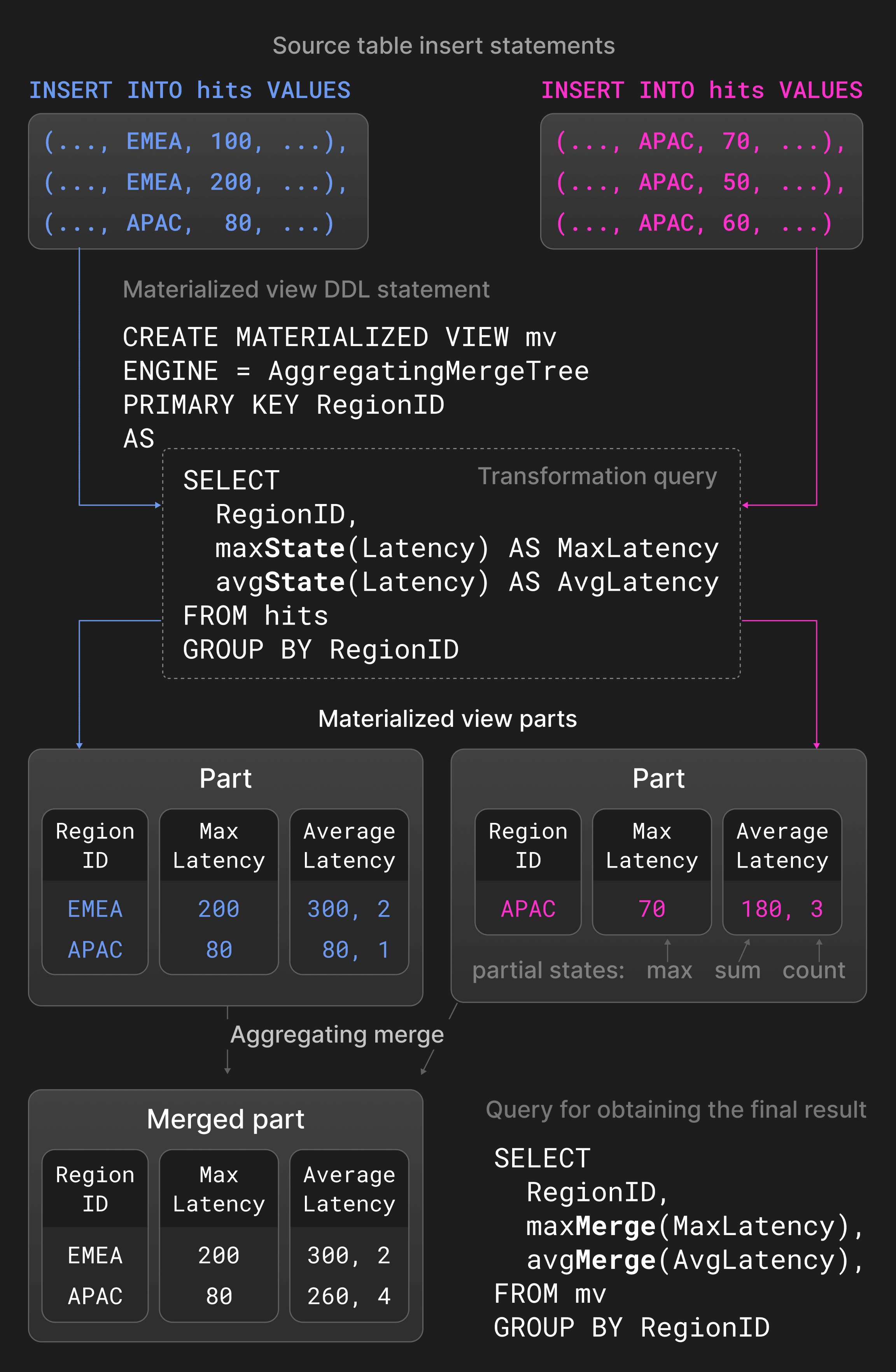
Рисунок 5: Агрегирующие слияния в materialized view.
3.4 Обновления и удаления
Движки таблиц семейства MergeTree* рассчитаны прежде всего на append-only рабочие нагрузки, однако в некоторых сценариях существующие данные всё же приходится время от времени изменять, например для соблюдения нормативных требований. Для обновления и удаления данных есть два подхода, и ни один из них не блокирует параллельные вставки. Мутации переписывают все части таблицы на месте. Чтобы таблица (при удалении) или столбец (при обновлении) не увеличивались временно вдвое, эта операция не является атомарной, то есть параллельные операторы SELECT могут читать как мутированные, так и немутированные части. Мутации гарантируют, что по завершении операции данные будут физически изменены. Удаляющие мутации по-прежнему затратны, поскольку переписывают все столбцы во всех частях. В качестве альтернативы легковесные удаления обновляют только внутренний столбец битмапа, который показывает, удалена строка или нет. ClickHouse дополняет запросы SELECT дополнительным фильтром по столбцу битмапа, чтобы исключить удалённые строки из результата. Физически такие строки удаляются только в ходе обычных слияний в некоторый неопределённый момент в будущем. В зависимости от количества столбцов легковесные удаления могут быть значительно быстрее мутаций, но ценой более медленных SELECT. Ожидается, что операции обновления и удаления для одной и той же таблицы будут выполняться редко и последовательно, чтобы избежать логических конфликтов.3.5 Идемпотентные вставки
Проблема, которая часто возникает на практике, заключается в том, как клиентам обрабатывать тайм-ауты соединения после отправки данных на сервер для вставки в таблицу. В такой ситуации клиентам трудно понять, были ли данные успешно вставлены. Традиционно эта проблема решается повторной отправкой данных с клиента на сервер и использованием первичного ключа или ограничений уникальности для отклонения дублирующихся вставок. Базы данных быстро выполняют необходимые точечные lookup с помощью индексных структур на основе бинарных деревьев [39, [68]](#page-13-16), radix-деревьев [45] или хеш-таблиц [29]. Поскольку эти структуры данных индексируют каждый кортеж, связанные с ними накладные расходы на хранение и обновление становятся неприемлемыми для больших наборов данных и высоких скоростей приёма. ClickHouse предлагает более лёгкую альтернативу, основанную на том, что каждая вставка в конечном итоге создаёт часть. Точнее, сервер хранит хеши N последних вставленных частей (например, N=100) и игнорирует повторные вставки частей с уже известным хешем. Хеши для нереплицируемых и реплицируемых таблиц хранятся локально и в Keeper соответственно. В результате вставки становятся идемпотентными, то есть клиенты могут просто повторно отправить тот же батч строк после тайм-аута и считать, что сервер сам выполнит дедупликацию. Для более точного управления процессом дедупликации клиенты при желании могут передать токен вставки, который выступает в роли хеша части. Хотя дедупликация на основе хешей влечёт накладные расходы, связанные с хешированием новых строк, стоимость хранения и сравнения хешей пренебрежимо мала.3.6 Репликация данных
