ClickStack OpenTelemetry collector
OTel FYI は、receiver、processor、exporter、pipeline を網羅した、明快で簡潔な OpenTelemetry collector のドキュメントを提供します。ClickStack OTel collector を設定する際の優れた補助リソースです。
このページでは、公式の ClickStack OpenTelemetry (OTel) collector の設定に関する詳細を説明します.
コレクターのロール
OpenTelemetry コレクターは、主に 2 つのロールでデプロイできます:
-
エージェント (Agent) - エージェントインスタンスはエッジでデータを収集します。たとえばサーバー上や Kubernetes ノード上で動作したり、OpenTelemetry SDK でインスツルメントされたアプリケーションからイベントを直接受信します。後者の場合、エージェントインスタンスはアプリケーションと同じホスト上、またはアプリケーションと一緒に (サイドカーやデーモンセットなどとして) 実行されます。エージェントは、収集したデータを直接 ClickHouse に送信することも、ゲートウェイインスタンスに送信することもできます。前者のケースは Agent deployment pattern と呼ばれます。
-
ゲートウェイ (Gateway) - ゲートウェイインスタンスは、スタンドアロンのサービス (たとえば Kubernetes におけるデプロイメント) を提供し、通常はクラスタごと、データセンターごと、リージョンごとにデプロイされます。これらは単一の OTLP エンドポイント経由で、アプリケーション (またはエージェントとして動作する他のコレクター) からイベントを受信します。通常、複数のゲートウェイインスタンスがデプロイされ、その間で負荷を分散するために、あらかじめ用意されたロードバランサーが使用されます。すべてのエージェントとアプリケーションがこの単一のエンドポイントにシグナルを送信する場合、これはしばしば Gateway deployment pattern と呼ばれます。
重要: コレクターは、ClickStack のデフォルトディストリビューションを含め、ここで説明する ゲートウェイロール を前提としており、エージェントや SDK からデータを受信します。
エージェントロールで OTel collector をデプロイするユーザーは、通常、ClickStack バージョンではなく collector の default contrib distribution を使用しますが、Fluentd や Vector など、他の OTLP 互換テクノロジーを自由に利用することもできます。
Collector のデプロイ
- マネージド型 ClickStack
- オープンソース版 ClickStack
可能な場合には、Managed ClickStack 環境に送信する際の gateway ロールとして、公式の ClickStack ディストリビューション版 collector を使用することを推奨します。独自の collector を使用する場合は、ClickHouse exporter が含まれていることを確認してください。
ClickStack ディストリビューション版の OTel connector をスタンドアロン モードでデプロイするには、次の Docker コマンドを実行します。
ClickStack のイメージは、現在は clickhouse/clickstack-* として公開されています(以前は docker.hyperdx.io/hyperdx/*)。
CLICKHOUSE_ENDPOINT、CLICKHOUSE_USERNAME、CLICKHOUSE_PASSWORD という環境変数を指定することで、送信先の ClickHouse インスタンスを変更できる点に注意してください。CLICKHOUSE_ENDPOINT には、プロトコルおよびポートを含む完全な ClickHouse Cloud の HTTP エンドポイントを指定する必要があります。たとえば、https://99rr6dm6v3.us-central1.gcp.clickhouse.cloud:8443 のようになります。
