데이터 레이크 시작하기
데이터 레이크 테이블을 쿼리하고, MergeTree로 가속화한 뒤, 결과를 Iceberg에 다시 쓰는 과정을 실습으로 안내합니다. 모든 단계는 공개 데이터셋을 사용하며 Cloud와 OSS 모두에서 동작합니다.
이 가이드의 스크린샷은 ClickHouse Cloud SQL 콘솔에서 캡처했습니다. 모든 쿼리는 Cloud와 자가 관리형 배포 모두에서 작동합니다.
Iceberg 데이터 직접 쿼리하기
가장 빠르게 시작하는 방법은 icebergS3() 테이블 함수를 사용하는 것입니다. S3의 Iceberg 테이블을 지정하면 별도의 설정 없이 즉시 쿼리할 수 있습니다.
스키마를 확인합니다:
쿼리를 실행하세요:
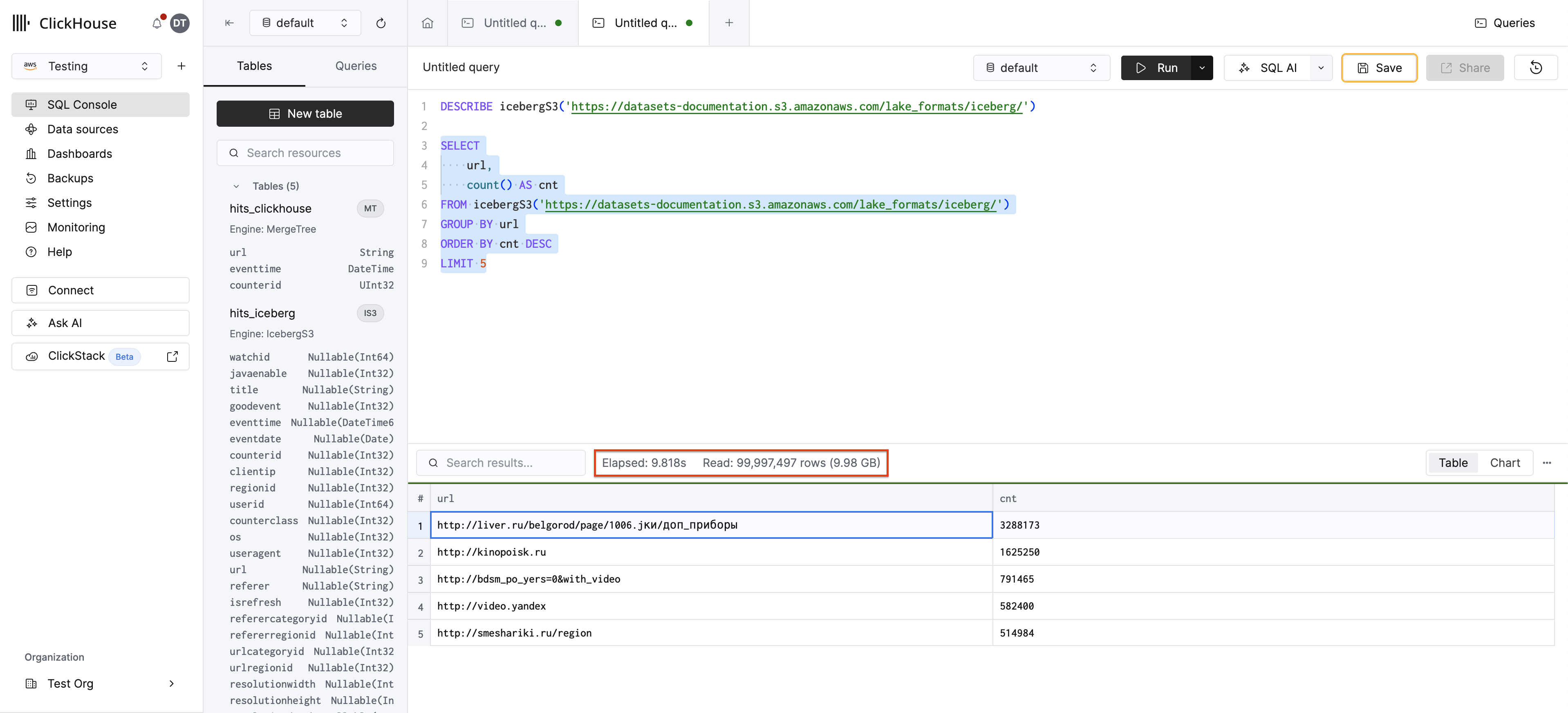
ClickHouse는 S3에서 Iceberg 메타데이터를 직접 읽어 스키마를 자동으로 추론합니다. 동일한 방식이 deltaLake(), hudi(), paimon()에도 적용됩니다.
