データの移行
これは、PostgreSQL から ClickHouse への移行に関するガイドの パート 1 です。具体例を用いて、リアルタイムレプリケーション(CDC)方式により効率的に移行を行う方法を示します。ここで扱う多くの概念は、PostgreSQL から ClickHouse への手動での一括データ転送にも適用できます。
データセット
Postgres から ClickHouse への典型的なマイグレーション例を示すサンプルデータセットとして、こちら で説明している Stack Overflow データセットを使用します。これは、2008 年から 2024 年 4 月までに Stack Overflow 上で発生したすべての post、vote、user、comment、badge を含みます。このデータ用の PostgreSQL スキーマを以下に示します。
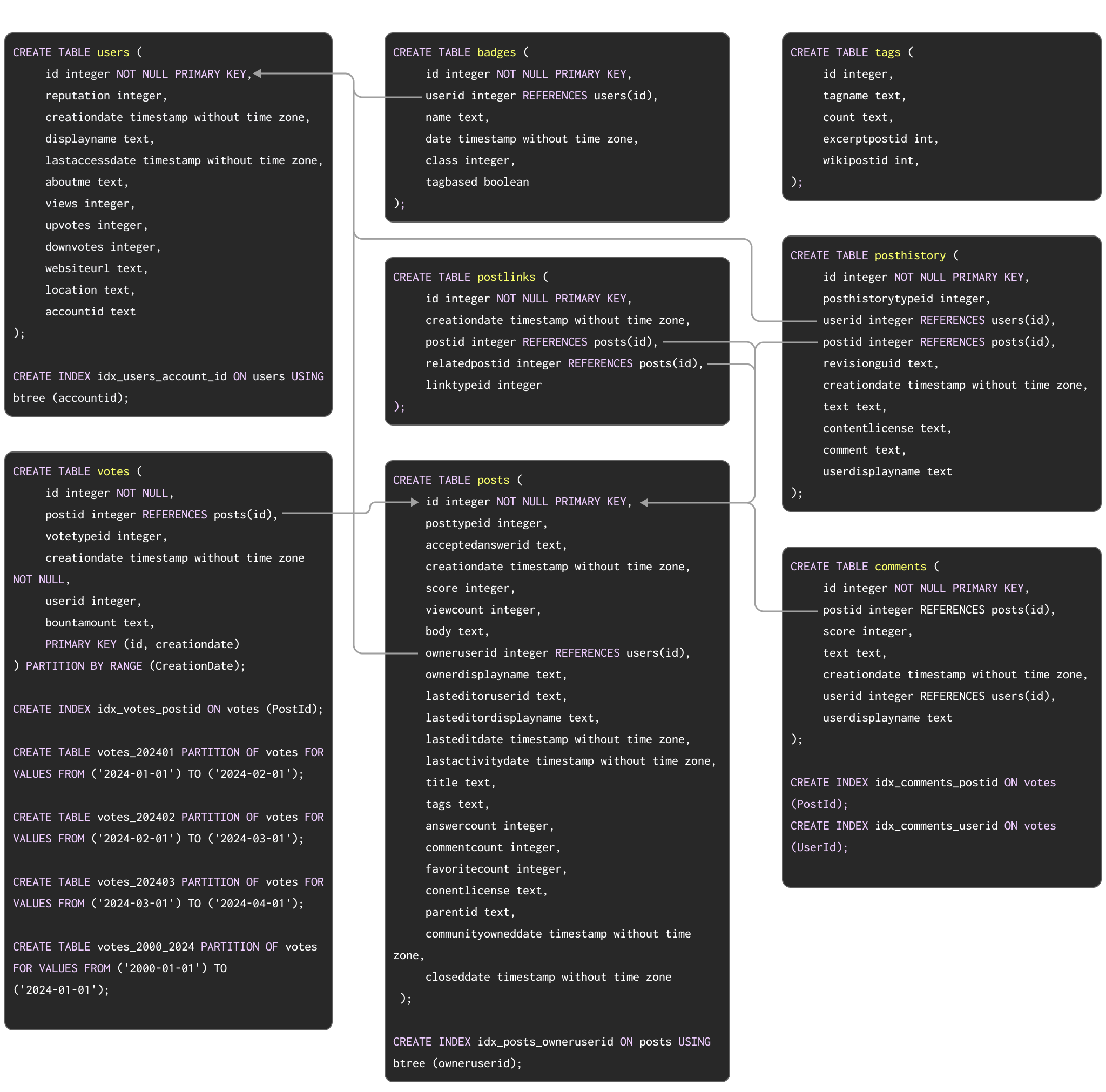
PostgreSQL でテーブルを作成するための DDL コマンドは こちら から利用できます。
このスキーマは必ずしも最適というわけではありませんが、主キー、外部キー、パーティショニング、インデックスなど、PostgreSQL の一般的な機能をいくつか活用しています。
これらそれぞれの概念を、ClickHouse の対応する機能へマイグレーションしていきます。
マイグレーション手順を検証する目的で、このデータセットを PostgreSQL インスタンスに読み込みたいユーザー向けに、DDL とともにダウンロード可能な pg_dump 形式のデータを用意しています。続いて、データロード用コマンドを以下に示します。
ClickHouse にとっては小規模ですが、このデータセットは Postgres にとってはかなりの規模です。上記は、2024 年最初の 3 か月をカバーするサブセットを表しています。
この例では、Postgres と ClickHouse 間のパフォーマンス差を示すためにフルデータセットを使用していますが、以下で説明するすべての手順は、より小さいサブセットでも機能的にはまったく同一です。フルデータセットを Postgres にロードしたいユーザーはこちらを参照してください。上記スキーマで課されている外部キー制約により、PostgreSQL 用のフルデータセットには、参照整合性を満たす行のみが含まれます。このような制約のない Parquet 版 は、必要に応じて簡単に ClickHouse に直接ロードできます。
データの移行
リアルタイムレプリケーション(CDC)
PostgreSQL 用の ClickPipes をセットアップするには、このガイドを参照してください。このガイドでは、さまざまな種類のソースとなる Postgres インスタンスを扱っています。
ClickPipes または PeerDB を用いた CDC アプローチでは、PostgreSQL データベース内のすべてのテーブルが ClickHouse に自動的にレプリケートされます。
更新と削除をほぼリアルタイムで処理するために、ClickPipes は Postgres のテーブルを、更新や削除の処理に特化した ReplacingMergeTree エンジンを使って ClickHouse のテーブルに対応付けます。ClickPipes を使用してデータがどのように ClickHouse にレプリケートされるかについての詳細はこちらを参照してください。CDC を用いたレプリケーションでは、更新または削除操作をレプリケートする際に、ClickHouse 内に重複した行が作成される点に注意することが重要です。ClickHouse でそれらを処理するための、FINAL 修飾子を使用した手法を参照してください。
ClickPipes を使用して ClickHouse に users テーブルがどのように作成されるかを見ていきましょう。
