マネージド版 ClickStack 入門
Managed ClickStack を ClickHouse Cloud 上にデプロイする方法が、最も簡単な始め方です。これにより、インジェスト、スキーマ、オブザーバビリティのワークフローを完全に制御しつつ、フルマネージドでセキュアなバックエンドが提供されます。これによって自前で ClickHouse を運用する必要がなくなり、次のような多くの利点が得られます。
- ストレージとは独立したコンピュートの自動スケーリング
- オブジェクトストレージに基づく、低コストかつ事実上無制限の保持期間
- ウェアハウスを使って読み取り・書き込みワークロードを個別に分離できる機能
- 統合認証
- 自動バックアップ
- セキュリティおよびコンプライアンス機能
- シームレスなアップグレード
ClickHouse Cloud にサインアップする
ClickHouse Cloud で Managed ClickStack サービスを作成するには、まず ClickHouse Cloud クイックスタートガイド の 最初のステップ を完了してください。
ほとんどの ClickStack ワークロードには、この Scale ティア を推奨します。SAML、CMEK、HIPAA 準拠などの高度なセキュリティ機能が必要な場合は、Enterprise ティアを選択してください。Enterprise ティアでは、非常に大規模な ClickStack デプロイメント向けのカスタムハードウェアプロファイルも提供されます。そのような場合は、サポートまでお問い合わせください。
Cloud プロバイダーとリージョンを選択します。
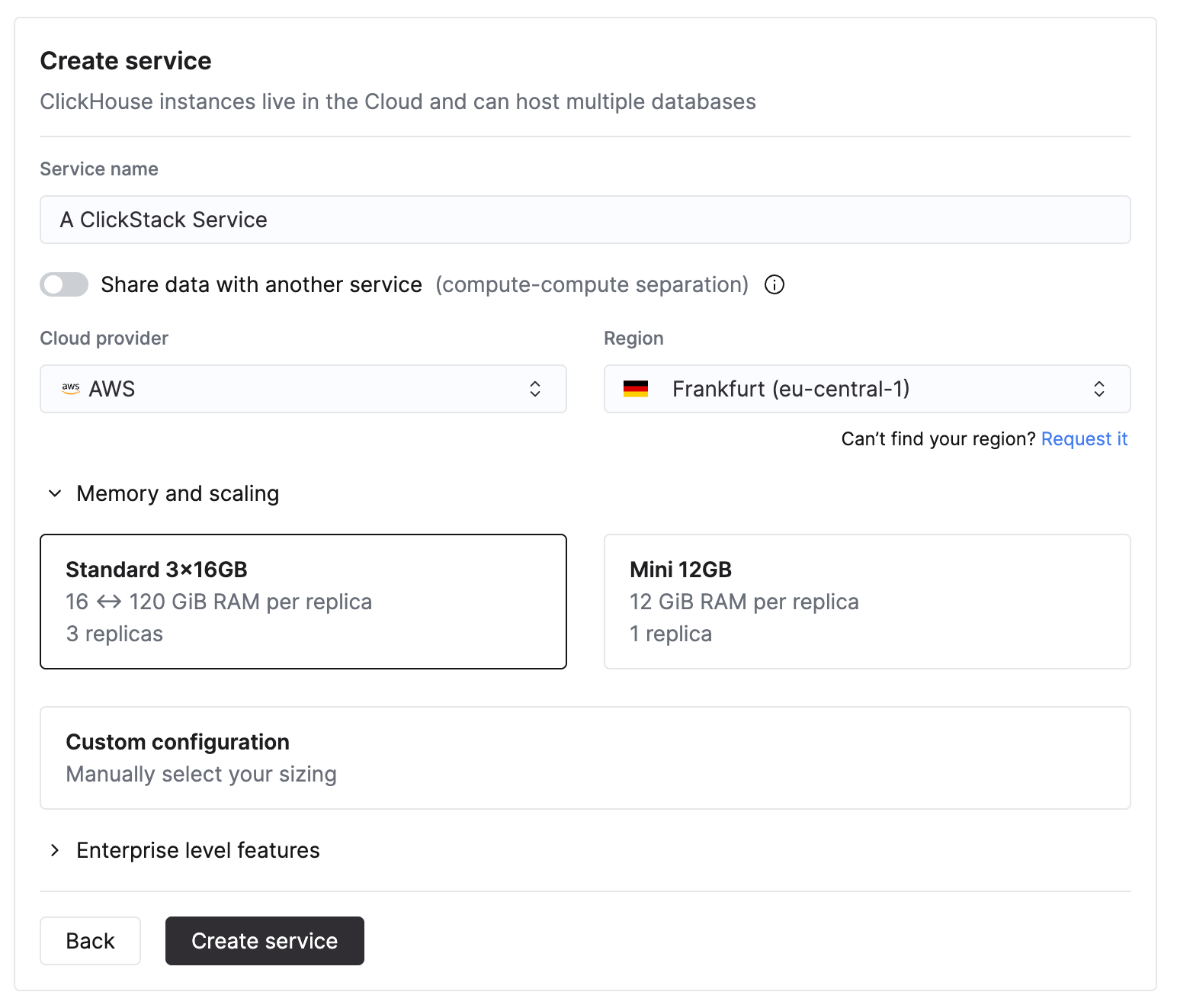
CPU とメモリを指定する際は、想定される ClickStack のインジェスト処理量に基づいて見積もってください。以下の表は、これらのリソースのサイジングに関する指針を示します。