자세히 알아보기: 오픈 테이블 형식 직접 쿼리하기에서는 네 가지 형식 모두, 분산 읽기를 위한 클러스터 변형, 스토리지 백엔드 옵션(S3, Azure, HDFS, 로컬)을 다룹니다.
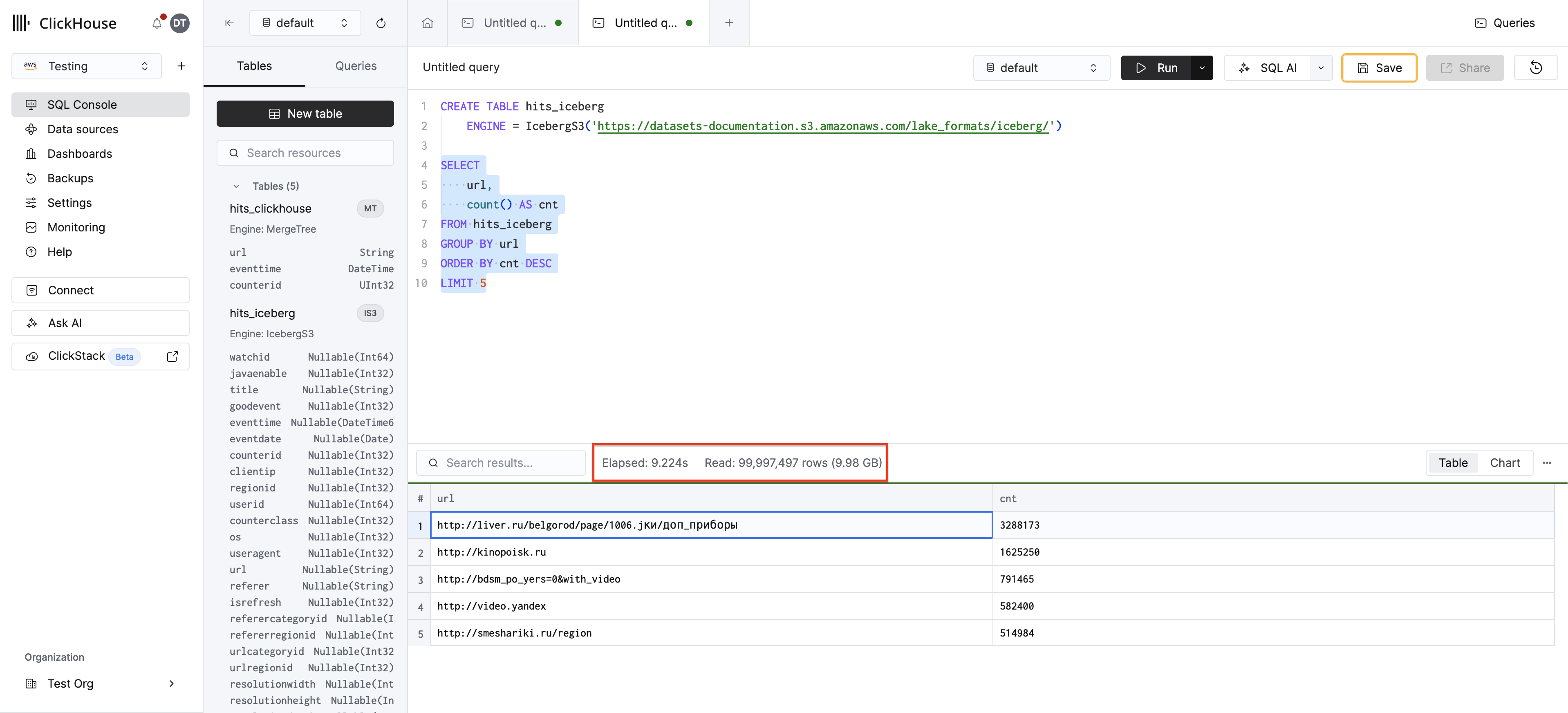
카탈로그에 연결
대부분의 조직은 테이블 메타데이터와 데이터 검색을 중앙화하기 위해 데이터 카탈로그를 통해 Iceberg 테이블을 관리합니다. ClickHouse는 DataLakeCatalog 데이터베이스 엔진을 사용하여 카탈로그에 연결할 수 있으며, 모든 카탈로그 테이블을 ClickHouse 데이터베이스로 노출합니다. 이는 더 확장성이 높은 방식으로, 새로운 Iceberg 테이블이 생성될 때마다 추가 작업 없이 ClickHouse에서 항상 접근할 수 있습니다.
