
スキーマの設計
これは、PostgreSQL から ClickHouse への移行に関するガイドの 第2部 です。このコンテンツは、ClickHouse のベストプラクティスに従った初期の機能的なシステムを展開する手助けをすることを目的とした、入門的な内容と考えることができます。複雑なトピックを避けており、完全に最適化されたスキーマを得るには至りませんが、ユーザーが本番システムを構築し、学習の基盤とするためのしっかりとした基盤を提供します。
Stack Overflow のデータセットには、多くの関連するテーブルが含まれています。移行は、まず主テーブルの移行に焦点を当てることをお勧めします。これが必ずしも最大のテーブルである必要はなく、最も多くの分析クエリを受け取ることが予想されるテーブルです。これにより、主に OLTP のバックグラウンドを持つ方にとって特に重要な ClickHouse の主要な概念に慣れることができます。このテーブルは、ClickHouse の機能を最大限に活用し、最適なパフォーマンスを得るために、追加のテーブルが追加される際にリモデリングが必要となるかもしれません。このモデリングプロセスについては、データモデル文書で探ります。
初期スキーマの設定
この原則に従い、主な posts テーブルに焦点を当てます。これに対応する PostgreSQL スキーマは以下に示されています:
上記の各カラムに対する同等の型を確立するために、Postgres テーブル関数を使用して DESCRIBE コマンドを実行できます。次のコマンドをあなたの Postgres インスタンスに合わせて修正してください:
これにより、初期の非最適化スキーマが提供されます。
NOT NULL 制約がない場合、Postgres のカラムには Null 値を含むことができます。行の値を検査せずに、ClickHouse はこれらを同等の Nullable 型にマッピングします。主キーは Null ではないことに注意してください。これは Postgres の要件です。
これらの型を使用して ClickHouse テーブルを作成するには、シンプルな CREATE AS EMPTY SELECT コマンドを使用できます。
このアプローチは、他の形式の s3 からデータをロードするためにも使用できます。Parquet 形式からこのデータをロードするための同等の例は、ここにあります。
初期ロード
テーブルが作成されたので、Postgres テーブル関数を使用して、Postgres から ClickHouse に行を挿入できます。
この操作は、Postgres にかなりの負荷をかける可能性があります。ユーザーは、プロダクションのワークロードに影響を与えないように、SQL スクリプトをエクスポートするなどの代替操作でバックフィルを実行することを検討するかもしれません。この操作のパフォーマンスは、Postgres と ClickHouse クラスターのサイズ、およびそれらのネットワーク接続に依存します。
ClickHouse から Postgres への各
SELECTは、単一の接続を使用します。この接続は、設定postgresql_connection_pool_size(デフォルト 16)でサイズ指定されたサーバー側の接続プールから取得されます。
フルデータセットを使用する場合、例では 5900 万のポストをロードするはずです。ClickHouse で単純なカウントを実行して確認します:
型の最適化
このスキーマの型を最適化する手順は、データが他のソース(例えば、S3 上の Parquet)からロードされた場合と同じです。この代替ガイドを使用して Parquetで説明されたプロセスを適用すると、次のスキーマが得られます:
前のテーブルからデータを読み込み、このテーブルに挿入するために、シンプルな INSERT INTO SELECT でこれを行うことができます:
新しいスキーマには Null 値を保持しません。上記の挿入によって、これらはそれぞれの型のデフォルト値 - 整数の場合は 0、文字列の場合は空の値 - に暗黙的に変換されます。ClickHouse はまた、任意の数値をターゲット精度に自動的に変換します。
ClickHouse の主(整列)キー
OLTP データベースから来たユーザーは、ClickHouse の同等の概念を探すことがよくあります。ClickHouse が PRIMARY KEY 構文をサポートしているのを見て、ユーザーは元の OLTP データベースと同じキーを使用してテーブルスキーマを定義したくなるかもしれません。これは適切ではありません。
ClickHouse の主キーはどのように異なるのか?