Managed ClickStack の認証情報の取得方法の詳細についてはこちらを参照してください。
本番環境では、適切な権限を持つユーザーを使用する必要があります。
設定の変更
Managed ClickStack インスタンスの設定
OpenTelemetry collector を含むすべての Docker イメージは、環境変数 CLICKHOUSE_ENDPOINT、CLICKHOUSE_USERNAME、CLICKHOUSE_PASSWORD を介して Managed ClickStack インスタンスを使用するように構成できます。
たとえば、オールインワンイメージの場合:
コレクター設定の拡張
ClickStack の OTel collector ディストリビューションでは、カスタム設定ファイルをマウントし、環境変数を設定することで、基本設定を拡張できます。
カスタムの receiver、processor、pipeline を追加するには:
- 追加の設定を含むカスタム設定ファイルを作成する
- ファイルを
/etc/otelcol-contrib/custom.config.yamlにマウントする - 環境変数
CUSTOM_OTELCOL_CONFIG_FILE=/etc/otelcol-contrib/custom.config.yamlを設定する
カスタム設定の例:
スタンドアロン コレクターでデプロイする:
カスタム構成では、新しい receiver、processor、pipeline だけを定義します。ベースとなる processor(memory_limiter、batch)および exporter(clickhouse)はすでに定義されているため、名前で参照してください。カスタム構成はベース構成とマージされ、既存のコンポーネントを上書きすることはできません。
より複雑な構成については、デフォルトの ClickStack コレクター構成および ClickHouse exporter ドキュメントを参照してください。
設定構造
receivers、operators、および processors を含む OTel collector の設定方法の詳細については、公式の OpenTelemetry collector ドキュメント を参照することを推奨します。
Docker Compose
Docker Compose を使用する場合は、上記と同じ環境変数を使用してコレクターの設定を変更します。
HyperDX 専用ディストリビューションを使用していて、スタンドアロン デプロイメントとして自前の OpenTelemetry コレクターを管理している場合でも、可能であればゲートウェイ ロールには公式の ClickStack ディストリビューション版コレクターの使用を推奨します。ただし自前のコレクターを使用する場合は、ClickHouse exporter が含まれていることを確認してください。
ClickStack ディストリビューション版の OTel コネクターをスタンドアロン モードでデプロイするには、次の Docker コマンドを実行します。
ClickStack のイメージは、現在 clickhouse/clickstack-*(以前は docker.hyperdx.io/hyperdx/*)として公開されています。
CLICKHOUSE_ENDPOINT、CLICKHOUSE_USERNAME、CLICKHOUSE_PASSWORD という環境変数を使用することで、ターゲットの ClickHouse インスタンスを上書きできることに注意してください。CLICKHOUSE_ENDPOINT には、プロトコルおよびポートを含む、ClickHouse の完全な HTTP エンドポイントを指定する必要があります(例: http://localhost:8123)。