以下では、想定されるインジェスト量に基づき、ClickStack のデプロイに必要なコンピュートおよびストレージリソースを見積もるためのモデルを示します。算出される値はあくまで概算であり、初期ベースラインとして利用してください。規定的な答えではありません。実際に必要となるリソースは、クエリの複雑さ、同時実行数、保持ポリシー、インジェスト処理量の変動によって異なります。必ずリソース使用量を監視し、必要に応じてスケールしてください。
このページのすべての数値 - スループット (MB/s、TB/月) 、CPU サイジング、ストレージ - は、非圧縮の生インジェスト量、つまりアプリケーションによって生成され、圧縮が適用される前に OpenTelemetry collector に送信されるデータサイズを基準にしています。
この値は、既存のログ、トレース、メトリクスのパイプラインから見積もってください。以下の表にあるストレージ値には、この生データ量に対する想定10 倍圧縮率がすでに適用されています。
ClickStack をデプロイする際は、インジェストとクエリという 2 つの独立したワークロードをまかなえるようにコンピュートをプロビジョニングしてください。
| ワークロード | 推定リソース |
|---|---|
| インジェスト | 持続的なインジェストスループット 10 MB/s あたり 1 vCPU |
| クエリ | 1 QPS あたり 1 vCPU、かつ持続的なインジェストスループット 10 MB/s あたり 1 vCPU |
ほとんどのセルフマネージド環境では、インジェストとクエリは同じノードを共有します。この場合は、Total CPUs をベースラインとして使用してください。インジェスト用とクエリ用のコンピュートを個別にプロビジョニングする分離スケーリングは、ClickHouse Cloud では 個別のコンピュートプール (別名 Warehouses) によってサポートされています。
前提
- ストレージについては10 倍圧縮率を想定しています。これは通常、ログとトレースに対しては保守的な見積もりです。
- クエリ SLA は、P50 が 1.5 秒、P99 が 5 秒です。