OLTP の主キーを ClickHouse で使用することが適切でない理由を理解するためには、まず ClickHouse のインデックスの基本を理解する必要があります。Postgres を例として比較しますが、これらの一般的な概念は他の OLTP データベースにも適用されます。
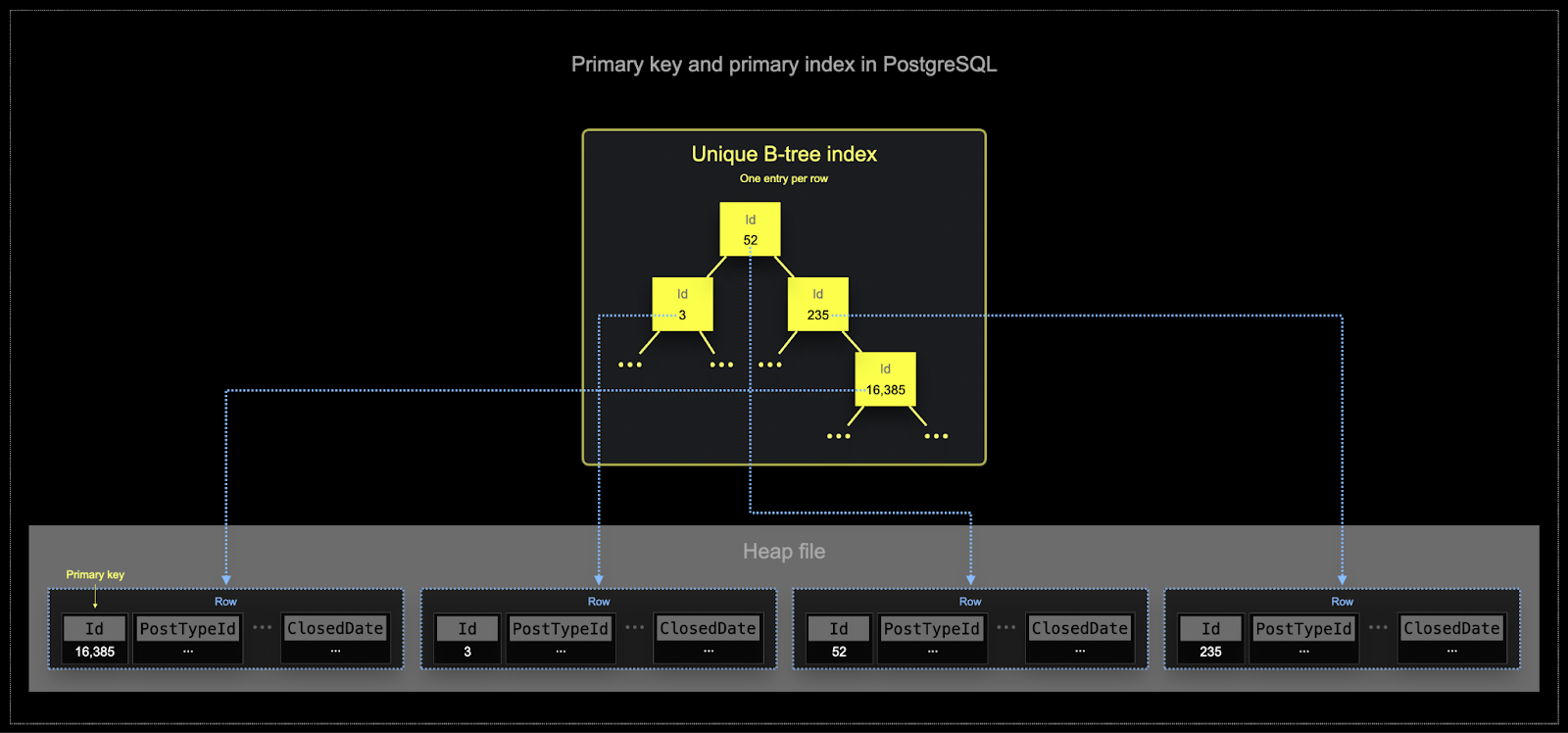
- Postgres の主キーは、定義上、行ごとに一意です。B-木構造を使用することで、このキーによって単一行を効率的にルックアップできます。ClickHouse は単一行値のルックアップに最適化できますが、分析ワークロードでは通常、いくつかのカラムを読む必要があり、多くの行を対象とします。フィルターは、集約が行われる行のサブセットを特定する必要があることが多いです。
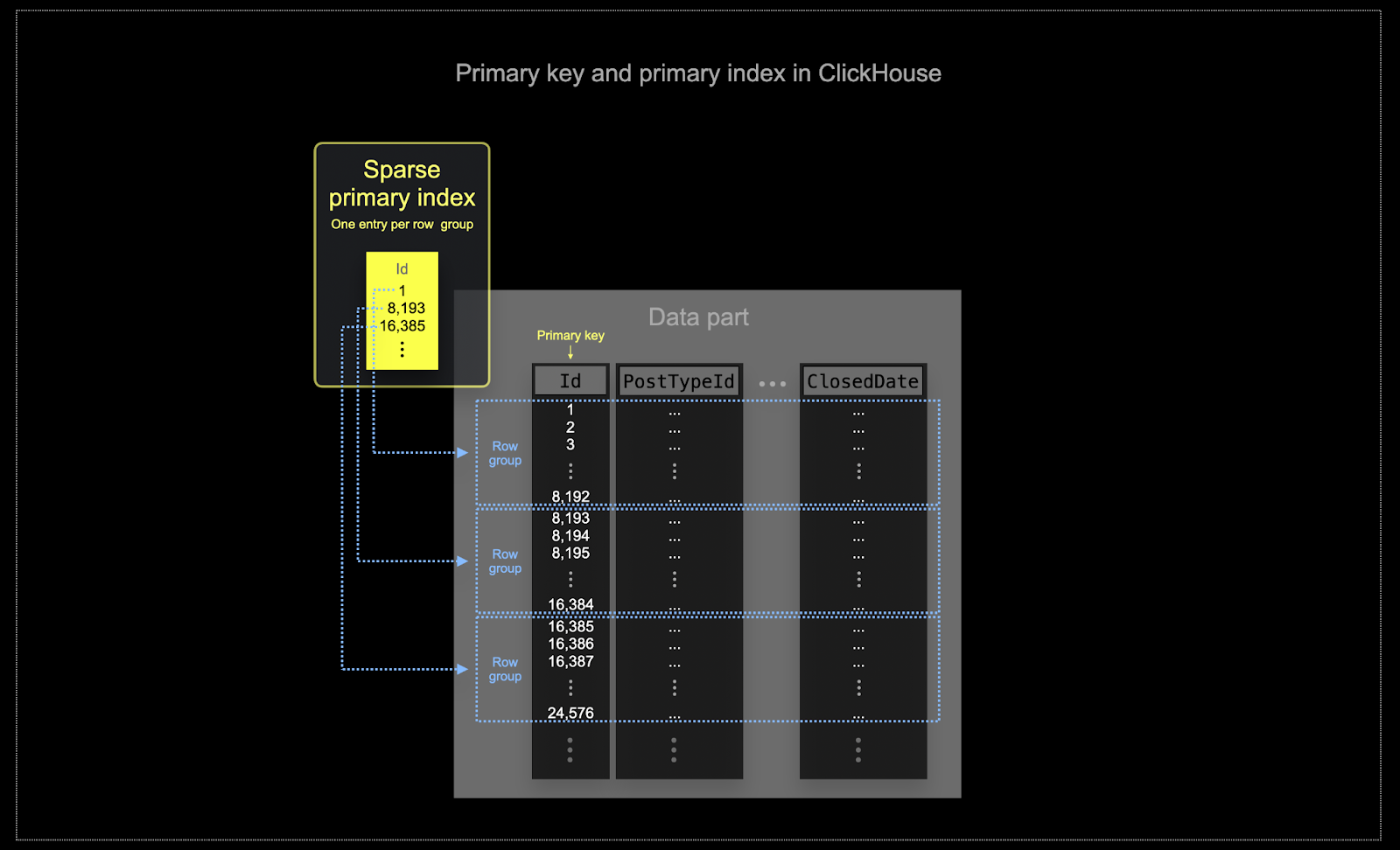
- メモリとディスクの効率は、ClickHouse が頻繁に使用されるスケールにとって極めて重要です。データは、シャードと呼ばれるチャンクで ClickHouse テーブルに書き込まれ、バックグラウンドで統合規則が適用されます。ClickHouse では、各シャードには独自の主インデックスがあります。シャードがマージされると、マージされたシャードの主インデックスもマージされます。Postgres とは異なり、これらのインデックスは各行のために構築されません。むしろ、シャードの主インデックスは、行グループごとに 1 つのインデックスエントリを持ちます。この技術はスパースインデックスと呼ばれます。