Репликация — обязательное условие для высокой доступности (устойчивости к отказам узлов), но она также используется для балансировки нагрузки и обновлений без простоя [14]. В ClickHouse репликация основана на понятии состояний таблицы, которые состоят из набора частей таблицы (раздел 3.1) и метаданных таблицы, таких как имена столбцов и типы. Узлы изменяют состояние таблицы с помощью трёх операций: 1. вставки добавляют в состояние новую часть, 2. слияния добавляют новую часть и удаляют существующие части из состояния, 3. мутации и DDL-команды добавляют части, и/или удаляют части, и/или изменяют метаданные таблицы в зависимости от конкретной операции. Операции выполняются локально на одном узле и записываются в глобальный журнал репликации как последовательность переходов состояния. Журнал репликации поддерживается ансамблем, обычно состоящим из трёх процессов ClickHouse Keeper, которые используют алгоритм консенсуса Raft [59], обеспечивая распределённый и отказоустойчивый слой координации для кластера узлов ClickHouse. Изначально все узлы кластера указывают на одну и ту же позицию в журнале репликации. Пока узлы выполняют локальные вставки, слияния, мутации и DDL-команды, журнал репликации асинхронно воспроизводится на всех остальных узлах. В результате реплицируемые таблицы обладают лишь eventual consistency, то есть узлы могут временно читать старые состояния таблицы, постепенно сходясь к последнему состоянию. Большинство из упомянутых выше операций также могут выполняться синхронно — до тех пор, пока кворум узлов (например, большинство узлов или все узлы) не примет новое состояние. В качестве примера на рисунке 6 показана изначально пустая реплицируемая таблица в кластере из трёх узлов ClickHouse. Узел 1 сначала получает два оператора вставки и записывает их ( 1 2 ) в журнал репликации, хранящийся в ансамбле Keeper. Затем узел 2 воспроизводит первую запись журнала, считывая её ( 3 ) и загружая новую часть с узла 1 ( 4 ), тогда как узел 3 воспроизводит обе записи журнала ( 3 4 5 6 ). Наконец, узел 3 объединяет обе части в новую часть, удаляет исходные части и записывает в журнал репликации запись о слиянии ( 7 ).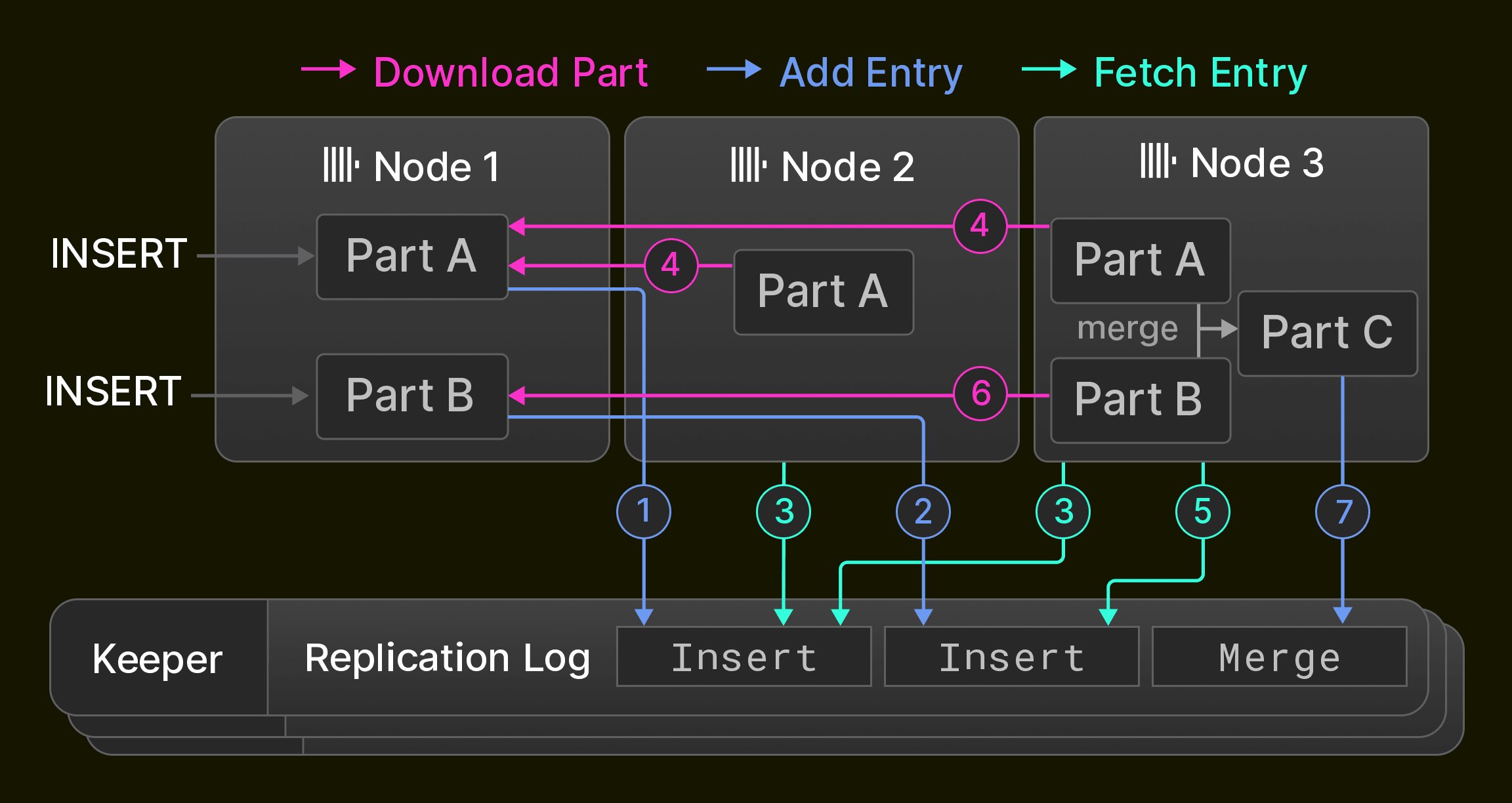
Рисунок 6: Репликация в кластере из трёх узлов.
3.7 Соответствие требованиям ACID
Чтобы максимально повысить производительность параллельных операций чтения и записи, ClickHouse по возможности избегает блокировок. Запросы выполняются по снимку всех частей во всех задействованных таблицах, созданному в начале запроса. Это гарантирует, что новые части, добавленные параллельными операциями INSERT или слияниями (раздел 3.1), не участвуют в выполнении. Чтобы части не изменялись и не удалялись одновременно (раздел 3.4), на время выполнения запроса увеличивается счётчик ссылок обрабатываемых частей. Формально это соответствует изоляции снимков, реализованной вариантом MVCC [6] на основе версионируемых частей. В результате команды, как правило, не соответствуют требованиям ACID, за редким исключением, когда параллельные записи в момент создания снимка затрагивают только по одной части каждая. На практике большинство сценариев ClickHouse с интенсивной записью, связанных с принятием решений, допускают небольшой риск потери новых данных в случае сбоя питания. База данных использует это, по умолчанию не выполняя принудительную фиксацию (fsync) вновь вставленных частей на диске, что позволяет ядру группировать записи ценой отказа от атомарности.4 СЛОЙ ОБРАБОТКИ ЗАПРОСОВ
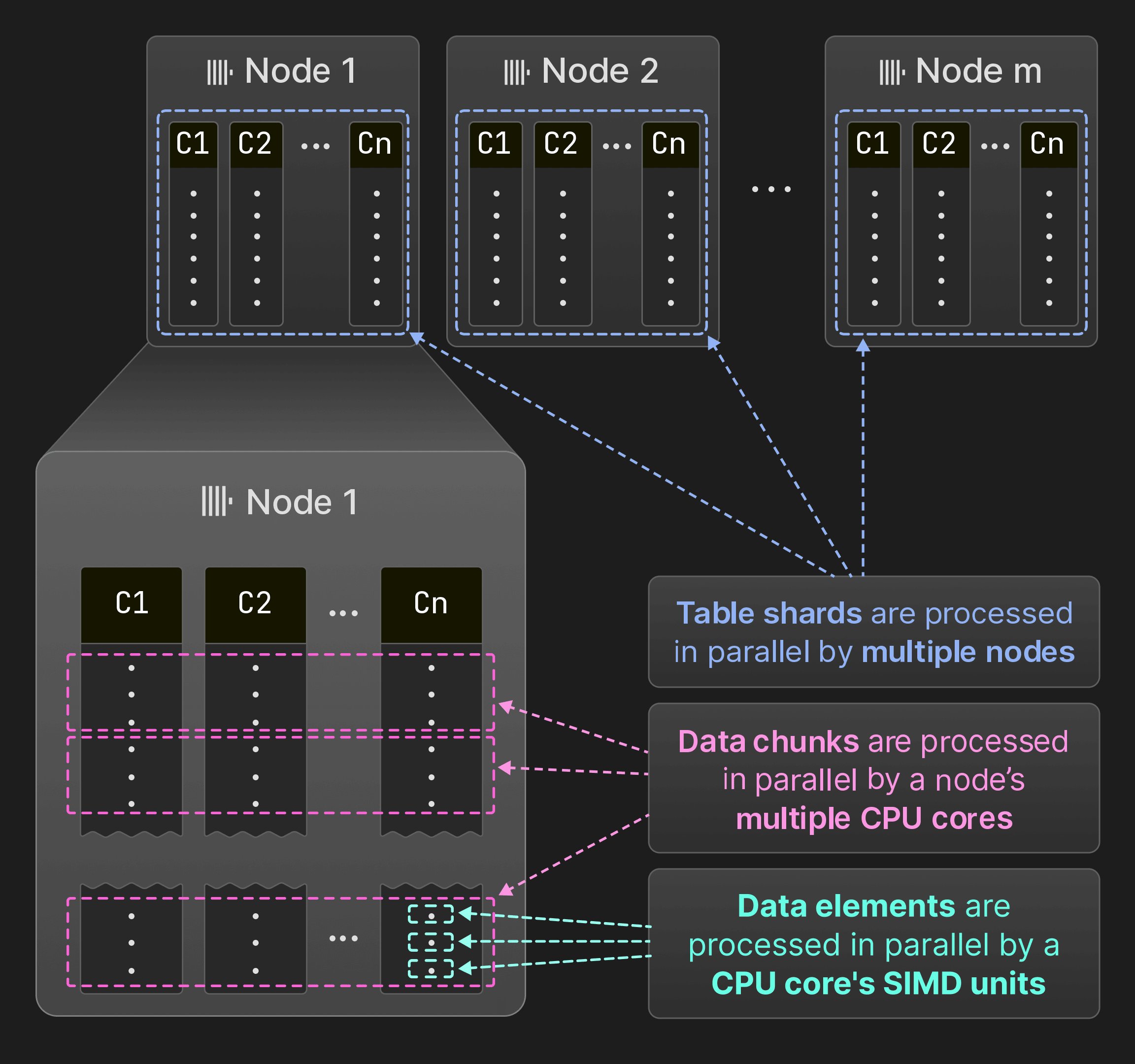
Рисунок 7: Параллелизация между SIMD-блоками, ядрами и узлами.
