はじめに
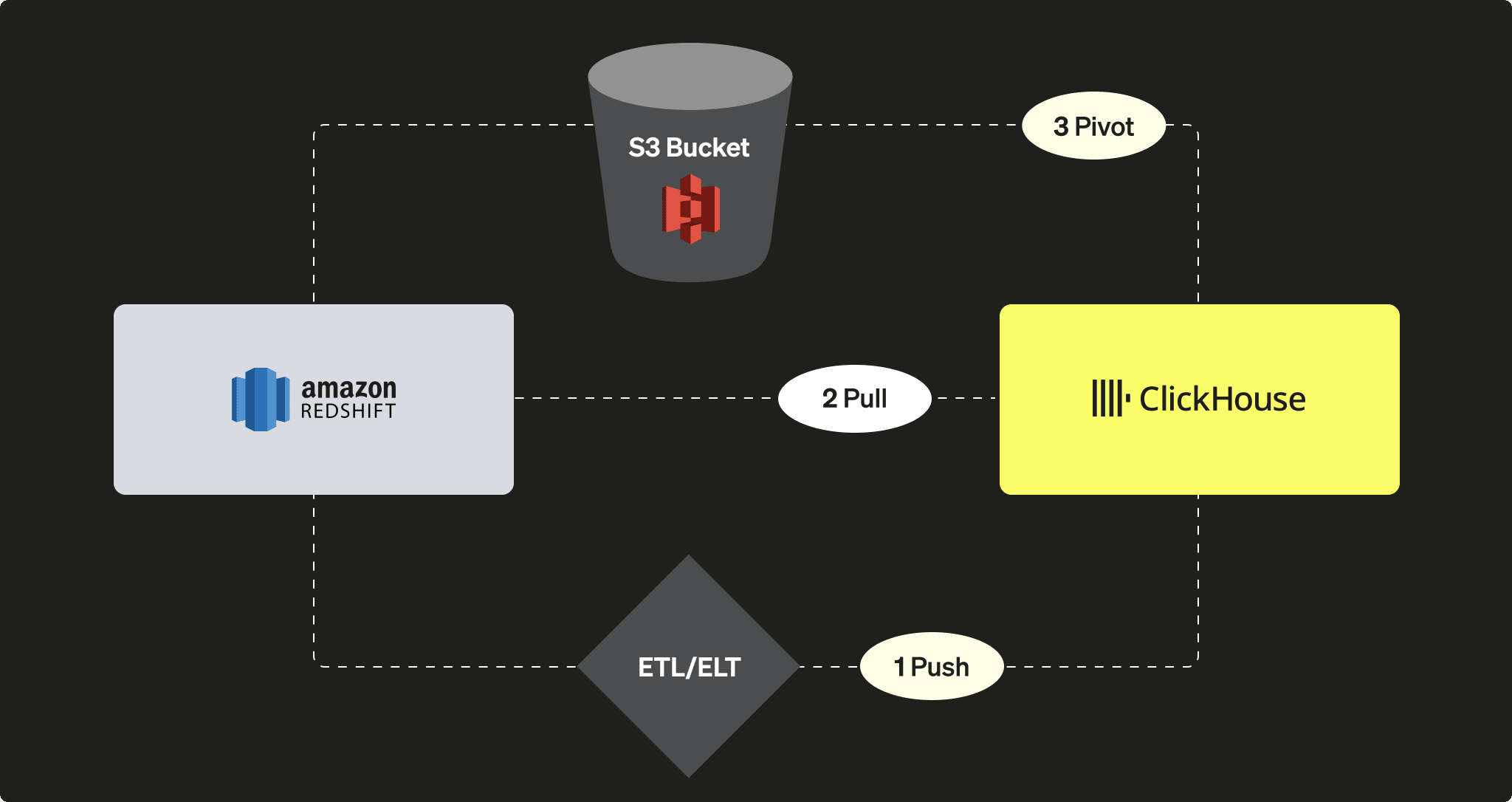
- PUSH サードパーティの ETL/ELT ツールまたはサービスを使用して、データを ClickHouse に送る
- PULL ClickHouse JDBC Bridge を利用して、Redshift からデータを取得する
- PIVOT S3 オブジェクトストレージを使用し、「アンロードしてからロードする」方式を用いる
このチュートリアルでは、データソースとして Redshift を使用しています。ただし、ここで紹介する移行方法は Redshift に限ったものではなく、互換性のある任意のデータソースに対して同様の手順を適用できます。
プッシュ方式で Redshift から ClickHouse にデータを送る

長所
- ETL/ELT ソフトウェアに既存するコネクタのカタログを活用できます。
- データの同期を維持するための組み込み機能 (append/overwrite/increment ロジック) を備えています。
- データ変換のユースケースに対応できます (例: dbt のインテグレーションガイド を参照) 。
欠点
- ETL/ELTインフラストラクチャの構築と運用が必要です。
- アーキテクチャにサードパーティの要素が加わるため、スケーラビリティ上のボトルネックになる可能性があります。
Redshift から ClickHouse へデータを Pull する
INSERT INTO ... SELECT クエリを実行します。

長所
- すべてのJDBC対応ツールで利用可能
- ClickHouse内から複数の外部データソースにクエリできる、スマートなソリューション
欠点
- ClickHouse JDBC Bridgeのインスタンスが必要で、スケーラビリティのボトルネックになる可能性があります