다음은 AWS Glue에 연결하는 예시입니다:
각 카탈로그 유형마다 고유한 연결 설정이 필요합니다. 지원되는 카탈로그의 전체 목록과 구성 옵션은 카탈로그 가이드를 참조하십시오.
테이블 탐색 및 쿼리:
ClickHouse는 기본적으로 둘 이상의 네임스페이스를 지원하지 않기 때문에 <database>.<table> 주위에 백틱(backtick)이 필요합니다.
자세히 알아보기: 데이터 카탈로그 연결에서는 Delta 및 Iceberg 예제를 포함한 전체 Unity Catalog 설정 과정을 안내합니다.
쿼리 실행
위에서 어떤 방법을 사용했든 — 테이블 함수, 테이블 엔진, 카탈로그 — 동일한 ClickHouse SQL이 모든 방법에서 동작합니다.
쿼리 구문은 동일하며, FROM 절만 변경됩니다. 모든 ClickHouse SQL 함수, 조인, 집계는 데이터 소스에 관계없이 동일하게 작동합니다.
ClickHouse에 하위 집합 로드하기
Iceberg를 직접 쿼리하는 것은 편리하지만, 성능은 네트워크 처리량과 파일 레이아웃에 의해 제한됩니다. 분석 워크로드의 경우 데이터를 네이티브 MergeTree 테이블에 로드하십시오.
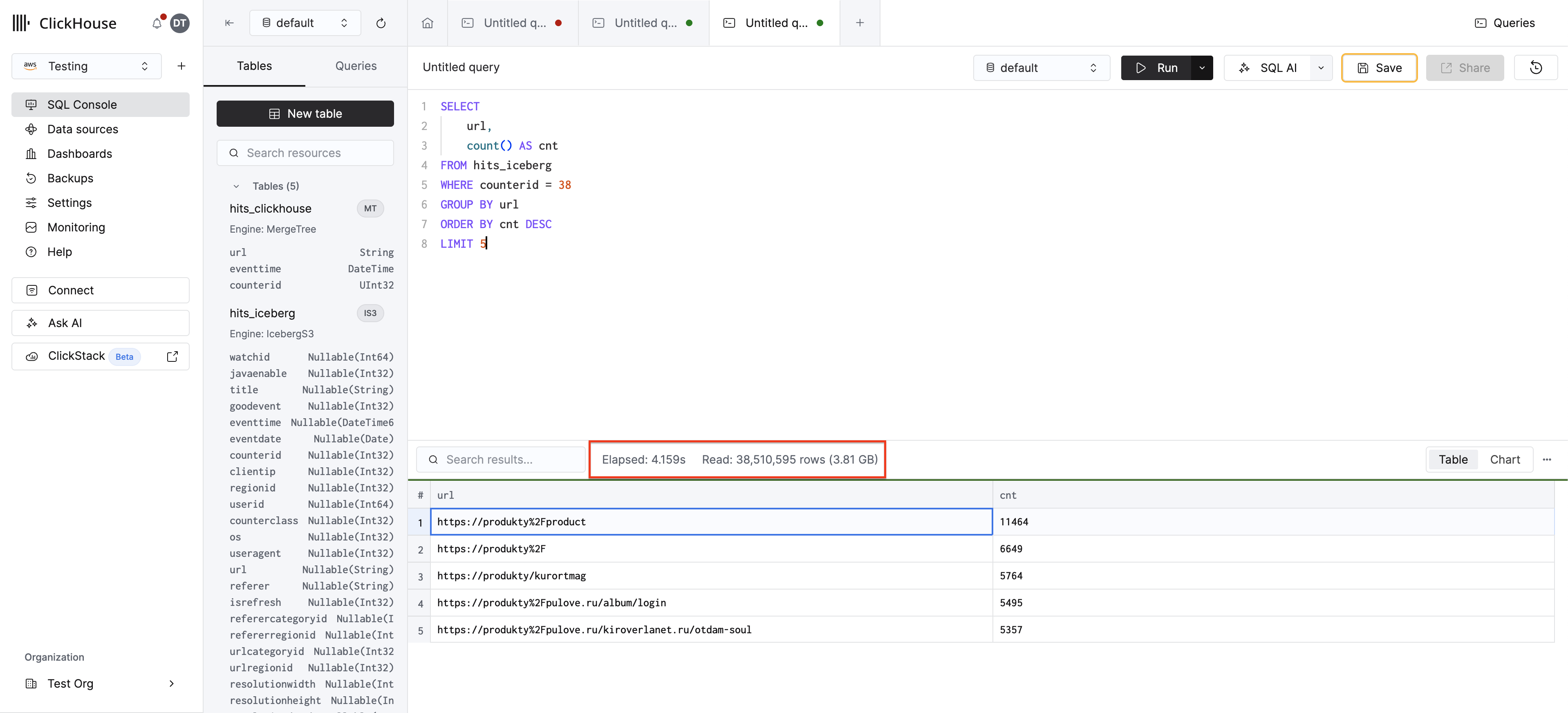