これらの環境変数は、コネクタを含む任意の Docker ディストリビューションで使用できます。
OPAMP_SERVER_URL は、あなたの HyperDX デプロイメントを指す必要があります(例: http://localhost:4320)。HyperDX は、デフォルトでポート 4320 の /v1/opamp で OpAMP (Open Agent Management Protocol) サーバーを公開します。HyperDX を実行しているコンテナからこのポートが公開されていることを確認してください(例: -p 4320:4320 を使用)。
コレクターが OpAMP ポートに接続するには、そのポートが HyperDX コンテナから公開されている必要があります(例: -p 4320:4320)。ローカルテストでは、macOS ユーザーは OPAMP_SERVER_URL=http://host.docker.internal:4320 を設定できます。Linux ユーザーは、--network=host を指定してコレクターコンテナを起動できます。
本番環境では、適切な認証情報 を持つユーザーを使用する必要があります。
設定の変更
ClickHouse インスタンスの設定
OpenTelemetry collector を含むすべての Docker イメージは、環境変数 OPAMP_SERVER_URL、CLICKHOUSE_ENDPOINT、CLICKHOUSE_USERNAME、CLICKHOUSE_PASSWORD を使用して、ClickHouse インスタンスを指すように設定できます。
例えば、オールインワンイメージの場合は次のようになります。
コレクター設定の拡張
ClickStack の OTel collector ディストリビューションでは、カスタム設定ファイルをマウントし、環境変数を設定することで、基本設定を拡張できます。
カスタムの receiver、processor、pipeline を追加するには:
- 追加の設定を含むカスタム設定ファイルを作成する
- ファイルを
/etc/otelcol-contrib/custom.config.yamlにマウントする - 環境変数
CUSTOM_OTELCOL_CONFIG_FILE=/etc/otelcol-contrib/custom.config.yamlを設定する
カスタム設定の例:
スタンドアロン コレクターでデプロイする:
カスタム構成では、新しい receiver、processor、pipeline だけを定義します。ベースとなる processor(memory_limiter、batch)および exporter(clickhouse)はすでに定義されているため、名前で参照してください。カスタム構成はベース構成とマージされ、既存のコンポーネントを上書きすることはできません。
より複雑な構成については、デフォルトの ClickStack コレクター構成および ClickHouse exporter ドキュメントを参照してください。
設定構造
receivers、operators、および processors を含む OTel collector の設定方法の詳細については、公式の OpenTelemetry collector ドキュメント を参照することを推奨します。
Docker Compose
Docker Compose を使用する場合は、上記と同じ環境変数を使用してコレクターの設定を変更します。
collector のセキュリティ保護
- マネージド ClickStack
- オープンソース ClickStack
デフォルトでは、オープンソースディストリビューション以外の形でデプロイされた場合、ClickStack OpenTelemetry Collector は保護されておらず、OTLP ポートで認証を要求しません。
インジェストを保護するには、collector をデプロイする際に環境変数 OTLP_AUTH_TOKEN を使用して認証トークンを指定します。例:
加えて、次の設定を推奨します:
- collector が ClickHouse と HTTPS で通信するように構成する。