4.1 SIMD-параллелизация
4.2 Многоядерная параллелизация
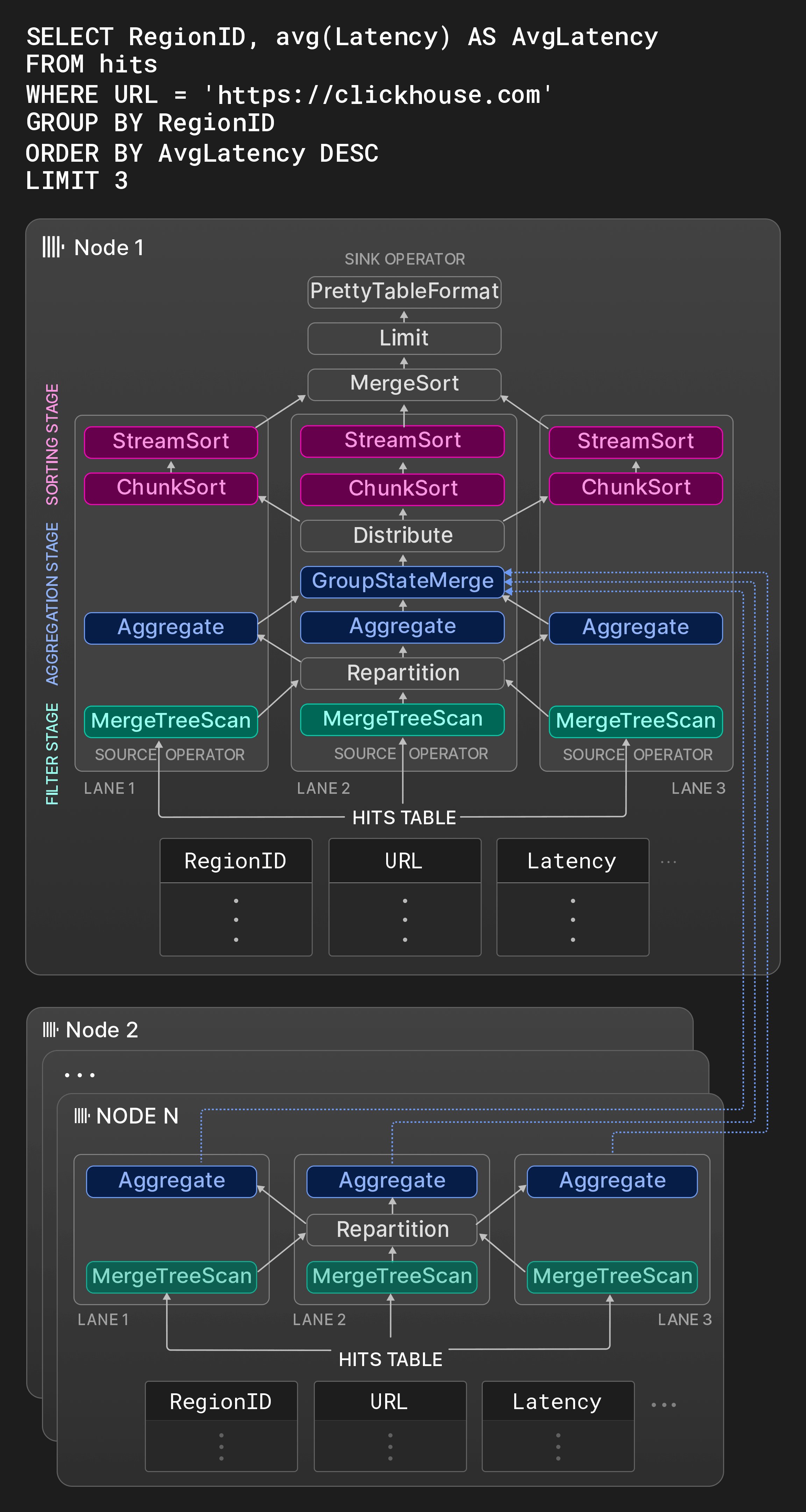
Рисунок 8: План физических операторов с тремя линиями выполнения.
4.3 Многоузловое распараллеливание
4.4 Комплексная оптимизация производительности
В этом разделе рассматриваются ключевые оптимизации производительности, применяемые на разных этапах выполнения запроса. Оптимизация запроса. Первый набор оптимизаций применяется к семантическому представлению запроса, полученному из его AST. К таким оптимизациям относятся свёртка констант (например, concat(lower(‘a’),upper(‘b’)) превращается в ‘aB’), вынесение скаляров из некоторых функций агрегации (например, sum(a2) превращается в 2 * sum(a)), устранение общих подвыражений и преобразование дизъюнкций фильтров по равенству в IN-списки (например, x=c OR x=d превращается в x IN (c,d)). Затем оптимизированное семантическое представление запроса преобразуется в логический план операторов. Оптимизации на уровне логического плана включают pushdown фильтров, а также переупорядочивание вычисления функций и этапов сортировки в зависимости от того, что предположительно требует больших затрат. Наконец, логический план запроса преобразуется в физический план операторов. Это преобразование может учитывать особенности используемых движков таблиц. Например, в случае движка таблицы MergeTree, если столбцы ORDER BY образуют префикс первичного ключа, данные можно читать в порядке их расположения на диске, и операторы сортировки можно удалить из плана. Кроме того, если столбцы группировки в агрегации образуют префикс первичного ключа, ClickHouse может использовать sort aggregation [33], то есть напрямую агрегировать последовательности одинаковых значений во входных данных, уже предварительно отсортированных. По сравнению с hash aggregation, sort aggregation требует значительно меньше памяти, а агрегированное значение можно передать следующему оператору сразу после обработки очередной последовательности. Компиляция запросов. ClickHouse использует компиляцию запросов на основе LLVM для динамического объединения соседних операторов плана [38, [53]](#page-13-0). Например, выражение a * b + c + 1 можно объединить в один оператор вместо трёх. Помимо выражений, ClickHouse также использует компиляцию для одновременного вычисления нескольких функций агрегации (то есть для GROUP BY) и для сортировки с более чем одним ключом сортировки. Компиляция запросов уменьшает число виртуальных вызовов, удерживает данные в регистрах или кэшах CPU и помогает предсказателю ветвлений, поскольку требуется выполнять меньше кода. Кроме того, компиляция во время выполнения открывает доступ к широкому набору оптимизаций, таких как логические оптимизации и peephole-оптимизации, реализованные в компиляторах, а также к самым быстрым доступным на данной машине инструкциям CPU. Компиляция запускается только тогда, когда одно и то же обычное выражение, выражение агрегации или сортировки выполняется разными запросами больше заданного числа раз. Скомпилированные операторы запроса кэшируются и могут повторно использоваться будущими запросами.[7] Оценка индекса первичного ключа. ClickHouse вычисляет условия WHERE с использованием индекса первичного ключа, если подмножество секций фильтра в конъюнктивной нормальной форме условия образует префикс столбцов первичного ключа. Индекс первичного ключа анализируется слева направо на лексикографически отсортированных диапазонах значений ключа. Секции фильтра, соответствующие столбцу первичного ключа, вычисляются с использованием троичной логики — они либо все истинны, либо все ложны, либо содержат смесь истинных и ложных значений для значений в диапазоне. В последнем случае диапазон разбивается на поддиапазоны, которые затем анализируются рекурсивно. Для функций в условиях фильтра также существуют дополнительные оптимизации. Во-первых, у функций есть характеристики, описывающие их монотонность; например, toDayOfMonth(date) является кусочно-монотонной в пределах месяца. Эти характеристики позволяют определить, даёт ли функция отсортированные результаты на отсортированных входных диапазонах значений ключа. Во-вторых, некоторые функции могут вычислять прообраз заданного результата функции. Это используется, чтобы заменить сравнение констант с вызовами функций по столбцам ключа сравнением значения столбца ключа с прообразом. Например, toYear(k) = 2024 можно заменить на k >= 2024-01-01 && k < 2025-01-01. Пропуск данных. ClickHouse старается избегать чтения данных во время выполнения запроса, используя структуры данных, представленные в разделе 3.2. Кроме того, фильтры по разным столбцам вычисляются последовательно в порядке убывания предполагаемой селективности на основе эвристик и (необязательной) статистики столбцов. На следующий предикат передаются только те фрагменты данных, которые содержат хотя бы одну подходящую строку. Это постепенно уменьшает объём читаемых данных и число вычислений, которые нужно выполнить при переходе от предиката к предикату. Оптимизация применяется только при наличии хотя бы одного высокоселективного предиката; в противном случае задержка запроса была бы выше по сравнению с вычислением всех предикатов in parallel. Хеш-таблицы. Хеш-таблицы — фундаментальные структуры данных для агрегации и hash JOIN. Выбор правильного типа хеш-таблицы критически важен для производительности. ClickHouse создает различные хеш-таблицы (более 30 по состоянию на март 2024 года) из универсального шаблона хеш-таблицы, где в качестве параметров выступают хеш-функция, аллокатор, тип ячейки и политика изменения размера. В зависимости от типа данных в столбцах группировки, оценочной мощности хеш-таблицы и других факторов для каждого оператора запроса отдельно выбирается самая быстрая хеш-таблица. Дополнительные оптимизации, реализованные для хеш-таблиц, включают:- двухуровневую структуру с 256 подтаблицами (на основе первого байта хеша) для поддержки огромных наборов ключей,
- строковые хеш-таблицы [79] с четырьмя подтаблицами и разными хеш-функциями для строк разной длины,
- lookup-таблицы, которые используют ключ напрямую как индекс бакета (то есть без хеширования), когда ключей немного,
- значения со встроенными хешами для более быстрого разрешения коллизий, когда сравнение обходится дорого (например, для строк и AST),
- создание хеш-таблиц на основе размеров, спрогнозированных по статистике времени выполнения, чтобы избежать лишних изменений размера,
- выделение нескольких небольших хеш-таблиц с одинаковым жизненным циклом создания и уничтожения в одном блоке памяти,
- мгновенную очистку хеш-таблиц для повторного использования с помощью счетчиков версий для каждой hash map и каждой ячейки,
- использование CPU prefetch (__builtin_prefetch) для ускорения получения значений после хеширования ключа.