먼저, 기준값을 얻기 위해 Iceberg 테이블에 필터링된 쿼리를 실행하십시오:
이 쿼리는 Iceberg가 counterid 필터를 인식하지 못하므로 S3의 전체 데이터셋을 스캔합니다. 완료까지 수 초가 소요될 수 있습니다.
이제 MergeTree 테이블을 생성하고 데이터를 로드하세요:
MergeTree 테이블에 동일한 쿼리를 다시 실행하십시오:
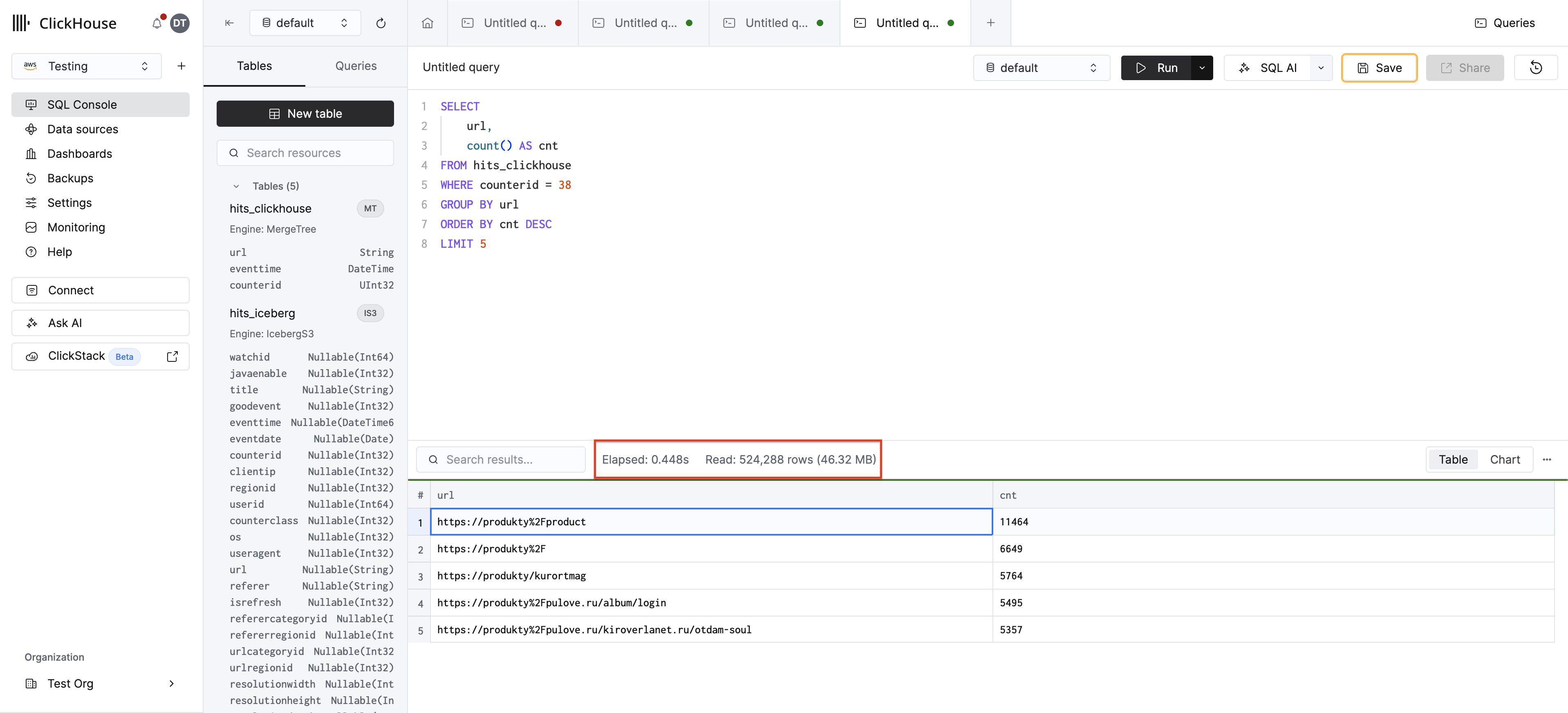
counterid가 ORDER BY 키의 첫 번째 컬럼이므로, ClickHouse의 희소 기본 인덱스는 관련 그래뉼로 직접 건너뜁니다 — 1억 개의 행을 전부 스캔하는 대신 counterid = 38에 해당하는 행만 읽습니다. 그 결과 처리 속도가 크게 향상됩니다.
분석 가속화 가이드에서는 LowCardinality 타입, 전문 검색 인덱스, 최적화된 정렬 키를 활용하여 2억 8,300만 행 데이터셋에서 약 40배의 성능 향상을 달성하는 방법을 설명합니다.
자세히 알아보기: MergeTree로 분석 가속화에서는 스키마 최적화, 전문 검색(full-text) 인덱싱, 그리고 적용 전후의 성능 비교를 다룹니다.
Iceberg에 데이터 쓰기