- 権限を制限したインジェスト専用ユーザーを作成する (詳細は以下を参照) 。
- OTLP エンドポイントに対して TLS を有効化し、SDK/エージェントと collector 間の通信を暗号化する。これは カスタム collector 設定 で構成できます。
インジェストユーザーの作成
Managed ClickStack へのインジェストのために、OTel collector 用の専用データベースとユーザーを作成することを推奨します。これは ClickStack により作成・利用されるテーブル を作成し、そこに挿入できる権限を持つ必要があります。
これは collector がデータベース otel を使用するように構成されていることを前提としています。これは環境変数 HYPERDX_OTEL_EXPORTER_CLICKHOUSE_DATABASE によって制御できます。これを 他の環境変数と同様に collector に渡します。
ClickStack ディストリビューションの OpenTelemetry collector には OpAMP (Open Agent Management Protocol) への組み込みサポートが含まれており、これを使用して OTLP エンドポイントを安全に構成および管理します。起動時には OPAMP_SERVER_URL 環境変数を指定する必要があり、これは OpAMP API を /v1/opamp でホストしている HyperDX アプリを指すように設定します。
この統合により、OTLP エンドポイントは HyperDX アプリのデプロイ時に自動生成されるインジェスト API key を使用して保護されます。collector に送信されるすべてのテレメトリデータには、認証のためにこの API key を含める必要があります。キーは HyperDX アプリの Team Settings → API Keys で確認できます。
デプロイメントをさらに安全にするため、次のことを推奨します:
- collector が ClickHouse と HTTPS で通信するように構成する。
- 権限を制限したインジェスト専用ユーザーを作成する (詳細は以下を参照) 。
- OTLP エンドポイントに対して TLS を有効化し、SDK/エージェントと collector 間の通信を暗号化する。これは カスタム collector 設定 で構成できます。
インジェストユーザーの作成
ClickHouse へのインジェストのために、OTel collector 用の専用データベースとユーザーを作成することを推奨します。これは ClickStack により作成・利用されるテーブル を作成し、そこに挿入できる権限を持つ必要があります。
これは collector がデータベース otel を使用するように構成されていることを前提としています。これは環境変数 HYPERDX_OTEL_EXPORTER_CLICKHOUSE_DATABASE によって制御できます。これを collector をホストしているイメージに、他の環境変数と同様に指定します。
処理 - フィルタリング、変換、エンリッチメント
ユーザーは、インジェスト時にイベントメッセージをフィルタリング、変換、およびエンリッチしたくなることがほぼ確実です。ClickStack コネクタの設定は変更できないため、さらなるイベントフィルタリングおよび処理が必要なユーザーには、次のいずれかを推奨します。
- 独自の OTel collector をデプロイし、そこでフィルタリングおよび処理を実行し、イベントを OTLP 経由で ClickStack collector に送信して ClickHouse にインジェストする。
- 独自の OTel collector をデプロイし、ClickHouse exporter を使用してイベントを直接 ClickHouse に送信する。