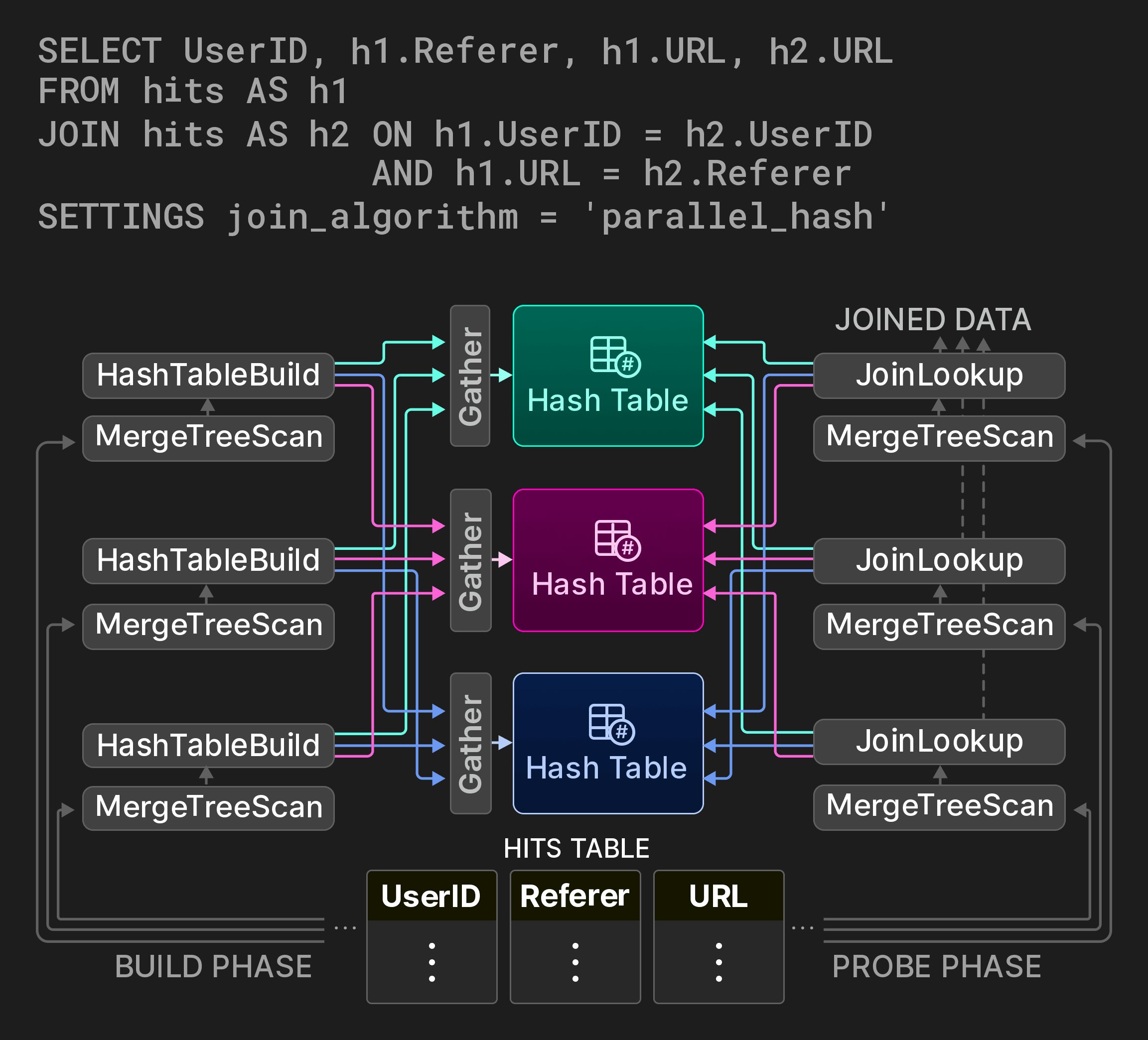
Рисунок 9: Параллельный hash JOIN с тремя партициями хеш-таблицы.