- ほとんどのクエリは直近のデータに対して実行され、約 1 時間付近でピークを迎え、約 6 時間まで裾を引く対数正規分布に従うと想定しています。古いデータをクエリするために、専用のコンピュートをプロビジョニングしたい場合もあります。ClickHouse Cloud では、使用していないときはこれを idle 状態にできるため、コストは発生しません。
- クエリ用コンピュートはインジェスト用コンピュートとは独立してスケールできますが、本質的にはインジェスト量に結び付いています。インジェストが増えるとデータ密度が高まり、その結果、クエリ時のスキャン量が増え、それに伴ってクエリ用コンピュート要件も高くなると想定しています。
以下の表は、1 秒あたりのインジェストスループット (MB/s) の増加に応じたサイジング例と、それに対応する 1 か月あたりのデータ量 (TB) を示しています。これは、すべてのクエリタイプ (検索、ダッシュボード、アラート) を通じて ClickStack からの平均 1 QPS が持続すると仮定したものです。
| MB/s | TB/月 | Ingest CPUs | Query CPUs | Total CPUs | 総ストレージ (1 か月あたり) (GB) |
|---|---|---|---|---|---|
| 10 | 25.92 | 1 | 3 | 4 | 2,592 |
| 20 | 51.84 | 2 | 6 | 8 | 5,184 |
| 50 | 129.6 | 5 | 15 | 20 | 12,960 |
| 100 | 259.2 | 10 | 30 | 40 | 25,920 |
| 200 | 518.4 | 20 | 60 | 80 | 51,840 |
| 500 | 1,296 | 50 | 150 | 200 | 129,600 |
| 1000 | 2,592 | 100 | 300 | 400 | 259,200 |
要件を指定すると、Managed ClickStack サービスのプロビジョニングに数分かかります。プロビジョニングを待つ間、ClickHouse Cloud console の他の部分を自由に閲覧できます。