- スパースインデックスは、ClickHouse がッシュのディスク上で指定されたキーに従って行をストレージするために可能になります。単一行を直接見つけるのではなく(B-木に基づくインデックスのように)、スパース主インデックスはインデックスエントリのバイナリ検索を介して可能性のある一致の行グループを迅速に特定します。見つかった一致する可能性のある行のグループは、並行して ClickHouse エンジンにストリーミングされ、一致を見つけます。このインデックスデザインにより、主インデックスは小さく(メインメモリに収まる)、クエリ実行時間が大幅に短縮されます。特にデータ分析のユースケースで典型的な範囲クエリの場合です。詳細については、この詳細ガイドをお勧めします。
ClickHouse で選択されたキーは、インデックスだけでなく、ディスクにデータが書き込まれる順序も決定します。このため、圧縮レベルに劇的な影響を与え、さらにクエリパフォーマンスに影響を及ぼす可能性があります。大部分のカラムの値が連続した順序で書き込まれる整列キーは、選択された圧縮アルゴリズム(およびコーデック)がデータをより効果的に圧縮できるようにします。
テーブル内のすべてのカラムは、指定された整列キーの値に基づいてソートされます。キー自体に含まれているかどうかは関係ありません。たとえば、
CreationDateをキーとして使用した場合、他のすべてのカラムの値の順序はCreationDateカラムの値の順序に対応します。複数の整列キーを指定できます - これはSELECTクエリ内のORDER BY句と同じ意味で整列されます。
整列キーの選択
整列キーの選択に関する考慮事項とステップについては、posts テーブルを例にして、こちらをご覧ください。
圧縮
ClickHouse の列指向ストレージは、Postgres と比較して圧縮が大幅に改善されることがよくあります。以下に、両方のデータベースにおける Stack Overflow テーブルのストレージ要件を比較した例を示します:
圧縮の最適化と測定に関するさらに詳細は、こちらで確認できます。