ClickHouse는 Iceberg 테이블에 데이터를 다시 쓸 수도 있어 역방향 ETL 워크플로를 지원합니다. 집계된 결과나 하위 집합을 Spark, Trino, DuckDB 등 다른 도구에서 활용할 수 있도록 게시하는 것이 가능합니다.
출력용 Iceberg 테이블을 생성하십시오:
집계 결과 쓰기:
생성된 Iceberg 테이블은 Iceberg 호환 엔진이면 어디서든 읽을 수 있습니다.
자세히 알아보기: 오픈 테이블 형식으로 데이터 쓰기에서는 UK Price Paid 데이터셋을 사용하여 원시 데이터 및 집계 결과를 작성하는 방법을 다루며, ClickHouse 타입을 Iceberg에 매핑할 때의 스키마 고려 사항도 포함합니다.
다음 단계
이제 전체 워크플로를 살펴보았으니, 각 영역을 더 자세히 확인해 보십시오:
- 직접 쿼리하기 — 지원되는 4가지 형식, 클러스터 구성, 테이블 엔진, 캐싱
- 카탈로그 연결하기 — Delta 및 Iceberg를 포함한 Unity Catalog 전체 안내
- 분석 가속화하기 — 스키마 최적화, 인덱스, 약 40배 속도 향상 데모
- 데이터 레이크에 쓰기 — 원시 쓰기, 집계 쓰기, 타입 매핑
- 지원 매트릭스 — 형식 및 스토리지 백엔드 전반에 걸친 기능 비교