環境に合わせてサイジングの前提条件をさらに調整する方法の詳細については、"環境に合わせたサイジング前提条件の調整" を参照してください。
プロビジョニングが完了すると、左側メニューの 'ClickStack' オプションが有効になります。
インジェストをセットアップする
サービスがプロビジョニングされたら、そのサービスが選択されていることを確認し、左側のメニューから "ClickStack" をクリックします。
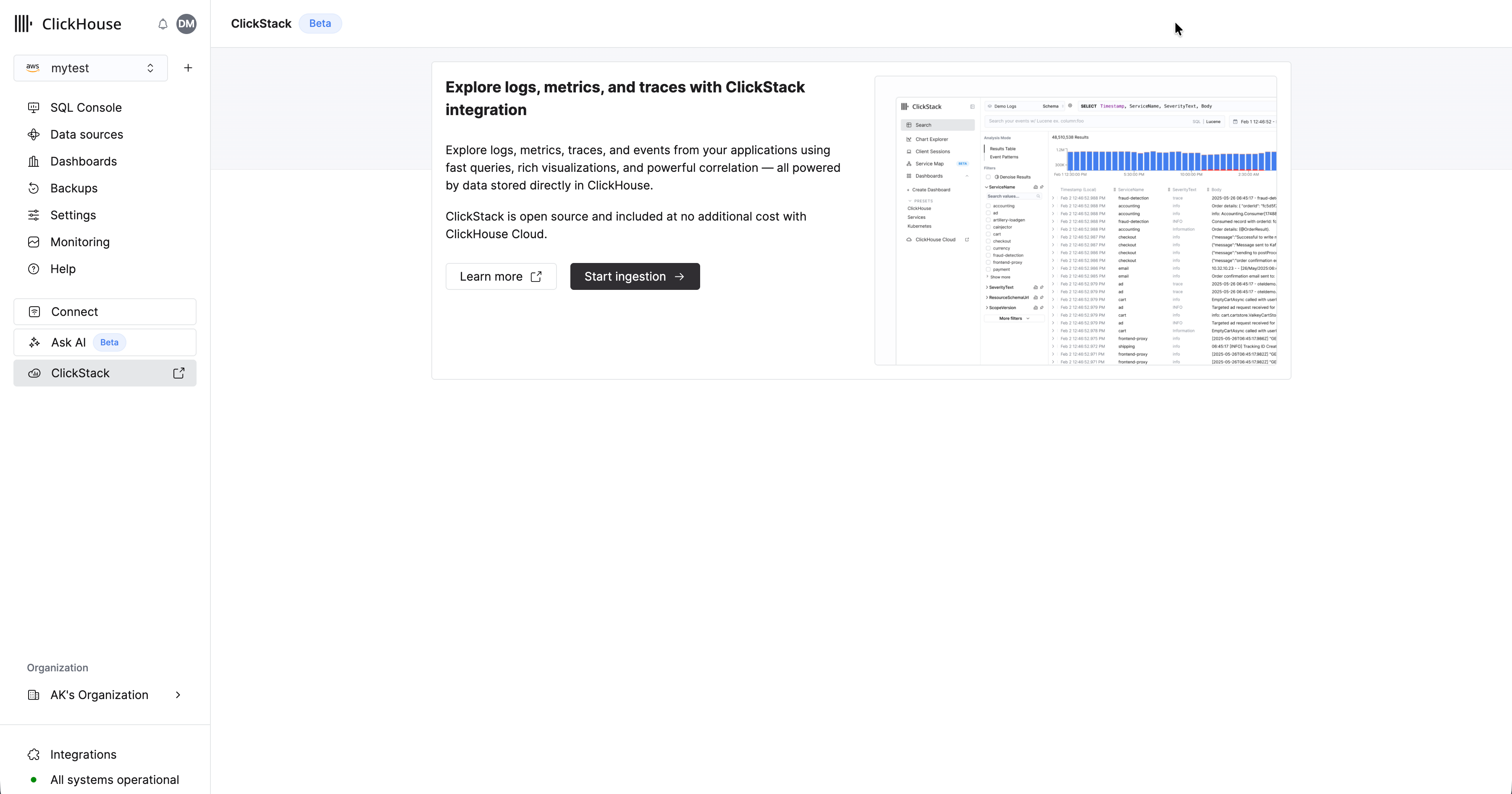
「Start Ingestion」を選択すると、インジェストソースの選択を求められます。Managed ClickStack は、主なインジェストソースとして OpenTelemetry と Vector をサポートしています。ただし、ユーザーは任意の ClickHouse Cloud support integrations を利用して、独自のスキーマで ClickHouse に直接データを送信することもできます。
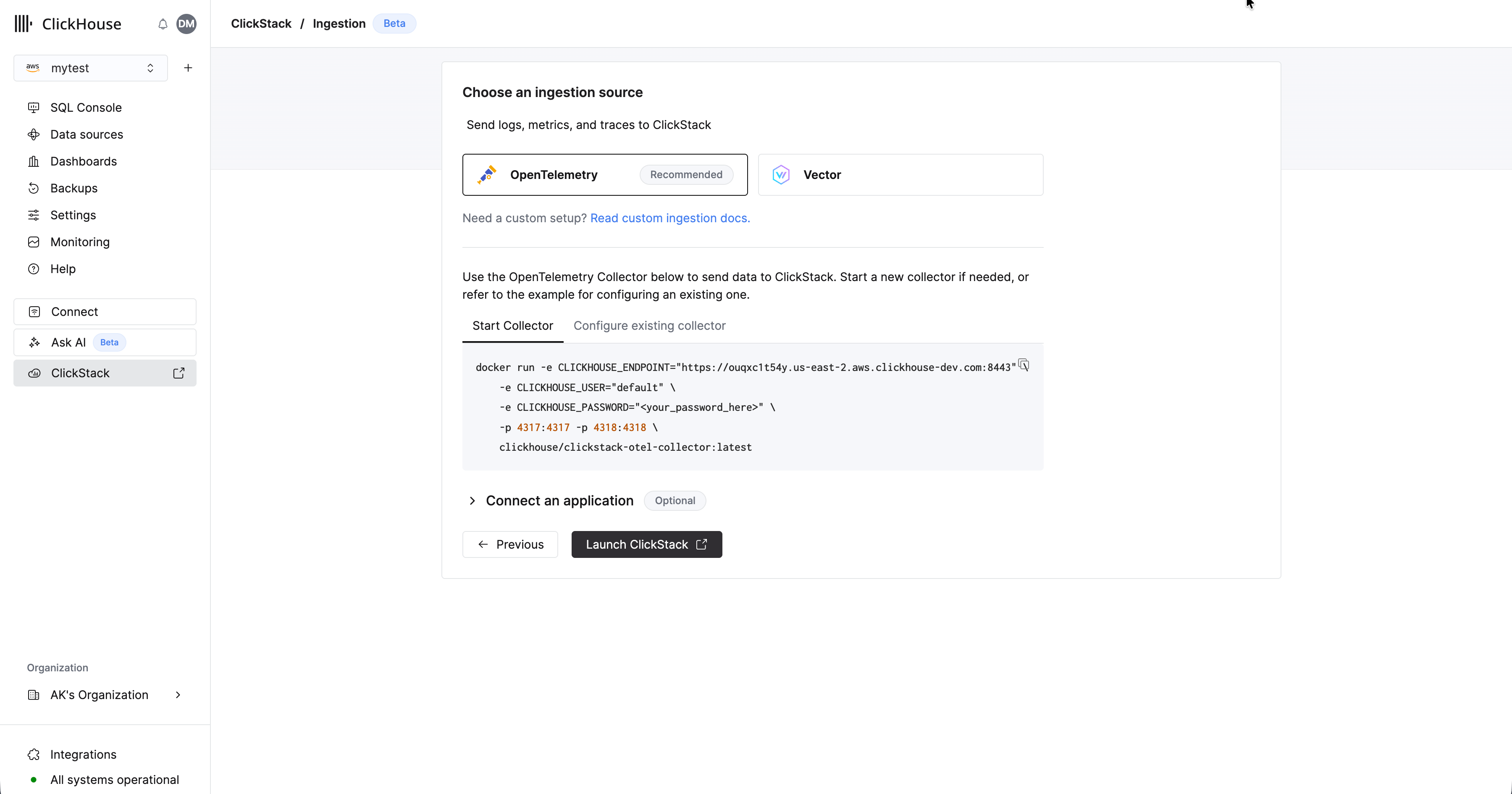
インジェスト形式としては、OpenTelemetry の利用を強く推奨します。 ClickStack と効率的に連携するよう特別に設計された、すぐに利用可能なスキーマを備えており、もっともシンプルかつ最適化された利用体験を提供します。
- OpenTelemetry
- Vector
Managed ClickStackにOpenTelemetryデータを送信する場合は、OpenTelemetry Collectorを使用することを推奨します。コレクターは、アプリケーション(および他のコレクター)からOpenTelemetryデータを受信し、それを ClickHouse Cloud に転送するゲートウェイとして機能します。
まだコレクターが動作していない場合は、以下の手順でコレクターを起動してください。既存のコレクターがある場合は、設定例も提供しています。
コレクターを起動する