処理を OTel collector で行う場合、ゲートウェイインスタンスで変換を行い、エージェントインスタンスで行う処理を最小限に抑えることを推奨します。これにより、サーバー上で動作するエッジ側のエージェントに必要なリソースを可能な限り小さくできます。一般的に、ユーザーはフィルタリング(不要なネットワーク使用を最小化するため)、タイムスタンプ設定(オペレーターによる)、およびエージェント側でコンテキストが必要となるエンリッチのみを実行することが多いです。たとえば、ゲートウェイインスタンスが別の Kubernetes クラスターに存在する場合、k8s エンリッチメントはエージェント内で行う必要があります。
OpenTelemetry は、ユーザーが活用できる以下の処理およびフィルタリング機能をサポートしています。
-
Processors - Processor は、receivers によって収集されたデータを取得し、それを変更または変換してから exporter に送信します。Processor は、collector 設定の
processorsセクションで設定された順序で適用されます。これらは任意ですが、最小限のセットが一般的に推奨されています。OTel collector を ClickHouse と併用する場合、Processor は次のものに限定することを推奨します。 -
memory_limiter は、collector におけるメモリ不足(Out Of Memory)を防ぐために使用されます。推奨事項については Estimating Resources を参照してください。
-
コンテキストに基づいてエンリッチを行う任意の Processor。たとえば、Kubernetes Attributes Processor は、k8s メタデータによりスパン、メトリクス、ログのリソース属性を自動設定できます(例: イベントに送信元ポッド ID を付与してエンリッチする)。
-
トレースで必要な場合の Tail サンプリングまたは Head サンプリング。
-
基本的なフィルタリング - オペレーターで実行できない場合に、不要なイベントをドロップする(下記参照)。
-
Batching - ClickHouse を扱う際にデータをバッチで送信するために不可欠です。"Optimizing inserts" を参照してください。
-
Operators - Operators は、receiver で利用可能な最も基本的な処理単位を提供します。基本的なパースがサポートされており、Severity や Timestamp などのフィールドを設定できます。ここでは JSON および正規表現によるパースに加え、イベントフィルタリングおよび基本的な変換がサポートされています。イベントフィルタリングはここで実行することを推奨します。
ユーザーが Operator や transform processors を用いて過度なイベント処理を行うことは避けることを推奨します。これらは、特に JSON パースでは、かなりのメモリおよび CPU のオーバーヘッドを招く可能性があります。いくつかの例外(具体的には、k8s メタデータの追加など、コンテキスト認識型のエンリッチ)を除き、ClickHouse ではマテリアライズドビューやカラムを用いて、挿入時にすべての処理を実行することが可能です。詳細については、Extracting structure with SQL を参照してください。
例
次の構成は、この非構造化ログファイルを収集するための例です。この構成は、エージェントロールで動作するコレクターがデータを ClickStack ゲートウェイに送信する際に使用できます。
regex_parser オペレーターを用いてログ行から構造化データを抽出し、イベントをフィルタリングしている点と、プロセッサでイベントをバッチ処理してメモリ使用量を制限している点に注目してください。
すべての OTLP 通信で、インジェスト API key を含む Authorization ヘッダー を必ず付与する必要がある点に注意してください。
より高度な設定については、OpenTelemetry Collector のドキュメント を参照してください。
挿入の最適化