4.5 Изоляция рабочих нагрузок
ClickHouse предлагает контроль параллелизма, ограничения на использование памяти и планирование ввода-вывода, что позволяет изолировать запросы по классам рабочих нагрузок. Задавая ограничения на общие ресурсы (ядра CPU, DRAM, дисковый и сетевой ввод-вывод) для определённых классов рабочих нагрузок, можно гарантировать, что такие запросы не будут влиять на другие критически важные бизнес-запросы. Контроль параллелизма предотвращает чрезмерное выделение потоков в сценариях с большим числом параллельных запросов. Точнее, число потоков-воркеров на запрос динамически регулируется на основе заданного соотношения к количеству доступных ядер CPU. ClickHouse отслеживает объём выделений памяти в байтах на уровне сервера, пользователя и запроса, что позволяет гибко задавать ограничения на использование памяти. Оверкоммит памяти позволяет запросам использовать дополнительную свободную память сверх гарантированного объёма, при этом сохраняя лимиты памяти для других запросов. Кроме того, можно ограничивать использование памяти для агрегации, сортировки и секций JOIN, что при превышении лимита памяти приводит к переходу на внешние алгоритмы. Наконец, планирование ввода-вывода позволяет ограничивать локальный и удалённый доступ к дискам для классов рабочих нагрузок на основе максимальной пропускной способности, количества незавершённых запросов и политики (например, FIFO, SFC [32]).5 СЛОЙ ИНТЕГРАЦИИ
Приложения для принятия решений в реальном времени часто зависят от эффективного доступа к данным с низкой задержкой, даже если эти данные находятся в нескольких местах. Существует два подхода, позволяющих сделать внешние данные доступными в OLAP-базе данных. В push-модели доступа к данным сторонний компонент выступает связующим звеном между базой данных и внешними хранилищами. Один из примеров — специализированные инструменты extract-transform-load (ETL), которые отправляют удаленные данные в систему назначения. В pull-модели сама база данных подключается к удаленным источникам данных и либо загружает данные в локальные таблицы для выполнения запросов, либо экспортирует данные в удаленные системы. Хотя push-подходы более универсальны и распространены, они усложняют архитектуру и создают узкое место для масштабируемости. Напротив, возможность удаленного подключения непосредственно на уровне базы данных открывает интересные возможности, например выполнение JOIN между локальными и удаленными данными, при этом упрощая общую архитектуру и сокращая время до получения результата. Остальная часть раздела посвящена pull-методам интеграции данных в ClickHouse, предназначенным для доступа к данным в удаленных расположениях. Отметим, что сама идея удаленного подключения в SQL-базах данных не нова. Например, стандарт SQL/MED [35], представленный в 2001 году и реализованный в PostgreSQL с 2011 года [65], предлагает foreign data wrappers как унифицированный интерфейс для работы с внешними данными. Максимальная совместимость с другими хранилищами данных и форматами хранения — одна из целей проектирования ClickHouse. По состоянию на март 2024 года, насколько нам известно, ClickHouse предлагает больше всего встроенных вариантов интеграции данных среди всех аналитических баз данных. Внешние подключения. ClickHouse предоставляет 50+ табличных функций и движков интеграции для подключения к внешним системам и местам хранения, включая ODBC, MySQL, PostgreSQL, SQLite, Kafka, Hive, MongoDB, Redis, объектные хранилища S3/GCP/Azure и различные озера данных. Далее мы разбиваем их на категории, показанные на следующем дополнительном рисунке (не входившем в исходную статью vldb).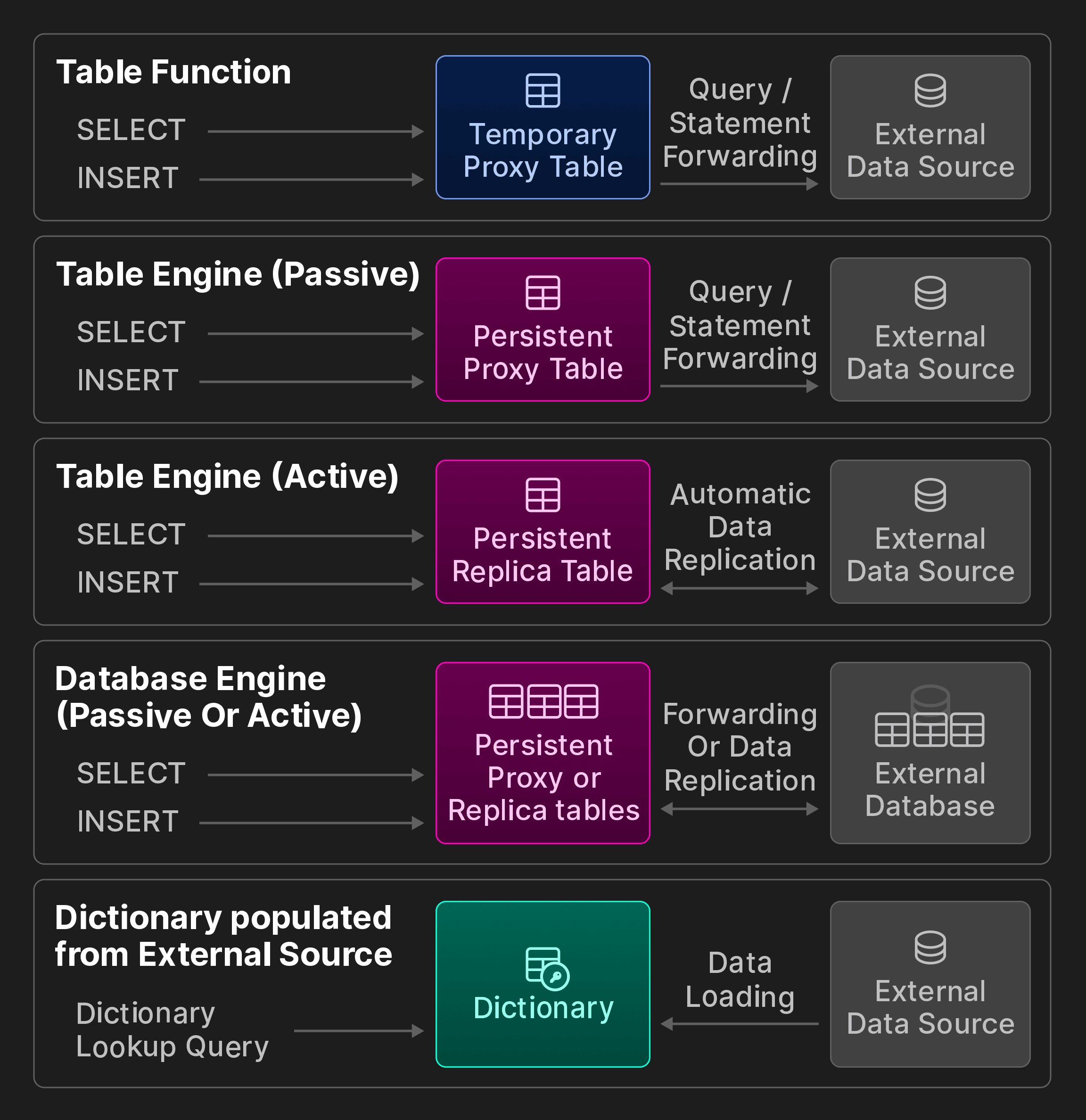
Дополнительный рисунок: варианты совместимости ClickBench.
6 ПРОИЗВОДИТЕЛЬНОСТЬ КАК ВОЗМОЖНОСТЬ
6.1 Встроенные инструменты анализа производительности
6.2 Бенчмарки
6.2.1 Денормализованные таблицы
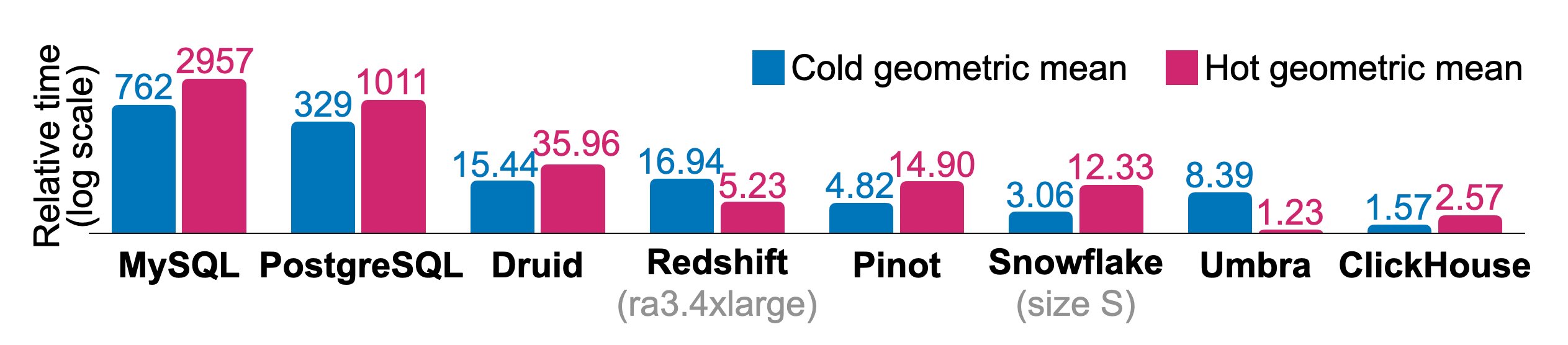
Рисунок 10: Относительное время выполнения ClickBench на холодных и горячих данных.
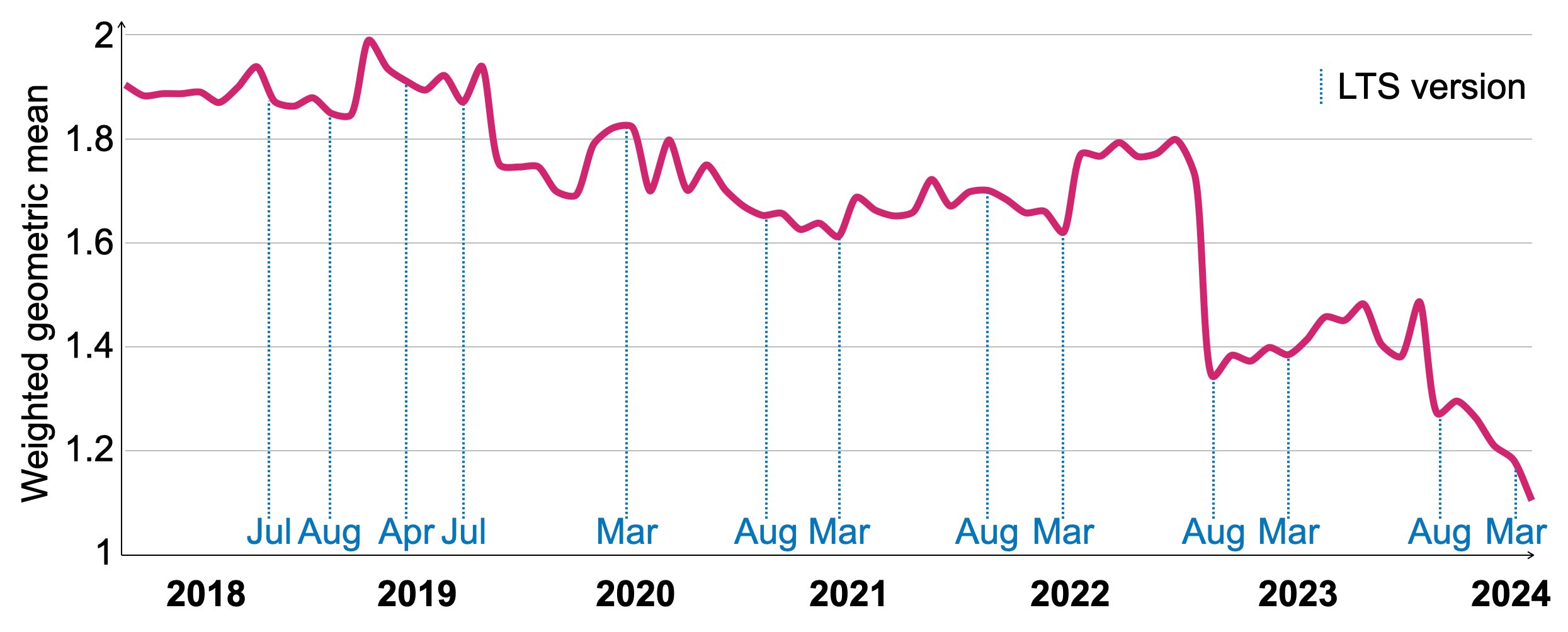
Рисунок 11: Относительное время выполнения на горячих данных для VersionsBench 2018-2024.