以下では、追加の処理を含み、ClickHouse Cloud向けに最適化された ClickStack distribution of the OpenTelemetry Collector を使用する推奨パスを前提としています。独自のOpenTelemetry Collectorを使用する場合は、「既存のコレクターの設定」を参照してください。
すぐに開始するには、表示されているDockerコマンドをコピーして実行します。
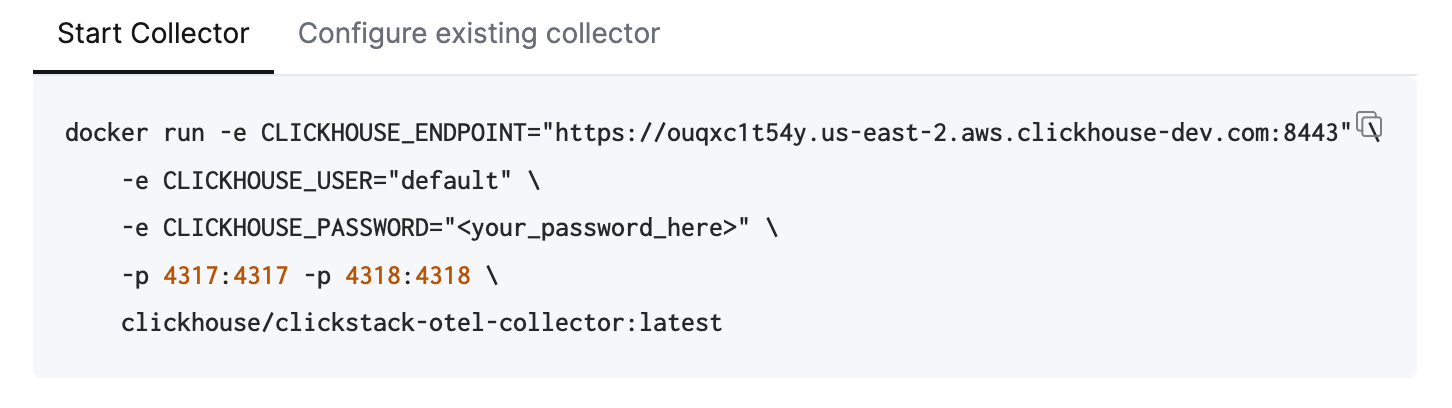
このコマンドには、接続認証情報があらかじめ埋め込まれています。
このコマンドはManaged ClickStackへの接続にdefaultユーザーを使用していますが、本番環境に移行する際には専用ユーザーを作成し、設定を変更してください。
このコマンドを1回実行するだけで、ポート4317(gRPC)および4318(HTTP)でOTLPエンドポイントが公開されたClickStackコレクターが起動します。既にOpenTelemetryインストルメンテーションとエージェントを使用している場合は、これらのエンドポイントへのテレメトリデータ送信を直ちに開始できます。
既存のコレクターの設定
既存のOpenTelemetryコレクターを設定したり、独自のコレクターディストリビューションを使用したりすることも可能です。
独自のディストリビューション(例: contrib イメージ)を使用している場合は、ClickHouse exporter が含まれていることを確認してください。
この目的のために、適切な設定でClickHouseエクスポーターを使用し、OTLPレシーバーを公開するOpenTelemetry Collectorの設定例が提供されています。この設定は、ClickStackディストリビューションが期待するインターフェースと動作に一致します。
この構成の例を次に示します(UI からコピーした場合、環境変数はあらかじめ設定されています)。
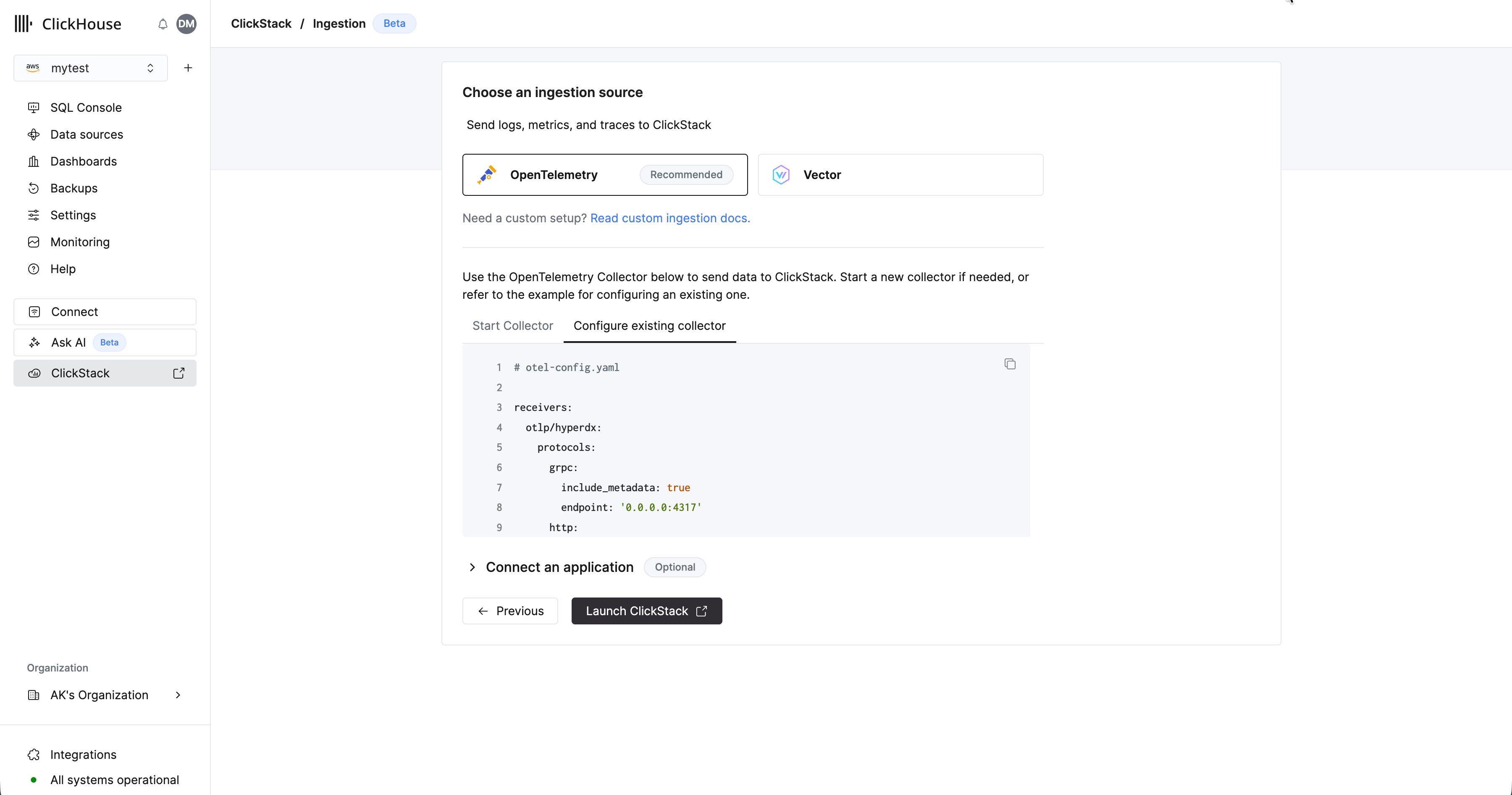
OpenTelemetryコレクターの設定の詳細については、「OpenTelemetryでのデータ取り込み」を参照してください。