ClickStack collector 経由で Observability データを ClickHouse に挿入する際に、高い挿入性能と強い一貫性保証を両立するには、いくつかの単純なルールに従う必要があります。OTel collector を正しく構成すれば、これらのルールに従うことは容易になります。これにより、ClickHouse を初めて利用するユーザーが直面しがちな一般的な問題も回避できます。
バッチ処理
デフォルトでは、ClickHouse に送信された各 insert に対して、ClickHouse はその insert のデータと、あわせて保存する必要があるその他のメタデータを含むストレージパーツを即座に作成します。したがって、各 insert に少量のデータしか含まない大量の insert を送信するよりも、各 insert により多くのデータを含めた少数の insert を送信するほうが、必要な書き込み回数を削減できます。データは一度に少なくとも 1,000 行以上の、十分に大きなバッチで挿入することを推奨します。詳細はこちらを参照してください。
デフォルトでは、ClickHouse への insert は同期的に実行され、内容が同一であれば冪等です。merge tree エンジンファミリーのテーブルに対しては、ClickHouse はデフォルトで自動的に insert の重複排除を行います。これは、次のようなケースでも insert が安全に扱えることを意味します。
- (1) データを受け取るノードに問題がある場合、insert クエリはタイムアウト (またはより具体的なエラー) となり、ACK (確認応答) を受け取りません。
- (2) データ自体はノードによって書き込まれたものの、ネットワーク障害によりクエリ送信元へ ACK を返せない場合、送信元はタイムアウトまたはネットワークエラーを受け取ります。
collector の視点からは、(1) と (2) を区別するのは難しい場合があります。しかし、どちらの場合でも、ACK が返ってこなかった insert はそのまま直ちにリトライできます。リトライした insert クエリが同じ順序で同じデータを含んでいる限り、元の (ACK されなかった) insert が成功していれば、ClickHouse はリトライされた insert を自動的に無視します。
このため、ClickStack に含まれる OTel collector では batch processor を使用しています。これにより、上記の要件を満たす行の一貫したバッチとして insert が送信されます。collector に高いスループット (毎秒イベント数) が想定されており、各 insert で少なくとも 10,000 イベントを送信できる場合、通常はパイプラインで必要となるバッチ処理はこれだけで十分です。メモリに余裕があれば、100,000 までの値を使用できます。この場合、collector は batch processor の timeout に達する前にバッチをフラッシュし、パイプライン全体のレイテンシを低く保ちつつ、バッチサイズの一貫性を確保します。
非同期挿入を使用する
通常、コレクターのスループットが低い場合、ユーザーはより小さなバッチを送信せざるを得ませんが、それでもエンドツーエンドのレイテンシーを最小限に抑えつつ、データが ClickHouse に届くことを期待します。このような場合、バッチプロセッサの timeout が切れると小さなバッチが送信されます。これが問題を引き起こすことがあり、その際に非同期挿入が必要となります。ClickStack コレクターを Gateway として動作させてそこにデータを送信している場合、この問題はまれです。アグリゲーターとして動作することでこの問題を緩和できるためです。詳細は Collector roles を参照してください。
大きなバッチを保証できない場合、Asynchronous Inserts を使用してバッチ処理を ClickHouse に委譲できます。非同期挿入では、データはまずバッファに挿入され、その後データベースストレージに後から、すなわち非同期に書き込まれます。