RedshiftはPostgreSQLベースですが、ClickHouseではPostgreSQLのバージョン9以降が必要である一方、Redshift APIはそれ以前のバージョン (8.x) ベースのため、ClickHouseのPostgreSQLテーブル関数やテーブルエンジンは使用できません。
チュートリアル
1
ClickHouse JDBC Bridge をデプロイする
ClickHouse JDBC Bridge をデプロイします。詳細については、外部データソース向け JDBC に関するユーザーガイドを参照してください
ClickHouse Cloud を使用している場合は、別の環境で ClickHouse JDBC Bridge を実行し、remoteSecure 関数を使用して ClickHouse Cloud に接続する必要があります
2
Redshift データソースを設定する
ClickHouse JDBC Bridge 用の Redshift データソースを設定します。たとえば、
/etc/clickhouse-jdbc-bridge/config/datasources/redshift.json です3
ClickHouse から Redshift インスタンスにクエリを実行する
ClickHouse JDBC Bridge のデプロイと起動が完了したら、ClickHouse から Redshift インスタンスにクエリを実行できます
4
Redshift から ClickHouse にデータをインポートする
以下では、
INSERT INTO ... SELECT ステートメントを使用してデータをインポートする例を示しますS3 を使用して Redshift から ClickHouse にデータを Pivot
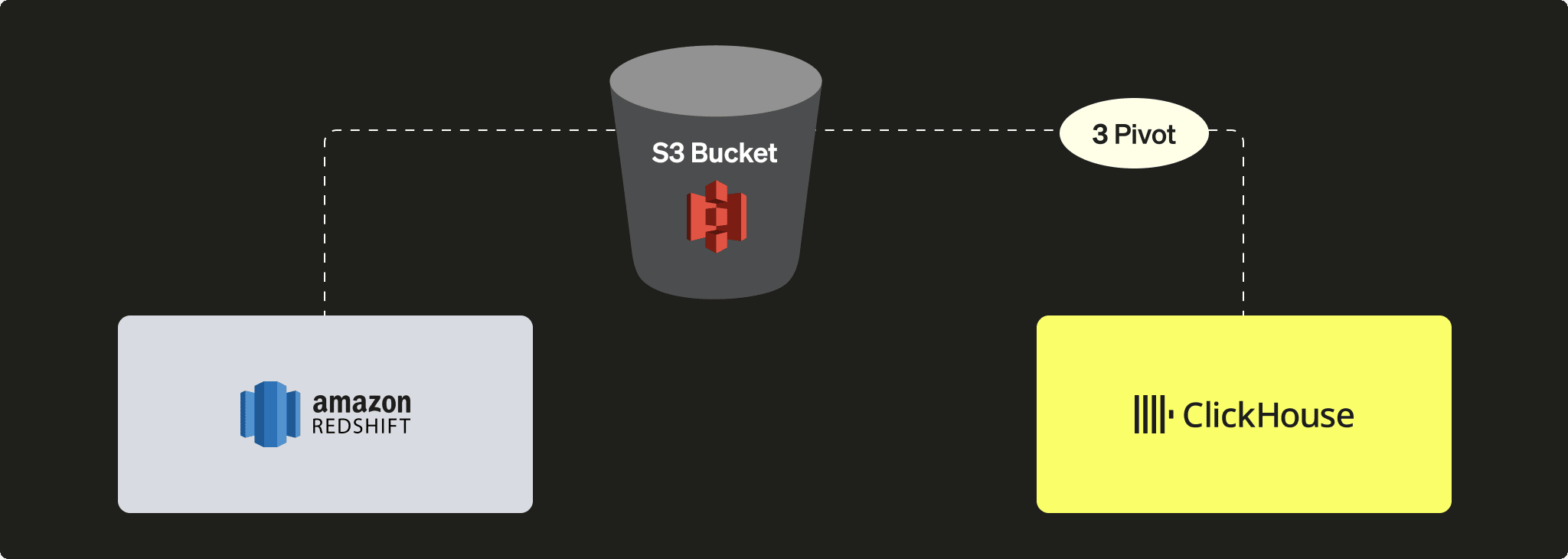
利点
- Redshift と ClickHouse は、どちらも強力な S3 連携機能を備えています。