インジェストを開始する(任意)
既存のアプリケーションやインフラストラクチャでOpenTelemetryによるインストルメンテーションを行う場合は、UIからリンクされている該当ガイドに進んでください。
アプリケーションをインストルメントしてトレースとログを収集するには、サポートされている言語SDKを使用します。これらは、Managed ClickStackへのインジェストのためのゲートウェイとして動作するOpenTelemetry Collectorにデータを送信します。
ログは、エージェントモードで動作し同じコレクターにデータを転送するOpenTelemetry Collectorを使用して収集できます。Kubernetesの監視については、専用ガイドに従ってください。他のインテグレーションについては、クイックスタートガイドを参照してください。
デモデータ
あるいは、既存データがない場合は、サンプルデータセットのいずれかを試すこともできます。
- Example dataset - 公開デモからサンプルデータセットをロードし、簡単な問題の診断を行います。
- Local files and metrics - ローカルのOTel collectorを使用して、OSXまたはLinux上でローカルファイルを読み込み、システムを監視します。
Vector は、高性能でベンダーに依存しないオブザーバビリティデータパイプラインであり、柔軟性とリソース消費の少なさから、特にログのインジェスト用途で広く利用されています。
ClickStack と併用する場合、Vector ではスキーマ定義をユーザー自身が行う必要があります。これらのスキーマは OpenTelemetry の規約に従ってもよいですし、ユーザー定義イベント構造を表す完全にカスタムなものでも構いません。
Managed ClickStack における唯一の厳密な要件は、データに タイムスタンプカラム (または同等の時刻フィールド) が含まれていることです。これは ClickStack UI でデータソースを設定する際に宣言できます。