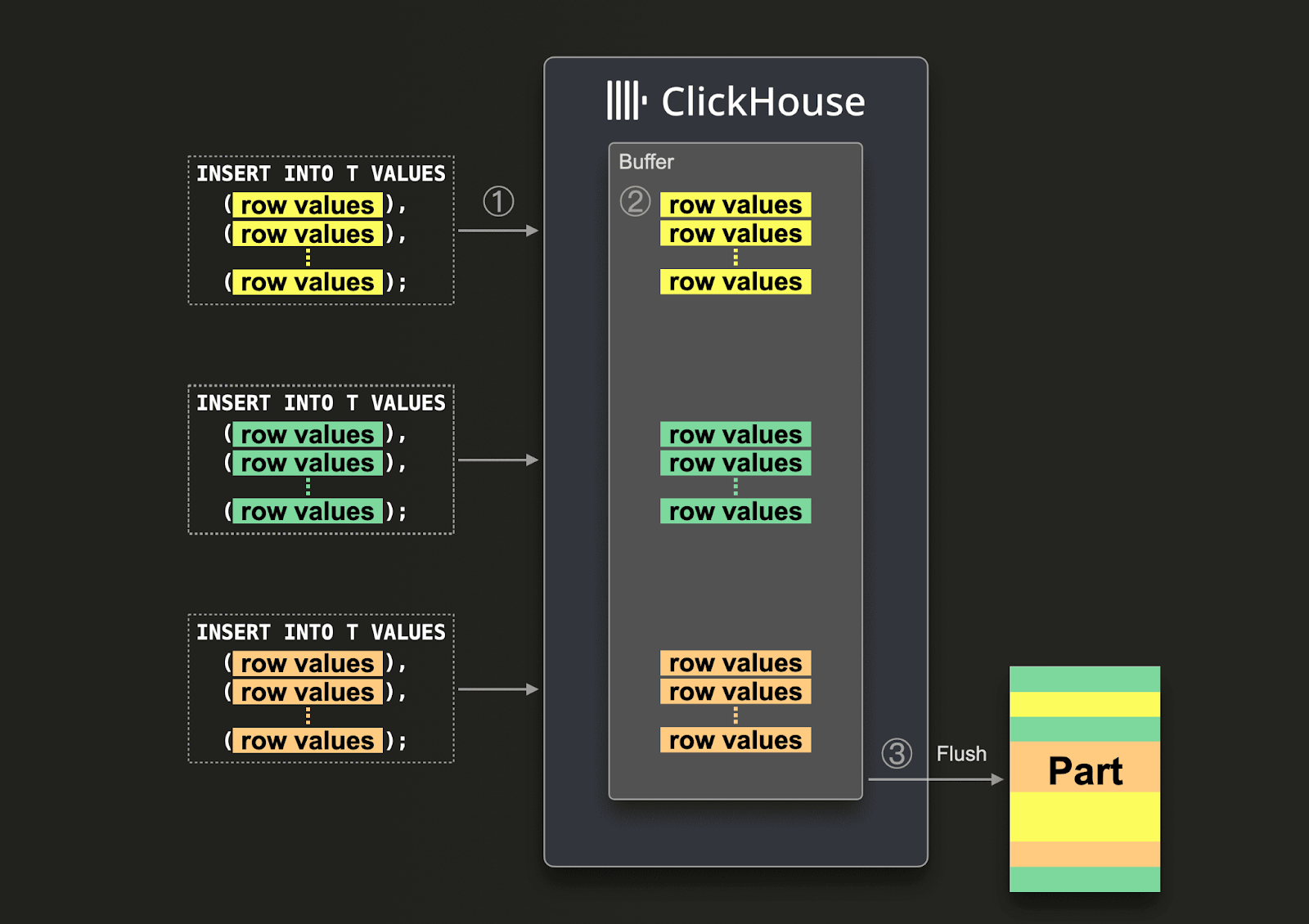
非同期挿入が有効な場合、ClickHouse が ① 挿入クエリを受信すると、そのクエリのデータは ② まず即座にインメモリバッファに書き込まれます。③ 次のバッファフラッシュが発生すると、バッファ内のデータは ソートされ、パーツとしてデータベースストレージに書き込まれます。なお、データはデータベースストレージにフラッシュされるまではクエリで検索できません。バッファフラッシュのタイミングは設定可能です。
コレクターで非同期挿入を有効にするには、接続文字列に async_insert=1 を追加します。到達保証を得るために、wait_for_async_insert=1(デフォルト)の使用を推奨します。詳細はこちらを参照してください。
非同期挿入によるデータは、ClickHouse のバッファがフラッシュされたときに挿入されます。これは、async_insert_max_data_size を超えた場合、または最初の INSERT クエリから async_insert_busy_timeout_ms ミリ秒経過した場合のいずれかで発生します。async_insert_stale_timeout_ms にゼロ以外の値が設定されている場合は、最後のクエリから async_insert_stale_timeout_ms milliseconds 経過後にデータが挿入されます。これらの設定を調整することで、パイプラインのエンドツーエンドのレイテンシーを制御できます。バッファフラッシュの調整に使用できるその他の設定はこちらに記載されています。一般的には、デフォルト値で問題ありません。
エージェント数が少なく、スループットも低い一方でエンドツーエンドのレイテンシーに厳しい要件がある場合、adaptive asynchronous inserts が有用な場合があります。一般的に、これは ClickHouse で見られるような高スループットのオブザーバビリティユースケースにはあまり適していません。
最後に、ClickHouse への同期挿入に関連付けられていた従来の重複排除動作は、非同期挿入を使用する場合はデフォルトでは有効になりません。必要に応じて、設定 async_insert_deduplicate を参照してください。
この機能の設定方法の詳細は、このドキュメントページや、より詳しいブログ記事を参照してください。
スケーリング
ClickStack の OTel collector はゲートウェイ インスタンスとして動作します。詳細は Collector roles を参照してください。これは通常、データセンターごと、あるいはリージョンごとに独立したサービスとして提供されます。これらはアプリケーション(またはエージェントロールの他の collector)から、単一の OTLP エンドポイント経由でイベントを受信します。一般的には複数の collector インスタンスをデプロイし、標準的なロードバランサーを使用して、それらの間で負荷を分散します。

このアーキテクチャの目的は、計算負荷の高い処理をエージェントからオフロードし、エージェントのリソース使用量を最小限に抑えることです。これらの ClickStack ゲートウェイは、本来であればエージェント側で実行する必要がある変換処理を実行できます。さらに、多数のエージェントからイベントを集約することで、ゲートウェイは ClickHouse に対して大きなバッチを送信できるようになり、効率的な挿入が可能になります。エージェントや SDK ソースの追加やイベントスループットの増加に応じて、これらのゲートウェイ collector は容易にスケールアウトできます。
Kafka の追加
ここまでに示したアーキテクチャでは、メッセージキューとして Kafka を使用していないことに気付く読者もいるでしょう。