セットアップが完了すると、ClickPipes は PostgreSQL から ClickHouse へのすべてのデータ移行処理を開始します。ネットワークやデプロイメントの規模によってかかる時間は異なりますが、Stack Overflow データセットであれば数分程度で完了するはずです。
手動による一括ロードと定期更新
手動アプローチを用いる場合、データセットの初回一括ロードは次の方法で実施できます。
- テーブル関数 - ClickHouse の Postgres テーブル関数 を使用して、Postgres からデータを
SELECTし、ClickHouse のテーブルにINSERTします。数百 GB 規模までの一括ロードに適しています。 - エクスポート - CSV や SQL スクリプトファイルといった中間形式へエクスポートします。これらのファイルは、クライアントから
INSERT FROM INFILE句を使うか、オブジェクトストレージとそれ用の関数(例: s3, gcs)を利用して ClickHouse にロードできます。
PostgreSQL から手動でデータをロードする場合は、まず ClickHouse 上にテーブルを作成する必要があります。ClickHouse におけるテーブルスキーマの最適化については、Stack Overflow データセットを用いた例も含む データモデリングのドキュメント を参照してください。
PostgreSQL と ClickHouse の間ではデータ型が異なる場合があります。各テーブルのカラムに対応する同等の型を確認するために、Postgres テーブル関数 と併せて DESCRIBE コマンドを使用できます。次のコマンドは PostgreSQL の posts テーブルを DESCRIBE する例です。自身の環境に合わせて修正して利用してください。
PostgreSQL と ClickHouse 間のデータ型マッピングの概要については、付録ドキュメントを参照してください。
このスキーマの型を最適化する手順は、データを他のソース(例:S3 上の Parquet)からロードした場合と同一です。Parquet を使用する別のガイドで説明されている手順を適用すると、次のスキーマになります。
PostgreSQL からデータを読み取り、ClickHouse に挿入する単純な INSERT INTO SELECT でデータをロードできます。
増分ロードは、スケジュール設定することもできます。Postgres テーブルが挿入のみを受け付けており、単調増加する id またはタイムスタンプが存在する場合は、上記のテーブル関数アプローチを用いて増分をロードできます。つまり、SELECT に対して WHERE 句を適用できます。このアプローチは、同一のカラムのみが更新されることが保証されている場合には、更新のサポートにも使用できます。一方で、削除をサポートするにはテーブル全体の再ロードが必要となり、テーブルが大きくなるにつれてこれを実現するのは困難になる可能性があります。
ここでは、CreationDate を使用した初回ロードと増分ロードを示します(行が更新されると CreationDate も更新されると仮定します)。
ClickHouse は、
=,!=,>,>=,<,<=, および IN といった単純なWHERE句を PostgreSQL サーバー側へプッシュダウンします。これにより、変更セットの識別に使用されるカラムにインデックスを作成しておくことで、増分ロードをより効率的に実行できます。
クエリレプリケーションを使用している場合に UPDATE 操作を検出する 1 つの方法として、
XMINシステムカラム(トランザクション ID)をウォーターマークとして利用することが挙げられます。このカラムの変化は変更を示すため、その変更を宛先テーブルに適用できます。この方法を用いるユーザーは、XMINの値はラップアラウンドする可能性があり、比較には全表スキャンが必要となるため、変更の追跡がより複雑になることに注意してください。