以下では、データを配信するためのインジェストパイプラインが事前に設定された Vector インスタンスが稼働していることを前提とします。
データベースとテーブルを作成する
Vector では、データをインジェストする前にテーブルとスキーマを定義しておく必要があります。
まずデータベースを作成します。これは ClickHouse Cloud console から行えます。
たとえば、ログ用のデータベースを作成します。
次に、ログデータの構造に合致するスキーマのテーブルを作成します。以下の例では、典型的な Nginx アクセスログ形式を想定しています。
テーブルは、Vector によって生成される出力スキーマと一致している必要があります。推奨されるスキーマ設計のベストプラクティスに従い、データに合わせてスキーマを調整してください。
ClickHouse におけるPrimary keysの動作を理解し、アクセスパターンに基づいて順序キーを選択することを強く推奨します。主キーの選択については、ClickStack 固有のガイダンスを参照してください。
テーブルを作成したら、表示されている設定スニペットをコピーします。既存のパイプラインを取り込めるよう入力を調整し、必要に応じて対象テーブルおよびデータベースも変更してください。認証情報は事前に入力されているはずです。
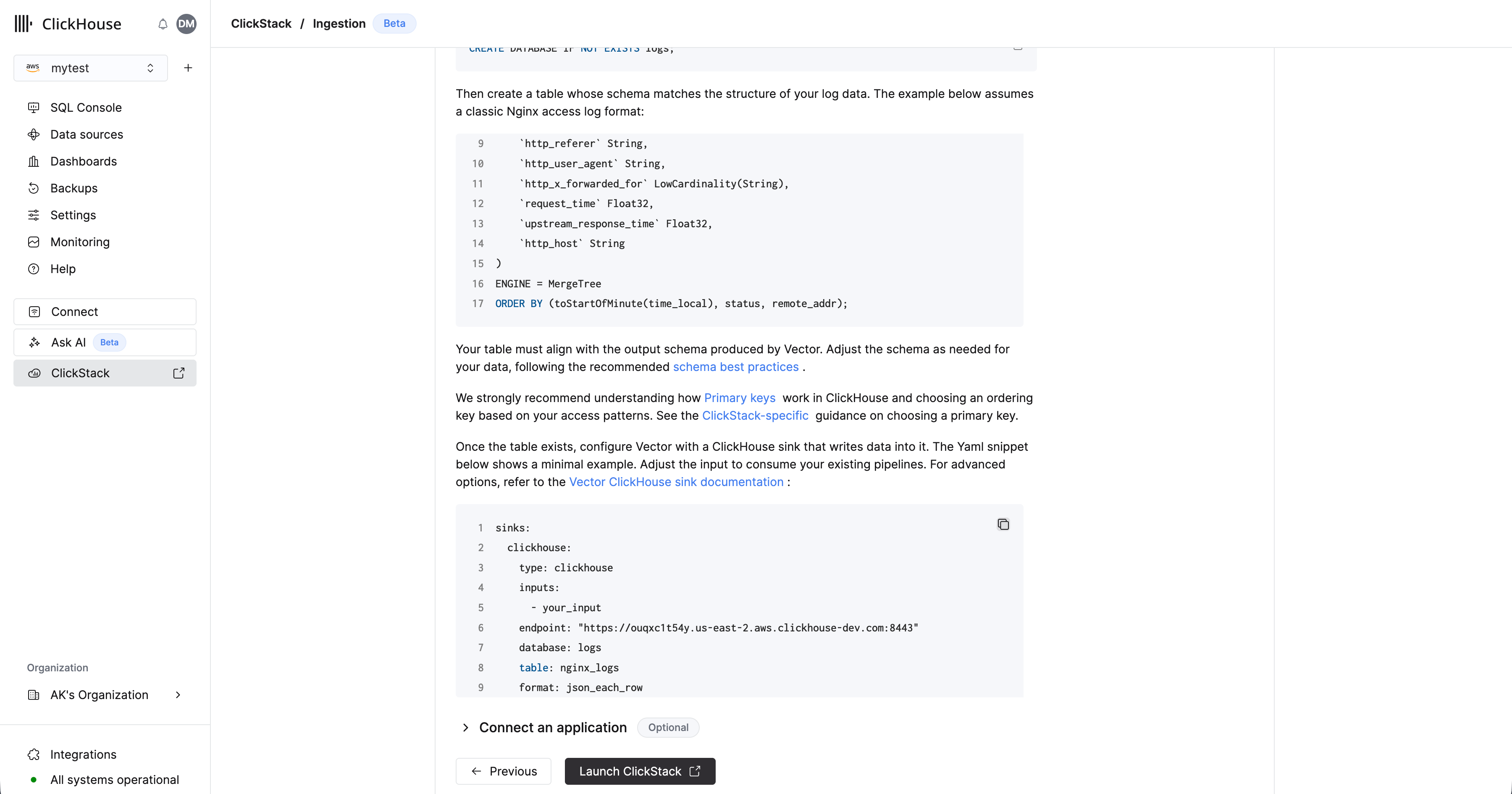
Vector を用いたデータ取り込みの例については、"Ingesting with Vector" または高度なオプションについて Vector ClickHouse sink documentation を参照してください。
ClickStack UI に移動する
'Launch ClickStack' を選択して ClickStack UI (HyperDX) にアクセスします。自動的に認証が行われ、リダイレクトされます。
- OpenTelemetry
- Vector
OpenTelemetry のデータについては、データソースがあらかじめ作成されています。