6.2.2 Нормализованные таблицы

Рисунок 12: Время выполнения запросов TPC-H на горячих данных (в секундах).
8 ЗАКЛЮЧЕНИЕ И ПЕРСПЕКТИВЫ
БЛАГОДАРНОСТИ
СПРАВОЧНИК
- 1 Daniel Abadi, Peter Boncz, Stavros Harizopoulos, Stratos Idreaos и Samuel Madden. 2013. Проектирование и реализация современных столбцовых систем баз данных. https://doi.org/10.1561/9781601987556
- 2 Daniel Abadi, Samuel Madden, and Miguel Ferreira. 2006. Интеграция сжатия и выполнения запросов в столбцовых системах баз данных. В материалах Proceedings of the 2006 ACM SIGMOD International Conference on Management of Data (SIGMOD ‘06). 671–682.https://doi.org/10.1145/1142473.1142548
- 3 Anastassia Ailamaki, David J. DeWitt, Mark D. Hill и Marios Skounakis. 2001. Weaving Relations for Cache Performance. В материалах 27-й Международной конференции по очень большим базам данных (VLDB ‘01). Morgan Kaufmann Publishers Inc., San Francisco, CA, USA, 169–180.
- 4 Nikos Armenatzoglou, Sanuj Basu, Naga Bhanoori, Mengchu Cai, Naresh Chainani, Kiran Chinta, Venkatraman Govindaraju, Todd J. Green, Monish Gupta, Sebastian Hillig, Eric Hotinger, Yan Leshinksy, Jintian Liang, Michael McCreedy, Fabian Nagel, Ippokratis Pandis, Panos Parchas, Rahul Pathak, Orestis Polychroniou, Foyzur Rahman, Gaurav Saxena, Gokul Soundararajan, Sriram Subramanian и Doug Terry. 2022. Amazon Redshift Re-Invented. В: Proceedings of the 2022 International Conference on Management of Data (Philadelphia, PA, USA) (SIGMOD ‘22). Association for Computing Machinery, New York, NY, USA, 2205–2217. https://doi.org/10.1145/3514221.3526045
- 5 Alexander Behm, Shoumik Palkar, Utkarsh Agarwal, Timothy Armstrong, David Cashman, Ankur Dave, Todd Greenstein, Shant Hovsepian, Ryan Johnson, Arvind Sai Krishnan, Paul Leventis, Ala Luszczak, Prashanth Menon, Mostafa Mokhtar, Gene Pang, Sameer Paranjpye, Greg Rahn, Bart Samwel, Tom van Bussel, Herman van Hovell, Maryann Xue, Reynold Xin и Matei Zaharia. 2022. Photon: A Fast Query Engine for Lakehouse Systems (SIGMOD ‘22). Association for Computing Machinery, New York, NY, USA, 2326–2339. https://doi.org/10.1145/3514221. 3526054
- 6 Philip A. Bernstein and Nathan Goodman. 1981. Управление параллелизмом в распределённых системах баз данных. ACM Computing Survey 13, 2 (1981), 185–221. https://doi.org/10.1145/356842.356846
- 7 Spyros Blanas, Yinan Li и Jignesh M. Patel. 2011. Проектирование и оценка алгоритмов hash JOIN в оперативной памяти для многоядерных CPU. В: Proceedings of the 2011 ACM SIGMOD International Conference on Management of Data (Athens, Greece) (SIGMOD ‘11). Association for Computing Machinery, New York, NY, USA, 37–48. https://doi.org/10.1145/1989323.1989328
- 8 Daniel Gomez Blanco. 2023. Practical OpenTelemetry. Springer Nature.
- 9 Burton H. Bloom. 1970. Space/Time Trade-Ofs in Hash Coding with Allowable Errors. Commun. ACM 13, 7 (1970), 422–426. https://doi.org/10.1145/362686. 362692
- 10 Peter Boncz, Thomas Neumann и Orri Erling. 2014. TPC-H Analyzed: Hidden Messages and Lessons Learned from an Infuential Benchmark. In Performance Characterization and Benchmarking. 61–76. https://doi.org/10.1007/978-3-319- 04936-6_5
- 11 Peter Boncz, Marcin Zukowski, and Niels Nes. 2005. MonetDB/X100: Hyper-Pipelining Query Execution. В материалах CIDR.
- 12 Martin Burtscher и Paruj Ratanaworabhan. 2007. Сжатие данных двойной точности с высокой пропускной способностью. В трудах конференции Data Compression Conference (DCC). 293–302. https://doi.org/10.1109/DCC.2007.44
- 13 Jef Carpenter и Eben Hewitt. 2016. Cassandra: The Defnitive Guide (2nd ed.). O’Reilly Media, Inc.
- 14 Bernadette Charron-Bost, Fernando Pedone и André Schiper (ред.). 2010. Replication: Theory and Practice. Springer-Verlag.
- 15 chDB. 2024. chDB — встраиваемый OLAP SQL-движок. Дата обращения: 2024-06-20. URL: https://github.com/chdb-io/chdb
- 16 ClickHouse. 2024. ClickBench: бенчмарк для аналитических баз данных. Дата обращения: 2024-06-20. https://github.com/ClickHouse/ClickBench
- 17 ClickHouse. 2024. ClickBench: Comparative Measurements. Дата обращения: 2024-06-20. URL: https://benchmark.clickhouse.com
- 18 ClickHouse. 2024. Дорожная карта ClickHouse на 2024 год (GitHub). Дата обращения: 2024-06-20. https://github.com/ClickHouse/ClickHouse/issues/58392
- 19 ClickHouse. 2024. Бенчмарк версий ClickHouse. Дата обращения: 2024-06-20. URL: https://github.com/ClickHouse/ClickBench/tree/main/versions
- 20 ClickHouse. 2024. Результаты бенчмарка версий ClickHouse. Дата обращения: 2024-06-20. https://benchmark.clickhouse.com/versions/
- 21 Andrew Crotty. 2022. MgBench. Дата обращения: 2024-06-20. https://github.com/ andrewcrotty/mgbench
- 22 Benoit Dageville, Thierry Cruanes, Marcin Zukowski, Vadim Antonov, Artin Avanes, Jon Bock, Jonathan Claybaugh, Daniel Engovatov, Martin Hentschel, Jiansheng Huang, Allison W. Lee, Ashish Motivala, Abdul Q. Munir, Steven Pelley, Peter Povinec, Greg Rahn, Spyridon Triantafyllis и Philipp Unterbrunner. 2016. The Snowflake Elastic Data Warehouse. В материалах Международной конференции по управлению данными 2016 года (San Francisco, California, USA) (SIGMOD ‘16). Association for Computing Machinery, New York, NY, USA, 215–226. https: //doi.org/10.1145/2882903.2903741
- 23 Patrick Damme, Annett Ungethüm, Juliana Hildebrandt, Dirk Habich и Wolfgang Lehner. 2019. From a Comprehensive Experimental Survey to a Cost-Based Selection Strategy for Lightweight Integer Compression Algorithms. ACM Trans. Database Syst. 44, 3, статья 9 (2019), 46 страниц. https://doi.org/10.1145/3323991
- 24 Philippe Dobbelaere и Kyumars Sheykh Esmaili. 2017. Kafka versus RabbitMQ: сравнительное исследование двух промышленных эталонных реализаций publish/subscribe: отраслевая статья (DEBS ‘17). Association for Computing Machinery, New York, NY, USA, 227–238. https://doi.org/10.1145/3093742.3093908
- 25 Документация LLVM. 2024. Автовекторизация в LLVM. Дата обращения: 2024-06-20. https://llvm.org/docs/Vectorizers.html
- 26 Siying Dong, Andrew Kryczka, Yanqin Jin и Michael Stumm. 2021. RocksDB: эволюция приоритетов разработки в хранилище типа ключ-значение для крупномасштабных приложений. ACM Transactions on Storage 17, 4, статья 26 (2021), 32 страницы. https://doi.org/10.1145/3483840
- 27 Markus Dreseler, Martin Boissier, Tilmann Rabl и Matthias Ufacker. 2020. Количественная оценка узких мест TPC-H и их оптимизаций. Proc. VLDB Endow. 13, 8 (2020), 1206–1220. https://doi.org/10.14778/3389133.3389138
- 28 Ted Dunning. 2021. The t-digest: эффективная оценка распределений. Software Impacts 7 (2021). https://doi.org/10.1016/j.simpa.2020.100049
- 29 Martin Faust, Martin Boissier, Marvin Keller, David Schwalb, Holger Bischof, Katrin Eisenreich, Franz Färber, and Hasso Plattner. 2016. Сокращение занимаемого объема и обеспечение уникальности с помощью хеш-индексов в SAP HANA. В сборнике Database and Expert Systems Applications. 137–151. https://doi.org/10.1007/978-3-319-44406- 2_11
- 30 Philippe Flajolet, Eric Fusy, Olivier Gandouet и Frederic Meunier. 2007. HyperLogLog: the analysis of a near-optimal cardinality estimation algorithm. В: AofA: Analysis of Algorithms, Vol. DMTCS Proceedings vol. AH, 2007 Conference on Analysis of Algorithms (AofA 07). Discrete Mathematics and Theoretical Computer Science, 137–156. https://doi.org/10.46298/dmtcs.3545
- 31 Hector Garcia-Molina, Jefrey D. Ullman и Jennifer Widom. 2009. Database Systems - The Complete Book (2-е изд.).