メッセージバッファとして Kafka キューを用いるのは、ログ収集アーキテクチャでよく見られる一般的な設計パターンであり、ELK スタックによって広く普及しました。これにはいくつかの利点があります。主として、より強いメッセージ配送保証を提供し、バックプレッシャーへの対応に役立つ点です。メッセージは収集エージェントから Kafka に送信され、ディスクに書き込まれます。理論上、クラスタ構成の Kafka インスタンスは、高スループットなメッセージバッファを提供できます。これは、メッセージを解析・処理するよりも、データをディスクに線形に書き込む方が計算オーバーヘッドが小さいためです。例えば Elastic では、トークナイズやインデックス作成に大きなオーバーヘッドが発生します。データをエージェントから切り離すことで、送信元でのログローテーションによってメッセージを失うリスクも減らすことができます。最後に、一部のユースケースでは魅力となり得る、メッセージのリプレイ機能やリージョン間レプリケーション機能も提供します。
しかし、ClickHouse はデータを非常に高速に挿入でき、通常のハードウェアでも毎秒数百万行を処理できます。ClickHouse 側でバックプレッシャーが発生することはまれです。多くの場合、Kafka キューを活用することは、アーキテクチャの複雑さとコストの増加を意味します。ログは銀行取引やその他のミッションクリティカルなデータと同等の配送保証を必要としない、という原則を受け入れられるのであれば、Kafka を導入してまでアーキテクチャを複雑化させることは避けることを推奨します。
一方で、高い配送保証や(複数の宛先に対して)データをリプレイできる機能が必要な場合、Kafka は有用なアーキテクチャ上の追加要素となり得ます。
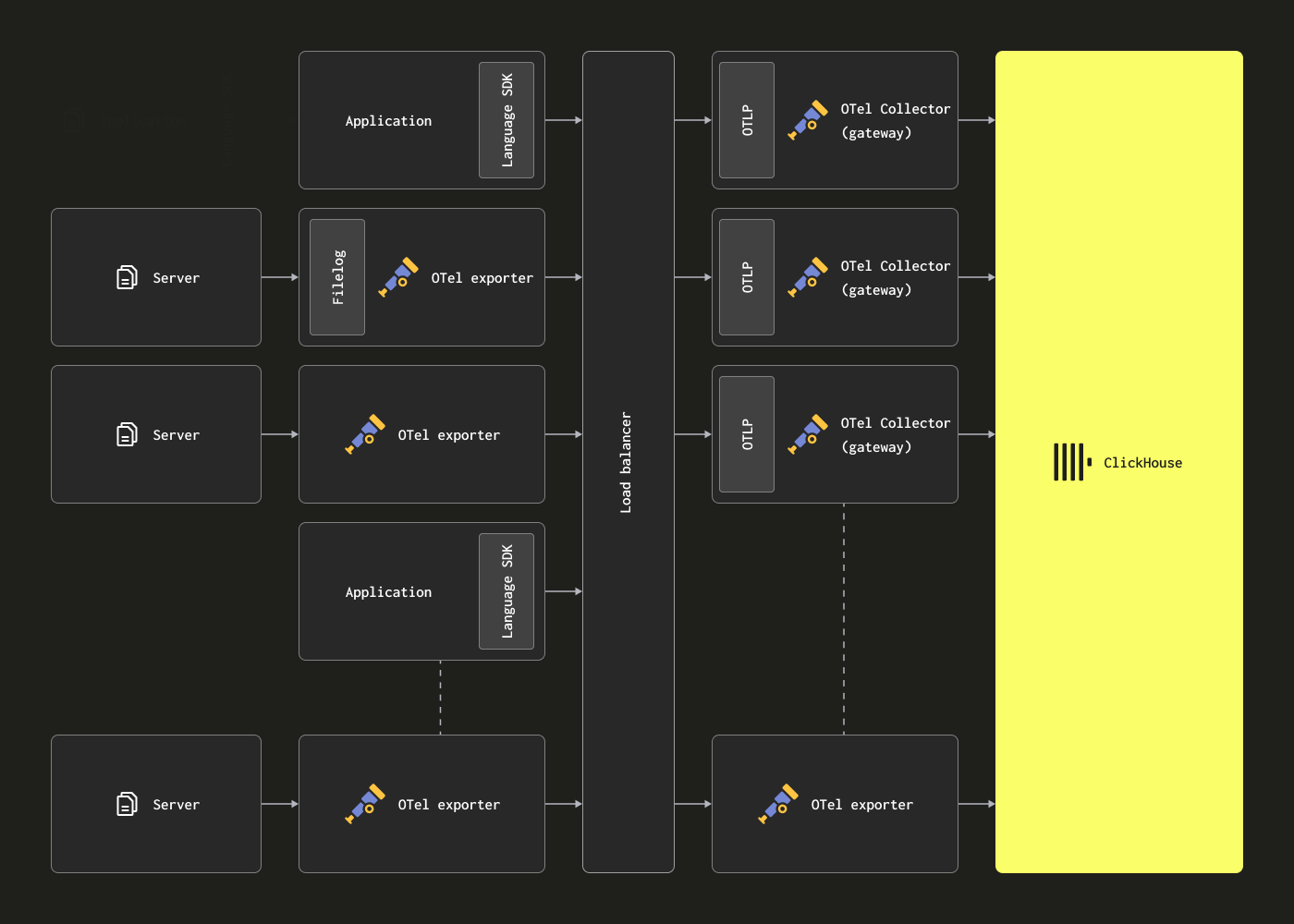
この場合、OTel エージェントは Kafka exporter を使用して Kafka にデータを送信するよう構成できます。ゲートウェイインスタンスは、Kafka receiver を使用してメッセージを消費します。詳細については Confluent と OTel のドキュメントを参照することを推奨します。
ClickStack の OpenTelemetry collector ディストリビューションは、custom collector configuration を使用して Kafka を組み込むように構成できます。
リソースの見積もり
OTel collector のリソース要件は、イベントのスループット、メッセージサイズ、および実行される処理量によって異なります。OpenTelemetry プロジェクトは、リソース要件を見積もる際に使用できるベンチマークを提供しています。
当社の経験では、3 コアと 12GB の RAM を持つ ClickStack ゲートウェイのインスタンスで、1 秒あたり約 60k イベントを処理できます。これは、フィールド名の変更のみを行い、正規表現を使用しない最小限の処理パイプラインを想定しています。
ゲートウェイへのイベント転送と、イベントへのタイムスタンプ設定のみを担当するエージェントインスタンスについては、想定される 1 秒あたりのログ数に基づいてサイジングすることを推奨します。以下は、検討を始める際の目安となる概算値です。
| ログレート | collector エージェントへのリソース |
|---|---|
| 1k/秒 | 0.2 CPU, 0.2GiB |
| 5k/秒 | 0.5 CPU, 0.5GiB |
| 10k/秒 | 1 CPU, 1GiB |
schema の選択: Map と JSON
ClickStack collector は、デフォルトで属性を Map(LowCardinality(String), String) カラムに格納するテーブルを作成します。これは、オブザーバビリティのワークロードに推奨される schema です。JSON 型の schema はベータ版として利用でき、属性キーの集合が小さく安定しているワークロードでの評価に適しています。
詳細な比較、各方式が適しているケース、JSON 型 schema を有効にするために必要な環境変数、移行手順については、Map vs JSON type を参照してください。