Vector を使用している場合は、データソースを自分で作成する必要があります。初回ログイン時にデータソース作成を促すメッセージが表示されます。以下に、ログ用データソースの設定例を示します。
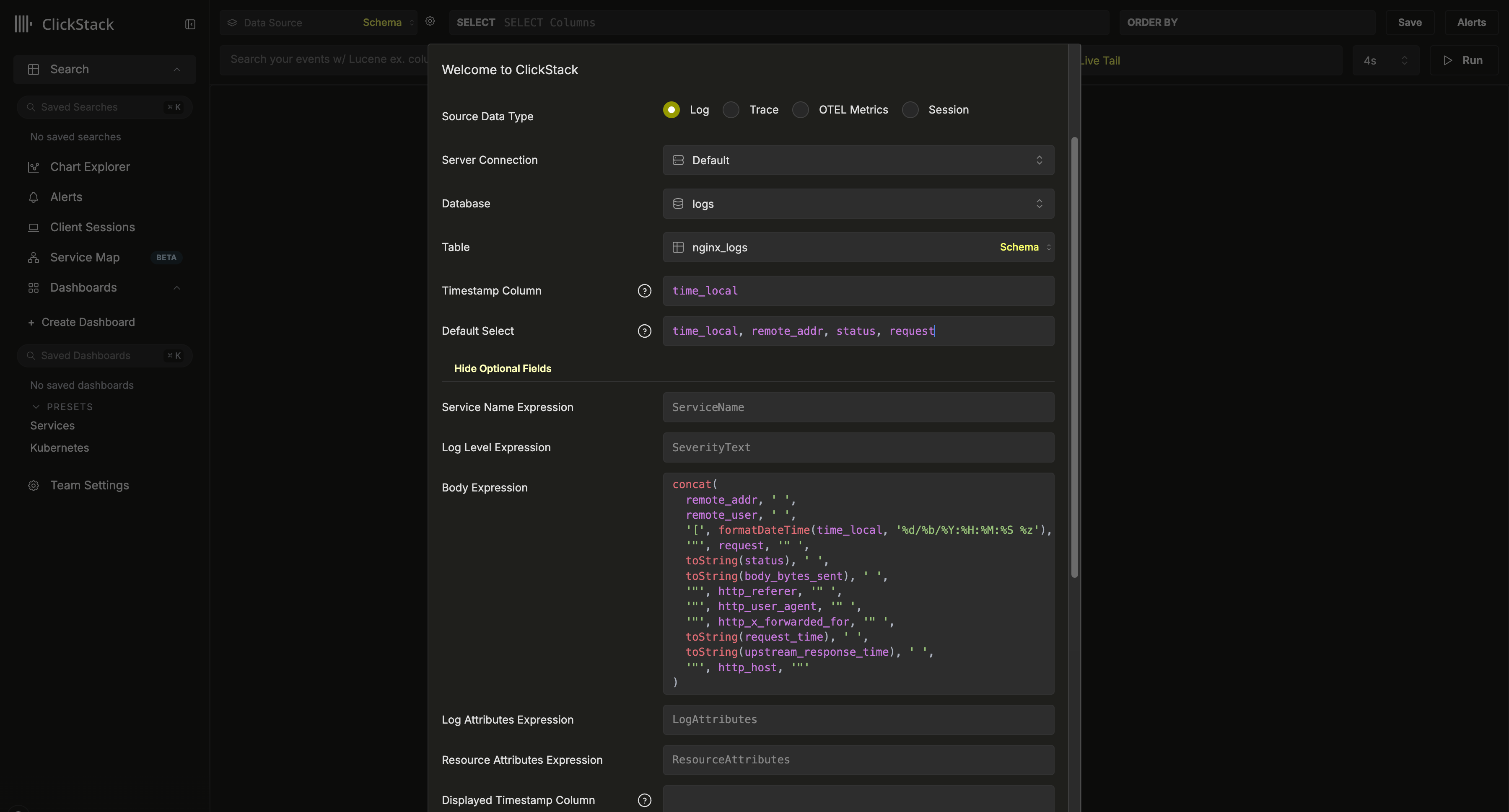
この設定は、タイムスタンプとして使用される time_local カラムを持つ Nginx 形式のスキーマを前提としています。可能であれば、これは PRIMARY KEY で定義されているタイムスタンプカラムであるべきです。このカラムは必須です。
また、Default SELECT を更新し、ログビューで返されるカラムを明示的に指定することを推奨します。サービス名、ログレベル、または body カラムなどの追加フィールドがある場合は、それらも設定できます。テーブルの PRIMARY KEY で使用しているカラムと異なる場合は、表示用のタイムスタンプカラムも上書き設定できます。
上記の例では、データに Body カラムは存在しません。その代わり、利用可能なフィールドから Nginx のログ行を再構築する SQL 式として定義しています。
他に利用可能なオプションについては、configuration reference を参照してください。
作成が完了すると、検索ビューに遷移し、すぐにデータの探索を開始できます。
以上で完了です。🎉
ClickStack を使って、ログやトレースの検索を開始し、ログ・トレース・メトリクスがリアルタイムにどのように相関付けられるかを確認し、ダッシュボードを構築し、サービスマップを探索し、イベントの差分やパターンを発見し、アラートを設定して問題を先回りで検知できるようにしましょう。
次のステップ
上記の手順の中でデフォルトの認証情報を記録していない場合は、サービスに移動して Connect を選択し、パスワードおよび HTTP/ネイティブエンドポイントを記録してください。これらの管理者認証情報は安全に保管し、他のガイドでも再利用できるようにしておきます。
新しいユーザーのプロビジョニングや追加のデータソースの追加などの作業を行うには、Managed ClickStack のデプロイガイド を参照してください。