- Redshift の
UNLOADコマンドや、ClickHouse の S3 テーブル関数 / テーブルエンジン など、既存の機能を活用できます。 - ClickHouse は、S3 との間での並列読み取りと高スループット性能により、シームレスにスケールできます。
- Apache Parquet のような高度で圧縮効率の高いフォーマットを活用できます。
デメリット
- プロセスが2段階になります (Redshift からアンロードして、その後 ClickHouse にロードする必要があります) 。
チュートリアル
1
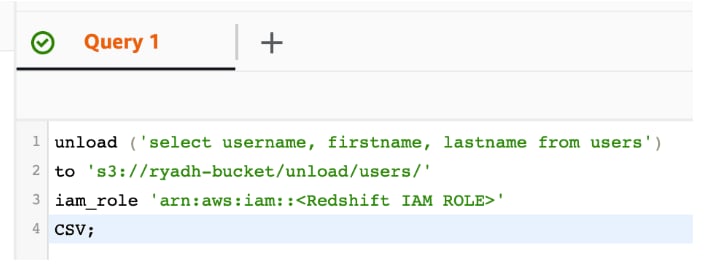
UNLOAD を使用してデータを S3 バケットにエクスポートする

2
ClickHouse にテーブルを作成する
ClickHouse にテーブルを作成します。または、これは、Parquet のようにデータ型に関する情報を含むフォーマットのデータで特に有効です。
CREATE TABLE ... EMPTY AS SELECT を使用して、ClickHouse にテーブル構造を推定させることもできます。3
S3 ファイルを ClickHouse にロードする
INSERT INTO ... SELECT ステートメントを使用して、S3 ファイルを ClickHouse にロードします。この例では、PIVOT フォーマットとして CSV を使用しました。ただし、本番ワークロードでは、大規模な移行には Apache Parquet を最適な選択肢として推奨します。圧縮に対応しているため、転送時間を短縮しながらストレージコストも抑えられるからです。 (デフォルトでは、各行グループは SNAPPY で圧縮されます。) また、ClickHouse は Parquet のカラム指向も活用して、データの取り込みを高速化します。