- 32 Pawan Goyal, Harrick M. Vin, and Haichen Chen. 1996. Справедливое обслуживание очередей по времени начала: алгоритм планирования для сетей коммутации пакетов с интегрированными сервисами. 26, 4 (1996), 157–168. https://doi.org/10.1145/248157.248171
- 33 Goetz Graefe. 1993. Query Evaluation Techniques for Large Databases. ACM Comput. Surv. 25, 2 (1993), 73–169. https://doi.org/10.1145/152610.152611
- 34 Jean-François Im, Kishore Gopalakrishna, Subbu Subramaniam, Mayank Shrivastava, Adwait Tumbde, Xiaotian Jiang, Jennifer Dai, Seunghyun Lee, Neha Pawar, Jialiang Li и Ravi Aringunram. 2018. Pinot: Realtime OLAP for 530 Million Users. В материалах Proceedings of the 2018 International Conference on Management of Data (Houston, TX, USA) (SIGMOD ‘18). Association for Computing Machinery, New York, NY, USA, 583–594. https://doi.org/10.1145/3183713.3190661
- 35 ISO/IEC 9075-9:2001 2001. Информационные технологии — язык баз данных — SQL — Часть 9: Управление внешними данными (SQL/MED). Стандарт. Международная организация по стандартизации.
- 36 Paras Jain, Peter Kraft, Conor Power, Tathagata Das, Ion Stoica, и Matei Zaharia. 2023. Analyzing and Comparing Lakehouse Storage Systems. CIDR.
- 37 Project Jupyter. 2024. Jupyter Notebooks. Дата обращения: 2024-06-20. https: //jupyter.org/
- 38 Timo Kersten, Viktor Leis, Alfons Kemper, Thomas Neumann, Andrew Pavlo и Peter Boncz. 2018. Everything You Always Wanted to Know about Compiled and Vectorized Queries but Were Afraid to Ask. Proc. VLDB Endow. 11, 13 (сент. 2018), 2209–2222. https://doi.org/10.14778/3275366.3284966
- 39 Changkyu Kim, Jatin Chhugani, Nadathur Satish, Eric Sedlar, Anthony D. Nguyen, Tim Kaldewey, Victor W. Lee, Scott A. Brandt, and Pradeep Dubey. 2010. FAST: fast architecture sensitive tree search on modern CPUs and GPUs. In Proceedings of the 2010 ACM SIGMOD International Conference on Management of Data (Indianapolis, Indiana, USA) (SIGMOD ‘10). Association for Computing Machinery, New York, NY, USA, 339–350. https://doi.org/10.1145/1807167.1807206
- 40 Дональд Э. Кнут. 1973. Искусство программирования, том III: Сортировка и поиск. Addison-Wesley.
- 41 André Kohn, Viktor Leis и Thomas Neumann. 2018. Адаптивное выполнение компилируемых запросов. В: 34-я Международная конференция IEEE по инженерии данных (ICDE), 2018. 197–208. https://doi.org/10.1109/ICDE.2018.00027
- 42 Andrew Lamb, Matt Fuller, Ramakrishna Varadarajan, Nga Tran, Ben Vandiver, Lyric Doshi, и Chuck Bear. 2012. The Vertica Analytic Database: C-Store 7 Years Later. Proc. VLDB Endow. 5, 12 (авг. 2012), 1790–1801. https://doi.org/10. 14778/2367502.2367518
- 43 Harald Lang, Tobias Mühlbauer, Florian Funke, Peter A. Boncz, Thomas Neumann, and Alfons Kemper. 2016. Data Blocks: Hybrid OLTP and OLAP on Compressed Storage using both Vectorization and Compilation. В: Proceedings of the 2016 International Conference on Management of Data (San Francisco, California, USA) (SIGMOD ‘16). Association for Computing Machinery, New York, NY, USA, 311–326. https://doi.org/10.1145/2882903.2882925
- 44 Viktor Leis, Peter Boncz, Alfons Kemper и Thomas Neumann. 2014. Morseldriven parallelism: a NUMA-aware query evaluation framework for the manycore age. В материалах Proceedings of the 2014 ACM SIGMOD International Conference on Management of Data (Snowbird, Utah, USA) (SIGMOD ‘14). Association for Computing Machinery, New York, NY, USA, 743–754. https://doi.org/10.1145/2588555. 2610507
- 45 Viktor Leis, Alfons Kemper и Thomas Neumann. 2013. The adaptive radix tree: ARTful indexing for main-memory databases. В материалах 2013 IEEE 29th International Conference on Data Engineering (ICDE). 38–49. https://doi.org/10.1109/ICDE. 2013.6544812
- 46 Chunwei Liu, Anna Pavlenko, Matteo Interlandi и Brandon Haynes. 2023. Глубокий анализ распространённых открытых форматов для аналитических СУБД. 16, 11 (июл 2023), 3044–3056. https://doi.org/10.14778/3611479.3611507
- 47 Zhenghua Lyu, Huan Hubert Zhang, Gang Xiong, Gang Guo, Haozhou Wang, Jinbao Chen, Asim Praveen, Yu Yang, Xiaoming Gao, Alexandra Wang, Wen Lin, Ashwin Agrawal, Junfeng Yang, Hao Wu, Xiaoliang Li, Feng Guo, Jiang Wu, Jesse Zhang, и Venkatesh Raghavan. 2021. Greenplum: гибридная база данных для транзакционных и аналитических рабочих нагрузок (SIGMOD ‘21). Association for Computing Machinery, New York, NY, USA, 2530–2542. https: //doi.org/10.1145/3448016.3457562
- 48 Roger MacNicol и Blaine French. 2004. Sybase IQ Multiplex — разработано для аналитики. В материалах Тридцатой международной конференции по очень большим базам данных — том 30 (Торонто, Канада) (VLDB ‘04). VLDB Endowment, 1227–1230.
- 49 Sergey Melnik, Andrey Gubarev, Jing Jing Long, Geofrey Romer, Shiva Shivakumar, Matt Tolton, Theo Vassilakis, Hossein Ahmadi, Dan Delorey, Slava Min, Mosha Pasumansky и Jef Shute. 2020. Dremel: A Decade of Interactive SQL Analysis at Web Scale. Proc. VLDB Endow. 13, 12 (aug 2020), 3461–3472. https://doi.org/10.14778/3415478.3415568
- 50 Microsoft. 2024. Kusto Query Language. Дата обращения: 2024-06-20. https: //github.com/microsoft/Kusto-Query-Language
- 51 Guido Moerkotte. 1998. Small Materialized Aggregates: A Light Weight Index Structure for Data Warehousing. В трудах 24-й Международной конференции по очень большим базам данных (VLDB ‘98). 476–487.
- 52 Jalal Mostafa, Sara Wehbi, Suren Chilingaryan и Andreas Kopmann. 2022. SciTS: бенчмарк для баз данных временных рядов в научных экспериментах и промышленном Интернете вещей. В трудах 34-й Международной конференции по управлению научными и статистическими базами данных (SSDBM ‘22). Статья 12. https: //doi.org/10.1145/3538712.3538723
- 53 Thomas Neumann. 2011. Эффективная компиляция эффективных планов запросов для современного оборудования. Proc. VLDB Endow. 4, 9 (июн 2011), 539–550. https://doi.org/10.14778/ 2002938.2002940
- 54 Thomas Neumann и Michael J. Freitag. 2020. Umbra: дисковая система с производительностью как у систем, работающих в памяти. В материалах 10-й Conference on Innovative Data Systems Research, CIDR 2020, Амстердам, Нидерланды, 12–15 января 2020 г., онлайн-сборник трудов. www.cidrdb.org. http://cidrdb.org/cidr2020/papers/p29-neumanncidr20.pdf
- 55 Thomas Neumann, Tobias Mühlbauer и Alfons Kemper. 2015. Fast Serializable Multi-Version Concurrency Control for Main-Memory Database Systems. In Proceedings of the 2015 ACM SIGMOD International Conference on Management of Data (Melbourne, Victoria, Australia) (SIGMOD ‘15). Association for Computing Machinery, New York, NY, USA, 677–689. https://doi.org/10.1145/2723372. 2749436
- 56 LevelDB на GitHub. 2024. LevelDB. Дата обращения: 2024-06-20. https://github. com/google/leveldb
- 57 Patrick O’Neil, Elizabeth O’Neil, Xuedong Chen и Stephen Revilak. 2009. The Star Schema Benchmark and Augmented Fact Table Indexing. In Performance Evaluation and Benchmarking. Springer Berlin Heidelberg, 237–252. https: //doi.org/10.1007/978-3-642-10424-4_17
- 58 Patrick E. O’Neil, Edward Y. C. Cheng, Dieter Gawlick и Elizabeth J. O’Neil. 1996. The log-structured Merge-Tree (LSM-tree). Acta Informatica 33 (1996), 351–385. https://doi.org/10.1007/s002360050048
- 59 Diego Ongaro and John Ousterhout. 2014. В поисках понятного алгоритма консенсуса. В материалах ежегодной технической конференции USENIX 2014 (USENIX ATC’14). 305–320. https://dl.acm.org/doi/10.5555/2643634.2643666
- 60 Patrick O’Neil, Edward Cheng, Dieter Gawlick и Elizabeth O’Neil. 1996. The Log-Structured Merge-Tree (LSM-Tree). Acta Inf. 33, 4 (1996), 351–385. https: //doi.org/10.1007/s002360050048
- 61 Pandas. 2024. Pandas Dataframes. Дата обращения: 2024-06-20. https://pandas. pydata.org/
- 62 Pedro Pedreira, Orri Erling, Masha Basmanova, Kevin Wilfong, Laith Sakka, Krishna Pai, Wei He и Biswapesh Chattopadhyay. 2022. Velox: Meta’s Unified Execution Engine. Proc. VLDB Endow. 15, 12 (авг. 2022), 3372–3384. https: //doi.org/10.14778/3554821.3554829
- 63 Tuomas Pelkonen, Scott Franklin, Justin Teller, Paul Cavallaro, Qi Huang, Justin Meza, and Kaushik Veeraraghavan. 2015. Gorilla: A Fast, Scalable, in-Memory Time Series Database. Proceedings of the VLDB Endowment 8, 12 (2015), 1816–1827. https://doi.org/10.14778/2824032.2824078
- 64 Orestis Polychroniou, Arun Raghavan и Kenneth A. Ross. 2015. Переосмысление SIMD-векторизации для баз данных в оперативной памяти. В: Труды Международной конференции ACM SIGMOD 2015 года по управлению данными (SIGMOD ‘15). 1493–1508. https://doi.org/10.1145/2723372.2747645
- 65 PostgreSQL. 2024. PostgreSQL — Foreign Data Wrappers. Получено 2024-06-20 с https://wiki.postgresql.org/wiki/Foreign_data_wrappers
- 66 Mark Raasveldt, Pedro Holanda, Tim Gubner, and Hannes Mühleisen. 2018. Fair Benchmarking Considered difficult: Common Pitfalls In Database Performance Testing. В сборнике трудов Workshop on Testing Database Systems (Houston, TX, USA) (DBTest’18). Статья 2, 6 стр. https://doi.org/10.1145/3209950.3209955
- 67 Mark Raasveldt и Hannes Mühleisen. 2019. DuckDB: Встраиваемая аналитическая база данных (SIGMOD ‘19). Association for Computing Machinery, New York, NY, USA, 1981–1984. https://doi.org/10.1145/3299869.3320212
- 68 Jun Rao and Kenneth A. Ross. 1999. Cache Conscious Indexing for Decision-Support in Main Memory. В трудах 25-й Международной конференции по очень большим базам данных (VLDB ‘99). Сан-Франциско, CA, США, 78–89.
- 69 Navin C. Sabharwal and Piyush Kant Pandey. 2020. Working with Prometheus Query Language (PromQL). В кн.: Monitoring Microservices and Containerized Applications. https://doi.org/10.1007/978-1-4842-6216-0_5
- 70 Todd W. Schneider. 2022. New York City Taxi and For-Hire Vehicle Data. Дата обращения: 2024-06-20. https://github.com/toddwschneider/nyc-taxi-data
- 71 Mike Stonebraker, Daniel J. Abadi, Adam Batkin, Xuedong Chen, Mitch Cherniack, Miguel Ferreira, Edmond Lau, Amerson Lin, Sam Madden, Elizabeth O’Neil, Pat O’Neil, Alex Rasin, Nga Tran и Stan Zdonik. 2005. C-Store: столбцово-ориентированная СУБД. В материалах 31-й Международной конференции по очень большим базам данных (VLDB ‘05). 553–564.
- 72 Teradata. 2024. Teradata Database. Дата обращения: 2024-06-20. https://www. teradata.com/resources/datasheets/teradata-database
- 73 Frederik Transier. 2010. Algorithms and Data Structures for In-Memory Text Search Engines. Диссертация на соискание учёной степени доктора философии. https://doi.org/10.5445/IR/1000015824
- 74 Adrian Vogelsgesang, Michael Haubenschild, Jan Finis, Alfons Kemper, Viktor Leis, Tobias Muehlbauer, Thomas Neumann, and Manuel Then. 2018. Ближе к реальности: как бенчмарки не отражают реальный мир. В сборнике материалов Workshop on Testing Database Systems (Houston, TX, USA) (DBTest’18). Статья 1, 6 страниц. https://doi.org/10.1145/3209950.3209952
- 75 Сайт LZ4. 2024. LZ4. Дата обращения: 2024-06-20. https://lz4.org/
- 76 Веб-сайт PRQL. 2024. PRQL. Дата обращения: 2024-06-20. URL: https://prql-lang.org 77 Till Westmann, Donald Kossmann, Sven Helmer, and Guido Moerkotte. 2000. The Implementation and Performance of Compressed Databases. SIGMOD Rec.
- 29, 3 (сент. 2000), 55–67. https://doi.org/10.1145/362084.362137 78 Fangjin Yang, Eric Tschetter, Xavier Léauté, Nelson Ray, Gian Merlino и Deep Ganguli. 2014. Druid: аналитическое хранилище данных реального времени. В Proceedings of the 2014 ACM SIGMOD International Conference on Management of Data (Snowbird, Utah, USA) (SIGMOD ‘14). Association for Computing Machinery, New York, NY, USA, 157–168. https://doi.org/10.1145/2588555.2595631
- 79 Tianqi Zheng, Zhibin Zhang, и Xueqi Cheng. 2020. SAHA: A String Adaptive Hash Table for Analytical Databases. Applied Sciences 10, 6 (2020). https: //doi.org/10.3390/app10061915
- 80 Jingren Zhou и Kenneth A. Ross. 2002. Implementing Database Operations Using SIMD Instructions. В трудах Proceedings of the 2002 ACM SIGMOD International Conference on Management of Data (SIGMOD ‘02). 145–156. https://doi.org/10. 1145/564691.564709
- 81 Marcin Zukowski, Sandor Heman, Niels Nes и Peter Boncz. 2006. Суперскалярное сжатие кэша RAM-CPU. В трудах 22-й Международной конференции по инженерии данных (ICDE ‘06). 59. https://doi.org/10.1109/ICDE. 2006.150